
Overview
This work proposes models that combine information from different modalities (e.g., images and text) to be able to classify social media content. Information from different modalities are combined using neural network models through a pooling layer. In addition, an auxiliary learning task is used to learn a common feature space for all modalities (more on this later).
Motivation
Multimodal approaches become more important as social media networks allow for users to post multimodal posts (e.g., gifs, videos, audio segments, text, etc.). Analysis of multimodal information allows for better understanding of users (user profiling) and can be used to effectively run ad campaigns on the social network. In addition, it can be used to better understand other emotion-related behaviors such as mental health disorders, etc.
Example
Consider the examples of multimodal posts in the pictures below. If we only paid attention to the images (left to right), we would predict emotions such as joy, fear, and contentment. If we considered both the image and text: the first example remains as joy; the second example is probably mixed emotion (the text convey joy); and the third example is also mixed emotion (the text convey sadness). These simple examples emphasize on the importance of considering both modalities to deduce the overall emotion conveyed in the social post.

Contribution
The main problem with previous multimodal approaches is the inability to deal with the absence of some important modality. For instance, let’s assume we can obtain text and video from a piece of content, but we can’t obtain the audio because it is corrupted or unavailable. In such cases, previous methods did not address this important problem (i.e., missing modality). The proposed model aims to address this problem and proves its robustness through an emotion classification task. Besides dealing with the “missing modality” problem, the authors claim that their approach can also scale to other tasks and modalities.
Challenge Addressed
As previously mentioned, the proposed model can handle situations where there is a missing modality. In other words, there system supports the following cases: only image or text or both.
Hand-Crafted Features vs. Automatic Feature Learning
I believe this is an important discussion that this paper highlights in the related work. As it relates to emotion recognition, it is challenging to manually create features as we cannot guarantee that all aspects of emotions (features) that can capture the emotions are covered. Convolutional neural networks (CNNs) are used in place so as to automatically learn representations that can generalize to the problem of emotion recognition. I couldn’t help but commenting that even though this argument is strong, hand-crafting features also offer better intuition of what is being learned, something deep learning models may not offer, yet! However, some good people are tirelessly working on this problem (Feature Visualization).
Concepts to Know
- Late fusion — combination of results obtained by different classifiers (trained on different modalities); i.e., fusion is done at the decision level.
- Early fusion — information from different modalities are combined at the feature level, and classification is done on the combined representations.
Multimodal Classification
This work employs an adaptation of early fusion for combining modalities for emotion recognition through CNNs. Two prominent modalities of social media are used, i.e. text and image. If both image and text are available for a social post, they are assumed to have semantic relation — the text describes the image. Images are represented by vectors, which are obtained after feeding images into a CNN trained on ImageNet. Texts are represented through pre-trained word embeddings (GloVe).
Model
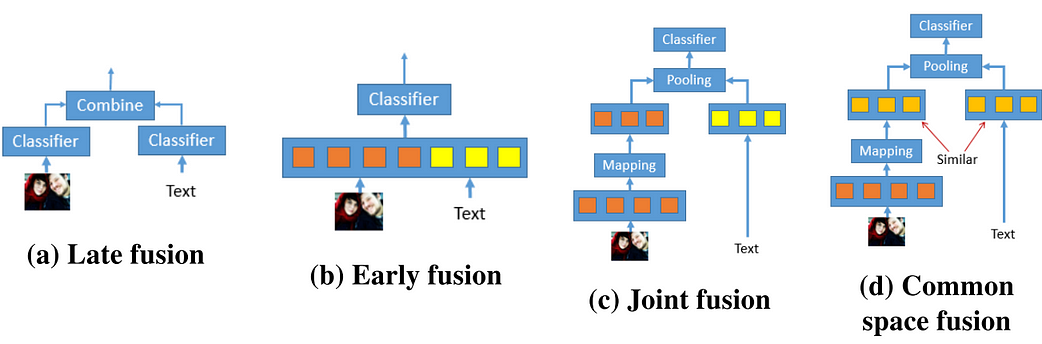
In the figure above, all types of fusion techniques for combining features to be fed to a classifier are shown. This work proposes two fusion approaches which enjoy the simplicity of early fusion (a) and the flexibility of late fusion (b). These approaches are called joint fusion © and common space fusion (d).
In the joint fusion model, text and images are fused in the fusion layer, which applies a pooling operation to the text and image vector to obtain a combined feature vector. The pooling operations require both vectors to be of the same size. Typically, the image vector has a higher dimension than the text vector, therefore, an extra linear layer is added to map the original image vector to a vector of the same dimension as the text vector. The joint fusion neural network is trained by minimizing the negative log-likelihood using stochastic gradient descent (SGD). (See paper for additional details)
The second approach, common feature space fusion, aims to enforce visual and textual vectors of a post to be in the same feature space. Note that this was motivated by the fact that the joint fusion model considers these signals (visual and textual) as different, i.e., no relationship between them. An auxiliary task is employed, which enforces similarity between both a text and image vector belonging to a post, ensuring that the rest of text vectors from different classes are different from the image vector. (See paper for details on how this objective is trained and combined with the main classification task).
Task
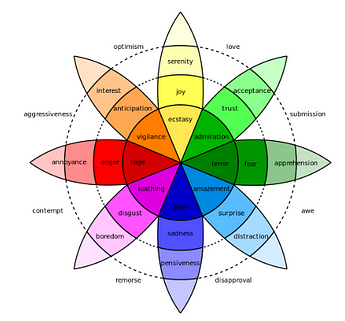
An emotion classification task is used to evaluate the proposed multimodal approaches. Different discrete emotion categories from Plutchik’s wheel of emotions are employed to label two types of datasets.
Datasets
A flickr image dataset was crawled and assigned to Amazon Mechanical Turk workers for annotations; i.e., human workers were asked to annotate the emotion they perceived from the images. Title and descriptions are also obtained for each image from the flickr website. In addition, a Reddit dataset was also collected; subreddits related to emotion (happy, creepy, rage, gore) were used to collect data for 4 emotions, joy, fear, anger, and disgust, respectively. (See paper for more details on collecting and preparing datasets)
Experiments
Unimodal baselines (FastText model for text and InceptionNet model for images), traditional multimodal approaches (early and late fusion), and the proposed multimodal models (joint fusion and common space fusion) are trained on the datasets. For the embedding layer, GloVe pre-trained word vectors are considered.
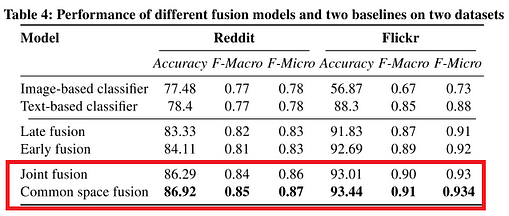
From the results in the table above, we can observe that the proposed fusion models (joint fusion and common space fusion) outperform all the other models in both datasets, including the traditional fusion techniques. The common space fusion model, in particular, performs extremely well even when only one modality for a post existed (see results below).

Analysis
Classification results on several examples are provided for error analysis (see figure below). We can observe that for the highlighted example, the common space fusion model can detect fear when using both the text and image information. Somehow, the model can detect that in this particular example, the image descriptor expresses sarcasm, which is obvious from the creepy doll in the closet show in the image. Kind on interesting and weird at the same time, no pun intended. (See paper for more interesting analysis and examples)

Conclusion and Future Work
-
Experimental results show that by combining textual and visual data, fusion models can improve emotion classification accuracy on two types of datasets, with very significant gains in some cases.
-
The common space fusion model performs well even when only one modality existed because this model contains information from two modalities. These type of models proof ideal for cases where more modalities may exist in the data. However, the authors point out that these models may suffer from information loss as one modality may be less informative than the other.
-
I honestly enjoyed reading this paper. It is well written and it provides a new idea on how to combine modalities for understanding social media data. Other applications may include sarcasm detection, which is a more complex task as summarized here.
References
- Datasets and code for this work are available here
- Ref: https://arxiv.org/abs/1708.02099 — “Multimodal Classification for Analysing Social Media”
👋 Thanks for all the love you gave to the last article “Detecting Sarcasm with Deep Convolutional Neural Networks”. I hope you enjoyed this one too! If you have any questions, feel free to reach out to me (@omarsar0) — I am very active there and discuss about AI, NLP, Affective Computing, among other things.