

Last year was huge for natural language processing (NLP). As far as improvements go, faster implementation of neural networks is now possible with the use of optimized libraries and high-performing hardware. However, one of the bottlenecks in modern deep learning-based NLP pipelines has been tokenization, in particular, implementations that are versatile and framework independent.
In an effort to offer access to fast, state-of-the-art, and easy-to-use tokenization that plays well with modern NLP pipelines, Hugging Face contributors have developed and open-sourced Tokenizers. Tokenizers is, as the name implies, an implementation of today’s most widely used tokenizers with emphasis on performance and versatility.
An implementation of a tokenizer consists of the following pipeline of processes, each applying different transformations to the textual information:
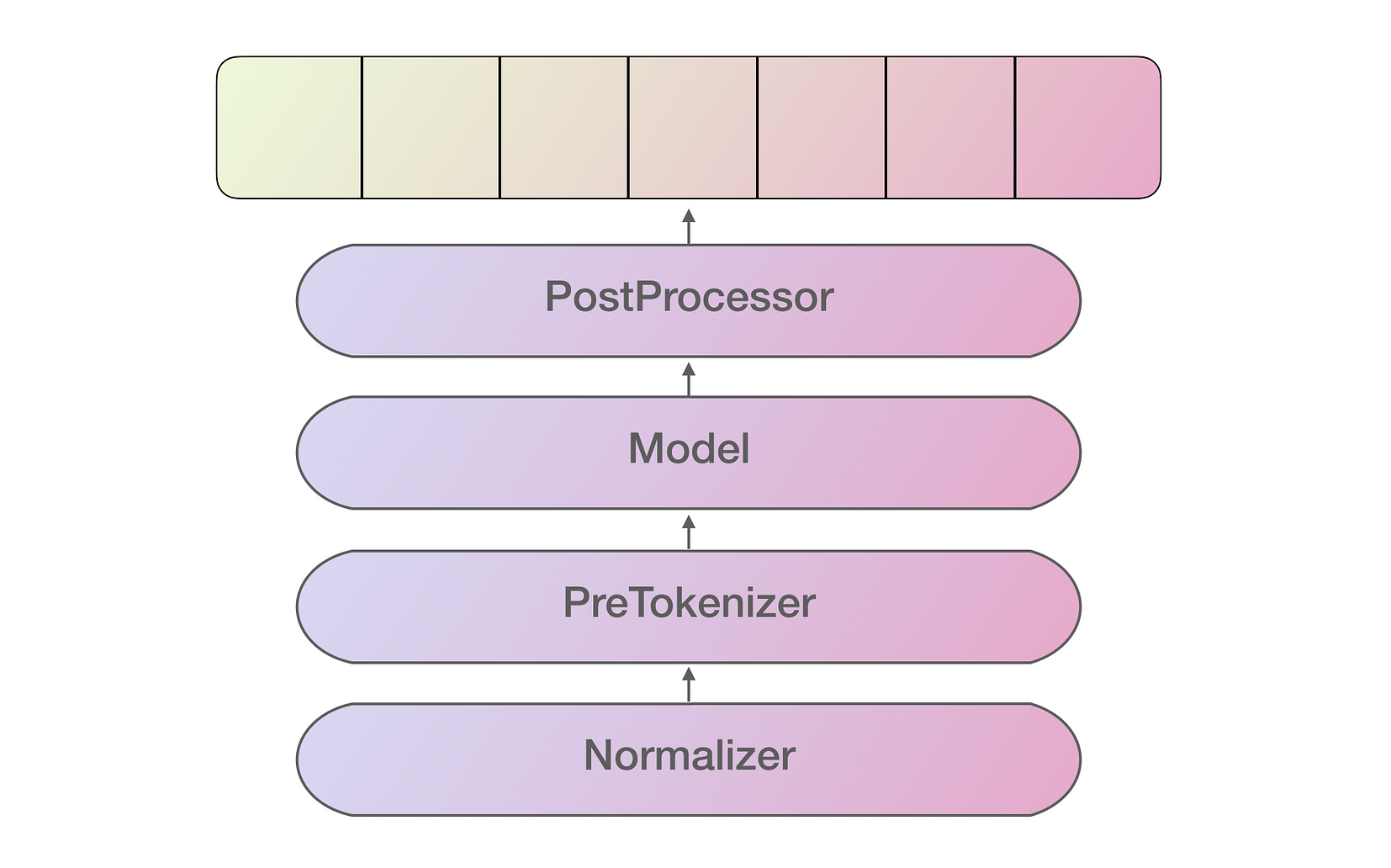
Tokenizer pipeline
The Normalizer first normalizes the text, the result of which is fed into the PreTokenizer which is in charge of applying simple tokenization by splitting the text into its different word elements using whitespaces. The Model corresponds to the actual algorithm, such as BPE, WordPiece or SentencePiece, that performs the tokenization itself. The PostProcessing then takes care of incorporating any additional useful information that needs to be added to the final output Encoding, which is then ready to be used and fed into, say, a language model for training.
This may look like a typical tokenization pipeline and indeed there are a lot of fast and great solutions out there such as SentencePiece, fast-BPE, and YouTokenToMe. However, where Tokenizers really shines is in the following key areas:
- Performance (“takes less than 20 seconds to tokenize a GB of text on a server’s CPU”)
- Provides access to the latest tokenizers for research and production use cases (BPE/byte-level-BPE/WordPiece/SentencePiece…)
- Aims for ease-of-use and versatility
- Offers reproducibility of the original text that corresponds to the token using alignments tracking
- Applies pre-processing best practices such as truncating, padding, etc.
Usage
Tokenizers is implemented with Rust and there exist bindings for Node and Python. There are plans to add support for more languages in the future. To get started with Tokenizers you can install it using any of the options below:
- Rust: https://crates.io/crates/tokenizers
- Python:
pip install tokenizers - Node: https://github.com/huggingface/tokenizers/tree/master/bindings/node
Below is a code snapshot of how to use the Python bindings for Tokenizers:
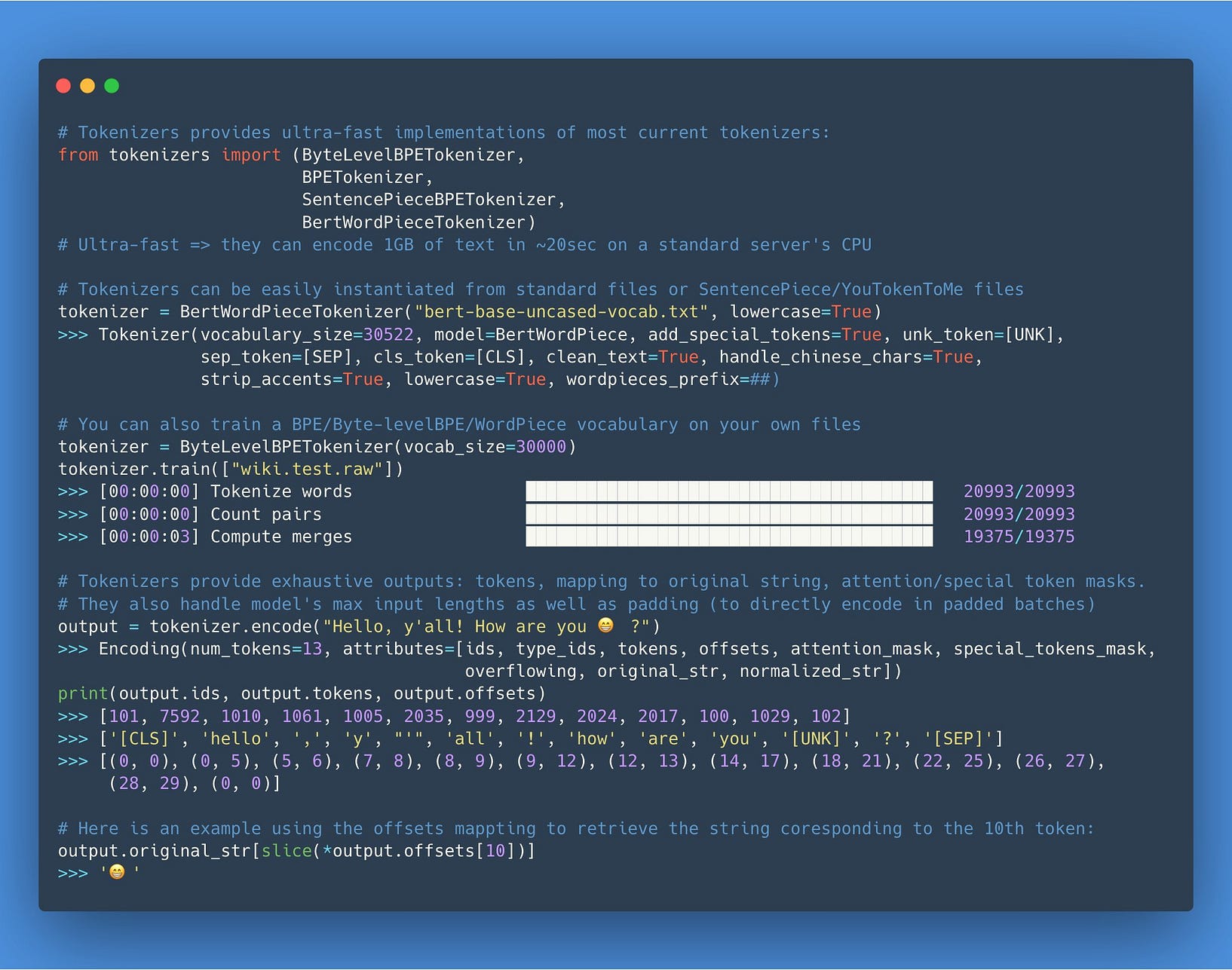
You can either use a pre-trained tokenizer or train your own tokenizer. The current Tokenizers that are currently provided out of the box are BPETokenizer, ByteLevelBPETokenizer, SentencePieceBPETokenizer, and BertWordPieceTokenizer. You can read more in the official documentation.
Happy Tokenizing! 🤗
Hugging Face is the New-York based NLP startup behind the massively popular NLP library called Transformers (formerly known as pytorch-transformers).
Recently, they closed a $15 million Series A funding round to keep building and democratizing NLP technology to practitioners and researchers around the world.
Thanks to Clément Delangue and Julien Chaumond for their contributions and feedback towards this article.
Thanks to Julien Chaumond.