
This paper aims to develop a deep learning method to extract causes behind emotions in a document. It’s a relatively new NLP task so the authors mainly aim to show its feasibility using a multi-task learning approach.
The proposed approach aims to separately extract emotion and causes from text using multi-task learning and then conducts emotion-cause pairing and filtering using an improved version of the multi-task learning model.
To understand the task, consider the following statement as an example document:

There are five clauses and the fourth clause is considered the emotion clause conveying the emotion of happiness. The clauses that contain causes (cause clause) are the second clause and the third clause.
Previously, the task was known as ECE and involved detecting if a clause was a cause given the annotated emotion label of a document. See the example in the previous figure. The task is to find the corresponding cause clauses that correspond to the emotion of “happy”.
The main shortcomings of this task are that emotions of a document must first be annotated before cause extraction, which limits its real-world application and ignores the fact that emotions and causes are mutually indicative.
In contrast, the proposed ECPE task (shown on the right of the figure) outputs pairs of emotion-cause clauses and doesn’t need to provide annotations in advance. As seen in the example, two emotion-cause clauses are extracted without providing the emotion label of “happy”. Ideally, identifying causes may be able to improve emotion extraction from text and vice-versa, assuming emotion and cause are not mutually independent.
The Approach
The framework consists of two parts: 1) extract sets of emotion and cause clauses from each document via two kinds of multi-task learning networks, and 2) conduct emotion-cause pairing and filtering. The pairing is done via Cartesian product applied to the set of emotion and cause clauses. This yields a set of candidate emotion-cause pairs, on which a filter is applied to remove clause pairs that don’t contain a causal relationship.
To perform the first part of the framework (i.e. emotion and cause clause extraction), the Bi-LSTM based multi-task framework shown in the figure below is used. The model (also referred to as Indep) shows how the prediction for each type of clause is performed via the Bi-LSTM hidden representations which consist of context-aware representations of each clause.
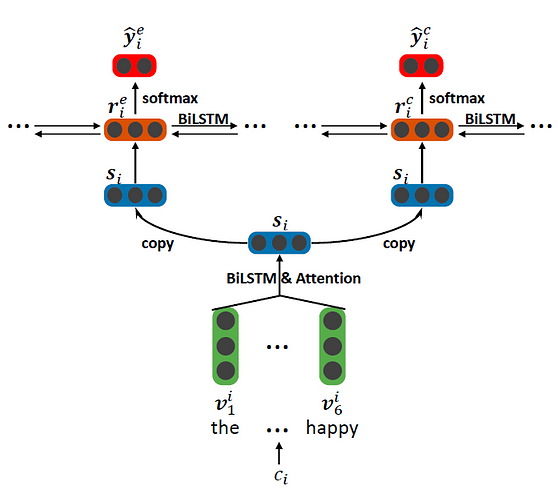
The assumption is that emotion and cause clauses are not mutually independent, therefore, the authors propose an interactive multi-task learning network to capture the correlation between them. To this end, a more interactive Bi-LSTM based multi-task framework (as shown in the figure below) is proposed. Compared to the previous multi-task model, the improved model performs a few extra steps in the upper layers which allows the prediction to happen based on the interaction of the two types of representations. Note that two separate enhanced models based on this framework are used: one for enhancing emotion extraction based on cause extraction (Inter CE), and one for enhancing cause extraction based on emotion extraction (Inter EC).
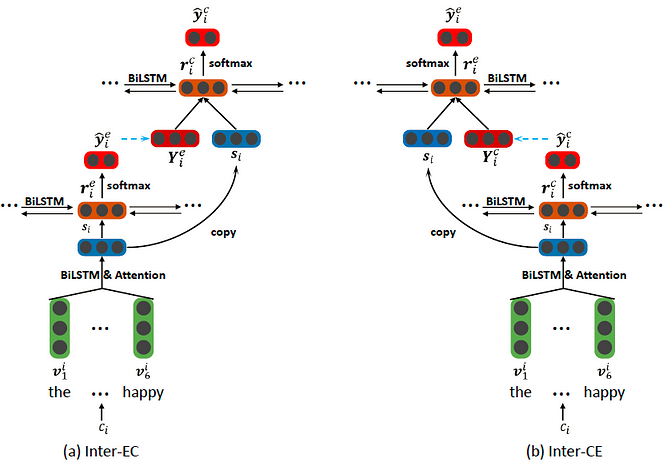
The output of these models is a set of emotion clauses and a set of cause clauses. The objective now is to pair the two sets to form emotion-cause pairs that form causal relationships. A Cartesian product renders the set of all possible pairs which are represented by a feature vector consisting of three components: emotion clause representation, cause clause representation, and the distance between the two clauses. The cause relationship is determined via a logistic regression model which takes as input the emotion-cause candidate pair features, applied a Sigmoid operation, and outputs a 1 or 0 to indicate if the relationship exists for each pair. The pairs that output 1 are the final set of emotion-cause pairs and used for evaluation.
Results
The benchmark emotion-cause dataset by Gui et al., 2016 is used for all experiments. Precision, recall, and F1 scores are used as the evaluation metrics. The table below shows the experimental results for all the separate tasks using the three proposed models based on multi-task learning.

Inter-EC produced better results, especially as it relates to the ECPE task. One can also observe that both emotion extraction and cause extraction improve each other in individual tasks. The results are consistent with the intuition that emotion and cause are mutually indicative.
Other variations of the models that leverage the dataset available annotations are also tested, which unsurprisingly show improvements since they use the additional information to improve the predictions of the different tasks. You can observe the results of the new models (labeled by the Bound tag) below:

The results below show the effectiveness of the pair filtering phase:
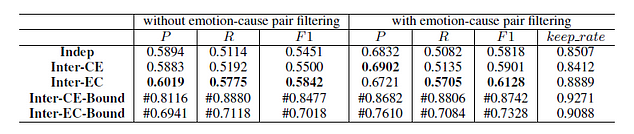
Other results using rule-based and machine learning methods are also presented in the paper.
In summary, the overall results indicate that emotion extraction helps to improve cause extraction and cause extraction also helps to enhance emotion extraction. Combined, both sub-tasks are used to improve ECPE. The authors also comment that there is room for improvement architecture-wise and also to improve cause extraction which was observed to be the more difficult task.
Paper: Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts — Rui Xia and Zixiang Ding
Source Code: https://github.com/NUSTM/ECPE