

Antes de tudo, gostaria de agradecer de ❤️ a todos vocês pelo incrível apoio e incentivo para continuar com a NLP Newsletter. Esse esforço requer pesquisa, edição, e tradução tediosas, mas que considero gratificantes e úteis para fornecer o melhor conteúdo. Espero que você esteja gostando deste conteúdo. 😉
Assine a NLP Newsletter 🔖 para receber edições futuras via e-mail.
Publicações 📙
Um entendimento teórico do self-distillation
No contexto de Deep Learning, self-distillation (NT: auto-destilação) é o processo de transferência de conhecimento de uma arquitetura para outra. As previsões do modelo original são alimentadas como valores de destino para o outro modelo durante o treinamento. Além de ter propriedades desejáveis como a redução do tamanho dos modelos, os resultados empíricos mostram que essa abordagem funciona bem em conjuntos de dados não vistos anteriormente pelo modelo (NT: amostras held out). Um grupo de pesquisadores publicou recentemente um artigo que fornece uma análise teórica com o foco em um melhor entendimento sobre o que está acontecendo neste processo de destilação do conhecimento e o porque ele é eficaz. Os resultados mostram que alguns poucos ciclos de destilação amplificam a regularização (devido ao fato que a técnica progressivamente ajuda a limitar o número de funções base que representam a solução) as quais tendem a reduzir o over-fitting. (Leia o paper aqui)
Os anos 2010s: Nossa década de Deep Learning / Perspectivas para os 2020s
Jürgen Schmidhuber, um dos pioneiros em Inteligência Artificial, postou recentemente em seu blog uma visão histórica sobre Deep Learning desde o ano de 2010. Alguns tópicos incluem LSTMs, feedforward neural networks, GANs, deep reinforcement learning, meta-learning, world models, distilling NNs, attention learning, etc. O artigo traz algumas perspectivas futuras para os anos 2020 chamando atenção para questões como privacidade e mercado de dados.
Usando Redes Neurais para a resolução de equações matemáticas
Pesquisadores do Facebook AI publicaram um paper em que apresentam um modelo treinado em problemas de matemática para prever possíveis soluções para inúmeras tarefas como, por exemplo, problemas de integração. A abordagem é baseada em uma nova estrutura semelhante à usada na neural machine translation (NT: tradução automática neural), em que expressões matemáticas são representadas como um tipo de linguagem e as soluções tratadas como um problema de tradução. Assim, ao invés do modelo produzir uma tradução, a saída desta tradução é a própria solução do problema. Com isso, os pesquisadores afirmam que as redes Deep Learning não são apenas boas em raciocínio simbólico, mas podem ser usadas também para tarefas mais diversas.
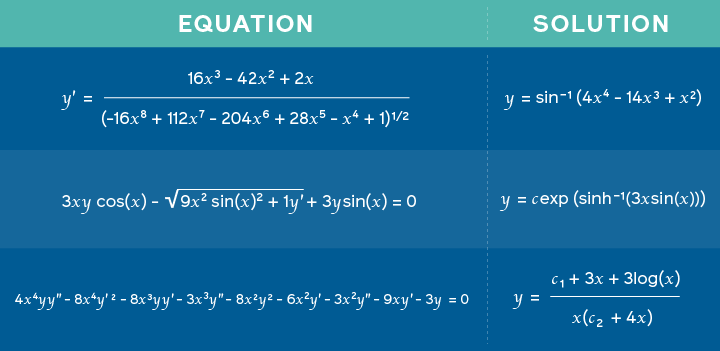
Equações sendo usadas como entrada, juntamente com a solução correspondente gerada pelo modelo— fonte
Criatividade e Sociedade 🎨
Inteligência Artificial para descobertas científicas
Mattew Hutson informa como a inteligência artificial (IA) pode ser utilizada para produzir emuladores que têm um uso importante na modelagem de fenômenos naturais complexos e que, por sua vez, podem levar a diferentes tipos de descobertas científicas. A mudança na construção desses emuladores acontece devido ao fato de que estes modelos geralmente exigem dados em larga escala e uma vasta exploração de parâmetros. Um paper recente propõe um método chamado DENSE que é uma abordagem baseada em neural architecture search (NAS) (NT: Exploração e busca de arquitetura de Redes Neurais) para criar emuladores precisos, contando apenas com uma quantidade limitada de dados de treinamento. Eles o testaram executando simulações para casos que incluem astrofísica, ciência climática e energia de fusão, entre outros.
Melhorando a tradução de imagem para imagem
GANILLA é uma abordagem que propõe o uso de GANs para melhorar a transferência de estilo e conteúdo em pares para tarefas de tradução image-to-image (NT: imagem para imagem). A abordagem propōe um modelo de imagem para imagem (com uma rede de geradores aprimorada) e este modelo é avaliado com base em uma nova estrutura de avaliação quantitativa que considera tanto o conteúdo quanto o estilo. A novidade do trabalho está na rede de geradores proposta, que considera um equilíbrio entre estilo e conteúdo que os modelos anteriores não conseguem. O código e os modelos pré-treinados estão disponíveis. Leia o artigo completo aqui.

Andrew Ng fala sobre o interesse em aprendizagem auto-supervisionada
Andrew Ng, o fundador do deeplearning.ai, falou no podcast de Inteligência Artificial do Lex Friedman sobre os seguintes tópicos: seus primeiros anos em ML, o futuro da IA, educação em IA, recomendações para o uso adequado da ML, seus objetivos pessoais e quais técnicas de ML que devemos prestar atenção nesta década de 2020.
Andrew explicou o motivo da sua animação em relação ao self-supervised representation learning. Self-supervised learning (NT: aprendizado de representação auto-supervisionado) envolve a estruturação de um problema de aprendizagem que visa obter supervisão dos próprios dados para fazer uso de grandes quantidades de dados não rotulados, o que é mais comum que os dados rotulados limpos. As representações são importantes e podem ser usadas para lidar com tarefas posteriores, semelhantes às usadas em modelos de linguagem como o BERT.
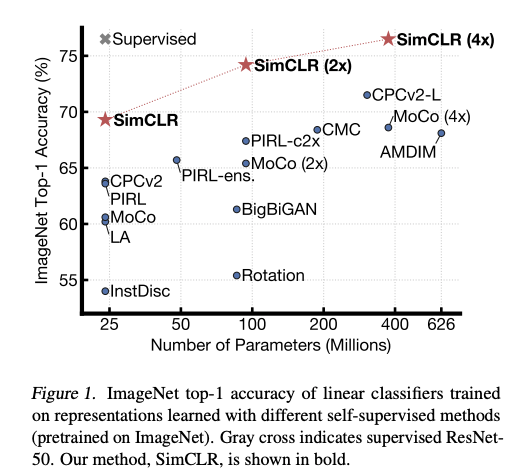
Também há muito interesse em usar o aprendizado auto-supervisionado para treinamento de representações visuais generalizadas que tornam os modelos mais precisos em ambientes com poucos recursos. Por exemplo, um método recente chamado SimCLR (liderado por Geoffrey Hinton) propõe uma estrutura para aprendizagem auto-supervisionada contrastante (NT: contrastive self-supervised learning) de representações visuais para melhorar a classificação de imagens em diferentes configurações, como transferência de aprendizado (NT: transfer learning) e aprendizado semi-supervisionado.
Ferramentas e Datasets ⚙️
Bibliotecas JAX
JAX é uma nova biblioteca que combina o NumPy e diferenciação automática para realizar pesquisas de ML de alto desempenho. Para simplificar os pipelines para a construção de redes neurais usando JAX, a DeepMind lançou o Haiku e RLax. O RLax simplifica a implementação de agentes de aprendizado por reforço e o Haiku simplifica a construção de redes neurais usando modelos familiares com o paradigma de programação orientada a objetos.
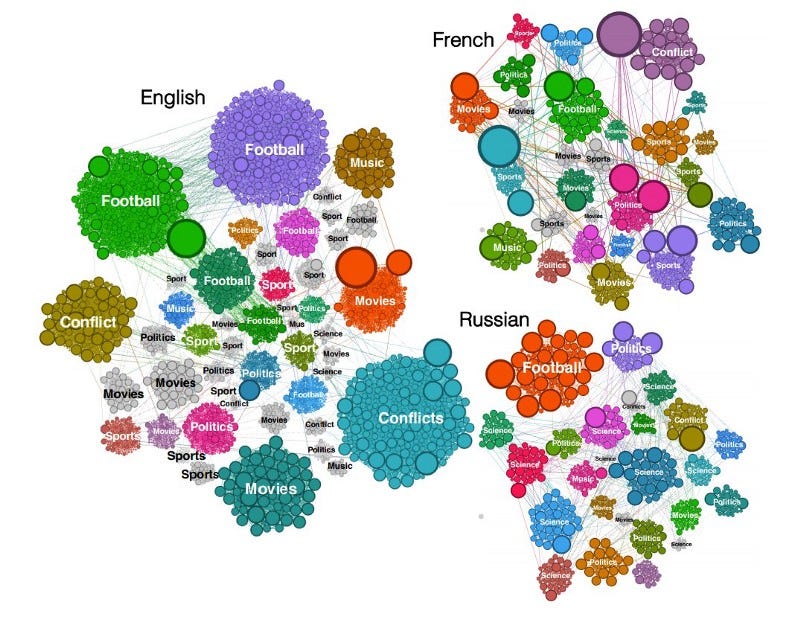
Uma ferramenta para processar dados da Wikipédia
Sparkwiki é uma ferramenta para processar dados da Wikipédia. Esta versão faz parte de muitos esforços para permitir pesquisas interessantes de análise comportamental, como a captura de tendências e preconceitos em diferentes idiomas na Wikipédia. Os autores descobriram que, independentemente do idioma, o comportamento de navegação dos usuários da Wikipédia mostra que eles tendem a compartilhar interesses comuns por categorias como filmes, música e esportes, mas as diferenças se tornam mais aparentes com eventos locais e particularidades culturais.
Tokenizers em Rust, DistilBERT e outros
Um novo release dos Transformers da Hugging Face inclui a integração de sua biblioteca de tokenização rápida, que visa acelerar modelos como o BERT, RoBERTa, GPT-2 e outros modelos criados pela comunidade.
Ética em Inteligência Artificial 🚨
Considerações éticas para modelos de NLP (Processamento de Linguagem Natural) e Machine Learning
Em um novo episódio do postcast NLP Highlights, Emily Bender e os hosts conversaram sobre algumas considerações éticas no desenvolvimento de modelos e tecnologias de NLP no contexto da academia e do seu uso no mundo real. Alguns dos tópicos da discussão incluem considerações éticas nas tarefas de NLP, abordagens sobre coleta de dados e eventualmente considerações na publicação de resultados.
Além de todas as considerações acima, uma preocupação discutida é que a comunidade de IA está se concentrando demais na otimização de métricas específicas, o que contraria os objetivos que a IA pretende alcançar. Rachel Thomas e David Uminsky discutem os problemas dessa abordagem através de uma análise completa de diferentes casos de uso. Eles também propõem uma estrutura simples para mitigar este problema, que envolve o uso e a combinação de várias métricas, seguidas pelo envolvimento das pessoas afetadas diretamente pela tecnologia.
Artigos e Blog posts ✍️
“The Annotated GPT-2”
Aman Arora publicou recentemente uma postagem no blog excepcionalmente intitulada “The Annotated GPT-2“ explicando o funcionamento interno do modelo baseado em Transformer chamado GPT-2. Sua abordagem foi inspirada em The Annotated Transformer que adotou uma abordagem de anotação para explicar as partes importantes do modelo. Aman fez um grande esforço para reimplementar o GPT-2 da OpenAI usando o PyTorch e a biblioteca Transformers da Hugging Face. É um trabalho brilhante!

Além do BERT?
Um ponto interessante foi levantado por Sergi Castella sobre o que está além do BERT. Os principais tópicos incluem o aprimoramento das métricas, uma reflexão de como a biblioteca Transformers da Hugging Face ajuda na pesquisa, alguns conjuntos de dados interessantes para análise, etc.
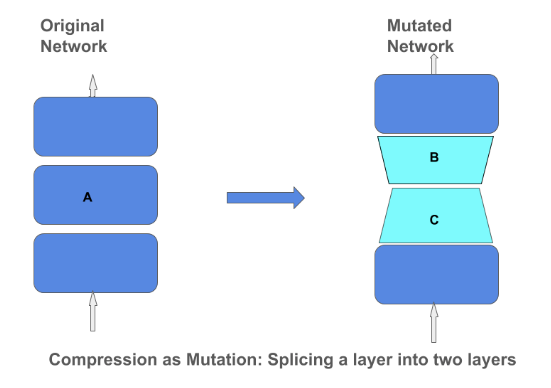
Operador de Compressão de Matrizes
O Blog do TensorFlow publicou um post explicando as técnicas e a importância por trás da compressão matrizes em um modelo de Deep Learning. A compactação matricial (NT: Matrix compression) pode ajudar a criar modelos menores e mais eficientes que podem ser incorporados a dispositivos menores, como telefones e assistentes domésticos. Concentrar-se na compressão dos modelos por meio de métodos como low-rank-approximation e quantização significa que não precisamos comprometer a qualidade do modelo.
Educação 🎓
Fundamentos de NLP
Estou animado por lançado um rascunho do Capítulo 1 da minha nova série chamado Fundamentos de NLP. Esta série ensina conceitos de NLP a partir do básico, compartilhando boas práticas, referências importantes, erros comuns a serem evitados e o que está por vir no que se refere a NLP. Um notebook no Colab foi incluído e o projeto será mantido aqui.

Revisão/Discussão Online: Parte I sessão de leitura para fundamentos da matemática
O time do Meetup “Machine Learning Tokyo” está hospedando uma discussão on-line remota, revisando capítulos que foram abordados em suas recentes sessões de estudo on-line. O grupo já havia estudado capítulos com base no livro Mathematics For Machine Learning escrito por Marc Peter Deisenroth, A Aldo Faisal e Cheng Soon Ong. O evento está programado para 8 de março de 2020.
Recomendações de livros
Em um segmento anterior, discutimos a importância da compressão de matriz para a construção de modelos pequenos (em termos de espaço) de ML. Se você estiver interessado em aprender mais sobre como construir redes neurais profundas menores para sistemas embarcados, confira este ótimo livro chamado TinyML de Pete Warden e Daniel Situnayake.

Outro livro interessante para ficar de olho é o próximo título “Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD” de Jeremy Howard e Sylvain Gugger. O livro tem como objetivo fornecer a base matemática necessária para criar e treinar modelos para abordar tarefas nas áreas de visão computacional e NLP.

Menções honrosas ⭐️
Você pode acessar a NLP Newsletter anterior em PT-BR aqui.
Torchmeta é uma biblioteca para pesquisa em meta-aprendizado. Esta biblioteca é de autoria de Tristan Deleu.
Manuel Tonneau escreveu um post oferecendo uma visão mais detalhada em relação ao hardware envolvido em modelagem de linguagem. Alguns tópicos incluem greedy e beam search e nucleus sampling.
O MIT lançou o plano de estudos completo e a programação do curso intitulado “Introdução ao Deep Learning”, incluindo vídeos das palestras já ministradas. Eles pretendem lançar palestras em vídeo e slides uma vez por semana.
Aprenda a treinar um modelo para reconhecimento de entidade (NER) usando uma abordagem baseada no Transformer em 300 linhas de código. Você pode encontrar o Google Colab em anexo aqui.
Se você tiver datasets, projetos, postagens de blog, tutoriais ou documentos que deseja compartilhar na próxima edição da NLP Newsletter, entre em contato conosco pelo e-mail ellfae@gmail.com ou via DM no Twitter.
Assine a NLP Newsletter 🔖 para receber edições futuras via e-mail.