

Avant-propos d’Elvis
Bienvenue au treizième numéro de la lettre d’information consacrée au NLP.
Dans ce numéro, nous abordons des sujets qui vont des travaux présentés lors de la conférence ACL aux outils permettant d’améliorer l’exploration des documents et des codes, en passant par plusieurs recommandations utiles en NLP.
Nous remercions tout particulièrement Keshaw Singh et Manikandan Sivanesan pour leur contribution significative à cette édition de la lettre d’information de la NLP.
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai :
- Dans l’une de nos prochaines conférences, le Dr Juan M. Banda discutera de la motivation et de la raison d’être de sa boîte à outils pour l’exploitation des médias sociaux (Social Media Mining Toolkit (SMMT) ainsi que de la manière de l’utiliser pour définir des frameworks pour la collecte de données à grande échelle sur les médias sociaux pour les projets de recherche en NLP et en ML. Il présentera toutes les leçons apprises, les erreurs et les décisions difficiles prises pour produire et maintenir un ensemble de données à grande échelle sur la COVID-19 issues de conversations sur Twitter. Le jeu de données comprent plus de 424 millions de tweets dans plus de 60 langues et provenant de plus de 60 pays.
- Nous avons récemment organisé un stream en direct sur comment débuter en NLP. Si vous débutez en NLP et que vous cherchez des conseils de recherche, n’hésitez pas à consulter la discussion. Si vous souhaitez être informé, vous pouvez vous inscrire sur la chaîne YouTube ou sur la page Meetup.
- Dans la prochaine discussion, nous discuterons du document intitulé “Deep Learning Based Text Classification: A Comprehensive Overview ».
Publications 📙
Au-delà de la précision : test comportemental de modèles de NLP avec CheckList
L’une des stratégies les plus courantes pour mesurer la généralisation dans les modèles de NLP consiste à évaluer des séries de tests. Bien qu’utile, cette approche présente deux inconvénients majeurs : la surestimation de la capacité de généralisation d’un modèle et l’incapacité à déterminer ses points d’échec. Dans un travail présenté lors de l’ACL de cette année (qui a également remporté le prix du meilleur article), Ribeiro et al. (2020) proposent une méthodologie d’évaluation plus complète qui est à la fois agnostique au modèle et à la tâche.
Elle applique le principe de test comportemental consistant à “découpler le test de la mise en œuvre” en traitant le modèle comme une boîte noire, ce qui permet de comparer différents modèles entraînés à partir de données différentes. Le code, à l’aide de modèles et d’autres abstractions, permet aux utilisateurs de générer facilement un grand nombre de cas de test. Le travail contient également de multiples études d’utilisateurs, démontrant l’efficacité de ce framework pour identifier les points d’échec dans les modèles commerciaux et de l’état de l’art.
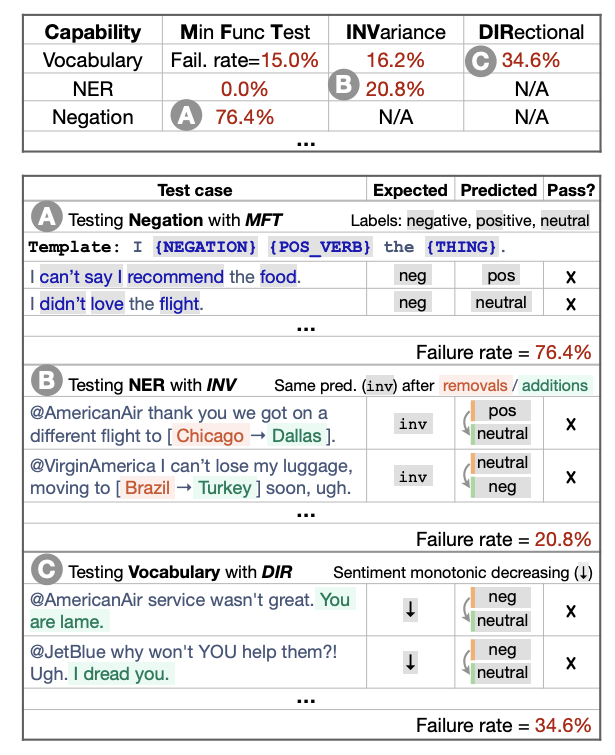
CheckListing a commercial sentiment analysis model (source)
TaBERT : un nouveau modèle pour comprendre les requêtes des tables de la base de données
Aujourd’hui, la plupart des approches sont surtout entraînées pour apprendre à partir d’un langage libre mais pas des tables de la base de données. TaBERT est le premier modèle à soutenir une compréhension commune des phrases en langage naturel et des données tabulaires. Cette compréhension commune des informations dans différents formats de données est importante dans des domaines tels que la compréhension des questions, où il faudrait un modèle capable d’analyser sémantiquement des bases de données pour répondre à une requête. TaBERT peut permettre différents cas d’utilisation commerciale tels que poser directement des questions sur un produit lorsque la réponse existe dans une base de données particulière de produits ou de transactions de commerce électronique.
Climbing towards NLU : Sur le sens, la forme et la compréhension à l’ère des données
Dans une autre publication primée lors de la conférence du ACL de cette année, les professeurs Emily M. Bender et Alexander Koller plaident pour une compréhension claire de la distinction entre forme et sens dans la recherche contemporaine en NLP. En se concentrant sur le débat autour de la question de savoir si les grands modèles linguistiques pré-entraînés comme BERT et GPT-2 “comprennent” le langage, ils avancent l’argument suivant : “la tâche de modélisation du langage, parce qu’elle n’utilise que la forme comme données d’entraînement, ne peut en principe conduire à l’apprentissage du sens”. Le document contient également plusieurs expériences de réflexion perspicaces, dont une qu’ils appellent “le test du poulpe”. Enfin, les auteurs appellent à une approche plus descendante de la recherche future en NLP, et proposent quelques bonnes pratiques sur la manière de relever les défis qui s’y trouvent.
La lutte contre le changement climatique grâce à l’apprentissage automatique
Pouvons-nous utiliser des méthodes d’apprentissage automatique pour réduire les émissions de gaz à effet de serre ? Ce document examine le paysage des méthodes de blanchiment d’argent pour atténuer ce problème et éventuellement lutter contre le changement climatique. En plus de fournir un aperçu complet des méthodes de blanchiment d’argent appliquées dans différents secteurs (par exemple, les transports, les systèmes électriques, les bâtiments et les villes, etc.) et des problèmes spécifiques (par exemple, l’urbanisme, l’optimisation des chaînes d’approvisionnement, etc.), les auteurs fournissent également des recommandations, un appel à la collaboration et des opportunités commerciales pour lutter contre le changement climatique.
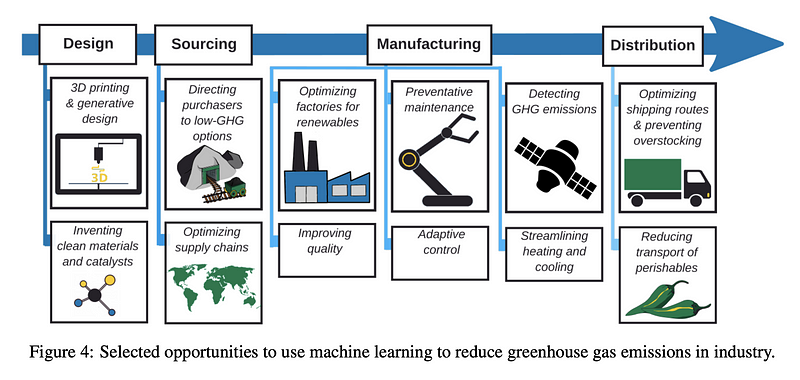
*Figure par Rolnick et al. (2020)
Embeddings contextuels : Quand en valent-ils la peine ?
Des embeddings contextuels profonds comme ELMo et BERT ont été largement utilisés dans l’industrie ces dernières années, en plus de permettre des progrès rapides sur plusieurs critères de référence comme GLUE. Outre les coûts importants en termes de temps et de mémoire lors de l’entraînement, il y a des coûts supplémentaires lors du fine-tuning ou de l’inférence sur les tâches en aval. Dans un travail présenté lors de l’ACL qui vient de s’achever, Arora et al. (2020) évaluent les avantages de l’utilisation des embeddings BERT par rapport aux embeddings non contextuels (GloVe, aléatoire). Grâce à leurs expériences sur des tâches de référence en aval comme la reconnaissance d’entités nommées (NER), l’analyse des sentiments et les tâches de compréhension du langage naturel (GLUE), ils montrent qu’il est souvent possible d’obtenir des performances absolues de 5 à 10 % de celles des embeddings BERT en utilisant GloVe ou des embeddings aléatoires.
Définir et évaluer une génération de langue naturelle équitable
Présenté lors du ACL 2020 Widening NLP Workshop, le travail de Catherine Yeo et Alyssa Chen se concentre sur les biais qui apparaissent dans la tâche de génération du langage que constitue l’achèvement des phrases. En particulier, elles présentent un cadre mathématique de l’équité, suivi d’une évaluation des préjugés sexistes dans GPT-2 et XLNet. Leur analyse fournit une formulation théorique pour définir les biais en NLG et des preuves empiriques que les modèles de génération du langage existants intègrent les préjugés liés au genre.
Smart To-Do : Génération automatique d’éléments à faire à partir de courriers électroniques
Nous sommes nombreux à connaître la fonction Smart Reply que nous voyons sur nos applications de courrier électronique. Mukherjee et al. (2020) explorent une nouvelle façon de stimuler la productivité des utilisateurs, en créant automatiquement des listes de tâches à partir des fils de discussion. Ce qui différencie cette tâche des autres tâches de génération de langage (par exemple, le résumé des conversations par courriel, les titres des nouvelles) est sa nature focalisée sur l’action, c’est-à-dire l’identification de la ou des tâches spécifiques à effectuer.
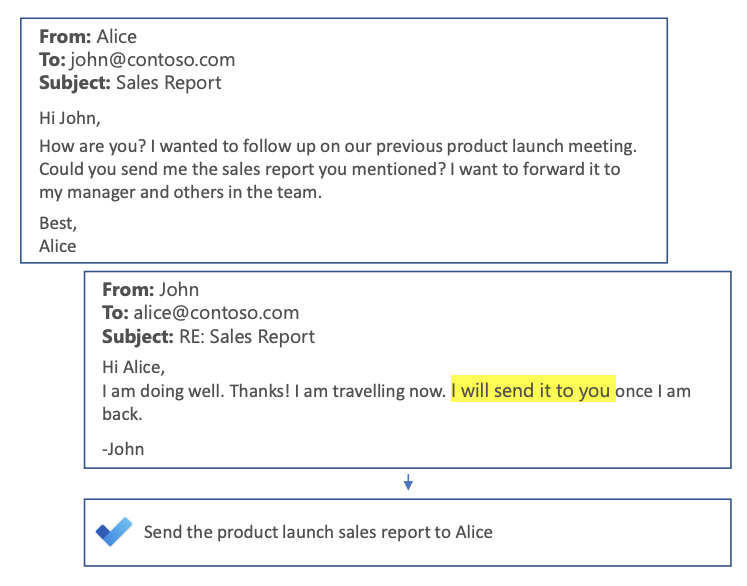
Sample To-Do list generation (source)
Outils et jeux de données ⚙️
Transformer v3.0
L’équipe de Hugging Face a publié une nouvelle version de sa librairie Transformers. Dans la nouvelle version 3.0 de Transformers, ils ont amélioré la documentation, renforcé les capacités de tokenisation et proposé plusieurs améliorations et ajouts de modèles.
Texthero
Texthero est une boîte à outils Python permettant de travailler plus efficacement avec des ensembles de données textuelles. Elle peut être utilisée par les personnes qui se lancent dans le NLP et qui cherchent à construire rapidement un pipeline NLP pour comprendre les données avant de les modéliser. C’est également un excellent outil pour enseigner les concepts de NLP puisqu’il offre une API pour interagir facilement et efficacement avec des ensembles de données textuelles.
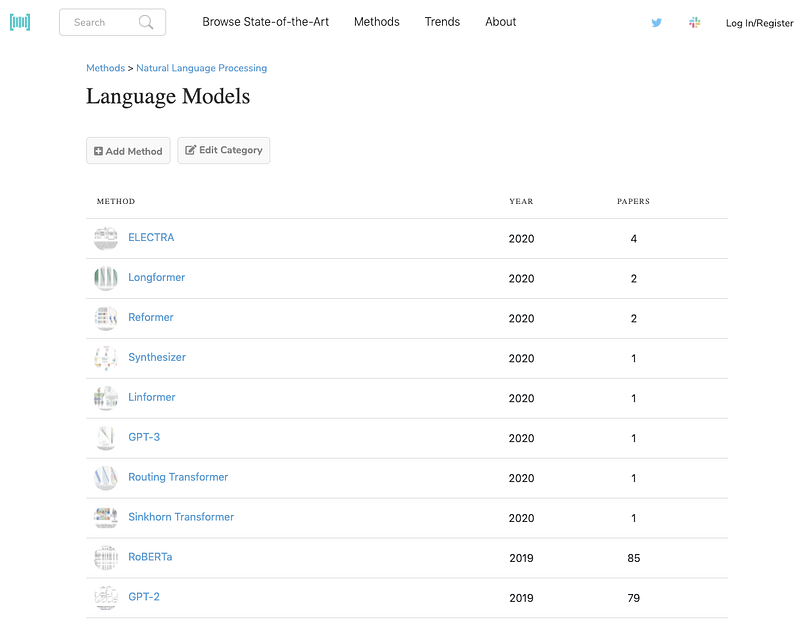
Papers with Code Methods
L’équipe de Papers with Code a récemment lancé une nouvelle fonctionnalité appelée Methods qui permet aux utilisateurs de mieux rechercher, naviguer et découvrir les différents éléments constitutifs de l’apprentissage machine tels que les optimiseurs, les fonctions d’activation, l’attention, et bien plus encore. Grâce à cette fonctionnalité, vous pouvez désormais facilement connaître les progrès réalisés en termes de méthodes dans le domaine de la NLP. Vous pouvez même suivre l’utilisation de ces méthodes au fil du temps et les tâches qu’elles soutiennent.
Code Finder for Research Papers
Cette extension de navigateur gratuite récemment publiée est utile pour trouver et afficher automatiquement des liens vers des implémentations de code pour les documents ML n’importe où sur le web, comme Google Search, Arxiv, Twitter, Scholar et d’autres sites.
Articles et Blog ✍️
Rendre multilingue des phrases monolingues par la distillation des connaissances
Le codage de la sémantique des mots et des phrases est une chose que nous considérons comme allant de soi et dont les systèmes de NLP de pointe sont capables. SentenceBERT fournit des exemples illustrant la manière dont nous pouvons utiliser au mieux les architectures basées sur des transformers dans des tâches telles que le regroupement et la similarité sémantique des textes. Ce modèle est toutefois limité au traitement de séquences de texte provenant d’une seule langue, ce qui, dans certains cas, peut être le facteur qui vous empêche de déployer un tel modèle en production. Il serait donc intéressant de trouver un moyen d’étendre ces modèles au domaine du multilinguisme, ce que Reimers et al. étudient dans leur travail intitulé “Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation”.
Cet article fournit un résumé de ce travail, où Viktor Karlsson partage également ses réflexions sur la contribution et les résultats des auteurs.
DeViSe sur PyTorch
Cet article de blog présente le modèle d’intégration Deep Visual-Semantic (DeViSe) mis en œuvre dans PyTorch. DeViSe utilise comme cible les vecteurs de mots des labels, ce qui facilite l’apprentissage de la signification sémantique des labels. Le modèle est entraîné pour identifier les objets visuels en utilisant les données des images étiquetées et les informations sémantiques du texte non annoté. Ces modèles peuvent ensuite être utilisés pour générer des résultats intéressants pour des tâches telles que la recherche par mot-clé, la recherche inversée d’images et la recherche d’images par mot-clé.
Découverte de la structure et de la fonction des protéines grâce à la modélisation du langage
Les modèles de langage se sont révélés très efficaces pour encoder des informations séquentielles telles que des phrases en langage naturel, ce qui est utile pour construire des modèles hautement prédictifs qui permettent d’effectuer un large éventail de tâches de NLP. Au fur et à mesure de leur amélioration, les modèles Transformer ont également été adoptés dans d’autres domaines tels que la vision par ordinateur pour la détection d’objets. Il n’est pas surprenant que le mécanisme d’attention sous-jacent utilisé dans ces modèles de langage puisse être appliqué efficacement à d’autres problèmes difficiles et à fort impact, comme la découverte de la structure des protéines.
Des travaux récents d’un groupe de recherche de Salesforce montrent le potentiel de l’utilisation d’un modèle de langage Transformer pour récupérer la structure et les propriétés fonctionnelles des protéines en entraînant le modèle à prédire les acides aminés masqués dans une séquence protéique. Comme ces informations peuvent être traitées de manière séquentielle, une stratégie de préentraînement similaire à celle du modèle BERT peut être utilisée et appliquée à des séquences de protéines non marquées à grande échelle. Il est démontré que le mécanisme d’attention permet de saisir les relations de contact qui pourraient être utiles pour la prédiction des interactions entre protéines et alimenter la découverte scientifique en biologie.
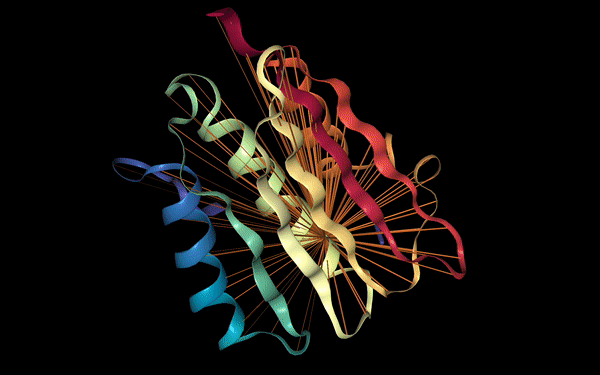
Figure source: Salesforce Einstein
Nettoyage des données textuelles à l’aide Dynamic Embedding Visualisation
Il est primordial de disposer de données d’entraînement de haute qualité pour les tâches de traduction automatique, ce qui est plus difficile dans le cas des langues à faibles ressources. Dans ce blogpost, Morgan McGuire démontre comment utiliser des techniques telles que l’intégration contextuelle multilingue, ainsi que la réduction de la dimensionnalité en utilisant UMAP pour identifier de manière interactive les groupes bruyants et les supprimer afin d’améliorer les ensembles de données. L’animation suivante présente un groupe bruyant aléatoire contenant des données en arabe et en pied de page de site web dans un ensemble de données irlandais-anglais.
Education 🎓
Ethical & Responsible NLP
Rachel Tatman aborde des sujets importants dans son discours d’ouverture What I won’t build à @WiNLPWorkshop. Les chercheurs et les praticiens doivent déterminer si les systèmes qu’ils mettent en place peuvent causer du tort, de la discrimination ou porter atteinte à la vie privée. Rachel nous invite à poser une série de questions sur les utilisateurs, l’utilisation du système et son effet sur l’inégalité systémique. Elle préconise également de sensibiliser les autres aux risques et à la manière dont l’organisation d’un effort coordonné peut donner des résultats.
Full Stack Deep Learning
Ce nouveau cours appelé Full Stack Deep Learning vise à fournir les connaissances nécessaires pour déployer des modèles d’apprentissage approfondi en production. Ce cours en ligne gratuit aborde notamment la mise en place de projets d’apprentissage machine, la gestion des données, l’entraînement et le débogage, les tests et le déploiement.
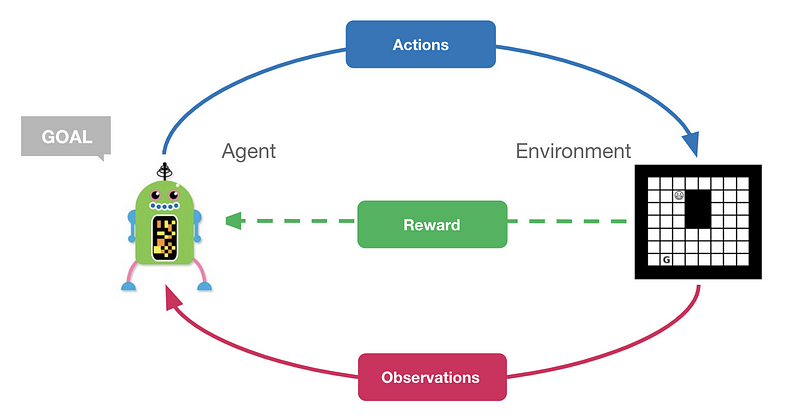
Reinforcement Learning Tutorial
Dans ce tutoriel d’apprentissage par renforcement (disponible sous forme de Google Colab), Feryal démontre d’importants concepts de RL qui comprennent des algorithmes tels que l’itération des politiques, le Q-Learning et le Q ajusté aux neurones. En outre, une courte introduction à l’apprentissage du renforcement profond est également couverte, qui comprend des explications et le code de l’algorithme du réseau Q profond (DQN).
Rester informé 🎯
Si vous cherchez d’autres aperçus et faits marquants de l’ACL de cette année, les liens suivants peuvent vous intéresser :
- Highlights of ACL 2020 (by Vered Shwartz)
- The missing pieces in virtual-ACL (by Yoav Goldberg)
- Takeaways from ACL 2020 Mentoring Session on Career Planning & becoming a research leader (by Zhijing Jin)
Quelques suggestions de challenges en cours si vous cherchez des idées pour démarrer et mettre en pratique vos connaissances en NLP et en ML :
- Dravidian-CodeMix - analyser des sentiments pour les langues dravidiennes dans le texte codé que l’on trouve dans les médias sociaux
- NLC2CMD - traduire les descriptions en anglaise des dans leur syntaxe Bash correspondante
- IEEE BigData 2020 Cup - un défi d’exploration de données pour prédire l’augmentation de l’assistance technique aux clients en utilisant des techniques de langage naturel
Mentions spéciales ⭐️
- Amit Chaudhary a publié un article qui passe en revue les défis posés par l’algorithme Word2Vec et la façon dont FastText les résout en utilisant des informations de sous-mots.
- Dans cet article, George Ho résume les tendances récentes en NLP. Il fournit un bref résumé des méthodes récentes, y compris d’autres aspects de ces modèles tels que la mise à l’échelle et les différences de représentation.
- Kostas Stathoulopoulos a créé cet outil de recherche pour explorer et découvrir des articles récents ou passés de l’ACL . Vous pouvez rechercher des publications par auteur, le domaine d’étude, l’année, le titre de l’article, etc.
- cutlet permet de convertir le japonais en romaji. Contrairement aux outils existants, il utilise le même dictionnaire qu’un tokenizer japonais commun et a la possibilité d’utiliser l’orthographe originale pour les mots de prêt étrangers.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.