

Thanks to Kaiyuan (WeChat: NewBeeNLP) for this great translation.
欢迎来到船新栏目「NLP 简报」,本新闻简报的目的是让你不必花费太多时间就可以了解与 NLP 和 ML 有关的一些有趣和最新的故事。
如果想让自己有趣的研究/项目出现在 NLP 简报中,随时在公众号后台留言联系我
下面来看看第一期的内容
- 1、Publications 📙
- 1.1 用于乳腺癌筛查的AI系统
- 1.2 信息抽取
- 1.3 Improved recommendation
- 2、Creativity and Society 🎨
- 2.1 AI就业
- 3、Tools and Datasets ⚙️
- 3.1 一个极速分词器
- 3.2 用于搜索的ML&NLP
- 3.3 医学图像分析
- 4、Ethics in AI 🚨
- 4.1 ML社区的欺诈行为
- 4.2 机器翻译中的性别偏见
- 4.3 ML偏差与公正性
- 5、Articles and Blog posts ✍️
- 5.1 NLP shortfalls
- 5.2 NLP和ML2019年亮点
- 6、Education 🎓
- 6.1 Democratizing AI education
- 6.2 Top NLP and ML Books
- 6.3 使用核方法的机器学习
- 7、Noteworthy Mentions ⭐️
1、Publications 📙
1.1 用于乳腺癌筛查的 AI 系统
DeepMind 在 Nature 杂志上发表了一篇名为“International evaluation of an AI system for breast cancer screening[1]”的新论文。作者说,这项工作是关于在乳腺癌筛查方面超越人类专家的 AI 系统的评估。当前的 AI 系统是否真的可以实现这一点尚有争议,并且对于这种类型的系统及其评估方式一直存在批评。
1.2 信息抽取
Pankaj Gupta 公开发布了他的博士学位论文,题目为“Neural Information Extraction From Natural Language Text[2]”。主要讨论如何使用基于神经的方法有效地从自然语言文本中提取语义关系, 此类研究工作旨在促进构建结构化的知识库,该知识库可用于一系列下游 NLP 应用程序,例如 Web 搜索,问题解答以及其他任务。
1.3 Improved recommendations
MIT 和 IBM 的研究人员基于三种广泛使用的文本分析工具(主题建模,单词嵌入和最佳传输)的组合,开发了一种用于分类,显示和搜索相关文档的方法(于去年在 NeurIPS 上发布)。该方法还为文档排序提供了有希望的结果。此类方法适用于需要对大规模数据(例如搜索和推荐系统)进行改进和更快建议的各种场景和应用。
2、Creativity and Society 🎨
2.1 AI 就业
Stanford 2019 年 AI 指数报告[3]表明,对 AI 从业者的需求更多。但是,与 AI 相关的工作有很多方面,例如职业转变和面试仍然没有适当定义。
在博客”Shifting Careers to Autonomous Vehicles[4]”中,Vladimir Iglovivok 详细介绍了他的职业生涯和 ML 冒险,从构建传统的推荐系统到构建壮观的计算机视觉模型(赢得了 Kaggle 竞赛)。他现在在 Lyft 从事自动驾驶汽车的工作,但是到达那里的旅程并不容易。
如果 n 真的对 AI 事业感兴趣并且很认真,Andrew Ng 的公司 deeplearning.ai 成立了 Workera,该公司专门致力于帮助数据科学家和机器学习工程师从事 AI 事业。可以在此处获取关于Workra 的官方报告[5]。
3、Tools and Datasets ⚙️
3.1 一个极速分词器
Hugging Face 是一家的 NLP 初创公司,拥有开源的 Tokenizers,这是一种可在现代 NLP pipeline 中使用的超快速的分词器,可以查看Tokenizers GitHub 库[6]以获取有关如何使用 Tokenizer 的文档。
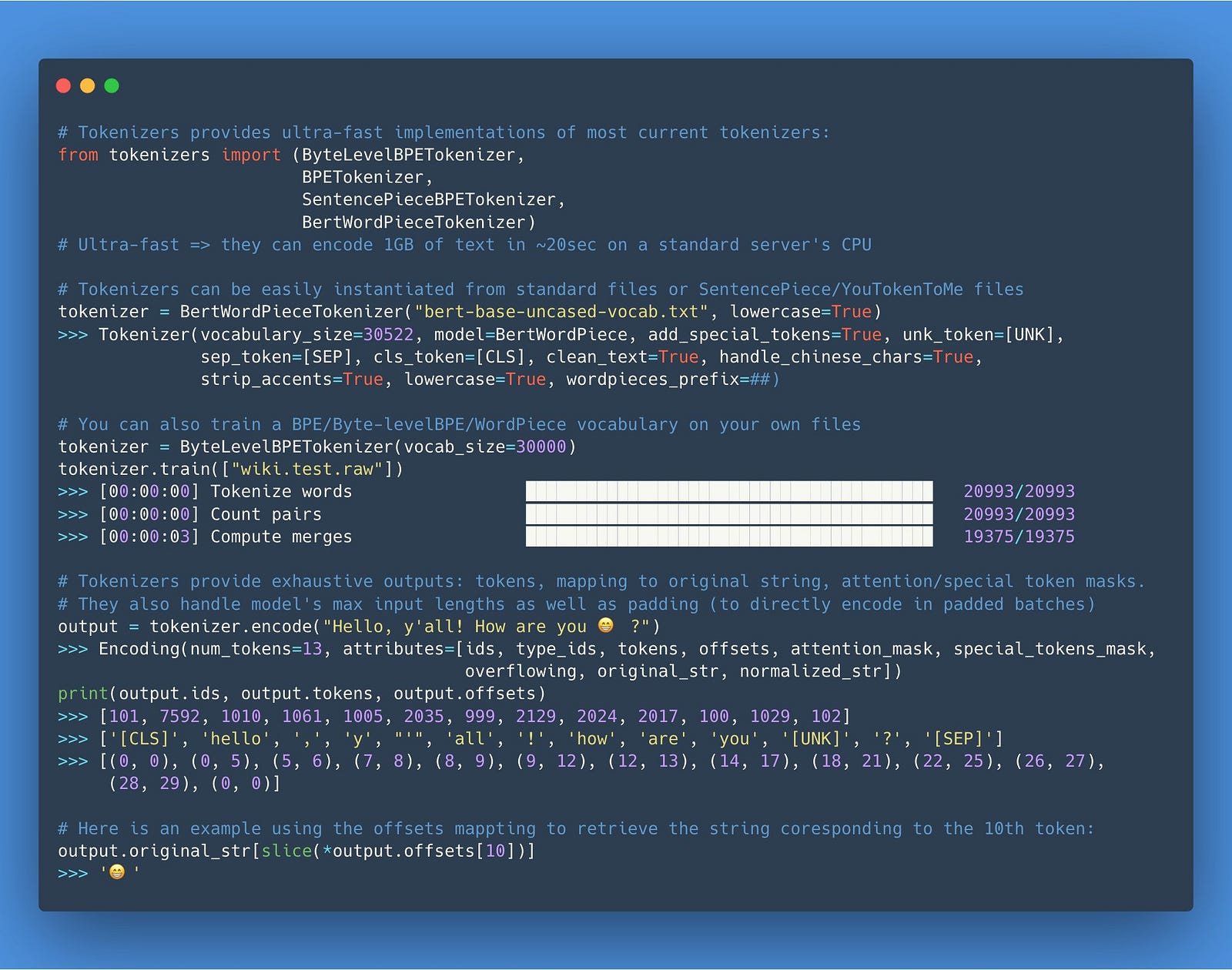
TensorFlow 2.1 合并了一个新的TextVectorization 层[7],你可以轻松处理原始字符串并有效地执行文本 normalization,tokenization,n-gram 生成和词汇索引。点击查看Chollet 的 Colab 笔记[8]本,演示如何使用该功能进行端到端文本分类。
3.2 用于搜索的 ML&NLP
去年,NLP 取得了巨大进步,其中一个领域是一系列改进和新的研究方向。搜索可能是可能从迁移学习 NLP 中受益的那些领域之一。
尽管搜索属于信息检索领域,但仍有机会构建使用现代 NLP 技术(例如来自基于BERT[9]的基于变压器的模型的上下文表示)来改进语义搜索的搜索引擎。Google 在几个月前发布了一篇博客文章,讨论了他们如何利用 BERT 模型来改善和理解搜索[10]。
如果您对如何将上下文化表示形式应用于使用 Elasticsearch 和 TensorFlow 等开放式搜索技术的搜索感到好奇,则可以查看”Elasticsearch meets BERT”[11]或”Building a Search Engine with BERT and TensorFlow”[12]。
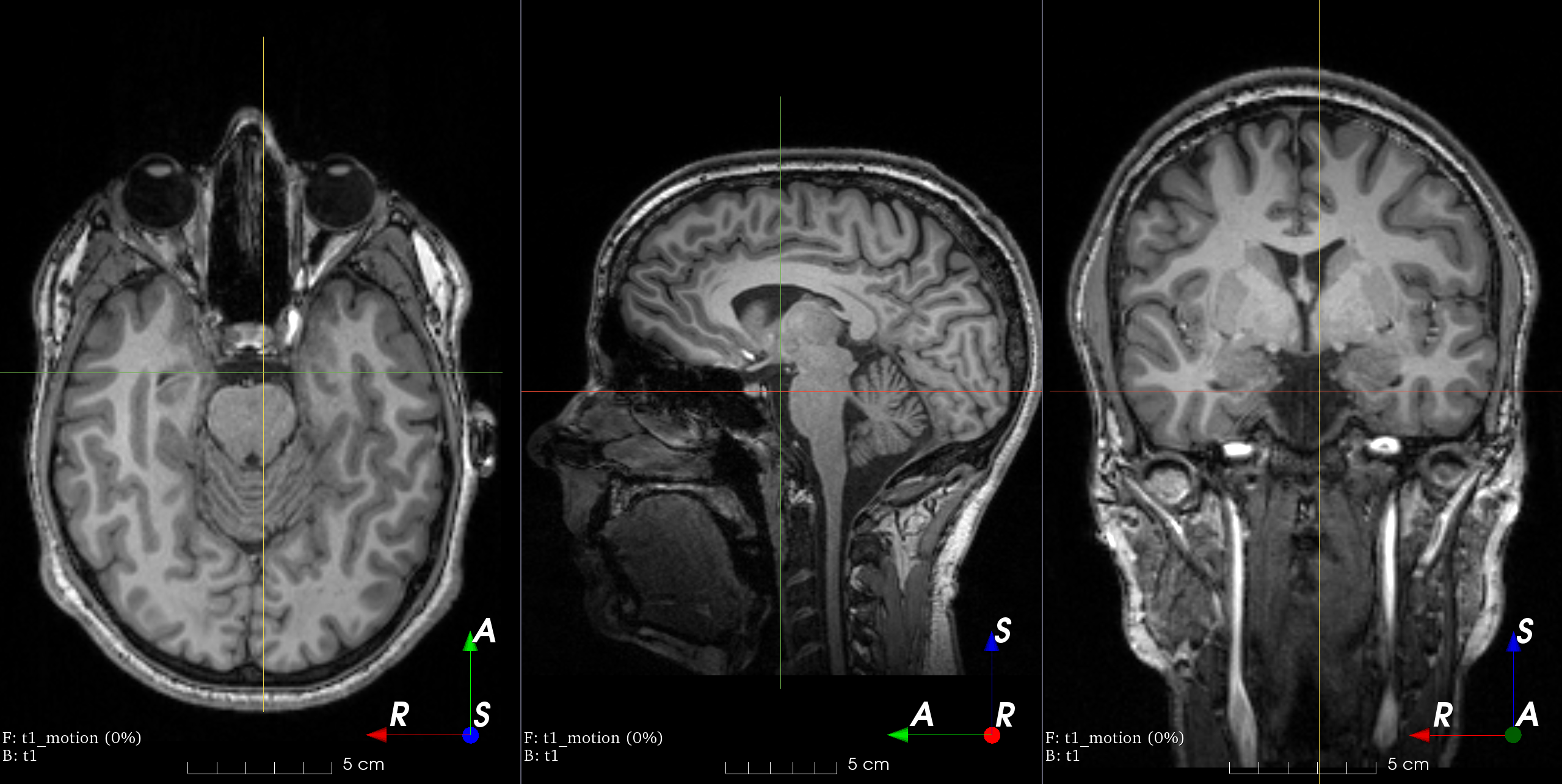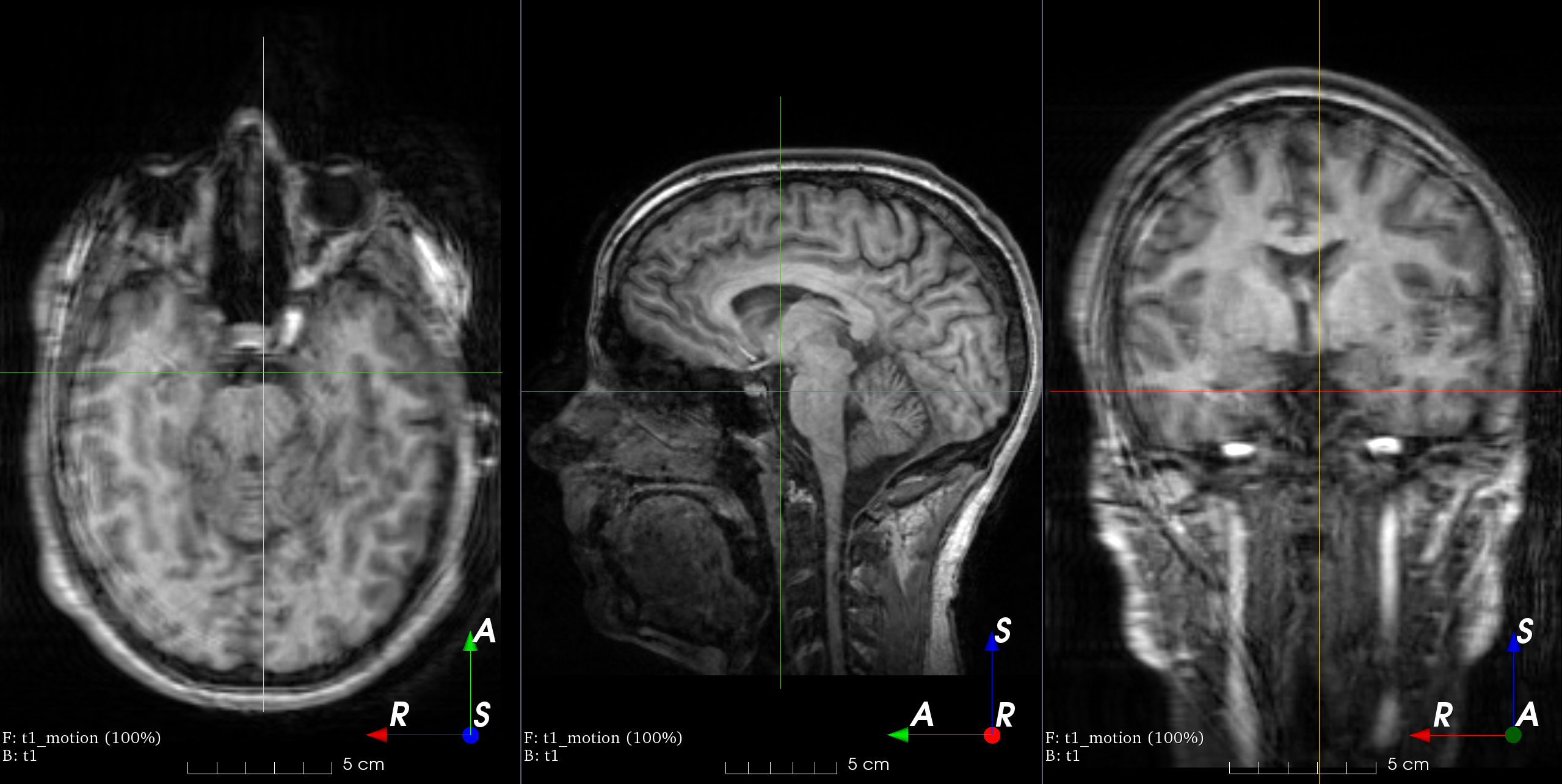
3.3 医学图像分析
TorchIO[13]是基于流行的深度学习库 PyTorch 的 Python 软件包。TorchIO 提供的功能可轻松高效地读取和采样 3D 医学图像。功能包括用于数据扩充和预处理的空间变换。
4、Ethics in AI 🚨
4.1 ML 社区的欺诈行为
Kaggle 比赛的第一名优胜者因欺诈活动而被取消参赛资格,其队伍使用了聪明但不负责任和不可接受的策略来赢得比赛的第一名。原文”PetFinder.my Contest: 1st Place Winner Disqualified[14]”重点介绍了机器学习社区想要缓解的许多严重且无法接受的行为,正确和道德地使用机器学习技术是前进的唯一方法。
4.2 机器翻译中的性别偏见
关于机器翻译系统是否反映性别偏见的主题,一组研究人员发表了这篇出色的论文,”Assessing Gender Bias in Machine Translation – A Case Study with Google Translate[15]”,提出了使用 Google 翻译的案例研究。作者声称的一项发现是,Google 翻译“表现出强烈的男性违约倾向,特别是在与性别分布失衡有关的领域,例如 STEM 工作。”
4.3 ML 偏差与公正性
如果您想让所有人都了解 AI 伦理和公平,那么这是一个由Timnit Gebru[16]主持,由 TWIML 主持的不错的播客。
Timnit 是 ML 公平性方面的杰出研究者,他与 Eun Seo Jo 一起发表了一篇论文,”Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning”[17]他们确定了档案中文档收集实践的五种关键方法,这些方法可以为社会文化 ML 中的数据收集提供更可靠的方法。这可能会导致跨学科合作研究获得更系统的数据收集方法。
Sina Fazelpour 和 Zachary Lipton 最近发表了一篇论文,”fairness-non-ideal-fazelpour-lipton-2020[18]”,他们认为,由于我们非理想世界的产生方式的性质,基于理想思维的公平 ML 可能会导致误导政策和干预措施。实际上,他们的分析表明“提出的公平 ML 算法的缺点反映了理想方法所面临的广泛问题。”
5、Articles and Blog posts ✍️
5.1 NLP shortfalls
Benjamin Heinzerling 在 The Gradient 中发表了一篇有趣的文章,讨论了NLP 不足的领域[19],例如论点理解和常识推理。本杰明参考了 Nivin&Kao 的最新论文,”Probing Neural Network Comprehension of Natural Language Arguments[20]”,该论文挑战和质疑了转移学习和语言模型对高级自然语言理解的能力。
5.2 NLP 和 ML2019 年亮点
对于新的一年,报告”NLP Year in Review — 2019[21]”,记录了 2019 年的一些最有趣的 NLP 和 ML 亮点。
塞巴斯蒂安·鲁德(Sebastian Ruder)最近还写了一篇精彩而详尽的博客文章[22],介绍了十大关于 ML 和 NLP 的研究方向,他认为这很有影响力 在 2019 年。列表中包括诸如通用无监督预训练,应用于科学的 ML 和 NLP,增强预训练模型,高效和远程 Transformers 等主题。
Google AI 研究会发布他们一年来进行的研究的摘要以及他们正在关注的未来研究方向,”Google Research: Looking Back at 2019, and Forward to 2020 and Beyond[23]”。
6、Education 🎓
6.1 Democratizing AI education
为了使 AI 教育民主化并向大众普及 AI 技术的影响,赫尔辛基大学与 Reaktor 合作发布了涵盖 AI 基础知识的精彩免费课程。受欢迎的课程称为“Elements of AI[24]”,包括诸如 AI 伦理学,AI 哲学,神经网络,朴素贝叶斯规则等主题,以及其他基础主题。
Stanford CS224N 再次推出了流行的“Natural Language Processing with Deep Learning[25]”课程。该课程于今年 1 月 7 日正式开始,因此,如果您想学习该课程,请访问其网站以获取完整的课程提纲,幻灯片,视频,阅读建议等。
6.2 Top NLP and ML Books
关于一些NLP 和 ML 领域书籍推荐[26]。
6.3 使用核方法的机器学习
诸如 PCA 和 K-means 之类的核方法已经存在了很长一段时间,这是因为它们已成功应用于各种应用,例如图形和生物序列。查看这套涵盖了各种Kernel Methods[27]及其内部工作原理的综合幻灯片。这也是一个由 Francis Bach 维护很棒的博客,”Are all kernels cursed?[28]”,讨论了内核方法和其他机器学习主题。
7、Notable Mentions ⭐️
另外还有一些有趣的研究/项目:
-
John Langford 的博客[29],讨论机器学习理论;
-
许多行业的面向机器学习的技术已经使用梯度增强机器多年了。看看这篇文章[30],其中介绍了一个用于应用梯度增强的库 XGBoost。
-
如果你对学习如何设计和构建基于机器学习的应用程序并将其投入生产感兴趣,那么Emmanuel Ameisen[31]的书籍可以帮助你。
本文参考资料
[1] International evaluation of an AI system for breast cancer screening: https://www.nature.com/articles/s41586-019-1799-6
[2] Neural Information Extraction From Natural Language Text: https://www.researchgate.net/publication/336739252_PhD_Thesis_Neural_Information_Extraction_From_Natural_Language_Text
[3] Stanford 2019 年 AI 指数报告: https://hai.stanford.edu/sites/g/files/sbiybj10986/f/ai_index_2019_report.pdf
[4] Shifting Careers to Autonomous Vehicles: https://towardsdatascience.com/how-i-found-my-current-job-3fb22e511a1f
[5] Workra 的官方报告: https://workera.ai/candidates/report
[6] Tokenizers GitHub 库: https://github.com/huggingface/tokenizers
[7] TextVectorization 层: https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/TextVectorization
[8] Chollet 的 Colab 笔记: https://colab.research.google.com/drive/1RvCnR7h0_l4Ekn5vINWToI9TNJdpUZB3
[9] BERT: https://arxiv.org/abs/1810.04805
[10] 利用 BERT 模型来改善和理解搜索: https://www.blog.google/products/search/search-language-understanding-bert/
[11] Elasticsearch meets BERT: https://towardsdatascience.com/elasticsearch-meets-bert-building-search-engine-with-elasticsearch-and-bert-9e74bf5b4cf2
[12] Building a Search Engine with BERT and TensorFlow: https://towardsdatascience.com/building-a-search-engine-with-bert-and-tensorflow-c6fdc0186c8a
[13] TorchIO: https://github.com/fepegar/torchio
[14] PetFinder.my Contest: 1st Place Winner Disqualified: https://www.kaggle.com/c/petfinder-adoption-prediction/discussion/125436
[15] Assessing Gender Bias in Machine Translation – A Case Study with Google Translate: https://arxiv.org/abs/1809.02208
[16] Timnit Gebru: https://twimlai.com/twiml-talk-336-trends-in-fairness-and-ai-ethics-with-timnit-gebru/
[17] Lessons from Archives: Strategies for Collecting Sociocultural Data in Machine Learning: https://arxiv.org/abs/1912.10389
[18] fairness-non-ideal-fazelpour-lipton-2020: http://zacklipton.com/media/papers/fairness-non-ideal-fazelpour-lipton-2020.pdf
[19] NLP 不足的领域: https://thegradient.pub/nlps-clever-hans-moment-has-arrived/
[20] Probing Neural Network Comprehension of Natural Language Arguments: https://www.aclweb.org/anthology/P19-1459/
[21] NLP Year in Review — 2019: https://medium.com/dair-ai/nlp-year-in-review-2019-fb8d523bcb19
[22] 精彩而详尽的博客文章: https://ruder.io/research-highlights-2019/
[23] Google Research: Looking Back at 2019, and Forward to 2020 and Beyond: https://ai.googleblog.com/2020/01/google-research-looking-back-at-2019.html
[24] Elements of AI: https://www.elementsofai.com/
[25] Natural Language Processing with Deep Learning: http://web.stanford.edu/class/cs224n/
[26] NLP 和 ML 领域书籍推荐: https://twitter.com/omarsar0/status/1214547402838986754?s=20
[27] Kernel Methods: http://members.cbio.mines-paristech.fr/~jvert/svn/kernelcourse/slides/master2017/master2017.pdf
[28] Are all kernels cursed?: https://francisbach.com/cursed-kernels/
[29] John Langford 的博客: https://hunch.net/
[30] 这篇文章: https://opendatascience.com/xgboost-enhancement-over-gradient-boosting-machines/?utm_campaign=Learning%20Posts&utm_content=111061559&utm_medium=social&utm_source=twitter&hss_channel=tw-3018841323
[31] Emmanuel Ameisen: https://www.amazon.com/Building-Machine-Learning-Powered-Applications/dp/149204511X/