

Seja muito bem-vindo à 10ª edição da NLP Newsletter. Nós esperamos que todos estejam bem e se mantendo seguros. Essa edição cobre tópicos como melhores práticas envolvendo Modelos de Linguagem, reprodutibilidade em ML e privacidade e segurança em NLP.
Atualizações da dar.ai 🔬🎓⚙️
- Com o intuito de ajudar na análise exploratória do COVID-19 Open Research Dataset e na obtenção de insights a partir dessa literatura, nós publicamos um notebook com os passos para a implementação de uma aplicação simples de busca por similaridade textual utilizando ferramentas de código-aberto e modelos de linguagem pré-treinados publicamente disponíveis.
- Nós realizamos um treinamento virtual na Open Data Science Conference na semana passada, com o tema Deep Learning for Modern NLP. Você pode acessar os materiais aqui.
- Também na semana passada, nós publicamos dois artigos bem interessantes, numa colaboração com membros da nossa comunidade. Um dos trabalhos aborda unsupervised progressive learning, um problema que envolve um agente que analisa uma sequência de vetores de dados não anotados (fluxo de dados) e aprende representações a partir da mesma. O segundo trabalho resume uma abordagem para Citation Intent Classification (que consiste em identificar porquê um autor citou outro trabalho) utilizando o modelo ELMo.
- Nós publicamos recentemente um notebook que fornece ideias para o ajuste fino de modelos de linguagem pré-treinados para a tarefa de classificação de emoções.
Pesquisas e Publicações 📙
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization
No início dessa semana, pesquisadores da Google AI e da DeepMind publicaram um interessante benchmark multi-tarefa denominado XTREME, que busca encorajar a avaliação das capacidades de generalização em diferentes idiomas de modelos de linguagem que aprendem representações multilíngues. O benchmark conta com 40 idiomas e 9 tarefas, que requerem entendimento sobre diferentes níveis de significado, tanto do ponto de vista sintático quanto semântico. O trabalho fornece bases para comparações utilizando modelos estado-da-arte para representações multilíngues, como o mBERT, XML e o MMTE.
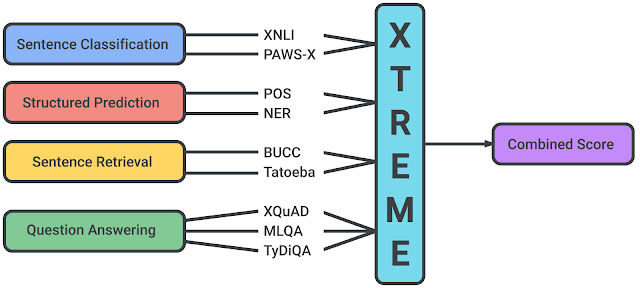
Fonte: Google AI Blog
Evaluating Machines by their Real-World Language Use
Foi demonstrado que modelos de linguagem apresentam um desempenho relativamente bom em diversas tarefas, como question answering e sequence labeling. Entretanto, um novo artigo propõe um framework e benchmark para melhor avaliar se modelos de linguagem (LMs) conseguem desempenhar bem seu papel com o uso de linguagem do mundo real em situações mais complexas (por exemplo, gerar conselhos proveitosos para o cenário atual do mundo). Resultados empíricos mostraram que modelos do estado-da-arte atual, como o T5, geram conselhos úteis como os escritos por humanos em apenas 9% dos casos. Essas observações apontam as deficiências dos LMs no que diz respeito a entender e modelar conhecimentos de mundo e do senso comum.
Give your Text Representation Models some Love: the Case for Basque
É possível que modelos monolíngues (como os word embeddings do FastText e o BERT) treinados em grandes bases de dados de idiomas específicos produzam melhores resultados que alternativas multilíngues? Num artigo recente, pesquisadores estudaram o desempenho de diversos modelos desse tipo utilizando uma grande base de dados para a língua basca. Os resultados indicaram que modelos monolíngues podem de fato produzir melhores resultados em tarefas como classificação de tópicos, de sentimentos e PoS tagging para esse idioma. Seria muito interessante verificar se o comportamento se repete para outros idiomas e quais resultados interessantes e novos desafio podem surgir.
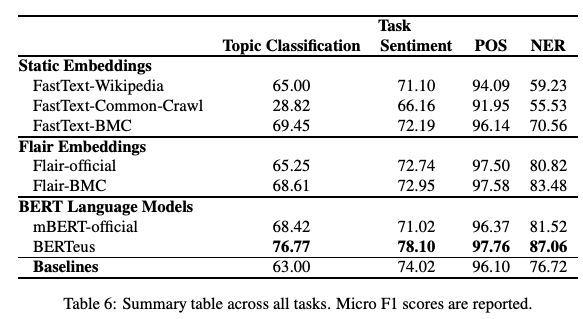
Figura extraída de Agerri et al. (2020)
Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
Numa edição anterior da Newsletter, nós apresentamos o SimCLR, método desenvolvido pela Google AI que propõe um framework para contrastive self-supervised learning de representações visuais, com o objetivo de melhorar os resultados da tarefa de classificação de imagens em diferentes cenários, como transfer-learning ou aprendizado semi-supervisionado, utilizando bases não-anotadas. Os resultados obtidos demonstraram que a abordagem alcança resultados estado-da-arte no ImageNet utilizando apenas 1% de dados anotados, o que também é um indicativo das possíveis vantagens do método em cenários com escassez de dados.
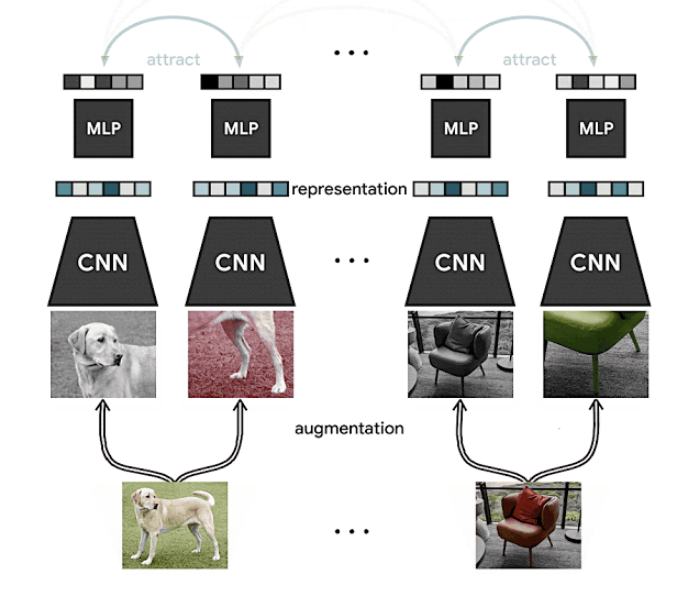
Fonte: Google AI Blog
Vale mencionar que o aprendizado auto-supervisionado (self-supervised learning) é um dos tópicos mais quentes na área atualmente. Se você tem interesse em saber mais, confira:
- Computers Already Learn From Us. But Can They Teach Themselves?
- The Illustrated Self-Supervised Learning
- Self-supervised learning and computer vision
Byte Pair Encoding is Suboptimal for Language Model Pretraining
Kaj Bostrom and Greg Durrett publicaram um trabalho onde foi investigado se o Byte Pair Encoding (BPE), um algoritmo para tokenização habitualmente utilizado, é a estratégia ótima para o treinamento de modelos de linguagem. Os autores propuseram uma avaliação direta do impacto da tokenização no desempenho desses modelos, o que, segundo eles, é raramente examinado, como observado na literatura. Para verificar isso, LMs foram treinados do zero em experimentos controlados, empregando diferentes técnicas de tokenização, a saber, Unigram e BPE. Após isso, os modelos pré-treinados foram testados em diversas tarefas. Os resultados mostraram que o desempenho utilizando a estratégia Unigram se equiparou e até mesmo foi superior ao BPE.
Longformer: The Long-Document Transformer
Pesquisadores do Allen AI publicaram um novo modelo baseado no Transformer, denominado Longformer, desenvolvido visando um desempenho mais eficiente em textos longos. Como já é conhecido, uma das limitações de modelos baseados no Transformer é que eles são computacionalmente custosos, devido à maneira como a operação de self-attention escala (quadraticamente com o tamanho da sequência), limitando assim a utilização de contextos mais longos. Recentemente, várias alternativas como o Reformer e o Sparse Transformers foram propostas, visando possibilitar a aplicação dessa classe de modelos para documentos maiores. O Longformer combina modelagem a nível de caractere e self-attention (uma mistura do mecanismo de atenção local e global) para requerer menos memória e demonstra sua eficiência na modelagens de textos longos. Os autores também mostraram que o seu modelo pré-treinado supera outros métodos quando aplicados à tarefas a nível de documento, como question answering e classificação de texto.
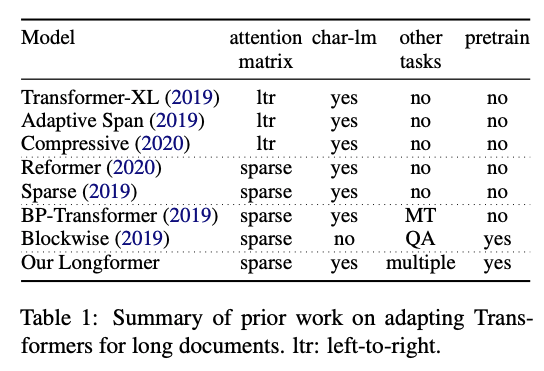
Figura extraída de Beltagy et al. (2020)
Criatividade, Ética e Sociedade 🌎
Reprodutibilidade em ML
- A questão da reprodutibilidade vem sendo discutida ativamente pelas comunidades de Aprendizado de Máquina. Com o intuito de encorajar uma ciência mais aberta, transparente e acessível, diversos esforços vêm sendo realizados a favor dela. Se você quiser entender como está essa questão no campo de ML, confira essa publicação feita por Joelle Pineau, dentre outros.
- Recentemente, e inspirado por esses esforços, o time do Papers With Code (que agora fazem parte do grupo de IA do Facebook) realizaram uma postagem explicando uma checklist de reprodutibilidade bem útil, com o objetivo de “facilitar pesquisas reprodutíveis apresentadas nas principais conferências de ML” (em tradução livre). A checklist avalia os códigos disponibilizados nos seguintes aspectos:
-
Dependências: O repositório apresenta informações sobre as dependências ou instruções sobre como preparar o ambiente de desenvolvimento?
-
Códigos de treinamento: O repositório fornece uma maneira de treinar o(s) modelo(s) descritos no artigo?
-
Códigos de Avaliação: O repositório fornece um código para calcular o desempenho do(s) modelo(s) treinado(s) ou rodar os experimentos neles?
-
Modelos pré-treinados: O repositório fornece acesso gratuito aos parâmetros do modelo pré-treinado?
-
Resultados: O repositório fornece uma tabela/gráfico com os principais resultados e o código para reproduzir esses resultados?

Fonte: Papers with Code
- Ainda nessa questão de ciência aberta e reprodutibilidade, aqui está uma postagem interessante, feita por um pesquisador de NLP, oferecendo uma recompensa pela reprodução de resultados de um artigo que outro pesquisador não conseguiu reproduzir.
Privacidade e Segurança em NLP
Será que um modelo de linguagem pré-treinado pode ser roubado, ou sua exposição para uso via API pode trazer implicações de segurança? Em um novo artigo, pesquisadores testaram APIs de modelos baseados no BERT para implicações de segurança, no que diz respeito à utilização de consultas para roubo do modelo. Resumidamente, eles observaram que um adversário pode roubar um modelo refinado apenas utilizando sequências de palavras sem sentido e refinando o seu próprio modelo com as predições do modelo-alvo. Leia mais sobre ataques de extração de modelos aqui.
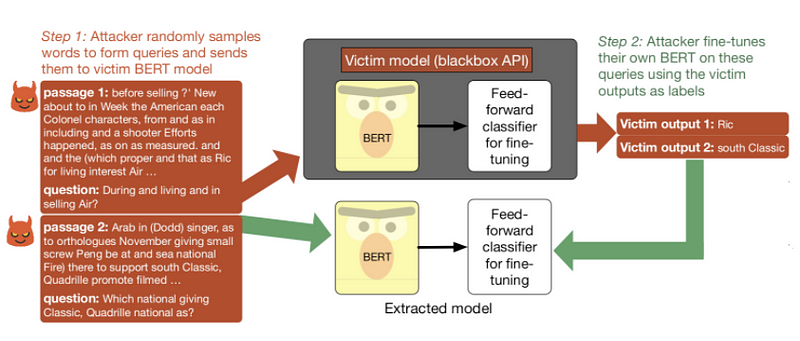
Sistema de extração de modelos aplicado a um modelo-alvo treinado no SQuAD (Fonte).
Outro artigo interessante, aceito na ACL 2020, investigou se modelos de linguagem pré-treinados são suscetíveis a ataques. Os autores desenvolveram um método de “envenenamento” que é capaz de injetar vulnerabilidades nos parâmetros pré-treinados, tornando os modelos vulneráveis à ameaças. Devido a essas vulnerabilidades, é possível mostrar que esses modelos expõem backdoors que podem ser aproveitadas por invasores com o intuito de manipular as predições do modelo, simplesmente injetando qualquer palavra-chave arbitrária. Para testar esse comportamento, modelos pré-treinados foram utilizados em tarefas que envolviam bases de dados “corrompidas” com palavras-chave específicas, feitas para forçar o modelos a classificar exemplos de maneira incorreta.
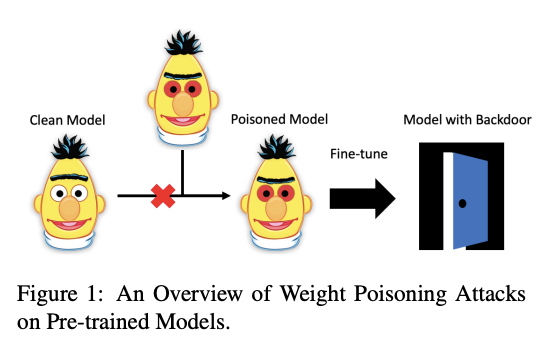
Figura extraída de Kurita et al. (2020)
Uma série de pesquisas e aplicações baseadas em IA para COVID-19
-
A COVID-19 provou-se um dos maiores desafios dos tempos modernos. Pesquisadores de todas as partes do mundo tentam encontrar maneiras de contribuir e ajudar a entender a doença, fornecendo desde ferramentas de busca até bases de dados. Sebastian Ruder publicou uma edição dedicada da sua Newsletter destacando alguns projetos interessantes que pesquisadores de IA vêm desenvolvendo.
-
Ainda nesse assunto, pesquisadores do Allen AI irão discutir a agora popular base de dados COVID-19 Open Research Dataset (CORD-19) num meetup virtual que acontecerá no final desse mês (27/04/2020).
-
A CORD-19 vem sendo utilizada por muitos pesquisadores para a construção de aplicações impulsionadas por NLP, como ferramentas de busca. Confira esse artigo recente para um exemplo de implementação dessas ferramentas que auxiliam pesquisadores a obter insights rápidos relacionados à CORD-19 a partir de resultados reportados em artigos de especialistas. De acordo com os autores, tais ferramentas ajudam em tomadas de decisão baseadas em evidências.
-
ArCOV-19 é uma base de dados de tweets em árabe sobre COVID-19, que cobre um período de 27 de janeiro até 31 de março de 2020 (e a coleta continua!). É a primeira base dados publicamente disponível do Twitter Árabe cobrindo a pandemia do COVID-19, onde estão inclusos cerca de 748K tweets populares (de acordo com o critério de busca do próprio Twitter) junto com as redes de propagação do sub-conjunto mais popular de postagens. As redes incluem tanto retweets quando threads de respostas. ArCOV-19 é projetado para permitir a pesquisa em diversas áreas, como NLP, Ciência de Dados, Computadores e Sociedade, entre outras.
Ferramentas e Bases de Dados ⚙️
Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence
Mesmo não sendo uma ferramenta ou base de dados por si só, esse excelente artigo, com autoria de Sebastian Raschka, Joshua Patterson, e Corey Nolet, fornece uma visão geral compreensiva de alguns dos principais desenvolvimentos em termos de tendências tecnológicas em ML, com foco na linguagem de programação Python.
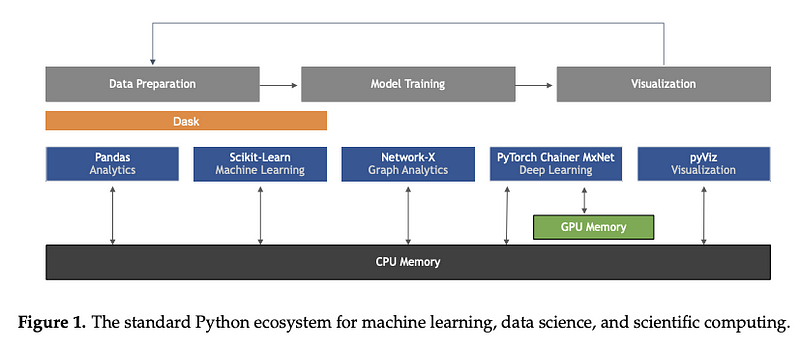
Figura extraída de Raschka et al. (2020)
Interpretabilidade e Explicabilidade em ML
A Hugging Face disponibilizou uma ferramenta de visualização denominada exBERT, que nos permite visualizar as representações aprendidas por modelos de linguagem como o BERT e RoBERTa. Essa funcionalidade foi integrada à página de modelos, com o objetivo de prover um melhor entendimento sobre como os modelos de linguagem estão aprendendo, assim como quais propriedades são potencialmente codificadas por eles nessas representações.
A OpenAI disponibilizou recentemente uma aplicação web chamada Microscope que contém uma coleção de visualizações obtidas de camadas e neurônios de diversos modelos de visão computacional que são comumente estudados no contexto de interpretabilidade. O objetivo principal é facilitar a análise e compartilhamento de insights interessantes, obtidos a partir das características aprendidas pelas redes neurais, assim como viabilizar um melhor entendimento dos mesmos.
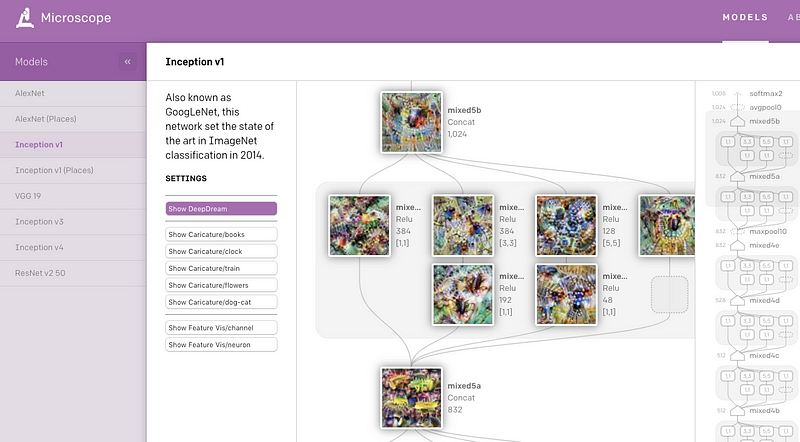
CloudCV: ViLBERT Multi-Task Demo
No edição anterior da NLP Research Highlights, nós apresentamos o ViLBERT multi-tarefa, que é um método para o aprimoramento de vision-and-language models que pode ser utilizado em recuperação de imagens baseada em descrições e visual question answering (VQA). Agora, os autores disponibilizaram uma aplicação web para teste dos modelos em 8 tarefas diferentes de linguagem e visão computacional, como VQA e pointing question answering.
A Twitter Dataset of 150+ million tweets related to COVID-19 for open research
Devido à relevância da pandemia global de COVID-19, pesquisadores estão liberando uma base de dados com tweets relacionados a doença. Desde a primeira versão disponibilizada, dados adicionais de novos colaborados foram adicionados, permitindo o crescimento da base até seu volume atual. A aquisição dedicada de dados começou em 11 de março, com mais de 4 milhões de tweets por dia.
A tiny autograd engine
Andrej Karpathy disponibilizou recentemente uma biblioteca conhecida como micrograd, que permite a construção e treinamento de redes neurais utilizando uma interface simples e intuitiva. Na verdade, ele escreveu a biblioteca completa com aproximadamente 150 linhas de código, o que, segundo ele, é a mais compacta ferramenta de diferenciação automática que existe. Idealmente, bibliotecas como essa podem ser utilizadas para fins educacionais.
Artigos e Postagens ✍️
The Transformer Family and Recent Developments
Numa nova e oportuna postagem, Lilian Weng resumiu alguns dos recentes avanços no modelo Transformer. O artigo utiliza uma notação amigável, apresenta uma revisão da literatura bem como as últimas melhorias propostas, como atenção com contextos mais longos (Transformer XL) e redução nos requisitos computacionais e de memória.
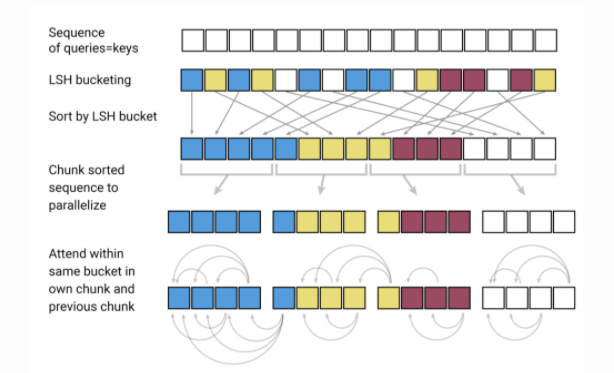
A compressão de modelos é uma importante área de pesquisa em NLP, devido à natureza e ao tamanho de modelos de linguagem pré-treinados. Idealmente, conforme os modelos produzem novos resultados estado-da-arte para as mais diferentes tarefas de NLP, torna-se importante reduzir seus requisitos computacionais, tornando sua utilização viável em produção. Madison May publicou recentemente outro excelente artigo trazendo um visão geral de alguns métodos utilizados para compressão de modelos para NLP. Alguns dos tópicos principais incluem poda, otimização dos grafos de computação, destilação de conhecimento, substituição progressiva de módulos, entre outros.
Educação 🎓
Guest Lecture on Language Models by Alec Radford
Se você tem interesse em conhecer os aspectos teóricos dos métodos utilizados para o aprendizado de modelos de linguagem como o CBOW, Word2Vec, ELMo, GPT, BERT, ELECTRA, T5 e GPT, então você deveria conferir essa excelente aula do Alec Radford (pesquisador na OpenAI). Ela faz parte de um curso em andamento, lecionado pelo Pieter Abbeel, sobre técnicas de aprendizado não-supervisionado com redes neurais profundas.
Python Numpy Tutorial (with Jupyter and Colab)
O popular curso online de Stanford, Convolutional Neural Network for Visual Recognition, agora inclui um link para um notebook do Colab com o seu guia introdutório ao NumPy, que apresenta um passo a passo extenso mas muito interessante para iniciantes.
New mobile neural network architectures
Interessado em construir modelos de redes neurais para dispositivos móveis ou de borda? Então essa postagem bem acessível pode te ajudar! O artigo cobre diversas configurações de redes e inclui testes de velocidade.
Data-Driven Sentence Simplification: Survey and Benchmark
A tarefa de Sentence simplification (simplificação de frases, numa tradução livre), possui a finalidade de modificar uma frase de modo a torná-la mais fácil de ler e entender. Essa coletânea foca em abordagens que tentam aprender a simplificar utilizando uma base de pares de sentenças em inglês, contendo as versões originais e simplificadas, que é um paradigma dominante nos dias atuais. Também está incluso um benchmark dos diferentes métodos em diversas bases de dados, que os compara e destaca os pontos fortes e fracos de cada um deles.
Tópicos Avançados em Aprendizado de Máquina
Yisong Yue publicou todas as vídeo-aulas do curso Data-Driven Algorithm Design. São cobertos tópicos de ML como otimização Bayesiana, computação diferenciável e imitation learning.
Menções Honrosas ⭐️
Acesse as edições anteriores da NLP Newsletter aqui (última edição em PT-BR).
Harvard está oferecendo uma ótima seleção de cursos self-paced de maneira gratuita!
ARBML fornece implementações de diversos projetos de NLP e ML para a língua árabe, incluindo experiências em tempo real utilizando diversas interfaces, como a web, linha de comando e notebooks.
NLP Dashboard é uma aplicação web de NLP interessante, que oferece Reconhecimento de Entidades Nomeadas e análises estatísticas de textos e notícias. Construída utilizando spaCy, Flask e Python.
Caso você ainda não conheça, Connor Shorten mantém um canal no YouTube bastante informativo, onde ele resume artigos de ML bem recentes e interessantes. São apresentados os detalhes importantes de cada trabalho através de um excelente e conciso resumo. Connor também começou um podcast com outros grandes pesquisadores e educadores da área.
Aqui está um repositório impressionante e bem completo que apresenta as melhoras práticas e recomendações (via notebooks e explicações) para diversos cenários de NLP, como classificação de texto, entailment (estabelecer relações lógicas, como implicação e contradição, entre textos), sumarização de texto, question answering, etc.
Se você conhece bases de dados, projetos, postagens, tutoriais ou artigos que gostaria de ver na próxima edição da Newsletter, por favor nos envie utilizando esse formulário.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada!