

Avant-propos d’Elvis
Bienvenue au onzième numéro de la lettre d’information consacrée au NLP. \
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai : \
-
Nous avons publié un jeu de données qui peuvent être utilisées pour la recherche d’émotions basée sur des textes. Le répertoire comprend un notebook) qui montre comment fine-tuner les modèles BERT pré-entraînés pour la tâche de classification des émotions. Plus récemment, un modèle a été fine-tuneé sur notre jeu de données et hébergé sur HuggingFace, permettant une intégration simple à une pipeline de NLP.
-
Nous avons récemment tenu notre toute première séance de lecture de d’articles. Plus de 124 personnes se sont inscrites et une grande partie de ce groupe a participé à l’événement à distance. La première discussion a porté sur le document du T5. Nous organisons une deuxième session où nous aurons une discussion approfondie sur le document. Pour en savoir plus sur les prochains événements, rejoignez notre groupe Meetup, ou participez à la discussion dans notre groupe Slack.
Publications 📙
OpenAI’s Jukebox
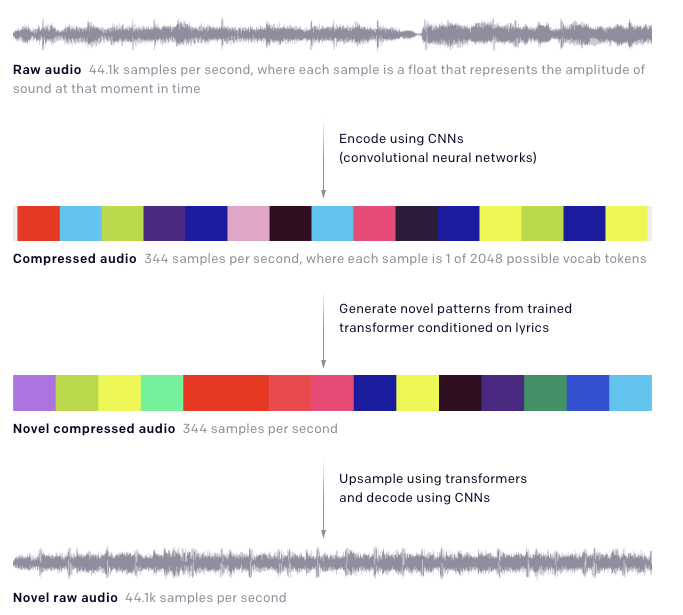
Le dernier travail dévoilé par OpenAI s’appelle Jukebox et est essentiellement une architecture de réseau neuronal entraîné pour générer de la musique (à partir de zéro) dans divers genres et styles artistiques. Le modèle, basé sur une approche de quantification appelée VQ-VAE, est alimenté par le genre, l’artiste et les paroles et produit un nouvel échantillon audio. L’idée est de traiter et de compresser de longues entrées audio brutes via un auto-encodeur à plusieurs niveaux et de réduire la dimensionnalité tout en préservant les informations musicales essentielles. Par la suite, des transformers sont utilisés pour générer des codes qui sont ensuite reconstruits en audio brut via le décodeur VQ-VAE. Plus de détails sur ce travail est disponible sur le blog d’OpenAI ou dans l’article complet.
HybridQA : A Dataset of Multi-Hop Question Answering over
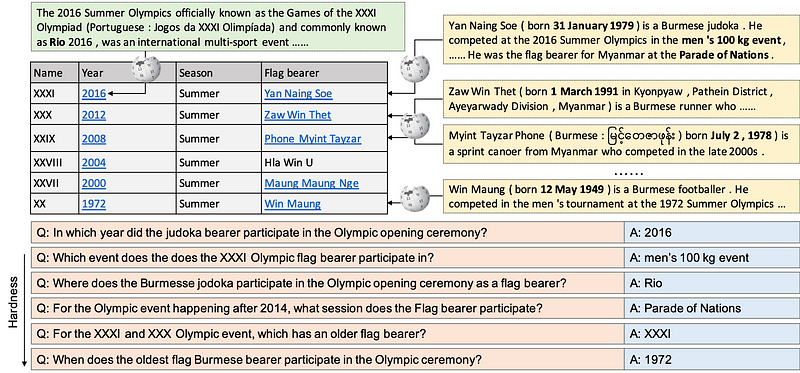
Jusqu’à présent, la plupart des jeux de données répondant aux questions portent sur des informations homogènes. HybridQA est un jeu de données de réponse aux questions à grande échelle destiné à encourager la recherche et les méthodes qui nécessitent un raisonnement sur des informations hétérogènes. L’ensemble de données se compose d’un tableau Wikipédia structuré et d’informations non structurées sous la forme d’entités se liant à des corpus de forme libre. Les auteurs introduisent également deux baselines permettant de souligner les avantages de travailler avec des informations hétérogènes par rapport à l’utilisation d’informations homogènes. Cependant, ils soulignent que les résultats sont loin derrière la performance humaine et que cela nécessite des systèmes d’assurance qualité qui peuvent mieux raisonner sur des informations hétérogènes.
Un chatbot open-source de pointe
Facebook AI a construit et a mis en open source Blender, un modèle basé sur l’IA qu’ils appellent le plus grand chatbot à domaine ouvert. Suite au succès de Meena (un récent système d’IA conversationnelle proposé par Google), ils ont proposé un modèle qui mélange les compétences conversationnelles comme l’empathie et la personnalité afin d’améliorer la qualité de la conversation générée. Le modèle a été entraîné à l’aide d’un modèle basé sur un transformer (jusqu’à 9,4 milliards de paramètres) sur environ 1,5 milliard d’échantillons d’entraînement. Il a ensuite été fine-tuné à l’aide d’un jeu de données (Blended Skill Talk) qui vise à fournir les traits souhaitables identifiés qui pourraient améliorer les capacités conversationnelles du modèle. Les auteurs affirment que le modèle est capable de générer des réponses que les évaluateurs humains ont jugées plus humaines que celles générées par Meena.
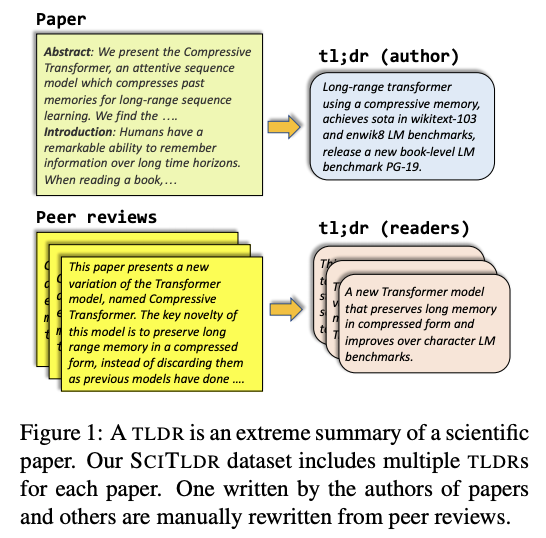
TLDR : résumé extrême d’articles scientifiques
Ce document propose une approche, y compris un jeu de données (SCITLDR), pour la nouvelle tâche de génération de TLDR d’articles scientifiques.
TLDR étant les initiales de « too long ; didn’t read » en anglais. Ce sigle est utilisé pour indiquer que ce qui suit est un résumé du texte trop long.
Dans ce travail, les TLDR sont définis comme une alternative et un résumé compact de l’article scientifique. Les TLDR, comme le suggèrent les auteurs, peuvent servir de moyen de comprendre rapidement le sujet d’un article et éventuellement aider le lecteur à décider s’il veut continuer à lire l’article. Pour la tâche finale, un modèle basé sur BART avec un fine-tuning multitâche (incluant la génération de titres et la génération de TLDR) a été utilisé.
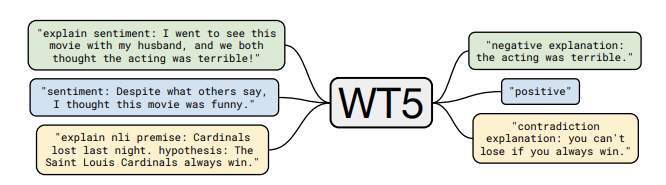
WT5 ?! Entraînement des modèles de texte à texte pour expliquer leurs prévisions
Un nouveau travail appelé WT5 (abréviation de “Why, T5 ?”) fine-tune un modèle T5 de Google pour produire des explications aux prévisions qu’il fait. Cela peut aider à mieux comprendre pourquoi un modèle fait certaines prédictions. Le modèle est alimenté par des exemples avec des explications cibles et des labels cibles. Le texte d’entrée, qui comprend un préfixe de tâche (par exemple, sentiment) et le texte réel peuvent également être précédés d’une étiquette “explain” (voir l’exemple dans la figure ci-dessous). Cela permet un apprentissage semi-supervisé où des données entièrement étiquetées sont fournies au modèle et où seuls des exemples limités ont les balises d’explication. Les auteurs font état de résultats quantitatifs et qualitatifs démontrant que leur approche permet d’obtenir des résultats de pointe sur les ensembles de données d’explicabilité, y compris la capacité à obtenir de bons résultats dans les données hors domaine. Ce travail présente un modèle de base intéressant qui peut être utilisé pour mieux comprendre les prédictions des modèles basés sur le texte mais, comme le soulignent les auteurs, l’approche n’est qu’une amélioration superficielle de l’interprétabilité et qu’il est possible de l’améliorer.
Narang et al. (2020)
Outils et jeux de données ⚙️
NVIDIA’s Medical Imaging Framework
MONAI est un framework d’IA en imagerie médicale destiné à soutenir le développement scientifique dans le domaine des soins de santé. Comme indiqué dans les notes de publication, MONAI vise à fournir une bibliothèque conviviale et optimisée pour le traitement des données relatives aux soins de santé. Comme d’autres bibliothèques, elle fournit également des outils de traitement et de transformation des données spécifiques à un domaine, des modèles de réseaux neuronaux couramment utilisés dans l’espace, y compris l’accès à des méthodes d’évaluation et la possibilité de reproduire les résultats.
Un émulateur Python pour Game Boy
PyBoy est un outil construit en Python capable de gérer une interface Game Boy. Il comprend aussi une enveloppe expérimentale pour entraîner un agent basé sur l’IA qui interagit avec le jeu.
Jupyter Notebooks en PDF
Avez-vous déjà voulu convertir vos notebooks en format PDF ? Cette extension de Jupyter écrite par Tim Head vous permet de produire des PDF à partir de vos ordinateurs portables avec le moins d’exigences possible en termes de plugins et permet de joindre les ordinateurs portables au PDF pour la reproductibilité.
Sur la mise en place de systèmes d’IA conversationnelle plus réalistes
La librairie Transformers comprend maintenant DialoGPT. DialoGPT est un modèle de génération de réponse conversationnelle neuronale à grande échelle proposé par Microsoft. Il diffère des modèles précédents qui dépendent de données textuelles générales telles que Wikipédia et les articles de presse, car il utilise des quantités massives de conversations extraites des commentaires de Reddit. DialoGPT est basé sur le modèle de langage autorégressif basé sur le GPT et vise à fournir un pré-entraînement à grande échelle pour la génération de réponses et de permettre ainsi une IA conversationnelle plus représentative de l’interaction humaine.
TorchServe et [TorchElastic for Kubernetes], nouvelles librairies PyTorch pour servir et entraîner des modèles à l’échelle
TorchServe est une librairie open-source qui permet aux développeurs d’entraîner leurs modèles tout en visant à réduire les frictions dans le processus. L’outil est construit sur PyTorch et permet aux développeurs de déployer leurs modèles en tant que travaux en utilisant AWS. Torchserve est conçu comme la manière canonique de servir les modèles entraînés en fournissant des fonctionnalités telles que le déploiement sécurisé, des API d’inférence, les mesures en temps réel du service d’inférence, et une gestion facile des modèles.
MLSUM : Le corpus multilingue de résumés
Pour encourager et renforcer la recherche multilingue en NLP, des chercheurs de ReciTAL et du CNRS ont récemment proposé un corpus de résumés multilingues. L’ensemble de données a été obtenu à partir de journaux et contient environ 1,5 million d’articles en français, allemand, espagnol, russe et turc.
Made with ML
Au cas où vous l’auriez manqué, Goku Mohandas a construit un site web appelé « Made with ML » qui vise à fournir un outil pour découvrir des projets ML pertinents et intéressants. Il s’agit d’une plateforme qui permet aux créateurs de partager leurs projets avec la communauté. Une récente mise à jour du site web comprend une section qui fournit des sujets soigneusement sélectionnés qui peuvent aider les utilisateurs à trouver rapidement des projets pertinents.
Articles et Blog ✍️
Quelles sont les nouveautés pour les Transformers lors de la conférence ICLR 2020 ?
L’une des plus importantes conférences sur l’apprentissage automatique, l’ICLR, a dû se tenir virtuellement cette année en raison des restrictions de voyage imposées par les pays du monde entier.
Voici quelques articles présentés lors de cette conférence.
Cet [article] (https://towardsdatascience.com/whats-new-for-transformers-at-the-iclr-2020-conference-4285a4294792) résume certains des travaux relatifs aux Transformers qui comprennent des révisions architecturales (par exemple ALBERT, Reformer et Transformer-XH), de nouvelles procédures d’apprentissage (par exemple ELECTRA et Pretrained Encyclopedia) et l’amélioration d’autres domaines tels que la recherche à grande échelle, la génération de texte et les représentations visuelles et linguistiques. Un document fournit une analyse détaillée décrivant les aspects communs des couches d’auto-attention et convolutionnelles, avec des résultats intéressants suggérant que les architectures de Transformers sont une généralisation potentielle des CNN.
Si vous souhaitez en savoir plus sur d’autres travaux publiés dans le cadre de la CIRL cette année, vous pouvez consulter le site Papers with Code website.
Enfin, l’ICLR vient de mettre en libre accès toutes les conférences.
AI Economist : Améliorer l’égalité et la productivité grâce à des politiques fiscales axées sur l’IA
Un groupe de chercheurs a proposé un framework d’apprentissage par renforcement (AI Economist) qui vise à apprendre les politiques fiscales dynamiques uniquement par la simulation et les solutions basées sur des données. Certaines des améliorations obtenues par l’AI Economist montrent des résultats et des calendriers prometteurs qui pourraient déboucher sur un cadre susceptible d’améliorer les résultats sociaux et l’état des inégalités économiques.

Sur l’apport de capacités de raisonnement de bon sens aux systèmes d’IA
L’une des capacités qui font défaut dans de nombreux systèmes d’IA actuels est le raisonnement de bon sens. Cet article présente un bref historique de ce problème et explique comment les chercheurs commencent à progresser dans ce domaine. Un bon nombre des efforts récents comprennent la création de bases de connaissances pour entraîner un réseau neuronal (en particulier des modèles de langage) afin d’apprendre plus rapidement et plus efficacement sur le monde. Cela peut être considéré comme un effort pour combiner le raisonnement symbolique avec les réseaux de neurones afin de traiter les problèmes de couverture et de bruitage des modèles.
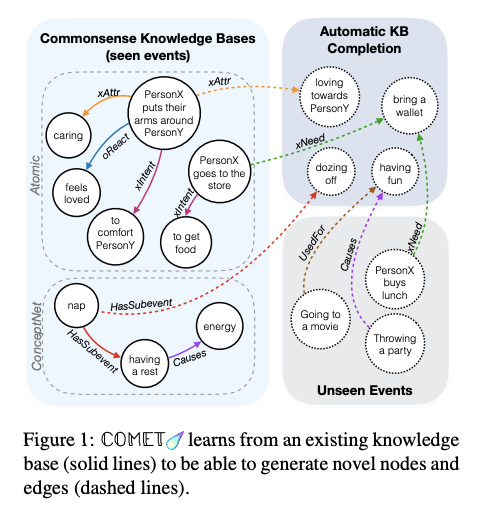
COMET — Bosselut et al. (2019)
Un examen des principaux critères de référence du NLP
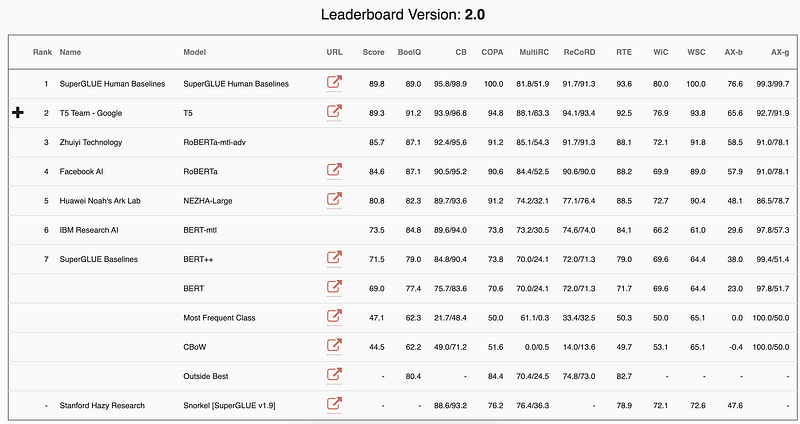
Qu’est-ce que le NLP peut faire de mieux que les humains et où y a-t-il encore des possibilités d’amélioration ? Dans un récent billet de blog, Manuel Tonneau examine les performances du modèle par rapport au benchmark GLUE, en identifiant les tâches où les systèmes de NLP excellent déjà et celles où les humains ont encore une longueur d’avance. Les références SuperGLUE et XTREME sont également présentées comme une initiative visant à placer la barre plus haut et à motiver davantage la recherche sur de nouvelles tâches et de nouveaux langages.
Serveur d’inférence Triton (TensorRT) pour les modèles de Transformers
Dans ce billet de blog les auteurs utilisent le serveur d’inférence Triton (TensorRT) de NVIDIA pour héberger les modèles et expérimenter avec différentes configurations afin de fournir des résultats comparables entre les modèles desservis par TensorFlow et PyTorch. Le rapport comprend les résultats obtenus sur les différents aspects du modèle de service, tels que la latence avec concurrence, le débit avec concurrence, et d’autres configurations impliquant la taille des batchs et la longueur de la séquence. De nombreux aspects du service de modèle sont manquants dans le rapport mais les auteurs sont intéressés par des tests avec le versionnement de modèle et différentes tâches telles que la détection d’objets. Ces guides fournissent les meilleures pratiques et techniques d’évaluation des modèles qui sont utiles aux personnes qui mettent leurs modèles en production.
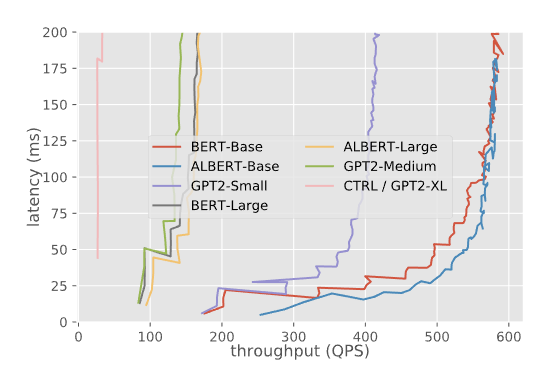
Latence et débit pour différents modèles — source
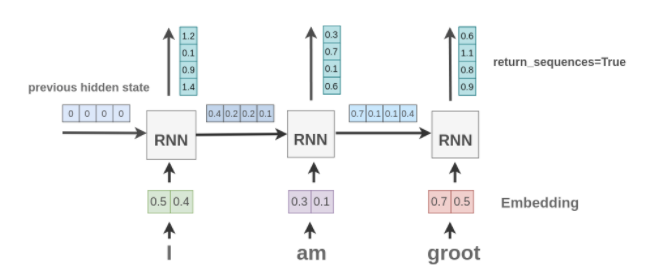
Un guide en Keras pour les couches récurrentes
Cet article d’Amit Chaudhary fournit une explication visuelle des couches récurrentes disponibles dans Keras et de l’effet de divers arguments sur l’entrée et la sortie. Cela vise à fournir une meilleure compréhension de la façon d’interagir avec les couches RNN de Keras lors de la préparation et du traitement des données. Un tutoriel utile pour les débutants intéressés par le langage de modélisation avec les modèles RNN.
Education 🎓
Livre d’apprentissage approfondi pour le cloud, le mobile et les périphériques
Si vous êtes intéressé par l’utilisation de vos modèles d’apprentissage approfondi dans le cloud, les téléphones mobiles et les périphériques, voici un livre écrit par Anirudh Koul, Siddha Ganju et Meher Kasam. Le livre s’intitule “Practical Deep Learning Book for Cloud, Mobile & Edge” et traite de sujets allant du fine-tuning et du déploiement de vos modèles de vision par ordinateur à une introduction de plus de 40 études de cas de l’industrie, en passant par l’utilisation de l’apprentissage par transfert pour entraîner rapidement les modèles.

Cours de ML
- Stanford a mis à disposition un ensemble de vidéos du cours de ML enseigné par Andrew Ng. Ce cours fournit un contenu qui pourrait être utile aux étudiants qui se lancent dans le monde de l’apprentissage automatique.
- Alors que nous mettons en production des systèmes de ML et de NLP pour une utilisation dans le monde réel, il devient crucial de construire des systèmes plus fiables et préservant la vie privée. Ce cours couvre les sujets de l’apprentissage machine fiable.
- Thomas Wolf a enregistré une vidéo qui explique les tendances récentes et les sujets futurs de l’apprentissage par transfert pour le NLP.
Cours sur les GAN
Cette conférence vidéo de Pieter Abbeel donne un aperçu complet des GAN qui sont utilisés aujourd’hui pour toutes sortes d’applications créatives, de la production d’images réalistes à la peinture numérique. Cette conférence fait partie du cours Deep Unsupervised Learning actuellement dispensé à l’université de Berkley. Voir le plan de la conférence ci-dessous.

Calcul différentiel pour l’apprentissage approfondi
Aurélien Geron partage un notebook qui vise à introduire les concepts de base du calcul différentiel tels que les dérivées, les dérivées partielles et les gradients. Ces sujets sont tous importants dans le domaine de l’apprentissage profond et Aurélien Géron résume les concepts ainsi que les mises en œuvre, y compris des visualisations faciles à comprendre pour guider l’apprenant. Il recommande également de consulter un autre notebook sur l’autodifférenciation.
Mentions spéciales ⭐️
- Andrej Karpathy partage certains des développements récents chez Tesla afin d’aboutir à une conduite autonome complète. Les sujets abordés comprennent la modélisation des HydraNets, les moteurs de données, les mesures d’évaluation et la manière d’effectuer efficacement des inférences sur ces modèles de réseaux neuronaux à grande échelle.
- Il s’agit d’un dépôt préparé par MLT contenant une liste d’outils interactifs pour l’apprentissage automatique, l’apprentissage approfondi et les mathématiques.
- Un récent document vise à fournir un aperçu concis des coûts associés à l’entraînement de grands modèles de NLP et la manière de calculer ces coûts.
- Springer a mis à disposition gratuitement des centaines de livres dont les titres vont des mathématiques à l’apprentissage approfondi. Cet article résume certains des livres relatifs à l’apprentissage machine qui peuvent être téléchargés gratuitement.
- Kra-Mania est une application simple de question-réponse construite avec Haystack en utilisant un jeu de données d’assurance qualité ouvert construit à partir de l’exposition Seinfeld. Ce tutoriel montre à quel point il est facile de construire des pipelines d’assurance qualité avec la librairie. Et ce lien vous emmène à l’application de démonstration.
- L’explicabilité est le processus par lequel les chercheurs visent à mieux comprendre les réseaux neuronaux profonds. Ce document fournit un “guide de terrain” sur l’explicabilité de l’apprentissage profond pour les non-initiés.
- Voici une petite enquête décrivant les travaux récents sur l’augmentation des données, qui est devenue un domaine d’étude populaire en ML et en NLP.
- Dans la newsletter précédente, nous avons présenté Longformer, une variante du Transformer qui améliore les performances de diverses tâches de NLP, en particulier pour les documents longs. Dans cette vidéo, Yannic Kilcher explique la nouveauté proposée dans ce travail.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.