

Post Original en Ingles: https://dair.ai/NLP_Newsletter_The_Annotated_GPT-2,_Understanding/
Primero que todo, no puedo agradecerles lo suficiente a todos por el increible animo y soporte para continuar con el boletín informativo de NLP. Este esfuerzo requiere una investigación y edición tediosa, la cual encuentro gratificante y útil para proveer el mejor contenido. Espero que lo estén disfrutando tanto como yo.
Suscríbete al Boletín Informativo de NLP para recibir futuras ediciones en tu email. Este boletin lo desarrolla Elvis Saravia, editor de dair.ai
Publicaciones📙
Un entendimiento teórico del self-distillation
En el contexto del Deep Learning, self-distillation es el proceso de transferir conocimiento de una arquitectura a otra arquitectura idéntica. Las predicciones del modelo original son alimentadas como valores objetivo al otro modelo mientras se entrena. Además de tener propiedades deseables (como reducir el tamaño del modelo) resultados empíricos demuestran que esta aproximación trabaja bastante bien en sets de datos del tipo held-out. Un grupo de investigadores recientemente publicó una investigación que provee un análisis teórico con foco en entender mejor qué está pasando en el proceso de destilación del conocimiento y por que es efectivo. Los resultados muestran que unas pocas rondas de self-distillation amplifica la regularización (limitando progresivamente el número de funciones básicas que representan la solución) lo que tiende a reducir el over-fitting. (Lee la investigación completa aquí)
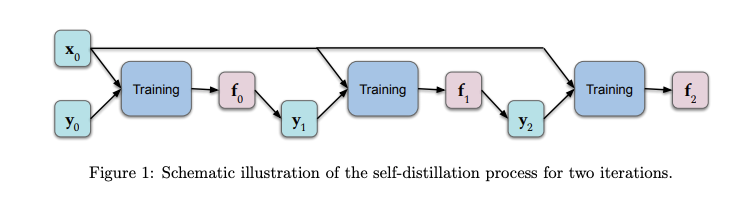
Traducción: Figura 1. Ilustración esquemática del proceso de self-distillation por dos iteraciones. Fuente: https://arxiv.org/abs/2002.05715
Los 2010: La década del Deep Learning / Mirada al 2020
Jürgen Schmidhuber, un pionero en la inteligencia artificial, publicó recientemente un artículo titulado “Foco en proveer un resumen histórico del Deep Learning desde el 2010”. Algunos de los temas incluyen LSTMs, redes neuronales feedforward, GANs, DeepRL, Meta-Learning, World Models, distillings NNs, Attention Learning, etc. El artículo concluye con una mirada al 2020, donde llama la atención a temas como la privacidad y los mercados de datos.
Utilizando Redes Neuronales para resolver ecuaciones matemáticas avanzadas.
Investigadores de Facebook AI publicaron una investigación que dice proponer un modelo entrenado en problemas matemáticos y sus soluciones para aprender a predecir posibles soluciones en problemas cómo resolver integrales matematicas. El acercamiento está basado en un novedoso framework similar al usado en neural machine translation donde una expresión matemática es representada como una especie de lenguaje y la solución es tratada como su traducción. Por esto, en vez de que el resultado sea una traducción, es la solución al problema matematico. Con esto, los investigadores concluyen que las redes neuronales profundas no solo son buenas para el razonamiento simbólico sino también para tareas más diversas.
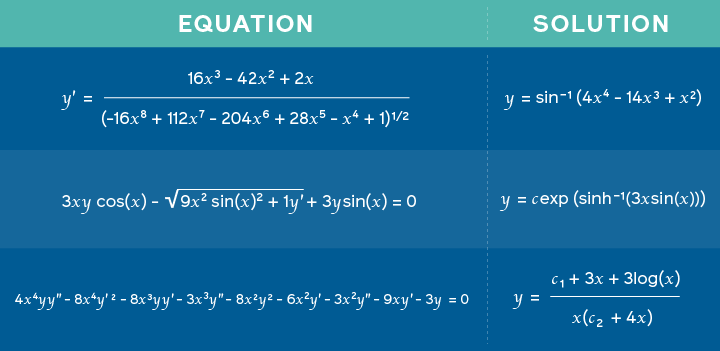
Ecuaciones incluidas como entrada con su correspondiente solución. Fuente
Creatividad y Sociedad 🎨
IA para el descubrimiento científico
Mattew Hutson reporta cómo la inteligencia artificial (IA) puede ser usada para producir emuladores con la capacidad de modelar fenómenos naturales complejos. Estos modelos pueden a su vez apuntar a diferentes tipos de descubrimientos científicos. El desafío al construir estos emuladores es que necesitan una gran cantidad de datos y una búsqueda extensiva de parámetros. Una investigación reciente propone una técnica llamada DENSE, basada en neural architecture search para construir emuladores precisos utilizando una cantidad de datos de entrenamiento limitada. Los investigadores hicieron distintas pruebas construyendo simuladores para caso como astrofísica, ciencia climática, energía de fusión, etc.
Mejorando la traducción imagen-a-ilustración
GANILLA es una aproximación que propone el uso de las GANs para mejorar la transferencia de estilo y contenido en la tarea de convertir una imagen en una ilustración. En particular, un modelo para imagen-a-ilustración es propuesto (con una red generadora mejorada) y evaluado basado en un nuevo framework para evaluación cuantitativa que considera tanto el contenido como el estilo de la imagen generada. La novedad de esta investigación es en la red generadora propuesta que considera un balance entre estilo y contenido que anteriores intentos fallaron en alcanzar. El código y modelo pre entrenado están disponibles en línea. Aquí se puede encontrar la investigación completa.

Traducción: Ejemplos de salida de CycleGAN, DualGAN, y nuestro método (GANILLA) utilizando diferentes estilos. CycleGAN y GANILLA generan imágenes en un estilo de ilustración, pero DualGAN falla en transferir el estilo. Sin embargo, CycleGAN falle en preservar el contenido de la imagen original, por ejemplo, aleatoriamente coloca caras de animales en el aire. Nuestro método preserva contenido así como también transfiere el estilo de la imagen original.
Andrew Ng habla sobre su interés en self-supervised learning
Andrew Ng, fundador de deeplearning.ai, participa en el podcast Artificial Inteligence de Lex Friedman para hablar de diferentes temas como sus comienzos en el ML, el futuro del AI y la educación, recomendaciones de uso para ML, sus metas personales y a cuáles técnicas de ML prestar atención en el 2020.
Andrew tambien explico por que está muy emocionado sobre el self-supervised representation learning. Self-supervised learning se trata sobre enfocar un problema de aprendizaje que intenta obtener la supervisión de los datos en sí mismos para hacer uso de grandes cantidades de datos no clasificados, escenario más común que datos limpios y clasificados. Las representaciones aprendidas, opuesto al rendimiento de la tarea, son importantes y pueden ser usadas en tareas más adelante, similar a lo que está siendo usado en modelos de lenguaje natural como BERT.
Hay mucho interés en usar el self-supervised learning para aprender representaciones visuales generales que hagan al modelo más preciso en situaciones de bajos recursos. Por ejemplo, un nuevo método llamado SimCLR (Dirigido por Geoffrey Hinton) propone un framework para el constrastive self-supervised learning de representaciones visuales para mejorar el resultado de la clasificación de imágenes en diferentes contextos como el transfer learning y el semi-supervised learning.
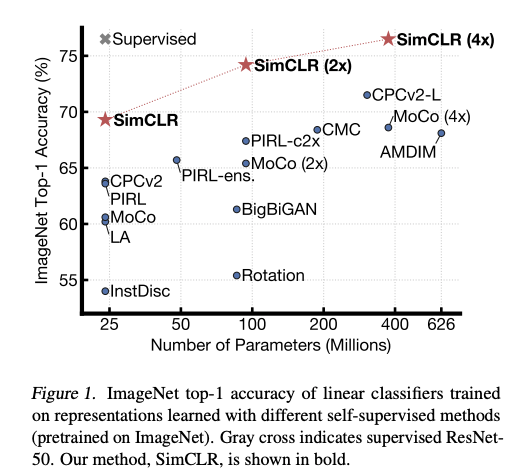
Traducción: ImageNet top-1 accuracy de clasificadores lineales entrenados en representaciones aprendidas con diferentes métodos de auto-aprendizaje (pre entrenados en ImageNet). La cruz gris indica un modelo ResNet-50 supervisado. Nuestro método, SimCLR, es mostrado en negrita.
Herramientas y Set de Datos ⚙️
Librerías JAX
JAX es una nueva librería que combina NumPy y diferenciación automática para realizar investigación de alto rendimiento en ML. Para simplificar procesos para construir redes neuronales usando JAX, DeepMind lanzó Haiku y RLax. RLAx simplifica la implementación de agentes de reinforcement learning y Haiku simplifica la construcción de redes neuronales utilizando paradigmas familiares de programación orientada a objetos.
Una herramienta para procesar datos de Wikipedia
Spakwiki es una herramienta para procesar datos de Wikipedia. Este lanzamiento es parte de muchos esfuerzos para permitir análisis interesantes de comportamiento como capturar tendencias y sesgos de lenguaje en ediciones de distinto idioma en Wikipedia. Los autores descubrieron que independientemente del lenguaje, el comportamiento de búsqueda de los usuarios de Wikipedia es muy parecido en categorías como películas, música y deportes pero que las diferencias se vuelven más aparentes con eventos locales y particularidades de cultura.
Tokenizadores, caso DistilBERT y modelos
Una nueva entrega de Transformers de Hugging Face ahora incluye la integración de su rápida librería de tokenización que intenta mejorar el tiempo de ejecución de modelos como BERT, RoBERTa, GPT2, y otro modelos construidos por la comunidad.
Ética en la Inteligencia Artificial 🚨
Consideraciones éticas para modelos de NLP y ML.
En un nuevo episodio de NLP Highlights, Emily Bender habla sobre algunas consideraciones éticas cuando se desarrollan modelos de Procesamiento de Lenguaje Natural y tecnologías tanto en el contexto de la academia como de industria. Algunos de los tópicos discutidos incluyen consideraciones éticas cuando se diseñan tareas, recolección de datos, y eventualmente publicación de resultados.
Adicionalmente a todas las consideraciones mencionadas anteriormente, una preocupación que siempre se discute en la comunidad de AI es enfocarse demasiado en optimizar una métrica, lo que va en contra de los cimientos de lo que el campo trata de alcanzar. Rachel Thomas y David Uminsky discuten cómo esto puede salir mal a través de un análisis con diferentes casos de uso. Además, proponen un framework simple para mitigar el problema que involucra el uso y combinación de múltiples métricas, seguido del involucramiento directo de los usuarios afectados por la tecnología que se está desarrollando.
Artículos y Blogs ✍️
GPT-2 Explicado
Aman Arora recientemente publicó un artículo excepcional titulado “El GPT-2 Explicado” explicando el funcionamiento interno del modelo basado en la técnica del Transformer llamado GPT-2. Su aproximación fue inspirada por el artículo El Transformer Explicado que tomó una aproximación a explicar las partes más importantes del modelo siguiendo ejemplos fáciles de seguir y código comentado. Amant realizó un gran esfuerzo para re implementar GPT-2 de OpenAI utilizando PyTorch y la librería de Transformers de Hugging Face. Es un trabajo brillante.

Más allá de BERT?
Opinión interesante de Sergi Castella en que hay más allá de BERT. El tema principal incluye mejorar métricas, como la librería Transformer de Hugging Face empodera la investigación, set de datos interesantes para revisar, utilización de modelos, etc.
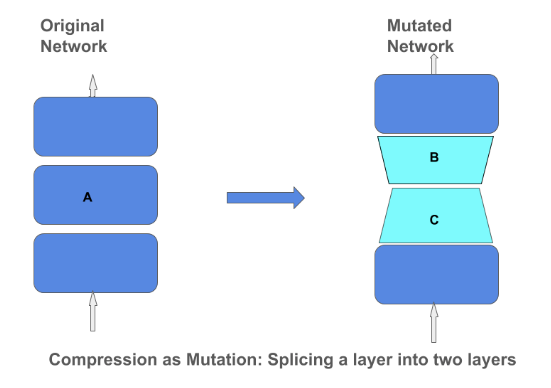
Operador para comprimir Matrices
El blog the TensorFlow publico un articulo donde explican las técnicas para compresión de matrices y su importancia en un modelo de red neuronal. La compresión de matrices puede ayudar a construir modelos más eficientes y reducidos que pueden ser incorporados en dispositivos más pequeños como teléfonos y asistentes del hogar. Enfocarse en la comprensión por métodos como low-rank-approximation y quantization significa que no debemos comprometer la calidad del modelo
Educación🎓
Fundamentos del NLP
Estoy emocionado de liberar un borrador del capítulo 1 de mi nueva serie llamado Fundamentos del NLP. Enseña conceptos comenzando desde lo más básico, compartiendo buenas prácticas, referencias importantes, errores comunes a evitar, y cuál es el futuro del NLP. Un Colab Notebook está incluido y el proyecto será mantenido aquí

[En línea] Revisión/Discusión: Parte 1 Sesión de lectura de Fundamentos Matemáticos
Machine Learning Tokio está organizando una discusión en línea para revisar los capítulos que fueron cubiertos en su más reciente sesión de estudio. El grupo ha estudiado previamente capítulos del libro Matemáticas para el Machine Learning escrito por Marc Peter Deisenroth, A Aldo Faisal, y Cheng Soon Ong. El evento está pautado para el 8 de Marzo de 2020.
Libros Recomendados
En un segmento previo discutimos la importancia de la compresión de matrices para construir modelos de ML compactos. Si estás interesado en aprender más sobre como construir redes neuronales más pequeñas para sistemas embebidos te recomiendo este gran libro llamado TinyML por Pete Warden y Daniel Situnayake.

Otro libro interesante a tener en cuenta es “Deep Learning para programadores con fastai y pyTorch: Aplicaciones AI sin un PhD” por Jeremy Howard y Sylvain Gugger. El libro trata de proveer la matemática necesaria para construir y entrenar modelos que resuelvan tareas en el área de visión por computador y Entendimiento natural de texto.

Menciones a considerar ⭐️
Puedes acceder a las versiones anteriores de este boletín aquí.
Torchmeta es una librería que permite el uso de data loaders para la investigación en meta-learning. El creador es Tristan Deleu.
Manuel Tonneau escribió una pieza ofreciendo una mirada más detallada a alguna de la maquinaria involucrada en el modelamiento del lenguaje. Algunos tópicos incluyen búsquedas greedy y beam, así como también nucleus sampling.
El MIT liberó el programa de estudio completo del curso titulado “Introducción al Deep Learning”, incluye videos de las clases que ya se dictaron. Están apuntando a liberar videos y presentaciones todas las semanas.
Aprende a entrenar un modelo para reconocimiento de entidades nombradas (NER) utilizando una aproximación vía Transformers en menos de 300 líneas de código. Puedes encontrar el Google Colab que lo acompaña aquí.