

Bem vindo novamente à NLP Newsletter! 👋 Esta segunda newsletter aborda topicos que vão de interpretabilidade de modelos para enovelamento de proteínas (protein folding) até active transfer learning. Você pode encontrar a versão Markdown desta edição no final.
Publicações 📙
Confiando na incerteza dos modelos
Um artigo recente do Google AI, publicado na NeurIPS, analisa se as probabilidades de um modelo refletem a sua capacidade de prever dados fora de distribuição ou mudança no conjunto de dados (shifted data).
Ensembles profundos (Deep ensembles) tiveram um melhor desempenho (i.e., melhoraram a incerteza do modelo) no dataset com mudança no conjunto de dados (data shift), enquanto outros modelos não tornaram-se mais incertos com o mesmo data shift, mas ao contrario transformaram-se confidentemente errados(Leia o paper aqui e o sumário aqui.).

Corrupção da imagem — fonte
Generalização Sistemática
Um trabalho interessante publicado na ICLR apresenta uma comparação entre modelos modulares e modelos genéricos e as suas respectivas efetividades para generalização sistematica em entendimento de linguagem (language understanding). Com base na avaliação do reasoning realizada em uma tarefa em que se respondia uma pergunta visual, os autores concluem que pode haver a necessidade de regularizadores e priorizadores explícitos para se conseguir uma generalização sistemática.
Um modelo eficiente baseado em Transformer chamado Reformer
É bem conhecido que um modelo Transformer é bastante limitado em relação à janela de contexto que pode ser coberta, devido aos cálculos de algo custo computacional realizados na camada de Attention. Assim, só pode ser possível aplicar o modelo Transformer a tamanhos de texto limitados ou gerar frases curtas e/ou peças musicais. O GoogleAI publicou recentemente uma variante eficiente de um modelo Transformer chamado Reformer. O foco principal deste método é ser capaz de lidar com janelas de contexto muito mais altas e, ao mesmo tempo, reduzir os requisitos computacionais com a melhoria da eficiência do uso de memória. O Reformer usa o “locality-sensitive-hashing” (LSH) para agrupar vetores similares e criar segmentos a partir deles, o que permite o processamento paralelo. A camada de Attention é então aplicada a estes segmentos menores e em partes vizinhas correspondentes - isto é, o que reduz a carga computacional. A eficiência de memória é obtida usando camadas reversíveis que permitem que as informações de entrada de cada camada sejam recalculadas sob demanda durante o treinamento via backpropagation. Esta é uma técnica simples que evita que o modelo tenha a necessidade de armazenar as ativações em memória. Confira este notebook no Colab para ver como um modelo Reformer pode ser aplicado a uma tarefa de geração de imagens.
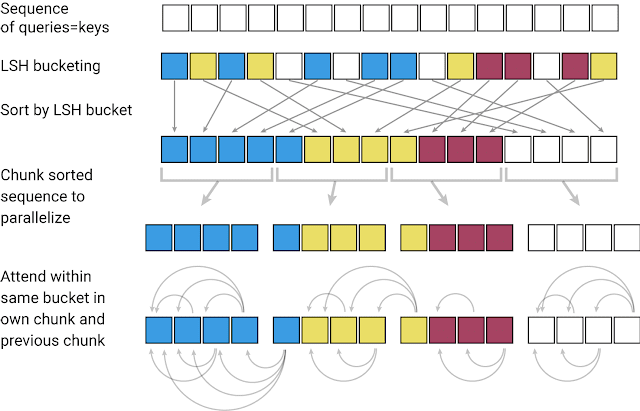
“Locality-sensitive-hashing: O Reformer assume uma sequência de palavras de entrada, onde cada palavra é na verdade um vetor representando palavras individuais (ou pixels, no caso das imagens) na primeira camada e contextos maiores nas camadas subsequentes. O LSH é aplicado à sequência, depois que as palavras são ordenadas pelo seu hash e particionadas. O Attention é aplicado apenas dentro de um único pedaço e dos seus vizinhos imediatos”. - fonte
Adaptação de Dominio de forma não-supervisionada para Classificação de Textos
Este trabalho propõe uma combinação de medidas de distância incorporadas em uma função de perda adicional, para treinar um modelo e melhorar a adaptação não-supervisionada do domínio. O modelo é estendido a um DistanceNet Bandit que otimiza os resultados para “transferência para o domínio alvo de poucos recursos”. O principal problema abordado com este método é como lidar com a disparidade entre os dados de diferentes domínios, especificamente no que diz respeito à tarefas de NLP, como a análise de sentimentos (sentiment analysis).
Melhoria de Representações Contextualizadas
Este artigo propõe uma tarefa de pré-treino mais eficiente em termos de amostragem chamada detecção de token. Esta tarefa pode ser utilizada para treinar um modelo linguístico que é mais eficiente do que métodos de pré-treino com modelagem de linguagem mascarada, como o BERT. O modelo é chamado ELECTRA e suas representações contextualizadas superam as do BERT e XLNET com os mesmos dados e tamanho de modelo. O método funciona particularmente bem no regime de baixa computação. Este é um esforço para construir modelos de linguagem menores e mais baratos.
Interpretabilidade de Modelos
A publicação mais recente da Distill intitulada “Visualizing the Impact of Feature Attribution Baselines” discute os gradientes integrados que são usados para interpretar redes neurais em vários problemas, identificando quais recursos são relevantes para prever um determinado ponto. O problema é definir e preservar corretamente uma noção de falta que é o que se pretende com a entrada de base dos gradientes integrados. O desafio aqui, no contexto da interpretabilidade de modelos, é que o método deve assegurar que o modelo não destaque as características em falta como importantes, evitando ao mesmo tempo dar zero importância às entradas de baseline, o que pode facilmente acontecer. O autor propõe avaliar quantitativamente os diferentes efeitos de algumas escolhas de baseline previamente utilizadas e propostas que melhor preservem a noção de falta.
Criatividade e Sociedade 🎨
Incompatibilidade de sentimentos
Este estudo longitudinal descobre que a emoção extraída através do uso de algoritmos baseados em texto, muitas vezes não é a mesma que as emoções auto-relatadas.
Compreensão da dopamina e o enovelamento de proteínas (protein folding)
A DeepMind lançou recentemente dois artigos interessantes na revista Nature. O primeiro artigo visa entender melhor como funciona a dopamina no cérebro usando a aprendizagem por reforço. O segundo paper está mais relacionado com enovelamento de proteínas e tenta compreendê-lo melhor para ser capaz de potencialmente descobrir tratamentos para uma ampla gama de doenças. Estes são grandes exemplos de como sistemas de IA poderiam potencialmente ser aplicados em aplicações do mundo real para ajudar a sociedade.
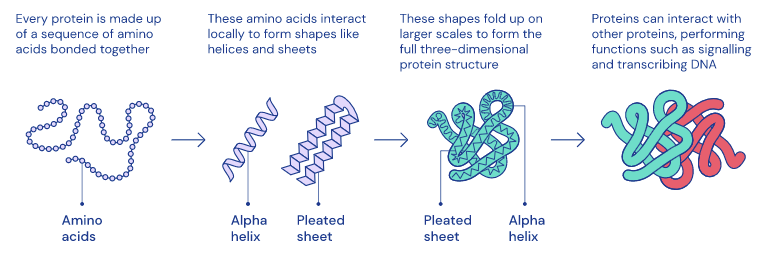
“Formas 3D complexas emergem de um conjunto de aminoácidos.” — fonte
Entrevistas sobre o ML na sociedade
Em uma entrevista com a Wired, Refik Anadol discute o potencial dos algoritmos de aprendizagem de máquina para criação de arte. Este é um excelente exemplo de como Machine Learning pode ser usado de forma a criativa.
Um dos setores em que a IA pode ter um grande impacto é na educação. Em um novo episódio, que faz parte de “The Future of Everything”, Russ Altman e Emma Brunskill têm uma discussão profunda sobre a aprendizagem assistida por computador.
Ferramentas e Datasets ⚙️
Modelos PyTorch em produção
O Cortex é uma ferramenta para automatizar a infra-estrutura e implementar modelos PyTorch como APIs em produção com AWS. Saiba mais sobre como isso é feito aqui.
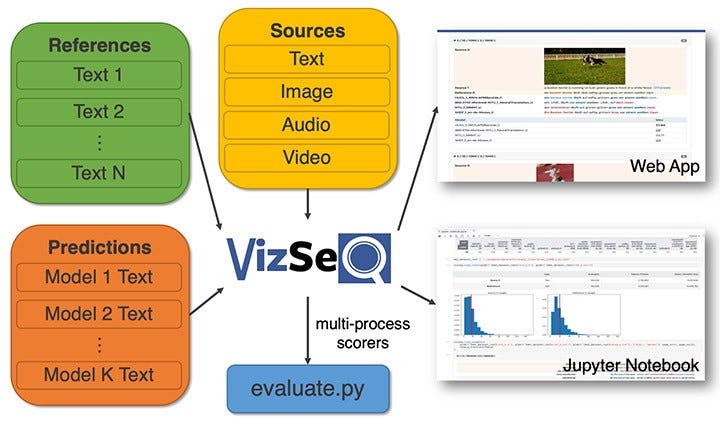
Visualizando Sequências de Geração de Texto
O time do Facebook AI lançou o VizSeq, que é uma ferramenta que auxilia na avaliação visual de seqüências de geração de texto sob métricas como BLUE e METEOR. O principal objetivo desta ferramenta é fornecer uma análise mais intuitiva dos conjuntos de dados de texto, alavancando visualizações e tornando-as mais escaláveis e produtivas para todos os pesquisadores. Leia o artigo completo aqui.
Estado da arte em reconhecimento de fala online
O FacebookAI tornou open-source o wav2letter@anywhere que é um framework de inferência que é baseado em um modelo acústico que usa o Transformer como base para reconhecimento de fala online de última geração. Grandes melhorias estão em torno do tamanho do modelo e reduzindo a latência entre o áudio e a transcrição, o que é importante para seja obtida uma inferência mais rápida em tempo real.
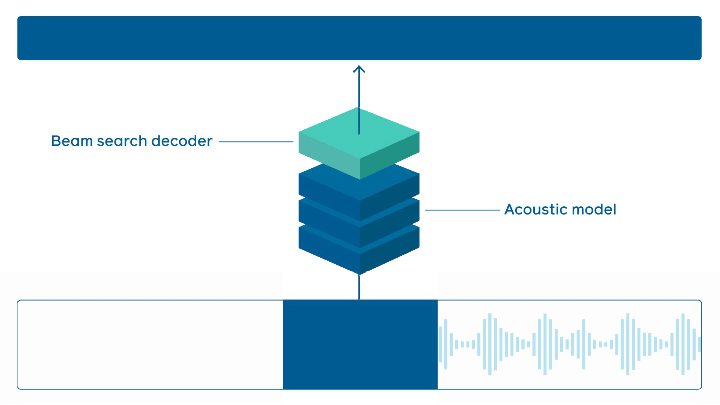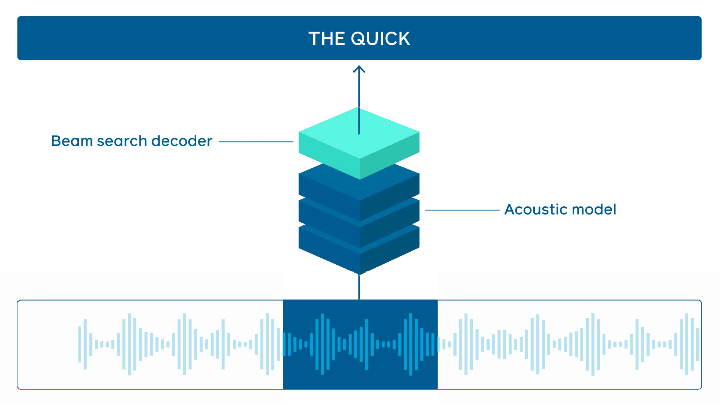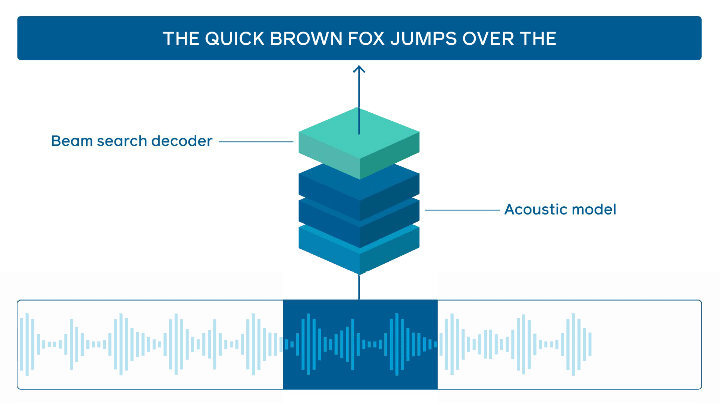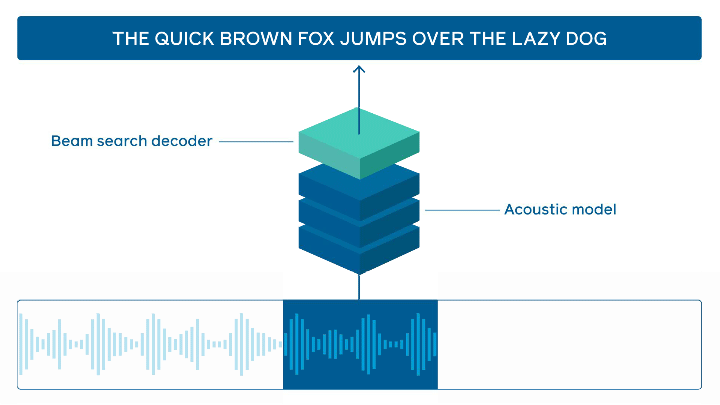
Processamento de fala — fonte
Ética em IA 🚨
Implicações de IA
Em um esforço para evitar abusos e ações antiéticas dos sistemas de IA sobre o público, a União Européia está considerando proibir a tecnologia de reconhecimento facial do público por cinco anos. (História completa)
Os custos ambientais de NLP
Talvez negligenciado na maioria das vezes, este documento discute as considerações energéticas e políticas para abordagens modernas de deep learning em NLP. É amplamente conhecido que os modelos atuais dependem de bilhões de parâmetros e que, por sua vez, dependem de grandes recursos computacionais que demandam um consumo substancial de energia. Os autores esperam espalhar mais consciência sobre os custos ambientais envolvidos no treinamento desses modernos modelos de NLP.
Zachary Lipton discute equidade(fairness), interpretabilidade e os perigos do solucionismo em Machine Learning nesta palestra proferida na Universidade de Toronto. Os principais tópicos giraram em torno de considerações cuidadosas e implicações das abordagens de equidade em ML.
Artigos e posts de blogs ✍️
Open-Sourcing ML
Thomas Wolf, líder científico da Hugging Face, compartilha excelentes conselhos para aqueles que planejam fazer código ML open-source ou pesquisa. Encontre o tópico do Twitter aqui.
Introdução para aprendizagem auto-supervisionada para computer vision*
Jeremy Howard escreveu este grande blog post introduzindo brevemente o conceito de aprendizagem auto-supervisionada no contexto de computer vision. Eu adoro estes pequenos resumos, pois ajudam a dar uma introdução confiável no caso de você estar interessado em aplicar técnicas deste domínio ao seu próprio problema.
TinyBERT para problemas de busca
Já vimos o sucesso de muitas variantes de modelos BERT (por exemplo, DistilBERT) que utilizam alguma forma de destilação do conhecimento para diminuir substancialmente o tamanho do modelo e melhorar a velocidade. Algumas pessoas usaram uma variante do BERT chamada, TinyBERT, e aplicaram-na a uma solução de busca baseada em palavras-chave. Este projeto foi inspirado por esta solução de busca para compreender as buscas propostas pelo Google. A maior parte da arquitetura que ela funciona é em uma CPU padrão e pode ser usada para melhorar e entender os resultados das buscas.
Active Transfer Learning
Rober Monarch escreveu este excelente blog post sobre Active Transfer Learning que faz parte de seu próximo livro chamado Human-in-the-loop Machine Learning. Ele está escrevendo ótimos posts em seu blog sobre métodos para combinar inteligência humana e máquinas para resolução de problemas. Ele também fornece implementações em PyTorch dos métodos discutidos.
Revelando os segredos ocultos do BERT
Anna Roger escreveu este divertido e interessante blog post que fala sobre o que realmente acontece com um BERT otimizado, e se os alegados pontos fortes são usados para abordar tarefas posteriores, tais como análise de sentimentos, vinculação textual e inferência da linguagem natural, entre outras. Os resultados das análises propostas sugerem que o BERT está excessivamente superparametrizado (overparameterized) e que os benefícios identificados do componente de self-attention da estrutura podem não ser necessariamente benéficos como se imagina. Em particular no que diz respeito à informação linguística que está sendo codificada e utilizada para a parte de inferência.
Educação 🎓
Redes Neurais para NLP
Graham Neubig, professor de PNL na CMU, tem lançado alguns vídeos para a aula “Redes Neurais para NLP” que está sendo ministrada neste semestre. Eu recomendo altamente esta playlist para aqueles interessados em aprender sobre os métodos modernos de NLP.
Deep Learning Math (DeepMath)
Quer mergulhar profundamente na matemática por trás dos métodos de deep learning? Aqui está uma série de vídeo-palestras com uma vasta gama de palestrantes.
Cursos de Python e Tutoriais
Python tornou-se uma das linguagens de programação mais requisitadas não só na indústria de TI, mas também no espaço da ciência dos dados. Em um esforço para qualificar alunos de todo o mundo com conhecimentos práticos de Python, o Google lançou o “Google IT Automation with Python Professional Certificate”. Saiba mais sobre o lançamento aqui e veja o curso aqui. Embora o curso não esteja diretamente relacionado ao ML ou à IA, é definitivamente um bom curso de fundamentos para deseja tornar-se proficiente com a linguagem Python. Bolsas de estudo também estão disponíveis.
Aqui está outra série de vídeos promissora chamada “Deep Learning (for Audio) with Python” com foco no uso de Tensorflow e Python para construção de aplicações relacionadas a áudio/música, e alavancando o uso de deep learning.

Andrew Trask lançou um conjunto de notebooks com tutoriais passo-a-passo para alcançar deep learning de forma descentralizada com objetivo de preservação da privacidade. Todos os notebooks contêm implementações PyTorch e são destinados a iniciantes.
Estado da arte em Deep Learning
Confira esta palestra em vídeo de Lex Fridman sobre a recente pesquisa e desenvolvimento em Deep Learning. Ele fala sobre os principais avanços em tópicos como perceptrons, redes neurais, backpropagation, CNN, deep learning, ImageNet, GANs, AlphaGo, e Transformers. Esta palestra faz parte da Série de Deep Learning do MIT.
Online learning e pesquisa
Há muitas e grandes iniciativas online para colaboração tanto em pesquisa quanto em aprendizagem. Os meus favoritos são a sessão de leitura de matemática MLT’s e este novo esforço de colaboração distribuída em pesquisa AI iniciado por nightai. Recentemente, tem havido muitos grupos de estudo como este online e estes grupos de estudos são ótimas maneiras de mergulhar no mundo do ML.
Perspectivas em aprendizagem por reforço
Aprenda com a Dra. Katja Hofmann os principais conceitos e métodos de aprendizagem por reforço nesta série de webinars.
Menções honrosas ⭐️
Confira esta implementação limpa e auto-contida em PyTorch da ResNet-18 aplicada ao CIFAR-10, que atinge ~94% de precisão.
PyTorch 1.4 é lançado! Confira as notas de lançamento aqui.
Elona Shatri escreveu este excelente resumo sobre como ela pretende abordar o reconhecimento da música óptica usando deep learning.
O título para este post no blog é auto-explicativo: “The Case for Bayesian Deep Learning””.
Chris Said compartilha sua experiência na otimização de tamanhos de amostras para testes A/B, uma parte importante em se tratando de Data Science de forma aplicada. Os tópicos incluem os custos e benefícios de grandes tamanhos de amostras e melhores práticas para os profissionais.
Neural Data Server (NDS) is a dedicated search engine for obtaining transfer learning data. Read about the method here and the service here.
O Neural Data Server (NDS) é um mecanismo de busca dedicado à obtenção de dados via transfer learning. Leia sobre o método aqui e o serviço aqui.