

Avant-propos d’Elvis
Bienvenue au douzième numéro de la lettre d’information consacrée au NLP.
Cela fait environ un mois que nous n’avons pas publié de nouveau numéro de la newsletter. L’interruption est terminée et nous sommes heureux de vous présenter d’autres travaux issus des communautés de l’apprentissage automatique et du traitement du langage naturel qui ont eu lieu au cours des dernières semaines.
Nous avons pris le temps de réfléchir à la manière d’améliorer la newsletter et avons reçu d’excellents commentaires. Nous vous remercions pour votre soutien.
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai:
La communauté dair.ai a produit un travail incroyable et a contribué à améliorer la démocratisation de l’éducation, de la recherche et des technologies. Voici ce que nous avons fait au cours des dernières semaines :
- ML Visuals est un nouvel effort de collaboration pour aider la communauté d’apprentissage machine à améliorer la communication scientifique en fournissant gratuitement des visuels et des figures professionnelles en rapport avec ML. Vous êtes libre d’utiliser les visuels dans vos présentations ou vos articles de blog.
- Notre discussion hebdomadaire tente de réunir des experts et des débutants pour s’informer mutuellement sur les publications parues récemment en NLP et ML. Il n’y a pas d’exigences pour participer, il suffit d’apporter votre volonté d’apprendre et nous serons heureux de vous aider en répondant à vos questions et en nous engageant dans des discussions plus approfondies sur les articles de ML.
- Début août, nous lancerons notre premier groupe d’étude. Nous couvrirons l’excellent livre intitulé “Dive into Deep Learning” d’Aston Zhang, Zack C. Lipton, Mu Li et Alex J. Smola. Pour en savoir plus sur ce programme, consultez notre page Meetup. Il n’y a pas de conditions préalables mais nous vous fournirons de nombreux documents à lire pour être mieux préparé aux leçons.
- Vous pouvez consulter nos récentes conférences sur cette chaîne YouTube. Cet effort vise à mieux faire connaître le travail des ingénieurs et chercheurs en NLP. Si vous souhaitez donner une conférence, veuillez consulter cet appel à conférence.
Publications 📙
Language Models are Few-Shot Learners
Jusqu’à présent, nous avons constaté le succès des modèles Transformers pour toute une série de tâches de NLP. Récemment, Brown et al. (2020) ont proposé le GPT-3, un modèle de langage autorégressif qui s’appuie sur le GPT-2, avec une taille de 175 milliards de paramètres. C’est le plus grand modèle de LM jamais formé et il vise à répondre à la question de savoir si l’augmentation de la taille du LM (en termes de taille) améliore les performances de nombreuses tâches de NLP. En outre, la question plus importante est de savoir si le modèle de LM étendu peut effectuer du few-shot learning pour ces tâches et comment cela se compare à d’autres paradigmes d’apprentissage comme le fine-tuning, le one-shot learning, et le zero-shot learning. Il est intéressant de noter que le modèle fonctionne très bien pour une variété de tâches, mais qu’il est moins performant pour les tâches qui exigent un certain niveau de raisonnement de bon sens. L’avantage du grand modèle de LM semble être qu’il ne nécessite pas de fine-tuning (dans une variété de cas), ce qui signifie qu’à un certain point, il pourrait être possible d’étendre facilement l’apprentissage à des tâches en aval encore plus complexes et nouvelles sans avoir besoin de collecter des ensembles de données supervisées.

Source: Brown et al. (2020)
Générer des notes SOAP à partir de conversations médecin-patient
La documentation électronique des dossiers de santé implique un processus rigoureux et long, généralement préparé manuellement par les médecins qui consacrent de longues heures à cette tâche. C’est pourquoi Khrisna et al. (2020) proposent une approche pour aider à automatiser la génération de la documentation sous forme de notes SOAP. Les auteurs expérimentent différentes approches de ML en tirant parti des conversations qui ont lieu entre les médecins et les patients lors d’une visite. Leur approche combine des modules d’extraction et d’abstraction entraînés aux conversations cliniques et obtient des scores ROUGES élevés pour la tâche de rédaction des notes SOAP.
BLEURT : Apprendre des mesures robustes pour la génération de textes
Il est bien connu dans le domaine du NLP que certaines mesures d’évaluation (par exemple, BLEU et ROUGE) ne sont pas les plus fiables. Sellam et al. (2020) proposent une mesure d’évaluation appelée BLEURT qui peut mieux modéliser les jugements humains. La métrique de génération de texte est basée sur BERT et vise à satisfaire l’expressivité et la robustesse par un pré entraînement sur de grandes quantités de données synthétiques. Par rapport à d’autres mesures (par exemple, Meteor et BLEU) utilisant les modèles BERT vanilla, BLEURT tend à mieux modéliser l’évaluation humaine et donc à être plus performant en termes de précision.
Si vous souhaitez une mise à jour des différents paramètres d’évaluation utilisés en NLP, cette récente enquête fournit une discussion approfondie de l’évaluation en NLP.
Raisonnement différent pour le texte
Les moteurs de recherche actuels permettent généralement d’utiliser une requête pour obtenir des pages ou des informations pertinentes. Cependant, ils ne sont pas aussi performants lorsqu’il s’agit d’obtenir des réponses à des requêtes qui impliquent plusieurs documents pour arriver à une réponse, comme c’est le cas avec les réponses à des questions à sauts multiples. Les méthodes actuelles utilisent soit une extraction + lecture (soutenue par un DNN), soit une base de connaissances pour effectuer une certaine forme d’extraction afin d’aider à traiter cette tâche particulière et à trouver des réponses raisonnables à ces questions. Cette dernière méthode fonctionne bien jusqu’à ce que l’information soit mise à l’échelle et que la traversée sur le graphique des connaissances devienne impossible. Il est important de parcourir le graphique efficacement pour aboutir à une réponse. Bhuwan Dhingra propose un système de bout en bout dans lequel l’opération de traversée est différenciée et peut être entraînée efficacement, même sur de grands corpus comme Wikipédia. Grâce à cette approche, la méthode est capable de raisonner sur un texte et de répondre à des questions, même celles qui nécessitent plusieurs sauts. L’auteur fournit également une démo qui présente le système utilisé pour répondre à des questions à sauts multiples.

Source: CMU Blog
DE⫶TR : Détection d’objets de bout en bout avec des Transformers
Carion et al. (2020) proposent un nouvel algorithme de détection d’objets qui exploite l’architecture de l’encodeur-décodeur du Transformer pour la détection d’objets. Le DETR, comme on appelle le modèle, est un système non-autoregressif de bout en bout qui fait des prédictions en parallèle, ce qui permet au modèle d’être rapide et efficace. La nouveauté réside dans l’utilisation directe d’un bloc Transformer pour effectuer la tâche de détection d’objet, qui est présentée comme un problème d’image à image. Cette tâche est chaînée avec un CNN qui extrait les informations locales des images. Cela signifie que le bloc Transformer est chargé de raisonner sur l’image dans son ensemble et de produire en parallèle l’ensemble final de prédictions. L’idée générale est de permettre le raisonnement des relations entre les objets et le contexte global de l’image, ce qui est utile pour la prédiction des objets dans une image.

DETR: source
Publications de type enquête
Si vous commencez à faire du NLP basé sur un apprentissage approfondi, la plupart des gens vous recommandent de commencer par apprendre à écrire le code pour les tâches de classification ou les pipelines de collecte de données. Ces enquêtes peuvent vous aider à développer votre intuition pour ces taches :
- Deep Learning Based Text Classification: A Comprehensive Review
- Contextual Word Representations: Putting Words into Computers
- Natural Language Processing Advancements By Deep Learning: A Survey
- A Survey on Data Collection for Machine Learning: a Big Data — AI Integration Perspective
Découverte de modèles symboliques issus d’un apprentissage approfondi avec des biais inductifs
Cranmer et al. (2020) ont développé une approche de réseau neuronal graphique (GNN) pour apprendre des représentations de faible dimension qui sont ensuite exploitées pour découvrir et extraire des relations physiques par régression symbolique. En tirant parti des forts biais inductifs des GNN, le cadre proposé peut être appliqué sur des données à grande échelle et entraîné à adapter les expressions symboliques aux fonctions internes apprises par le modèle. En utilisant les GNN, les auteurs ont pu entraîner le modèle à apprendre des représentations interprétables et à améliorer la généralisation de celui-ci. Les cas d’utilisation abordés avec la méthodologie comprennent la redécouverte des lois de la force, la redécouverte des Hamiltoniens, et l’application à un défi astrophysique du monde réel (prévision de la quantité de matière en excès pour un halo de matière noire.).
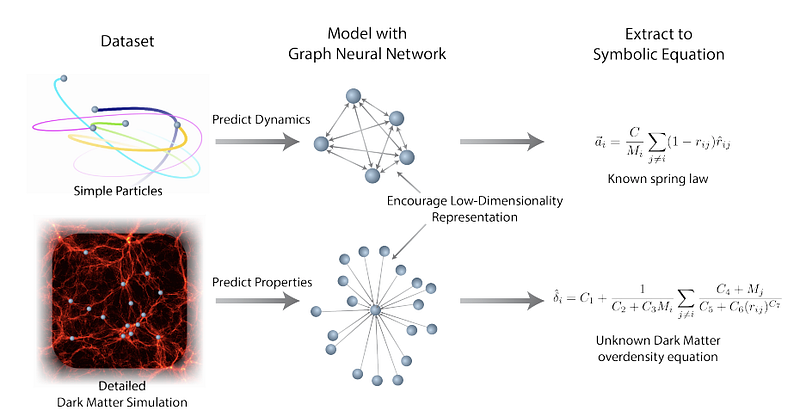
Figure par Cranmer et al. (2020)
Outils et jeux de données ⚙️
NLP de HuggingFace
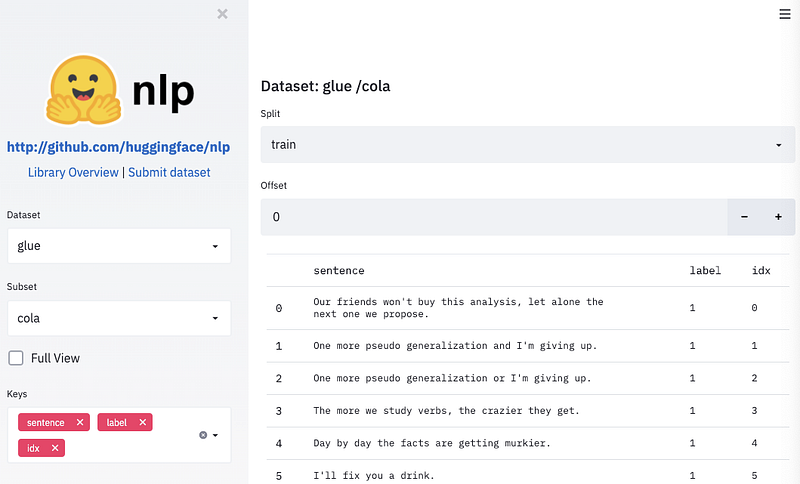
HuggingFace a publié une librairie Python appelée nlp qui vous permet de partager et de charger facilement des données/métriques avec un accès à plus de 100 ensembles de données NLP. Parmi les avantages de cette librairie, on peut citer l’interopérabilité avec d’autres bibliothèques de ML, la rapidité d’exécution, l’utilisation efficace de la mémoire, la mise en cache intelligente, et bien d’autres choses encore. La librairie est accompagnée d’un site web pour explorer les ensembles de données.
Hateful Memes Challenge
Le Hateful Memes Challenge est un concours visant à aider à construire des systèmes multimodaux plus efficaces pour les discours de haine. Dans le cadre de ce défi, un ensemble de données à grande échelle appelé Hateful Memes est fourni. Il combine texte et images, ce qui en fait une tâche difficile. L’ensemble de données a été créé par Facebook AI et hébergé par DrivenData. La cagnotte est de 100 000 dollars, sans compter que la compétition fait également partie du parcours du concours NeurIPS. Vous pourrez également trouver le code de démarrage pour vous familiariser avec la tâche.

TextAttack
TextAttack est une librairie Python permettant de développer différentes attaques adverses en NLP et d’examiner les résultats des modèles, d’accroître la généralisation des modèles par l’augmentation de données et d’entraîner facilement les modèles de NLP à l’aide de commandes de base.
GameGAN
NVIDIA a entraîné un nouveau modèle d’IA appelé GameGAN qui prend en entrée 50000 épisodes du populaire PAC-MAN et apprend les règles de l’environnement en regardant le scénario impliquant un agent se déplaçant dans le jeu. NVIDIA affirme qu’il s’agit du premier modèle de réseau neuronal capable d’imiter un ingénieur de jeu informatique en utilisant des GAN. Cette capacité peut être utilisée par les développeurs de jeux pour automatiser la génération de mises en page pour différents niveaux de jeu ou même construire des systèmes de simulation plus sophistiqués.
Question de compréhension : COVID-Q : Plus de 1 600 questions sur la COVID-19
Nous avons récemment assisté à une explosion des applications NLP utilisées pour mieux comprendre les ensembles de données liés à la COVID-19. Récemment, une équipe de chercheurs a créé un ensemble de données comprenant environ 1 600 questions liées à la COVID, annotées par catégorie et type de question. Voici quelques liens utiles si vous souhaitez en savoir plus sur le projet : ensemble de données sur GitHub, article, et article de blog. Si vous souhaitez savoir comment créer un tel ensemble de données, l’un des auteurs présentera son expérience dans le cadre de l’une de nos rencontres en ligne.
Articles et Blog ✍️
Recettes pour construire un chatbot à domaine ouvert
Constanza Fierro a récemment publié un article sur les marches à suivre afin de créer un chatbot à domaine ouvert. L’article vise à résumer un agent conversationnel proposé par l’IA de Facebook, BlenderBot, qui améliore la conversation grâce à un fine-tuning sur des ensembles de données qui mettent l’accent sur la personnalité, l’empathie et la connaissance. Une des nouveautés de ce travail est la capacité d’entraîner les modèles à générer et à avoir un dialogue plus humain, même avec des modèles plus petits.
Apprentissage machine sur les graphiques : Un modèle et une taxonomie complète
Cette étude fournit une taxonomie complète des approches qui visent à apprendre les représentations graphiques. Les auteurs présentent un nouveau cadre pour unifier les différents paradigmes qui existent pour les méthodes d’apprentissage des représentations graphiques. Cette unification est importante pour mieux comprendre l’intuition derrière les méthodes et pour faire progresser ce domaine de recherche.
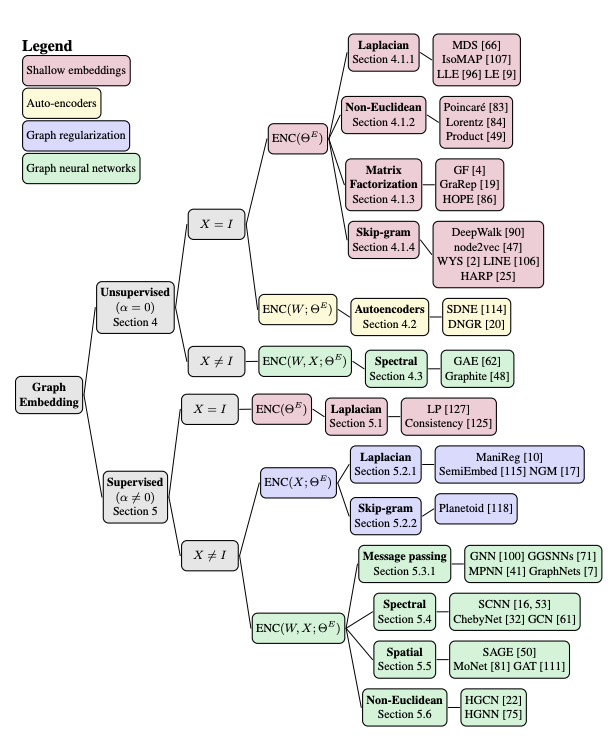
Source: https://arxiv.org/abs/2005.03675
Zero-Shot Learning en NLP
L’un des objectifs ambitieux des chercheurs en ML est de créer des systèmes d’IA capables d’effectuer du zero-shot learning, ce qui, dans le contexte du NLP, signifie simplement concevoir et entraîner un modèle à effectuer une tâche pour laquelle il n’a pas été explicitement entrainé. En d’autres termes, vous pouvez effectuer de nouvelles tâches de NLP sans aucun fine-tuning, comme le GPT-2 l’a fait pour la traduction automatique. Si vous souhaitez en savoir plus sur les approches sur ce sujet, Joe Davidson a écrit un article de blog détaillé sur le sujet qui comprend même une démo et un Colab.
Un autre guide illustré à consulter est celui d’Amit Chaudhary qui explique comment le zero-shot learning est utilisé pour la classification de textes.
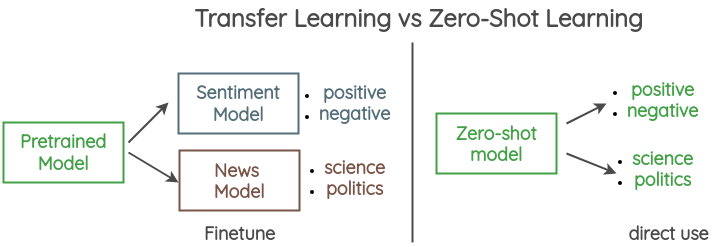
Source: Amit Chaudhary
Recherche en IA, reproductibilité et incitations
Dans un récent article de blog, Denny Britz aborde les questions de la reproductibilité de l’apprentissage approfondi ainsi que les systèmes d’incitation universitaires et notamment la manière dont ceux-ci sont à l’origine de certaines tendances de la recherche dans la communauté du NLP. Parmi les sujets abordés figurent les différences entre reproduction et réplication, le budget de calcul, les protocoles d’évaluation, l’incompréhension de l’open source et les incitations du haut vers le bas et du bas vers le haut. C’est un article intéressant car il aborde des sujets tels que le budget de calcul et la reproductibilité, qui font généralement défaut dans les rapports scientifiques. Denny aborde également l’idée du billet de loterie gagnant qui déclare que le fait de trouver une variante du modèle qui fonctionne pour vos expériences n’implique pas qu’elle se généralisera à des données sur différentes distributions de données. En fait, dans la majorité des cas, les billets perdants ou le reste des variations échouées ne sont pas signalés et ce que vous obtenez est généralement un papier poli. Alors, comment pouvons-nous reproduire le chemin complet vers la conclusion ?
Education 🎓
Fun Python
Rada Mihalcea a dévoilé une série complète de notebooks Python pour se familiariser avec Python. Le matériel couvre les concepts de base en Python et a été conçu pour les élèves de 10 à 12 ans.

Deep Mind x UCL : Série de conférences sur l’apprentissage profond
DeepMind a publié une série de conférences vidéo gratuites couvrant des sujets relatifs à l’apprentissage machine qui vont des modèles avancés pour la vision par ordinateur aux réseaux adversaires générateurs en passant par l’apprentissage de la représentation non supervisée.
Exemples de codes Keras
Au cours des derniers mois, la communauté a ajouté plusieurs exemples de code sur le site web de Keras. Les exemples vont des modèles de NLP aux algorithmes de vision par ordinateur en passant par les architectures d’apprentissage génératif.
Applied Machine Learning 2020
Andreas Muller publie des vidéos de son cours, Applied Machine Learning 2020. Celui-ci comprend des sujets comme l’introduction aux réseaux de neurones, les séries chronologiques et les prévisions, le clustering, etc.
Deep Learning Drizzle
Au cas où vous auriez du mal à trouver des cours de NLP ou de ML, ce site web possède l’une des bases de données de cours en ligne les plus complètes. La plupart d’entre eux sont disponibles sous forme de conférences video.

Source: Deep Learning Drizzle
CMU Neural Nets for NLP 2020
Graham Neubig publie toutes les conférences vidéo du cours intitulé “Neural Networks for NLP” (édition 2020). Le cours couvre des sujets tels que les CNN pour le texte, les astuces d’efficacité pour le NLP, l’attention, le multitâche et l’apprentissage multilingue. Il contient également des notebooks d’accompagnement avec des mises en œuvre de certains concepts abordés dans le cours.
PyTorch Recipes
PyTorch Recipes est une collection de tutoriels PyTorch qui vise à enseigner aux utilisateurs les caractéristiques spécifiques de PyTorch. Ils sont destinés à être facilement applicables et sont différents des longs tutoriels qui sont également disponibles sur le site web.
Rester informé 🎯
Ces dernières années, nous avons assisté à une explosion de projets et de documents sur le ML. Il est devenu difficile de suivre ce qui se passe et les tendances en matière de ML. Nous avons également vu des efforts incroyables de la part de la communauté pour aider à distiller cette information. À partir de ce numéro de la newsletter, nous allons inclure une section présentant certaines des ressources qui devraient aider les lecteurs à suivre et à rester informés sur les questions intéressantes et urgentes en matière de ML. Voici la liste de ce numéro :
- Underrated ML Podcast : un podcast qui présente des idées sous-estimées sur le ML
- Papers with Code : site web qui permet d’améliorer l’accessibilité des dernières publications via l’explication de codes.
- Made with ML : plateforme communautaire qui permet de se tenir au courant des derniers projets de ML.
- ML Paper Discussions : discussion hebdomadaire sur les derniers articles de ML et de NLP
- Yannic Kilcher : chaîne YouTube fournissant d’excellentes explications d’articles.
Mentions spéciales ⭐️
- Deeplearning.ai publie les deux premiers cours consacrés au PNL. Les cours 3 et 4 seront bientôt publiés.
- Cet article présente un aperçu mathématique des réseaux neuronaux discriminants et des réseaux neuronaux générateurs. Il a été écrit par Gabriel Peyré.
- YOLOv4 est la dernière mise à jour du populaire algorithme de détection d’objets qui vise à fournir un algorithme plus rapide pour localiser et classifier les objets.
- Suraj Patil propose ce tutoriel sur la façon d’affiner le modèle T5 à l’aide de la librairie Transformers.
- VidPress est l’un des derniers outils construits par Baidu pour créer des vidéos directement à partir d’articles textuels.
- Enfin quelques implémentations pour la tâche de questions/réponses utilisant PyTorch. C’est un travail réalisé par Kushal.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.