

بداية، لا أستطيع شكركم ❤️ جميعاً كفاية للدعم الهائل والتشجيع لمواصلة هذه القائمة البريدية. هذا الجهد يحتاج بحث وتعديل مضجرين، الذين أراهما يستحقان، ويساعدان في تزويدكم بأفضل محتوى. أتمنى أن تستمتعوا بهذه الإصدارات، لأنني أفعل 😉.
اشترك 🔖 في قائمة NLP البريدية لتصلك الأعداد القادمة مباشرة على صندوق بريدك.
المنشورات 📙
فهم نظري لل”التقطير الذاتي” (Self-Distillation)
في سياق التعلم العميق (Deep Learning)، التقطير الذاتي أو ال(Self-Distillation) بالإنجليزية هي عملية تحويل المعرفة من معمارية (Architecture) ما إلى معمارية أخرى مماثلة. توقعات النموذج الأصلي تتم تغذيتها كقيم مستهدفة إلى النموذج الآخر أثناء التدريب. بجانب وجود بعض مزايا، مثل تقليل حجم النموذج، تُظهر النتائج التجريبية أن هذا الأسلوب يعمل جيداً على قواعد البيانات المفصولة (Held-Out Datasets). نشر مجموعة من الباحثين ورقة بحثية مؤخراً تقدم تحليلاً نظرياً مع التركيز على فهم أعمق لما يحدث في عملية استخراج (“تقطير”) المعرفة هذه ولماذا هي فعالة. النتائج تظهر أن بضع جولات من “التقطير” تزيد التنظيم (Regularization) (عن طريق الحد تدريجياً من عدد الوظائف الأساسية التي تمثل الحل) الذي يميل إلى تقليل الملائمة الزائدة (Over-Fitting). (اقرأ الورقة كاملة (باللغة الإنجليزية) هنا)
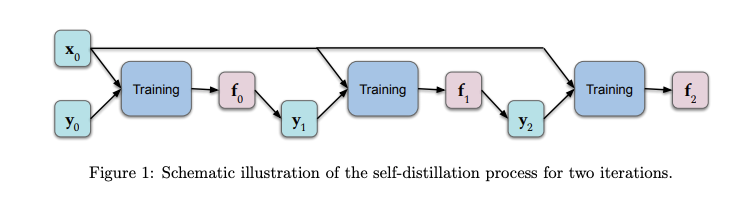
الشكل 1: مخطط توضيحي لعملية التقطير الذاتي لدورتين
عقد 2010 إلى 2019: عقدنا من التعلم العميق / توقعات العقد القادم 2020 - 2029
Jürgen Schmidhuber، رائد في الذكاء الاصطناعي، نشر مؤخراً تدوينة جديدة مركزاً على تقديم نظرة تاريخية على التعلم العميق من عام 2010 وحتى الآن. ذكر فيها بعض المواضيع مثل: وحدات الذاكرة الطويلة قصيرة-المدى (LSTMs)، شبكات التغذية الأمامية العصبية (Feedforward Neural Network)، شبكات الخصومة المولِدة (Generative Adversarial Networks - GANs)، التعليم المعزز العميق (Deep Reinforcement Learning)، التعليم الفوقي (Meta-Learning)، نماذج العالم (World Models)، تقطير الشبكات العصبية (Distilling NNs)، التعلم بالانتباه (Attention Learning)، وغيرها من المواضيع. المقالة ختمت بنظرة إلى القرن القادم بدئاً من عام 2020 مشجعة الاهتمام بمشاكل مثل الخصوصية وأسواق البيانات.
استخدام الشبكات العصبية لحل معادلات رياضية متقدمة
باحثو الذكاء الاصطناعي في فيسبوك نشروا ورقة بحثية تدعي أن تقدم نموذجاً مدرباً على المسائل الرياضية ومطابقة الحلول لتعلم توقع الحلول الممكنة لمهام مثل حل المعادلات التكاملية. هذا الأسلوب مبني على إطار عمل (Framework) جديد مشابه للمستخدم في الترجمة الآلية العصبية (Neural Machine Translation) حيث تكون التعبيرات الرياضية مقدمة كلغة والحلول تتم معاملتها كعملية ترجمة. وهكذا، بدل أن يخرج النموذج ترجمة، المخرج يكون حل المسألة. بهذه الطريقة، يدعي الباحثون أن الشبكات العصبية العميقة ليست جيدة فقط في المنطق الرمزي (Symbolic Reasoning) بل أيضاً في مهام أكثر تنوعاً.
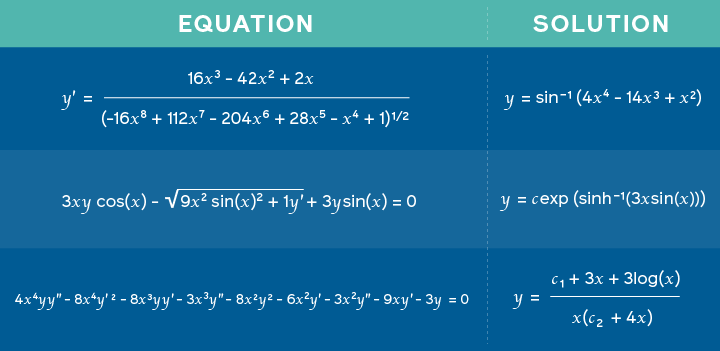
المعادلات المغذاة كمدخلات والحلول المقابلة الذي أخرجها النموذج
الإبداع والمجتمع 🎨
الذكاء الاصطناعي للاكتشافات العلمية
Mattew Hutson قدم تقريراً عن كيف أن الذكاء الاصطناعي (A.I.) يمكن استخدامه لإنتاج محاكيات ذات استخدام مهم في نمذجة ظواهر طبيعية معقدة، التي بدورها أدت إلى أنواع أخرى من الاكتشافات العلمية. التغيير في بناء هذه المحاكيات هو أنهم غالباً ما يحتاجون لبيانات على نطاق واسع (Large-Scale Data) واستكشاف معاملات (Parameter Exploration) مكثف. ورقة بحثية حديثة اقترحت DENSE، أسلوب مبني على بحث الهندسة العصبية (Neural Architecture Search) لبناء محاكيات دقيقة مع الاعتماد على قدر محدود من بيانات التدريب. جربوها بتشغيل محاكاة لحالات مثل: الفيزياء الفلكية، علم المناخ، طاقة الاندماج (Fusion)، وغيرها.
تحسين ترجمة صورة-إلى-رسمة (Image-to-illustration Translation)
GANILLA هو أسلوب يقترح استخدام شبكات الخصومة المولِدة (Generative Adversarial Networks - GANs) لتطوير تحويل كل من النمط الفني (Style) والمحتوى في عملتي ترجمة صورة-إلى-صورة غير مترابطتين. بالتحديد اقترح نموذج لل”صورة-إلى-رسمة” (مع شبكة توليد محسنة) وقيمها بناءً على إطار عمل (Framework) جديد للتقييم الكمي (Quantitative Evaluation) الذي يأخذ بعين الاعتبار كلاً من النمط الفني والمحتوى. ميزة عمله هي شبكة التوليد المقترحة التي تملك موازنة بين النمط الفني والمحتوى فشلت النماذج السابقة في تحقيقها. الشفرة بالإضافة إلى نماذج مدربة مسبقاً تم نشرها. اقرأ كامل الورقة (باللغة الإنجليزية) هنا.

الشكل 1: مثال على مخرجات كل من CycleGAN (3) وDualGAN (4) وطريقتنا (GANILLA) باستخدام أنماط فنية مختلفة. CycleGAN و GANILLAيولدان صور بأسلوب الرسم اليدوي، لكن DualGAN يفشل في تحويل النمط الفني. وعلى الصعيد الأخر فشل CycleGAN في الحفاظ على محتوى الصور المدخلة، على سبيل المثال وضع وجوه حيوانات في الهواء بشكل عشوائي. طريقتنا تحافظ على المحتوى وتغيير النمط في نفس الوقت.
Andrew Ng يتحدث عن الاهتمام بالتعليم الذاتي الإشراف (Self-Supervised Learning)
Andrew Ng، مؤسس deeplearning.ai، شارك في بودكاست الذكاء الاصطناعي ليتحدث عن مواضيع من ضمنها بداياته مع تعلم الآلة، مستقبل الذكاء الاصطناعي وتدريس الذكاء الاصطناعي، اقتراحات لاستخدام صحيح لتعلم الآلة، أهدافه الشخصية وتكنيكيات تعلم الآلة المهمة في القرن الحالي 2020.
Andrew يشرح لماذا هو متحمس جداً بشأن تعلم الإشراف الذاتي الممثل (Self-Supervised Representation Learning). التعليم الذاتي الإشراف يتضمن صياغة مشكلة تعلم تهدف إلى الحصول على رقابة من البيانات نفسها لاستخدام قدر كبير من البيانات الغير مصنفة (Unlabeled) وهي شائعة أكثر من البيانات الواضحة المصنفة (Labeled). التمثيلات (Representations) ذات أهمية في مقابل أداء المهمة ويمكن استخدامها لحل مهام باتجاه التيار (Downstream) مشابهة لما يستخدم في نماذج اللغات مثل BERT.
هناك أيضاً الكثير من الاهتمام لاستخدام التعليم الذاتي الإشراف لتعلم تمثيلات مرئية معممة التي ستجعل النماذج أكثر دقة في الظروف المنخفضة الدقة. مثلاً، طريقة جديدة تسمى SimCLR (كتبت بإشرافGeoffrey Hinton ) تقدم إطار عمل (Framework) للتعلم الذاتي الإشراف المختلف (Contrastive Self-Supervised Learning) لتمثيلات مرئية لتطوير نتائج تصنيف الصور في ظروف مختلفة مثل تحويل التعلم والتعلم شبه المراقب (Semi-Supervised Learning).
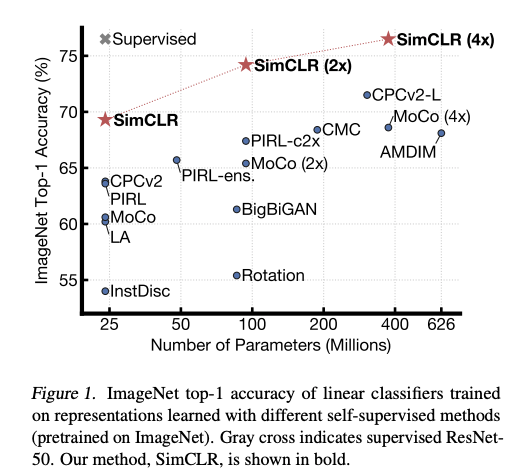
الشكل 1: مقياس Top-1 من مكتبة ImageNet للمصنِفات الخطية المدربة على تمثيلات تم تعلمها بطرائق مختلفة خاضعة للإشراف الذاتي (مدربة مسبقاً على ImageNet). يشير الصليب الرمادي إلى ResNet-50 الخاضع للإشراف. طريقتنا SimCLR، موضحة بالخط العريض.
على محور X مقياس Top-1 السابق ذكره، وعلى محور Y عدد المعاملات بالملايين.
أدوات ومجموعات بيانات ⚙️
مكتبات JAX
JAX هي مكتبة (Library) جديدة تدمج NumPy والاشتقاق الآلي (Automatic Differentiation) لإجراء أبحاث تعلم آلة عالية الأداء. لتبسيط خطوط الأنابيب (Pipelines) لبناء شبكات عصبية باستخدام JAX، DeepMind أصدرت Haiku وRLax.. RLax يبسط تنفيذ وكلاء التعليم المعزز (Reinforcement Learning Agents) وHaiku يبسط بناء الشبكات العصبية باستخدام نماذج برمجة كائنية التوجه (Object-Oriented) مألوفة.
أداة لمعالجة بيانات ويكيبيديا
Sparkwiki هي أداة لمعالجة بيانات ويكيبيديا. هذا الإصدار هو جزء من جهود كثيرة لتفعيل بحوث تحليلية سلوكية مثيرة للاهتمام مثل التقاط الاتجاهات الرائجة وانحيازيات اللغات من إصدارات ويكيبديا بلغاتها المختلفة. المؤلف اكتشف استقلال اللغات، سلوك مستخدمي ويكيبيديا في التصفح يظهر أنهم غالباً ما يشاركون اهتمامات مشتركة للتصنيفات مثل الأفلام، الأغاني، والرياضات، لكن الفروق تتضح في الأحداث المحلية والخصوصيات الثقافية.
مرمزات Rust (Rust Tokenizers)، قاعدة DistilBERT المغلفة (DistilBERT Base Cased)، بطاقات النماذج (Model Cards)
إطلاق محولات (Transformers) جديد من قبل Hugging Face يتضمن دمج مكتبة الترميز السريعة خاصتهم مما يهدف إلى تسريع نماذج مثل BERT، RoBERTa، GPT2، وغيرها من النماذج المجتمعية الصنع.
الأخلاق في الذكاء الاصطناعي 🚨
الاعتبارات الأخلاقية لنماذج معالجة اللغات الطبيعية (NLP) ونماذج تعلم الآلة (ML)
في حلقة جديدة من بودكاست NLP Highlights، تحدثت Emily Bende والمقدمون حول بعض الاعتبارات الأخلاقية عند تطوير نماذج معالجة اللغات الطبيعية والتقنيات في سياق كل من الأكاديميا والاستخدام الفعلي على أرض الواقع. كان من المواضيع في النقاش: الاعتبارات الأخلاقية عند تصميم مهام معالجة اللغات الطبيعية، أساليب جمع البيانات، ونشر النتائج في النهاية.
بالإضافة لكل الاعتبارات في الأعلى، قلق دائم النقاش في مجتمع الذكاء الاصطناعي هو التركيز المفرط على تحسين مقياس، وهذا يتعارض مع أساس ما يحاول الذكاء الاصطناعي تحقيقه. Rachel Thomas و David Uminsky ناقشا متى يمكن أن يصبح هذا خاطئاً عبر تحليل دقيق لحالات استخدام مختلفة. اقترحا أيضاً إطار عمل (Framework) بسيطاً لتخفيف المشكلة ويتضمن استخدام ودمج عدة مقاييس، متبوعاً بإشراك المتضررين من التقنية بشكل مباشر.
المقالات والتدوينات ✍️
GPT-2 المشروح
Aman Arora نشر مؤخراً في تدوينة استثنائية بعنوان “The Annotated GPT-2” (بمعنى GPT-2 المشروح) يشرح فيها تفاصيل عمل النموذج المسمى GPT-2 المبني على محول (Transformer). أسلوبه مستوحى من The Annotated Transformer (بمعنى المحول المشروح) الذي أخذ مسعى الحاشية والملاحظات لشرح أجزاء مهمة من النموذج عبر الشفرة (“الكود”) وشروحات سهلة المتابعة. بذل Aman جهداً عظيماً ليعيد تنفيذ GPT-2 الخاص ب OpenAIباستخدام PyTorch ومكتبة المحولات (Transformers Library) الخاصة ب Hugging Face. إنه عمل عبقري!

محول فك التشفير داخل GPT-2
لإعادة استخدام المصطلحات المستخدمة لوصف المحول، الانتباه (Attention) هو دالة من الاستعلام (Q) ومجموعة المفتاح (K) وأزواج القيمة (V). للتعامل مع المتتابعات الأطول، نقوم بتعديل الاهتمام الذاتي متعدد الرؤوس للمحول ليقلل من استخدام الذاكرة عن طريق الحد من المنتج النقطي بين Q وK في معادلة “الانتباه بمعلومية الاستعلام والمفتاح والقيمة” الظاهرة في الرسم.
ما وراء BERT؟
مقال مثير للاهتمام من كتابة Sergi Castella يتساءل فيه عن أسرار BERT. كان من المواضيع الأساسية: تطوير المقاييس، كيف مكنت مكتبة محولات Hugging Face البحث العلمي، مجموعات بيانات مثيرة تستحق النظر، تشريح نماذج، والمزيد.
عملية ضغط المصفوفات (Matrix Compression Operator)
مدونة TensorFlow نشرت تدوينة تشرح تكنيكات والأهمية وراء ضغط المصفوفات في نموذج شبكة عصبية عميقة. ضغط المصفوفات يمكنه أن يساعد لبناء نماذج صغيرة أكثر كفاءة التي يمكن أن تدمج في أجهزة صغيرة مثل الهواتف والمساعدات المنزلية (Home Assistants). التركيز على ضغط النماذج عبر طرق مثل التقريب المنخفض الرتبة (Low-Rank Approximation) والتكميم (Quantization) يعنى أننا لا نحتاج إلى أن نضر بجودة النموذج.
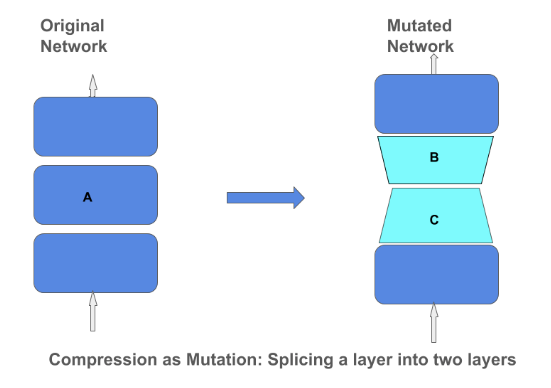
الضغط كتحول: ربط طبقة إلى طبقتين.
على اليسار الشبكة الأصلية، وعلى اليمين الشبكة المتحولة.
التعليم 🎓
أساسيات معالجة اللغات الطبيعية (NLP)
أنا متحمس لنشر مسودة من الفصل الأول من سلسلتي الجديدة المسماة Fundamentals of NLP(أساسيات معالجة اللغات الطبيعية). إنها تعلم مفاهيم معالجة اللغات الطبيعية بدئاً من الأساسيات في أثناء ما تشارك أفضل الممارسات، مراجع مهمة، أخطاء شائعة لتجنبها، وما ينتظرنا في معالجة اللغات العصبية. دفتر كولاب (Google Colab) مرفق والمشروع سيتم تحديثه هنا.

[عبر الانترنت] مراجعة/مناقشة: الجزء 1 جلسة قراءة الأسس الرياضية
Mathematics For Machine Learning تستضيف نقاش على الإنترنت لمراجعة الفصول التي تمت تغطيتها مؤخراً في جلساتهم للدراسة عبر الإنترنت. المجموعة درست سابقاً فصولاً بناءً على كتاب يدعى Mathematics For Machine Learning كتبه Marc Peter Deisenroth وA Aldo Faisal وCheng Soon Ong. الحدث مخطط ليقام في الثامن من مارس 2020.
اقتراحات الكتب
في قطعة سابقة ناقشنا أهمية ضغط المصفوفات لبناء نماذج تعلم آلة صغيرة. إذا كنت مهتماً لتعلم المزيد عن كيفية بناء شبكات عصبية عميقة أصغر للأنظمة المتضمنة (Embedded Systems) خذ نظرة على هذا الكتاب الرائع باسم TinyML (بمعنى: تعلم آلة صغير) من تأليف Pete Warden و Daniel Situnayake.

كتاب آخر مثير للاهتمام للمتابعة هو العنوان القادم “Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD” (بمعنى: التعلم العميق للمبرمجين ب fastai و PyTorch: تطبيقات الذكاء الاصطناعي بدون شهادة دكتوراة) من تأليف Jeremy Howard و Sylvain Gugger. الكتاب يهدف إلى تقديم البناء الرياضي الضروري لبناء وتدريب النماذج لتتعامل مع مهام في مجالات الرؤية الحاسوبية (Computer Vision) ومعالجة اللغات الطبيعية (NLP).

إضافات جديرة بالذكر ⭐️
يمكنك الوصول إلى الإصدار السابق من قائمة معالجة اللغات الطبيعية (NLP) البريدية من هنا.
Torchmeta هي مكتبة (Library) تتيح سهولة الاستخدام لمحملات البيانات (Data Loaders) ذات الصلة لأبحاث التعلم الفوقي (Meta-Learning). كتبها Tristan Deleu.
Manuel Tonneau كتبت مقالاً يقدم نظرة أقرب لبعض الآلات المستخدمة في نمذجة اللغة (Language Modeling). بعض المواضيع تضمنت البحث الجشع (Greedy Search) والبحث الشعاعي (Beam Search) وأخذ العينات النووي (Nucleus Sampling).
MIT نشرت المنهج والجدول الدراسي الكاملين لكورس “Introduction to Deep Learning” (مقدمة إلى التعلم العميق)، بما في ذلك مقاطع الفيديو للمحاضرات التي ألقيت بالفعل. يهدفون إلى نشر مقاطع فيديو وشرائح العرض للمحاضرات أسبوعياً.
تعلم كيف تدرب نموذجاً للتعرف على الكيانات المسماة (Named Entity Recognition (NER)) باستخدام أسلوب مبنى على المحول (Transformer) في أقل من 300 سطر من الشفرة “الكود”. يمكنك العثور على جوجل كولاب المصاحب هنا.
إذا كان لديك أي مجموعات بيانات، مشاريع، تدوينات، شروحات، أو أوراق بحثية تتمنى أن يتم نشرهم في العدد القادم من قائمة معالجة اللغات الطبيعية (NLP) البريدية، لا تترد في التواصل معي عبر البريد الالكتروني ellfae@gmail.com أوالرسائل الخاصة على تويتر.
اشترك 🔖 في قائمة NLP البريدية لتصلك الأعداد القادمة مباشرة على صندوق بريدك.