

Publicações 📙
Turing-NLG: A 17-billion-parameter language model by Microsoft
O Turing Natural Language Generation (T-NLG) é um modelo de linguagem com 17 bilhões de parâmetros proposto pelo grupo de pesquisa em Inteligência Artificial da Microsoft. O T-NLG é composto por 78 camadas, baseado na arquitetura dos Transformers, que superou o estado da arte anterior (atribuido ao Megatron-LM da Nvidia) considerando a Perplexidade na base de dados WikiText-103. O modelo foi testado em diversas tarefas, como question answering e sumarização abstrata, onde foram observados comportamentos interessantes e desejáveis para modelos dessa categoria, como “zero shot” question answering (onde o modelo responde a um pergunta sem estar ciente do contexto explicitamente), e baixa necessidade de bases previamente anotadas, para as tarefas citadas anteriormente. O modelo pode ser treinado graças à biblioteca DeepSpeed, utilizando o esquema de otimização ZeRO (que também aparece nessa edição da Newsletter).
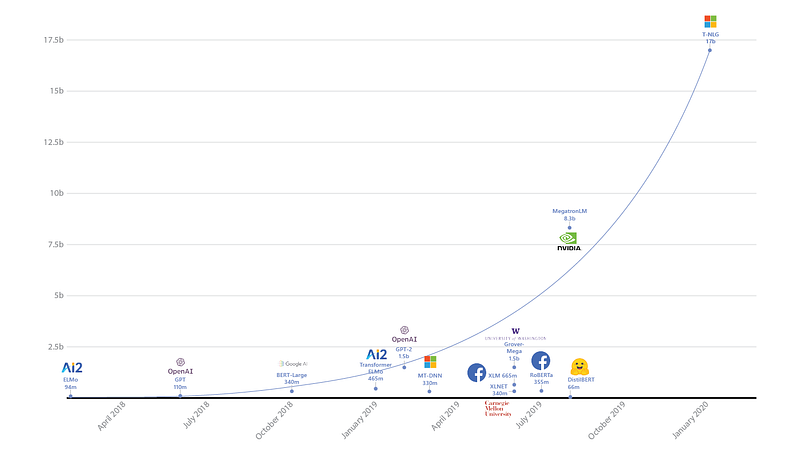
Modelos de Linguagem e suas quantidades de parâmetros — fonte
Neural based Dependency Parsing
A pesquisadora Miryam de Lhoneux liberou recentemente sua tese de Doutorado, entitulada “Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages”. O trabalho desenvolvido propõe a utilização de abordagens baseadas em redes neurais para a tarefa de análise de dependências (dependency parsing) em idiomas com diversas tipologias (línguas que apresentam padrões funcionais e estruturais diferentes). O trabalho apresentado pela autora indica que a incorporação de RNNs e camadas recursivas nos analisadores pode ser benéfica para a tarefa, uma vez que essas arquiteturas podem indicar o conhecimento linguístico necessário à análise. Outras extensões incluem a utilização de analisadores poliglotas e estratégias de compartilhamento de parâmetros para a análise de linguagens correlacionadas ou descorrelacionadas.
End-to-end Cloud-based Information Extraction with BERT
Um time de pesquisadores publicou um artigo descrevendo como modelos de Transformers, como o BERT, podem auxiliar sistemas de extração de informação de ponta a ponta em documentos de domínios específicos, como documentação regulatória e de concessão de propriedades. Esse tipo de trabalho, além de otimizar operações de negócios, demonstra a eficiência e aplicabilidade de modelos baseados no BERT em cenários onde bases de dados anotadas são extremamente limitadas. Uma plataforma na nuvem é apresentada e discutida, assim como os detalhes de sua implementação (ver figura abaixo).
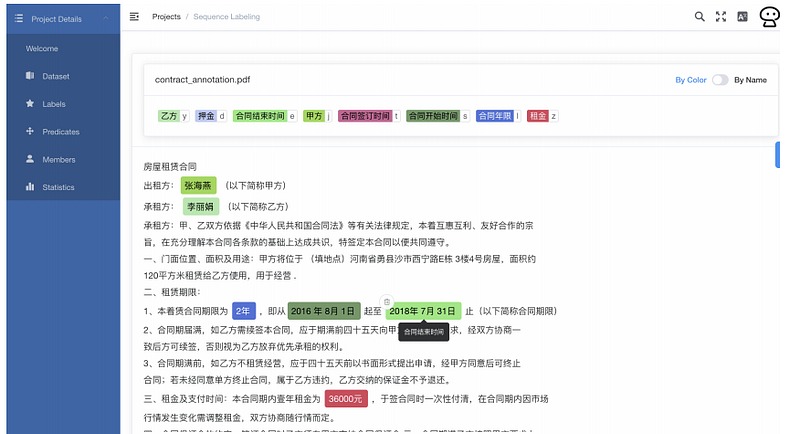
Question Answering Benchmark
Em Wolfson et al. (2020), apresenta-se um benchmark para a tarefa de question understanding e um método para decomposição de questões, uma etapa necessária para a determinação de uma resposta apropriada. Os autores recorreram à um serviço de crowdsourcing para a criação da base anotada de decomposição de questões. Com objetivo de demonstar a viabilidade e aplicabilidade do método proposto, os autores mostraram que é possível melhorar o desempenho de modelos utilizando essa técnica sobre a base de dados HotPotQA.
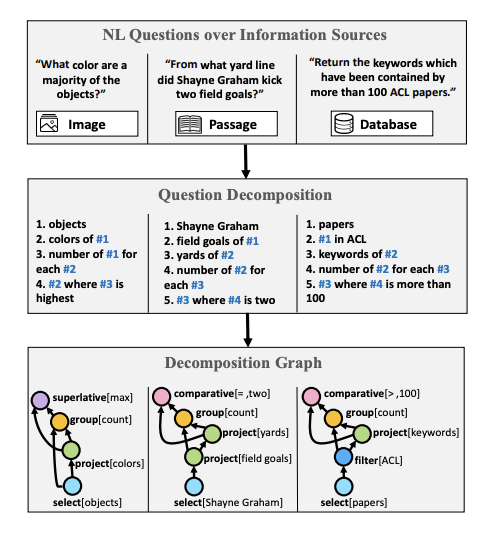
“Questões de diferentes fontes de informações exibem uma estrutura composicional semelhante. Questões em linguagem natural (parte de cima) são decompostas seguindo a metodologia QDMR (meio) e deterministicamente mapeadas para uma linguagem pseudo-formal (parte de baixo).” — fonte
Radioactive data: tracing through training
Membros da equipe de pesquisa em IA do Facebook publicaram recentemente um trabalho interessante que propõe a marcação de imagens (referenciadas como radioactivate data) de tal maneira que seja possível verificar se uma determinada base de dados foi utilizada no treinamento de um modelo de Aprendizado de Máquina. Os autores concluíram que é possível utilizar uma marcação mais robusta, que move as features para uma determinada direção, e que pode ser empregada para auxiliar a detecção de dados “radioativos”, mesmo quando apenas 1% destes estão presentes na base de treinamento.
Essa é uma tarefa bem desafiadora, uma vez que qualquer modificação nos dados pode potencialmente prejudicar o desempenho do modelo. De acordo com os autores, o trabalho proposto pode “ajudar pesquisadores e engenheiros a monitorar quais bases de dados foram utilizadas no treinamento de um modelo, com o objetivo de compreender melhor como bases de dados de diferentes naturezas influenciam o desempenho de diversas redes neurais”. Parece uma tarefa crucial para aplicações mission-critical. Confira o artigo completo aqui.
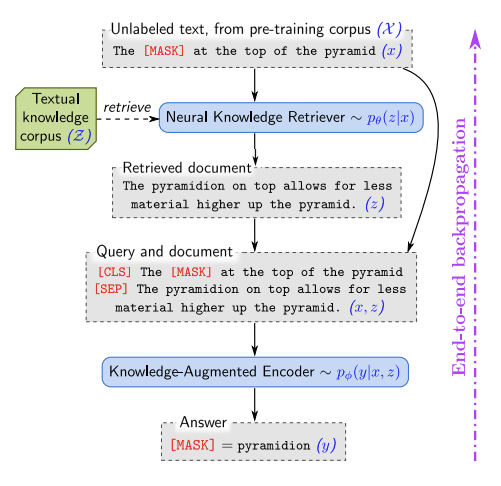
REALM: Retrieval-Augmented Language Model Pre-Training
O REALM é um método de recuperação em larga escala baseado em redes neurais, que faz uso de bases de conhecimento textual para pré-treinar um modelo de linguagem de maneira não-supervisionada. Essencialmente, o objetivo da abordagem é capturar o conhecimento, de uma maneira mais interpretável, expondo o modelo à conhecimentos gerais utilizados durante o processo de treinamento e inferência através do backpropagation. As bases onde o método foi testado e avaliado incluem benchmarks de open-domain question answering. Além do aumento observado na acurácia do modelo, outros benefícios incluem modularidade e interpretabilidade dos componentes.
Criatividade e Sociedade 🎨
Apresentações remotas de artigos e pôsteres em conferências científicas
Durante a semana passada, uma petição circulou na internet, reivindicando a permissão para apresentações remotas de artigos e pôsteres em conferências científicas, como as relacionadas à Aprendizado de Máquina. Para saber mais, acesse change.org. Parece que Yoshua Bengio, um dos pioneiros do Deep Learning, está convocando as pessoas à assinar a petição. Ele deixou isso bem claro em seu novo blog.
Abstração e Desafios de Raciocínio
François Chollet postou recentemente uma competição no Kaggle onde ele disponibilizou o Abstraction and Reasoning Corpus (ARC), uma base de dados que tem como objetivo encorajar os usuários a desenvolver sistemas de IA para resolver tarefas às quais nunca foram expostos. A esperança é que essa competição seja o pontapé inicial para a construção de modelos mais robustos de IA, capazes de resolver novos problemas por conta própria de maneira mais eficiente e rápida, ajudando na resolução de aplicações mais desafiadoras do mundo real como a melhoria de carros autônomos que operam em ambientes diversos e extremos.
Publicações de Aprendizado de Máquina e Processamento de Linguagem Natural em 2019
Marek Rei liberou sua análise anual com estatísticas das publicações sobre ML e NLP em 2019. As conferências consideradas nas análises foram ACL, EMNLP, NAACL, EACL, COLING, TACL, CL, CoNLL, NeurIPS, ICML, ICLR, e AAAI.
Growing Neural Cellular Automata
Morfogênese é um processo de auto-organização pelo qual alguns animais, como as salamandras, podem regenerar partes de seus corpos que sofreram danos. O processo é robusto a perturbações e adaptativo na natureza. Inspirado nesse esse fenômeno biológico e com a necessidade de uma melhor compreensão desse mecanismo, pesquisadores publicaram um trabalho entitulado “Growing Neural Cellular Automata”, que adota um modelo diferenciável para o processo de morfogênese buscando replicar os comportamentos e propriedades de sistemas de auto-reparação.
Espera-se que o processo seja capaz de criar máquinas “auto-reparáveis” que possuam a mesma robustez e maleabilidade dos organismos biológicos. Além disso, o método pode possibilitar um melhor entendimento do processo de regeneração em si. Áreas que podem se beneficiar com essa pesquisa incluem a medicina regenerativa e a modelagem de sistemas sociais e biológicos.
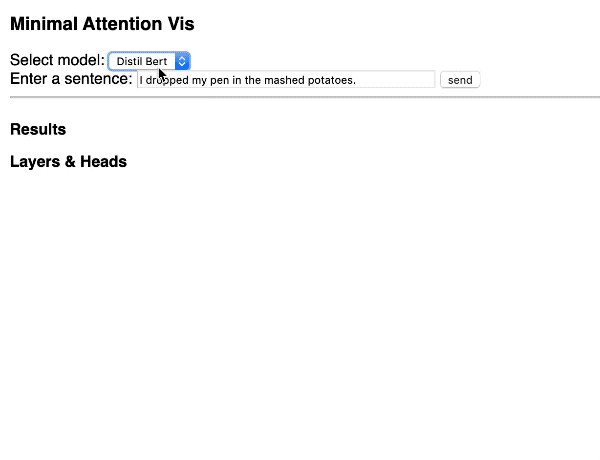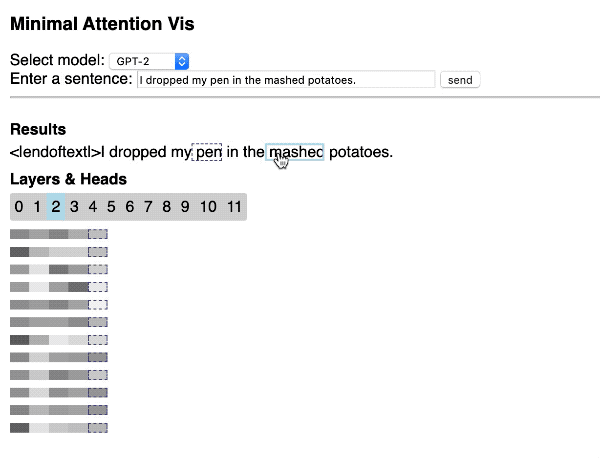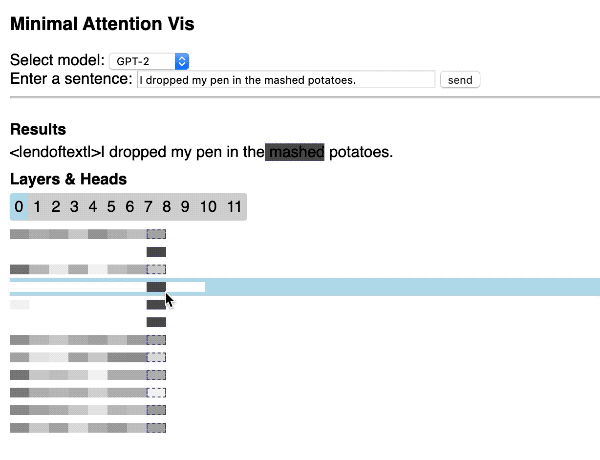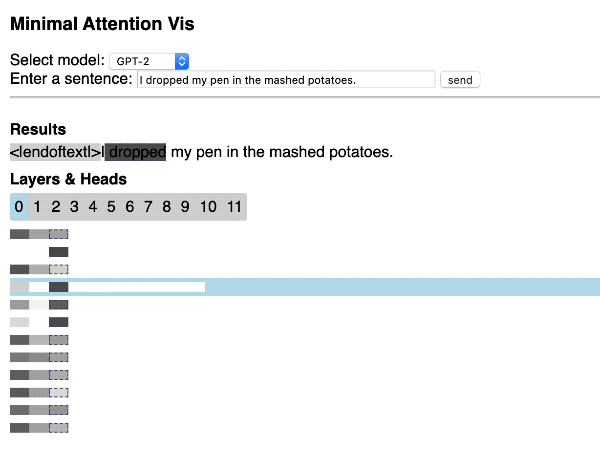
Visualização do mecanismo de Atenção do Transformer
Hendrik Strobelt compartilhou esse repositório bem interessante que mostra como construir rapidamente uma visualização simples e interativa da Atenção do Transformer através de uma aplicação web utilizando as bibliotecas Hugging Face e d3.js.
SketchTransfer: A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks
O SketchTransfer propõe uma nova tarefa que tem por objetivo testar a habilidade de redes neurais profundas em manter a capacidade invariância frente a presença/ausência de detalhes. Um debate de longa data existe acerca da inabilidade de redes profundas em generalizar variações que não foram vistas durante o treinamento, algo que os humanos conseguem fazer com relativa facilidade em situações como, por exemplo, a falta de alguns detalhes visuais quando assistimos desenhos. O trabalho discute e disponibiliza uma base de dados esboços não-anotados e imagens reais anotadas, permitindo que os pesquisadores possam estudar o problema de “detail-invariance” de maneira bastante cuidadosa.

Bibliotecas e Bases de Dados ⚙️
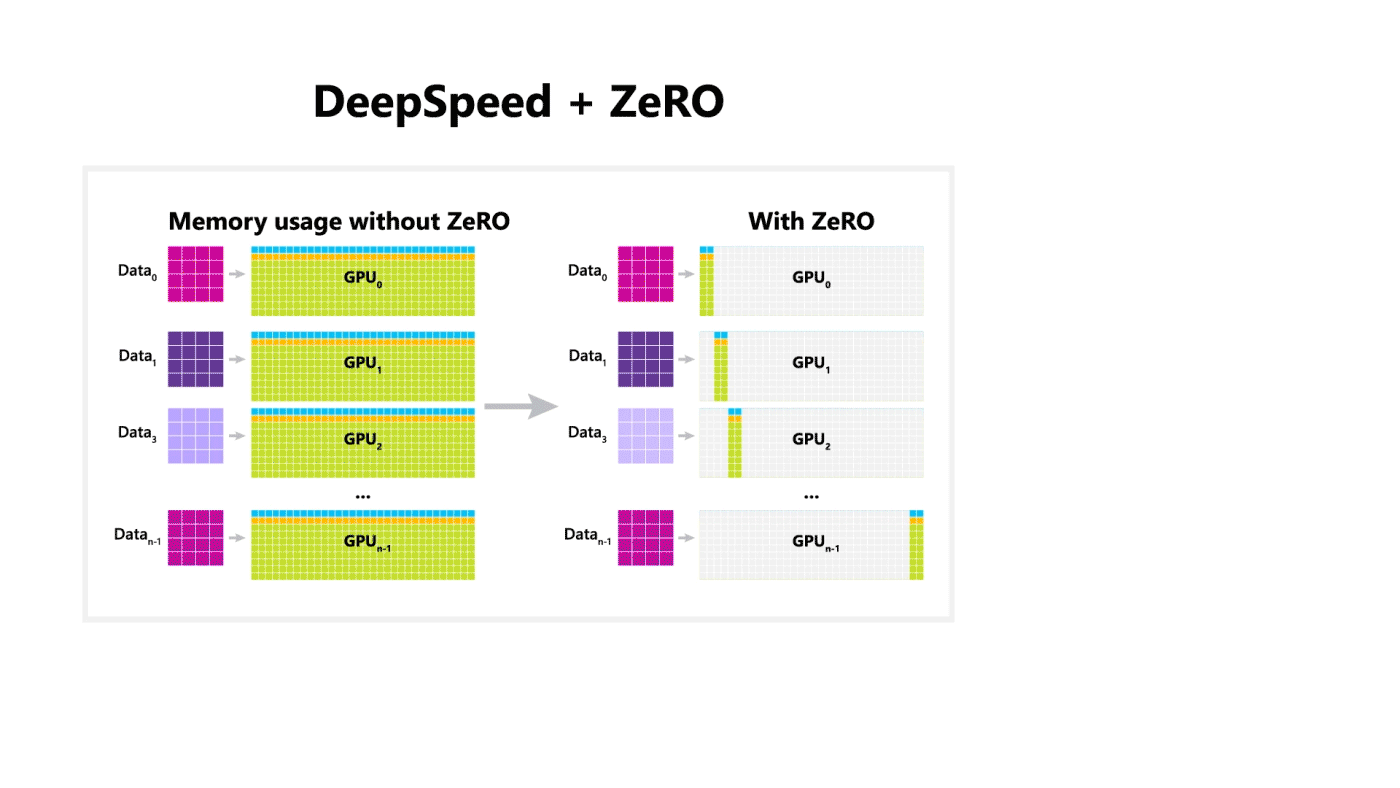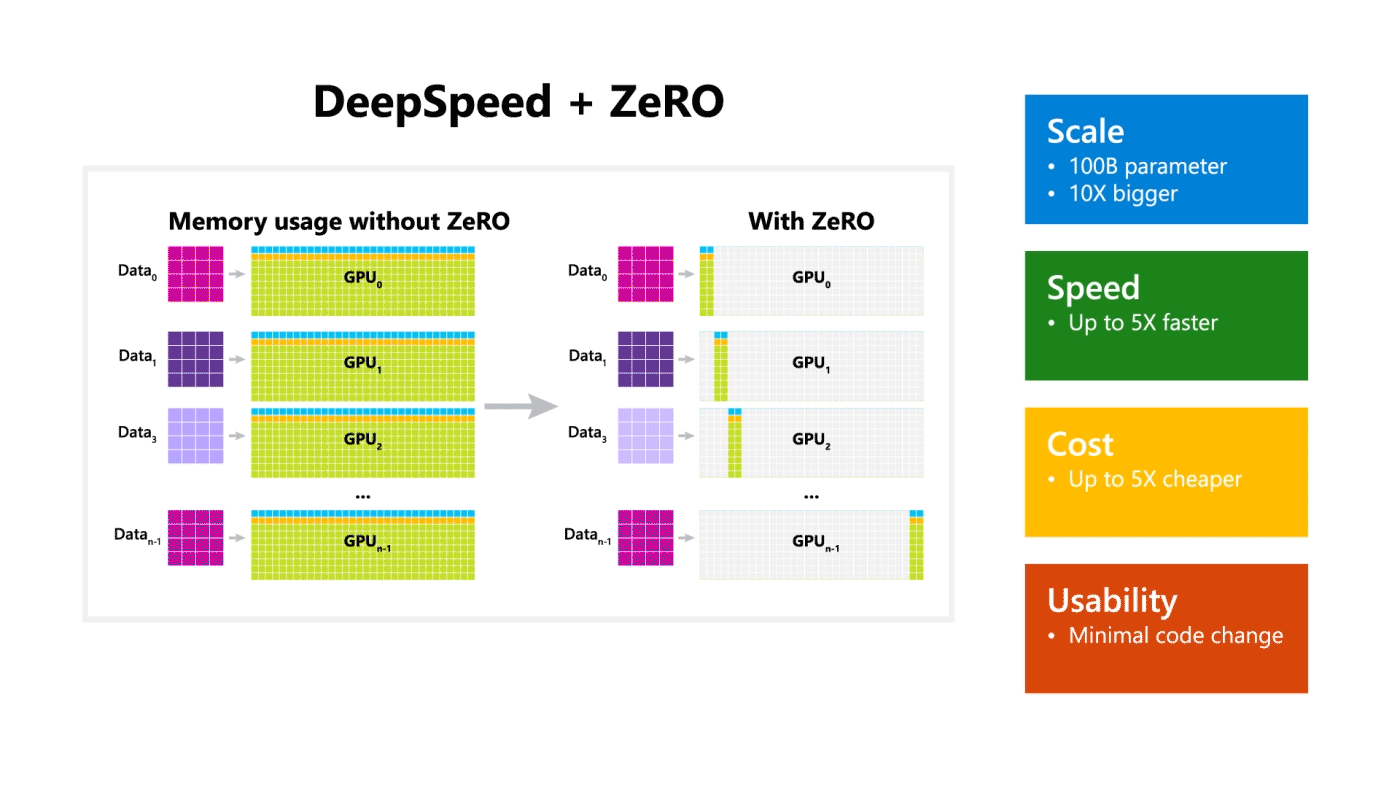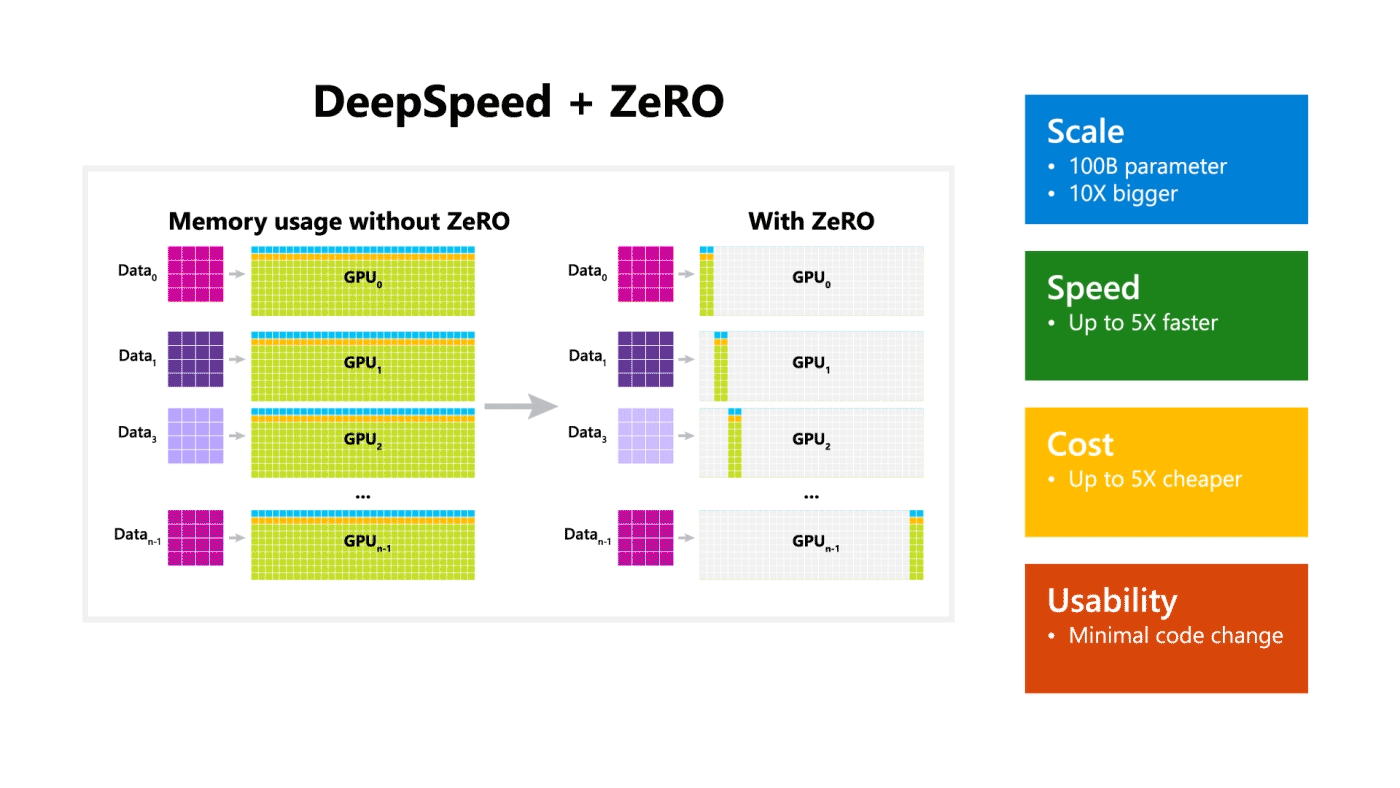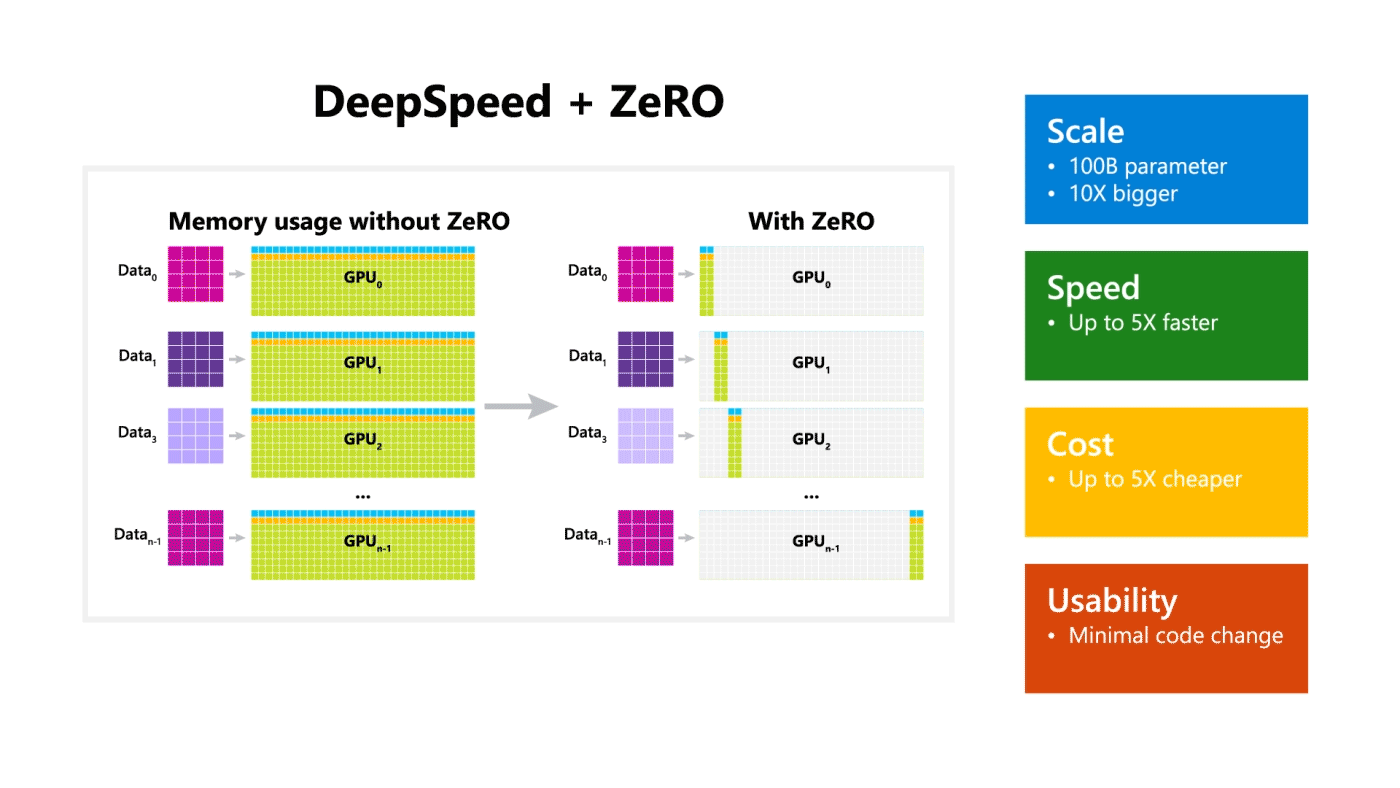
DeepSpeed + ZeRO
A Microsoft liberou um pacote para otimização chamado DeepSpeed, compatível com o PyTorch, que possibilita o treinamento de modelos com 100 bilhões de parâmetros. A biblioteca dá destaque a 4 importantes aspectos do processo de treinamento: operação em escala, velocidade, custo, e usabilidade. A DeepSeed foi liberada junto com o ZeRO, uma tecnologia que otimiza a utilização da memória, e que possibilita o emprego do Deep Learning em larga escala de maneira distribuída com as atuais tecnologias de GPU, além de melhorar o throughput em 3-5 vezes em relação à melhor solução atual. A tecnologia possibilita o treinamento de modelos de tamanho arbitrário que podem ocupar a memória total disponível, distribuída pelos diversos dispositivos na infra-estrutura.
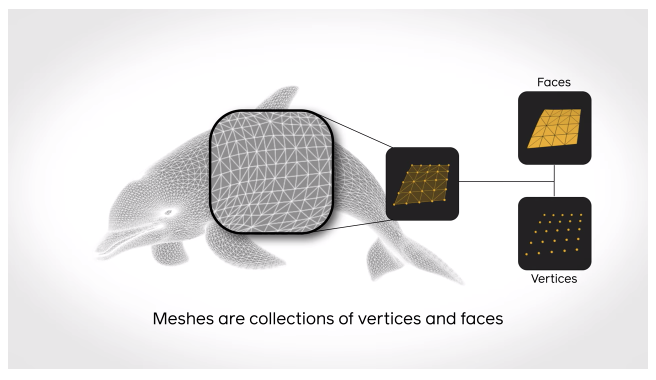
Deep Learning em Superfícies 3D de Maneira Rápida e Eficiente
A PyTorch3D é uma biblioteca em código aberto para a pesquisa de Deep Learning aplicado à superfícies 3D. Esse pacote, baseado no PyTorch, busca auxiliar no suporte e entendimento de dados em 3D aplicados à redes neurais. A biblioteca consiste de implementações eficientes e otimizadas de operadores e funções de custo 3D comumente utilizadas. Um renderizador diferenciável modular também está disponível, que pode ser útil durante a pesquisa e exploração de entradas 3D com padrões complexos e na geração de predições de alta qualidade.
Gerenciamento de Configurações para projetos de ML
Hydra é uma ferramenta de configuração escrita em Python, que auxilia no gerenciamento de projetos complexos de ML de maneira mais eficiente. O propósito é dar suporte a pesquisadores que utilizam o PyTorch, oferencedo a possibilidade de reutilização de configurações de projetos de maneira funcional. O benefício principal oferecido é a possibilidade do programador compor configurações como compõe-se código, o que permite a rápida alteração de arquivos de configuração. A Hydra pode ainda gerenciar automaticamente o diretório de trabalho que armazena as saídas do seu projeto de ML, o que é bem útil quando precisamos salvar e acessar diversos resultados provenientes de múltiplos jobs. Para saber, mais visite o site.
Uma biblioteca para Inferência Causal com Redes Bayesianas
A CausalNex é uma ferramenta que busca combinar o aprendizado de máquina e o raciocínio causal, possibilitando a descoberta de relacionamentos estruturais na base de dados. Os autores prepararam um tutorial introdutório que mostra porquê e como inferir causalidade com as Redes Bayesianas utilizando a biblioteca proposta.

Google Colab Pro agora está disponível
O Google Colab comecou a oferecer uma versão Pro, que disponibiliza vantagens como o acesso exclusivo à GPUs e TPUs, tempos de execução mais longos e mais memória.
TyDi QA: A Multilingual Question Answering Benchmark
O grupo de IA da Google introduziu recentemente a TyDi QA, uma base de dados multi-idiomas que busca encorajar pesquisadores a abordar a tarefa de question answering em línguas mais tipologicamente diversas, ou seja, que apresentam padrões estrturais não-convencionais. A liberação da base visa motivar a construção de modelos mais robustos a idiomas tipologicamente distantes, como o Árabe, Bengali, Coreano, Russo, Telugo e Tailândes, podendo generalizar para outros dialetos.

Question Answering para Node.js
A empresa Hugging Face liberou uma biblioteca para question answering baseada no DistilBERT, dando continuidade a sua missão de tornar a área de Processamento de Linguagem Natural mais acessível. O modelo apresentado pode rodar num ambiente de produção utilizando Node.js com apenas 3 linhas de código, se benficiando da implementação eficiente oferecida pela Tokenizers, também desenvolvida pelo Hugging Face, e a versão em Javascript do TensorFlow (TensorFlow.js).
Ética em IA 🚨
Identificando viés subjetivo em texto
Num podcast que contou com a participação de Diyi Yang, um pesquisador em ciência social computacional, foi discutido como sistemas de IA podem auxiliar na identificação de viés subjetivo em informações textuais. Essa é uma área de pesquisa importante envolvendo Inteligência Artificial e NLP, especialmente quando discutimos sobre o consumo de textos, como títulos e chamadas de notícias, e a facilidade que esses meios possuem para influenciar leitores com opiniões subjetivas.
Do ponto de vista da aplicação, se torna de vital importância a tarefa de identificação desse viés de maneira automática, assim como a conscientização dos leitores, para que esses se tornem mais atentos e criteriosos em relação ao conteúdo que estão consumindo.
Artificial Intelligence, Values and Alignment
A disseminação de sistemas de IA e a forma com que esses sistemas se alinham com os valores humanos é uma área de pesquisa envolvendo ética na Inteligência Artificial em crescente atividade. A DeepMind publicou recentemente um artigo que busca investigar de maneira mais profunda as questões filosóficas envolvidas no alinhamento da IA com os valores humanos. O trabalho discute duas frentes: a técnica (como codificar valores que permitem que agentes de IA produzam resultados confiáveis), e a normativa (quais princípios deveriam ser codificados pelos modelos), e como eles se relacionam e podem ser garantidos. O artigo encoraja uma abordagem baseada em princípios para o alinhamento de valores pelos sistemas de Inteligência, de modo a preservar um tratamento igualitário e justo frente às diferenças de convicções e opiniões.
Auditoria em Sistemas de IA
A VentureBeat divulgou que pesquisadores da Google, numa colaboração com outros grupos, criaram um framework chamado SMACTR, que permite a auditoria de sistemas de IA. A motivação para esse trabalho envolve a ausência de “prestação de contas” dos sistemas atuais, que são colocados à disposição do público geral. A reportagem completa pode ser acessada aqui, assim como o trabalho completo.
Artigos e Postagens ✍️
Destilação de modelos em sistemas de NLP
Num novo episódio do podcast NLP Highlights, Thomas Wolf and Victor Sanh discutiram sobre a destilação de modelos e como a técnica pode ser utilizada como uma alternativa factível para a compressão de grandes arquiteturas, como o BERT, para aplicações escaláveis de NLP em cenários reais. A metodologia é discutida no trabalho publicado pelos convidados, entitulado DistilBERT, onde são construídos modelos menores (baseados na mesma arquitetura do modelo original) que tentam simluar o comportamento do modelo com maior número de parâmetros, de acordo com suas saídas. Essencialmente, o menor modelo (student) tenta modelar a distribuição de probabilidade do modelo maior (teacher) baseado na distribuição empírica gerado por suas saídas.
BERT, ELMo, & GPT-2: How contextual are contextualized word representations?
O sucesso de métodos contextualizados como o BERT para resolução de uma ampla gama de tarefas complexas de NLP é um assunto que está em voga no momento. Nesse post, Kawin Ethayarajh tenta responder a questão que diz respeito à quão contextuais os modelos como BERT, o ELMo e o GPT-2 e seus respectivos word embedddings contextualizados são. As características exploradas incluem métricas de contextualidade, especificidade de contexto, além de comparações entre representações vetoriais de palavras “estáticas” e suas versões contextualizadas.
Esparsidade em Redes Neurais
François Lagunas, pesquisador na área de ML, escreveu esse excelente post compartilhando seu otimismo em relação à utilização de tensores esparsos em modelos de redes neurais. A expectativa é empregar alguma forma de esparsidade visando a redução do tamanho dos modelos atuais, que de certa forma estão se tornando impraticáveis, dadas suas colossais quantidades de parâmetros. Os Transformers, por exemplo, com seus bilhões de parâmetros, poderiam se beneficar com o emprego dessa técnica.
Entretanto, os detalhes de implementação para viabilizar a utilização eficiente da esparsidade em GPU ainda não estão claros… Felizmente, a comunidade de Aprendizado de Máquina já está trabalhando nisso!
Treinando Seu Próprio Modelo de Linguagem
Se você está interessado em aprender como treinar um modelo de linguagem do zero, confira esse excelente tutorial da Hugging Face que utiliza as suas incríveis bibliotecas Tokenizers e Transformers no treinamento do modelo.
Tokenizers: How machines read
Cathal Horan publicou um blog post impresssionante e bem detalhado sobre como e quais tipos de tokenizers vêm sendo utilizados nos mais recentes modelos de NLP, auxiliando modelos de Inteligência a aprender por meio de informações textuais. O post também discute e motiva porquê a tarefa de tokenização é uma importante e desafiadora área de pesquisa ativa. O artigo apresenta ainda como treinar o seu próprio tokenizer utilizando métodos como o SentencePiece e o WordPiece.
Educação 🎓
Machine Learning na VU Amsterdam
Agora você pode acompanahar o curso 2020 MLVU machine learning pela internet, onde estão inclusas a lista completa de slides, videos e o plano de estudos. O curso oferece uma introdução à ML, além de cobrir tópicos mais avançados de Deep Learning, como Variational AutoEncoders (VAEs) e Redes Neurais Adversariais (GANs).

Materiais de Matemática para ML
Suzana Ilić e a organização Machine Learning Tokyo (MLT) vêm realizando um excelente trabalho em prol da democratização do conhecimento em ML. Confira esse repositório que apresenta uma coleção de fontes e materiais sobre os fundamentos matemáticos utilizados em Aprendizado de Máquina.
Introduction to Deep Learning
Acompanhe o curso “Introduction to Deep Learning” do MIT nesse site. Novas aulas serão postadas toda semanas e todos os materiais, como slides, vídeos e códigos utilizados, serão publicados.
Deep Learning com PyTorch
Alfredo Canziani publicou os slides e notebooks utilizados no minicurso de Deep Learning com Pytorch. O repositório contém ainda um site que incluem notas sobre os conceitos apresentados no curso.
Missing Semester of Your CS
O “Missing Semester of Your CS” é um excelente curso online composto por recursos que podem ser potencialmente úteis para cientistas de dados que não possuem background na área de desenvolvimenteo. Estão inclusos materiais sobre shell scripting e versionamento. O curso foi disponibilizado por alunos do MIT.
Advanced Deep Learning
A CMU disponibilizou recentemente os slides e plano de estudos para o curso “Advanced Deep Learning”, que cobre tópicos como modelos autoregressivos, modelos generativos, aprendizado autosupervisionado, entre outros. O público-alvo são alunos de mestrado e doutorado com sólidos conhecimentos de ML.
Menções honrosas ⭐️
Você pode encontrar a última Newsletter aqui. Essa edição cobriu tópicos como melhorias em agentes conversacionais, divulgação de modelos BERT para idiomas específicos (entre eles o Português!!!), bases de dados publicamente disponívies, introdução de novas bibliotecas para Deep Learning, e muito mais.
Em Xu et al. (2020), foi proposto um método para progressivamente substituir e comprimir modelos BERT através da separação de seus componentes originais. Através dessa substituição progressiva, aliado ao processo de treinamento, é possível combinar os componentes originais e suas versões compactadas. A metodologia apresentada supera outras abordagens de knowledge distillation no benchmark GLUE.
Um outro curso interessante é o “Introduction to Machine Learning”, que cobre o básico de ML, regressão supervisionada, random forests, ajuste de parâmetros, dentre outros conceitos fundamentais.
A versão para 🇬🇷 grego do BERT (GreekBERT) está disponível para uso através da biblioteca Transformers, da Hugging Face.
Jeremy Howard publicou um artigo descrevendo a biblioteca de Deep Learning fast.ai, que é amplamente utilizada para pesquisa e ensino em seus cursos de Deep Learning. Uma leitura bastante recomendada para desenvolvedores de software que trabalham construindo e melhorando pacotes de Aprendizado de Máquina e Deep Learning.
A Deeplearning.ai completou o lançamento dos seus 4 cursos da série TensorFlow: Data and Deployment Specialization. A especialização visa ensinar desenvolverdores a como realizar o deploy de modelos de maneira efetiva e eficiente nos mais diferentes cenários, além de utilizar dados de maneiras eficazes durante o treinamento de modelos.
Sebastian Raschka publicou recentemente um artigo entitulado “Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence”. O trabalho apresenta uma revisão bastante acessível às mais variadas ferramentas de ML. É um artigo excelente para compreender as vantagens de algumas bibliotecas e conceitos utilizados em Aprendizado de Máquina. Além disso, levanta-se a discussão sobre o futuro de bibliotecas de ML baseadas em Python.