

欢迎来到 NLP 时事简报!全文较长,建议收藏。
如果想让自己有趣的研究/项目出现在NLP简报中,随时在公众号后台留言联系我
来看看都有哪些内容,enjoy
- 1、Publications 📙
- 1.1 理解self-distillation
- 1.2 深度学习十年简史
- 1.3 利用神经网络求解高等数学方程
- 1.4 CodeBERT
- 2、Creativity and Society 🎨
- 2.1 AI for scientific discovery
- 2.2 改善image-to-illustration
- 2.3 Andrew Ng谈自监督学习
- 3、Tools and Datasets ⚙️
- 3.1 JAX libraries
- 3.2 处理维基百科数据的工具
- 3.3 Rust Tokenizers, DistilBERT base cased
- 3.4 夸夸语料
- 4、Ethics in AI 🚨
- 4.1 NLP和ML模型的道德考量
- 5、Articles and Blog posts ✍️
- 5.1 The Annotated GPT-2
- 5.2 Beyond BERT?
- 5.3 矩阵压缩算子
- 6、Education 🎓
- 6.1 NLP基础
- 6.2 数学基础课
- 6.3 书籍推荐
- 6.4 计算机科学自学指南
- 7、Noteworthy Mentions ⭐️
1、Publications 📙
1.1 理解self-distillation
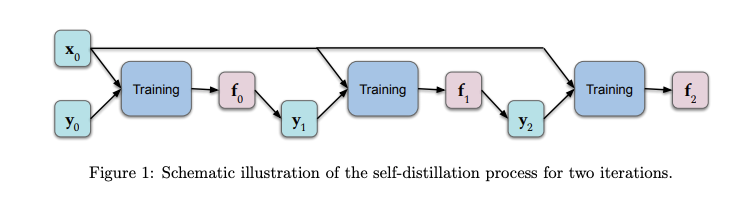
在深度学习中,self-distillation[1]是将知识从一种架构转移到另一种相同架构的过程。在训练时,原始模型的预测作为目标值提供给另一个模型。除具有所需的属性(例如减小模型大小)外,经验结果还表明该方法在held-out datasets上效果很好。
一组研究人员最近发表了一篇论文,Self-Distillation Amplifies Regularization in Hilbert Space[2],提供了理论分析,重点是更好地了解知识蒸馏过程中正在发生的事情以及为何有效。结果表明,几轮self-distillation会通过逐渐限制代表解的基函数的数量放大正则化,这往往会减少过度拟合。
1.2 深度学习十年简史
人工智能的先驱、LSTM之父JürgenSchmidhuber最近发布了一个新博客,The 2010s: Our Decade of Deep Learning / Outlook on the 2020s[3],提供自2010年以来的深度学习历史概述,包括LSTM,前馈神经网络,GAN,深度强化学习,元学习,世界模型 ,蒸馏神经网络,注意学习等一些主题。文章最后总结了2020年代的前景,鼓励人们关注紧迫的问题,例如隐私和数据市场。
1.3 利用神经网络求解高等数学方程
Facebook AI研究人员发表了一篇论文,Deep Learning for Symbolic Mathematics[4],声称提出了一个针对数学问题和匹配解决方案进行训练的模型,以学习预测诸如解决集成问题之类的任务的可能解决方案。该方法基于类似于机器翻译中使用的新颖框架,在该框架中,数学表达式表示为一种语言,而解决方案则视为翻译问题。因此,输出是解决方案本身,而不是模型输出翻译。据此,研究人员声称深度神经网络不仅擅长符号推理,而且还可以胜任各种任务。
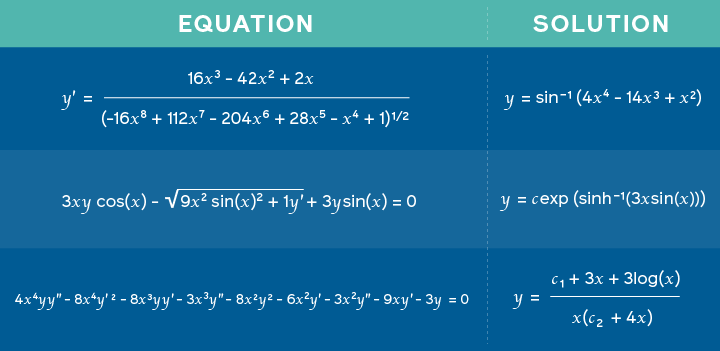
1.4 CodeBERT
在这篇名为《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》[5]的论文中,来自哈工大、中山大学和微软的研究人员详细介绍了这一新预训练模型,该模型可处理双模态数据:编程语言(PL)和自然语言(NL)。
CodeBERT 学习能够支持下游 NL-PL 应用的通用表示,比如自然语言代码搜索、代码文档生成,经实验 CodeBERT 模型在两项任务均取得 SOTA 效果,同时研究者构建了 NL-PL 探测数据集,CodeBERT 在 zero-shot 设置中的性能表现也持续优于 RoBERTa。
2、Creativity and Society 🎨
2.1 AI for scientific discovery
Mattew Hutson报告了如何使用人工智能(AI)来生成仿真器[6],这些仿真器在对复杂自然现象进行建模方面具有重要作用,而自然现象又可能导致不同类型的科学发现。构建这些仿真器的变化是,它们通常需要大规模数据和广泛的参数探索。最近的论文提出了DENSE方法[7],一种基于神经结构搜索[8]来构建准确的仿真器,而仅依赖有限数量的训练数据。他们通过对包括天体物理学,气候科学和聚变能等在内的案例进行仿真来对其进行测试。
2.2 改善image-to-illustration
GANILLA[9]是一种使用GAN来改进未配对的图像到图像翻译任务[10]中样式和内容传递的方法。提出了一种具有改进的生成器网络用于图像到插图的模型,并基于新的定量评估框架对模型进行了评估,该框架同时考虑了内容和样式。这项工作的新颖性在于拟议的生成器网络,该生成器网络考虑了先前模型无法实现的样式和内容之间的平衡。可以在此处阅读原文:GANILLA: Generative Adversarial Networks for Image to Illustration Translation[11]

2.3 Andrew Ng谈自监督学习
deeplearning.ai的创始人Andrew Ng加入人工智能播客[12],讨论的主题包括他早期从事ML的工作,AI的未来和AI教育,正确使用ML的建议,他的个人目标以及在2020年代应该关注ML技术。
Andrew解释了为什么他对自监督的表示学习感到非常兴奋。自监督式学习涉及一个学习问题,该问题旨在从数据本身获得监督,以利用大量未标记数据,这比纯净标记数据更常见。这些表示很重要,可用于处理下游任务,类似于BERT等语言模型中使用的任务。
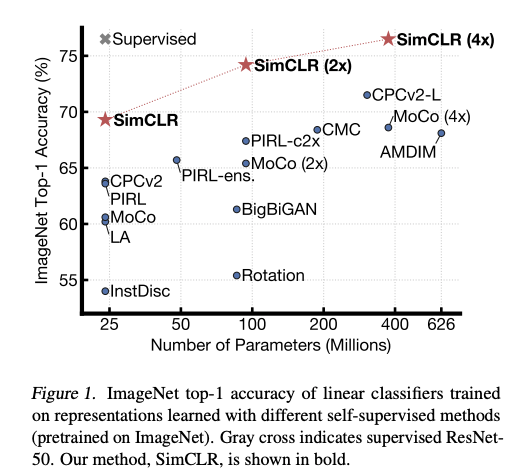
使用自监督学习来学习广义的视觉表示也引起了很大关注,这使模型在资源匮乏的环境中更加准确。例如,最近一种名为SimCLR[13]的方法(由Geoffrey Hinton领导)提出了一种视觉表示的对比自监督学习框架,以改善在不同环境下的图像分类结果,例如转移学习和半监督学习。
3、Tools and Datasets ⚙️
3.1 JAX libraries
JAX[14]是一个新库,结合了NumPy和自动微分功能,可以进行高性能ML研究。为了简化使用JAX构建神经网络的管道,DeepMind发布了Haiku[15]和RLax[16]。使用熟悉的面向对象编程模型,RLax简化了强化学习代理的实现,而Haiku简化了神经网络的构建。
3.2 处理维基百科数据的工具
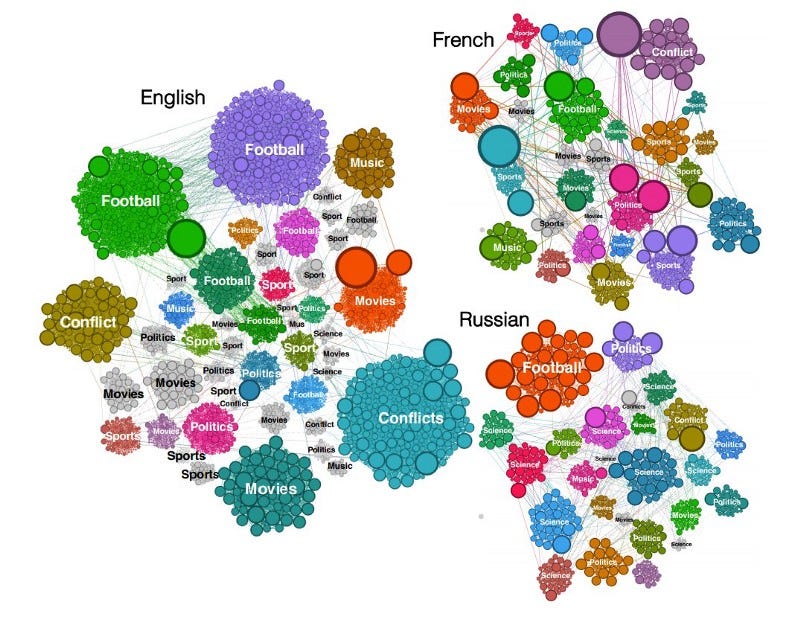
Sparkwiki[17] 是处理Wikipedia数据的工具。此版本是有趣的行为分析研究的众多努力的一部分,例如,捕获跨不同语言版本的Wikipedia的趋势和语言偏见[18]。作者发现,独立于语言,维基百科用户的浏览行为表明,他们倾向于在电影,音乐和体育等类别上拥有共同的兴趣,但是随着当地事件和文化特殊性的出现,差异变得更加明显。
3.3 Rust Tokenizers, DistilBERT base cased, Model cards
Hugging Face发行的新版Transformers[19]包括其快速分词器库的集成,该库旨在加速BERT,RoBERTa,GPT2等模型以及其他社区构建的模型。
3.4 夸夸语料
夸夸语料[20],来自豆瓣互相表扬组数据。
4、Ethics in AI 🚨
4.1 NLP和ML模型的道德考量
在NLP Highlights的新内容中[21],Emily Bender和主持人讨论了在学术界和实际使用情况下开发NLP模型和技术时的一些道德考量。讨论中的一些主题包括设计NLP任务,数据收集方法以及最终发布结果时的道德考虑。
除了上述所有考虑因素之外,AI社区中经常讨论的一个问题过于关注优化指标,这与AI旨在实现的目标背道而驰。Rachel Thomas和David Uminsky[22]讨论了通过对不同用例进行透彻分析而可能出错的地方。他们还提出了一个缓解该问题的简单框架,其中涉及多个指标的使用和组合,然后是那些直接受到该技术影响的人的参与。
5、Articles and Blog posts ✍️
5.1 The Annotated GPT-2
Aman Arora最近发表了一篇特别的博客文章,标题为“ The Annotated GPT-2[23]”,解释了基于Transformer的模型GPT-2的内部工作原理。他的方法受到The Annotated Transformer[24]的启发,采用了注释方法,通过代码和易于理解的解释来解释模型的重要部分。Aman付出了巨大的努力,使用PyTorch和Hugging Face的Transformers库重新实现OpenAI的GPT-2。这是出色的工作!

5.2 Beyond BERT?
Sergi Castella[25]对BERT以外的内容感兴趣。主要主题包括改善指标,Hugging Face的Transformers库如何支持研究,查看有趣的数据集,解压缩模型等。
5.3 矩阵压缩算子
TensorFlow博客发布了一篇博客文章,Matrix Compression Operator[26],解释了在深度神经网络模型中压缩矩阵背后的技术和重要性。矩阵压缩可以帮助构建更有效的微型模型,这些模型可以集成到较小的设备中,例如电话和家庭助理。通过低秩逼近和量化等方法专注于模型的压缩,这意味着我们无需牺牲模型的质量。
6、Education 🎓
6.1 NLP基础
NLP基础[27]从基础开始讲授NLP概念,同时分享最佳实践,重要参考,应避免的常见错误以及NLP的未来。包含一个Colab笔记本[28],该项目将在此github[29]维护。

6.2 数学基础课
Machine Learning Tokyo 将在3月8日主持一个远程在线讨论,其中回顾他们最近的在线学习课程中[30]涉及的章节。该小组以前研究过Marc Peter Deisenroth,Ado Faisal和Cheng Soon Ong所著的《机器学习数学》[31]一书章节。
6.3 书籍推荐
在上一部分中,我们讨论了矩阵压缩对于构建微型ML模型的重要性。如果你有兴趣了解有关如何为嵌入式系统构建更小的深度神经网络的更多信息,请查看Pete Warden和Daniel Situnayake撰写的这本名为TinyML[32]的出色著作。

另一本值得关注的有趣书籍是即将出版的题为“Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD[33]”,作者为Jeremy Howard和Sylvain Gugger。该书旨在提供必要的数学基础,以建立和训练模型来处理计算机视觉和NLP领域中的任务。

6.4 计算机科学自学指南
使用建议的教科书或视频讲座系列,以大致顺序学习以下所有九个主题,但理想情况下两者都学习。针对每个主题进行100-200小时的学习,然后在整个职业生涯中重温最爱favorites。另外在reddit上也有类似的讨论[34]。
7、Noteworthy Mentions ⭐️
Torchmeta[35]是一个是由Tristan Deleu创作的可以轻松使用相关的数据加载器进行元学习研究的库。
Manuel Tonneau撰写了一篇文章,仔细研究了语言建模中涉及的一些机制[36],包括贪婪和波束搜索以及原子核采样等主题。
MIT发布了名为“Introduction to Deep Learning[37]”的课程的完整提纲和课程表,其中包括已授课的视频, 他们的目标是每周发布视频讲座和幻灯片。
了解如何使用基于Transformer的方法在不到300行代码中训练用于命名实体识别(NER)的模型[38]。您可以在此处找到随附的Google Colab[39]。
本文参考资料
[1] self-distillation: https://arxiv.org/pdf/1503.02531.pdf
[2] Self-Distillation Amplifies Regularization in Hilbert Space: http://xxx.itp.ac.cn/abs/2002.05715
[3] The 2010s: Our Decade of Deep Learning / Outlook on the 2020s: http://people.idsia.ch/~juergen/2010s-our-decade-of-deep-learning.html
[4] Deep Learning for Symbolic Mathematics: https://arxiv.org/abs/1912.01412
[5] 《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》: https://arxiv.org/abs/2002.08155
[6] 如何使用人工智能(AI)来生成仿真器: https://www.sciencemag.org/news/2020/02/models-galaxies-atoms-simple-ai-shortcuts-speed-simulations-billions-times
[7] 论文提出了DENSE方法: https://arxiv.org/abs/2001.08055
[8] 神经结构搜索: https://en.wikipedia.org/wiki/Neural_architecture_search
[9] GANILLA: https://github.com/giddyyupp/ganilla
[10] 图像到图像翻译任务: https://paperswithcode.com/task/image-to-image-translation
[11] GANILLA: Generative Adversarial Networks for Image to Illustration Translation: https://arxiv.org/abs/2002.05638
[12] 人工智能播客: https://www.youtube.com/watch?v=0jspaMLxBig
[13] SimCLR: https://arxiv.org/abs/2002.05709
[14] JAX: https://github.com/google/jax
[15] Haiku: https://github.com/deepmind/dm-haiku
[16] RLax: https://github.com/deepmind/rlax
[17] Sparkwiki: https://github.com/epfl-lts2/sparkwiki
[18] 捕获跨不同语言版本的Wikipedia的趋势和语言偏见: https://arxiv.org/abs/2002.06885
[19] 新版Transformers: https://github.com/huggingface/transformers/releases/tag/v2.5.0
[20] 夸夸语料: https://github.com/xiaopangxia/kuakua_corpus
[21] NLP Highlights的新内容中: https://soundcloud.com/nlp-highlights/106-ethical-considerations-in-nlp-research-emily-bender
[22] Rachel Thomas和David Uminsky: https://arxiv.org/abs/2002.08512
[23] The Annotated GPT-2: https://amaarora.github.io/2020/02/18/annotatedGPT2.html
[24] The Annotated Transformer: https://nlp.seas.harvard.edu/2018/04/03/attention.html
[25] Sergi Castella: https://towardsdatascience.com/beyond-bert-6f51a8bc5ce1
[26] Matrix Compression Operator: https://blog.tensorflow.org/2020/02/matrix-compression-operator-tensorflow.html?linkId=82298016
[27] NLP基础: https://medium.com/dair-ai/fundamentals-of-nlp-chapter-1-tokenization-lemmatization-stemming-and-sentence-segmentation-b362c5d07684
[28] Colab笔记本: https://colab.research.google.com/drive/18ZnEnXKLQkkJoBXMZR2rspkWSm9EiDuZ
[29] 此github: https://github.com/dair-ai/nlp_fundamentals
[30] 在线学习课程中: https://www.meetup.com/Machine-Learning-Tokyo/events/268817313/
[31] 《机器学习数学》: https://mml-book.github.io/
[32] TinyML: https://tinymlbook.com/?linkId=82595412
[33] Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD: https://www.amazon.com/Deep-Learning-Coders-fastai-PyTorch/dp/1492045527
[34] reddit上也有类似的讨论: https://www.reddit.com/r/learnprogramming/comments/87j7fw/teach_yourself_computer_science_a_diy_curriculum/
[35] Torchmeta: https://arxiv.org/abs/1909.06576
[36] 语言建模中涉及的一些机制: https://creatext.ai/blog-posts/machine-text-writing-gpt2-beam-search?utm_medium=newsletter
[37] Introduction to Deep Learning: http://introtodeeplearning.com/
[38] 训练用于命名实体识别(NER)的模型: https://github.com/huggingface/transformers/blob/master/examples/ner/run_pl_ner.py
[39] 随附的Google Colab: https://colab.research.google.com/drive/184LPlygvdGGR64hgQl3ztqzZJu8MmITn