

Avant-propos d’Elvis
Bonjour à tous,
Bienvenue au 14ème numéro de la Newsletter consacrée au NLP. Tout d’abord, merci de prendre le temps de lire la newsletter. Certaines choses changent dans celle-ci et c’est pour le mieux. Nous allons nous concentrer sur quelques thèmes importants de l’apprentissage machine et du NLP, centrés sur trois piliers que je crois importants pour notre communauté : éducation, recherche, et technologies. En fait, ce sont les mêmes piliers sur lesquels nous, à dair.ai, nous concentrons et construisons nos initiatives et nos projets. J’espère que vous aimez le nouveau format car il nous permet de discuter de certains sujets importants plus en profondeur que d’habitude.
Je ne peux insister davantage sur l’importance de continuer à apprendre dans un domaine aussi rapide que l’apprentissage machine. Que vous soyez à la pointe de la recherche ou que vous mettiez en production des modèles de ML à grande échelle chaque jour, il est toujours possible d’apprendre quelque chose de nouveau chaque semaine. La question est de savoir comment vous gardez votre motivation pour apprendre. J’ai identifié cela comme une opportunité pour nous de nous connecter et de partager ce qui compte pour nous. C’est pourquoi j’ai créé un nouveau groupe d’apprentissage appelé Keep Learning ML. Chaque vendredi, nous nous réunirons et nous nous amuserons en partageant ce que nous avons appris au cours de la semaine. Il peut s’agir d’un article de NLP ou de ML, d’un outil, d’une démo, d’un point de vue philosophique, d’un problème urgent, etc.
Dans ce numéro, nous abordons des sujets qui vont de l’importance d’appliquer le NLP à d’autres langues que l’anglais aux ressources pour la surveillance des systèmes de ML, en passant par une conversation sur l’avenir des systèmes d’IA conversationnelle.
Nous remercions tout particulièrement Keshaw Singh et Manikandan Sivanesan pour leur contribution significative à cette édition de la lettre d’information de la NLP.
Bonne lecture
Top Stories
Présentation des applications basée sur le GPT-3
Cette année, OpenAI a travaillé sur l’accès de ses modèles d’apprentissage machine (ML) via une API. Le processus d’accès à l’API nécessite une demande formelle et l’indication de votre objectif d’utilisation. Quelques développeurs et chercheurs ont reçu l’accès à l’API et ont présenté différentes applications du GPT-3.
Un développeur a construit un générateur de site et un autre un générateur de regex. Si vous souhaitez voir d’autres cas d’utilisation de GPT-3, Yaser Martinez Palenzuela a rassemblé une collection de démos et applications qui sont alimentées par GPT-3. Il devient évident que des modèles comme le GPT-3 ont un énorme potentiel pour être utilisés dans des applications du monde réel, cependant, il n’est pas clair si ces applications sont sûres et comment traiter les préjugés nuisibles ou les biais qui sont communs avec ce type de modèles qui sont généralement pré-entraînés sur des données Internet ouvertes à grande échelle.
En savoir plus 🎓
Si vous souhaitez en savoir plus sur le fonctionnement du GPT-3, Jay Alammar a préparé une série d’animations qui explique les étapes importantes de l’architecture du transformer avec des exemples et des transformations clés qui ont lieu dans le modèle de langage du GPT-3.
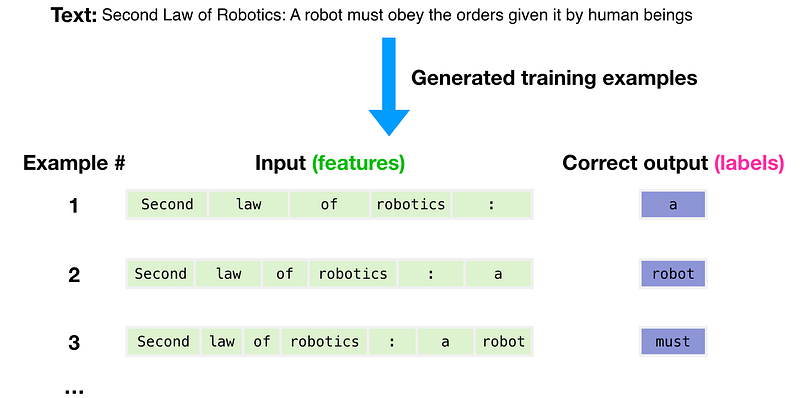 Source : Jay Alammar
Source : Jay Alammar
Rester informé 🎯
Avec tout le buzz autour des technologies émergentes, GPT-3 en étant un exempel, cet article publié par Page Street Labs propose un cadre intuitif pour donner un sens au “battage” qui les entoure. Il s’agit notamment de mieux comprendre l’utilisation du terme “hype” lui-même. Plus précisément, les utilisateurs peuvent être placés dans l’un des quatre quadrants d’une visualisation 2x2 (voir figure ci-dessous) en fonction de leur expérience directe avec certaines technologies ainsi que de la polarité du battage (positif/négatif). La plupart des signaux utiles pour évaluer les capacités et les promesses proviennent de ceux qui ont une bonne connaissance des principes sous-jacents ou qui ont une expérience de la technologie : ceux qui la créent ou qui “voient la lumière” sont parmi ceux qui génèrent le buzz positif, tandis que ceux qui se trouvent de l’autre côté mettent en garde contre les fausses alarmes. Les lecteurs sont encouragés à lire l’article original.
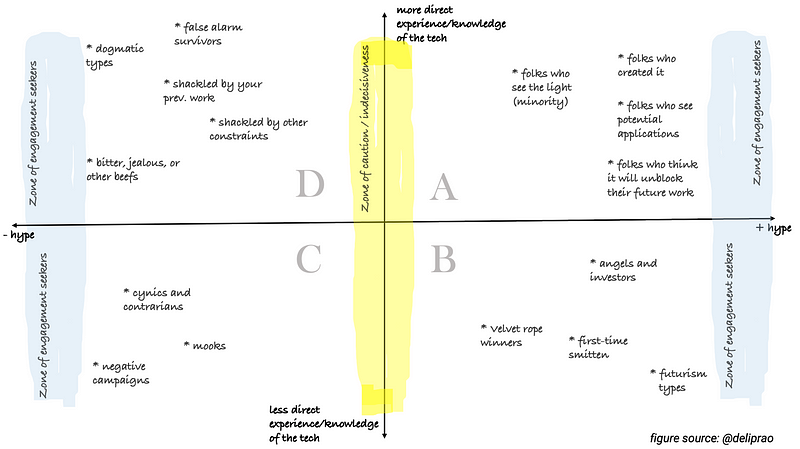 Source : Page Street Labs
Source : Page Street Labs
Jeux de données pour explorer les articles scientifiques
Plus tôt cette année, l’Institut Allen IA a publié un vaste ensemble de données d’articles scientifiques liés à la COVID-19. Alors que la plupart de ces articles contenaient des études sur la COVID-19 et d’autres coronavirus, de nombreux scientifiques et chercheurs ont commencé à l’utiliser pour effectuer des analyses intéressantes et construire des applications interactives qui permettent certaines capacités de recherche sémantique. L’idée était d’extraire de nouvelles informations des textes qui pourraient être utilisées par les chercheurs et les experts dans ce domaine pour découvrir des faits intéressants sur le virus, ce qui, dans un certain sens, accélérerait le rythme des découvertes.
Dans la foulée, arXiv.org a publié un jeu de données contenant 1,7 million d’articles dans le but de fournir des articles scientifiques - dans différents domaines tels que la biologie et l’informatique - dans un format plus accessible et lisible par les machines. L’appel à l’action vise à donner aux chercheurs et aux praticiens de l’apprentissage machine les moyens de créer des outils pour accélérer les nouvelles découvertes à l’aide d’applications basées sur le ML, telles que l’analyse des tendances, les moteurs de recommandation de papier, la construction de graphiques de connaissances et même les interfaces de recherche sémantique.
Suite à la publication de ce jeu de données, Elsevier a également récemment publié un corpus de 40 000 textes CC-BY contenant des articles scientifiques qui pourraient être utilisés pour la recherche en NLP et en ML.
Appel à l’action 💡
Chez dair.ai, nous avons lancé un projet dont l’objectif est d’utiliser l’ensemble de données arXiv pour explorer de nouvelles façons d’extraire des informations d’articles scientifiques afin d’alimenter de nouvelles découvertes. En plus de cet effort de recherche, nous mettons sur pied une équipe chargée de créer des applications basées sur le NLP avec des capacités de recherche sémantique afin de fournir à la communauté une solution open-source pour trouver facilement des tendances et d’autres idées intéressantes pour se tenir informé des différents domaines de recherche tels que l’apprentissage machine. Consultez cette annonce pour plus de détails et rejoignez notre groupe Slack pour plus d’informations.
Pourquoi est-il important de surveiller les modèles d’apprentissage automatique ?
Imaginez un scénario dans lequel nous avons construit et déployé un système d’apprentissage machine (ML) pour nos utilisateurs. La question est maintenant de savoir comment nous pouvons garantir que le système fonctionne constamment comme prévu sur une période donnée. Selon les exigences de tolérance du système, l’impact d’une défaillance va d’un inconvénient mineur à des situations mettant la vie en danger. Les pratiques traditionnelles de gestion des performances des applications, telles que la surveillance des mesures de l’expérience utilisateur (par exemple, la latence) et des ressources du système (par exemple, l’utilisation du processeur et de la mémoire), sont également applicables à la surveillance des systèmes de ML. Elles sont essentielles pour identifier les modes de défaillance connus et mettre en place une infrastructure d’alerte pour effectuer des actions correctives. En outre, pour les systèmes de ML, nous devons également surveiller les facteurs suivants :
- les changements dans la qualité des données d’entrée tels que les colonnes manquantes ou les entrées inattendues pendant le temps d’inférence
- les changements dans la relation entre l’entrée et la sortie sur une période de temps. Cela entraîne une dégradation progressive du modèle due à la modification des hypothèses sous-jacentes, communément appelée “dérive conceptuelle”.
- la robustesse des prédictions due à toute modification des données, des caractéristiques, des hyperparamètres, des paramètres du modèle, etc… C’est ce qu’on appelle le principe CACE : * Changing Anything Changes Everything (Changer quelque chose change tout)*. Si vous souhaitez en savoir plus sur l’importance de la surveillance des systèmes de blanchiment d’argent et découvrir quelques exemples concrets, consultez l’article complet.
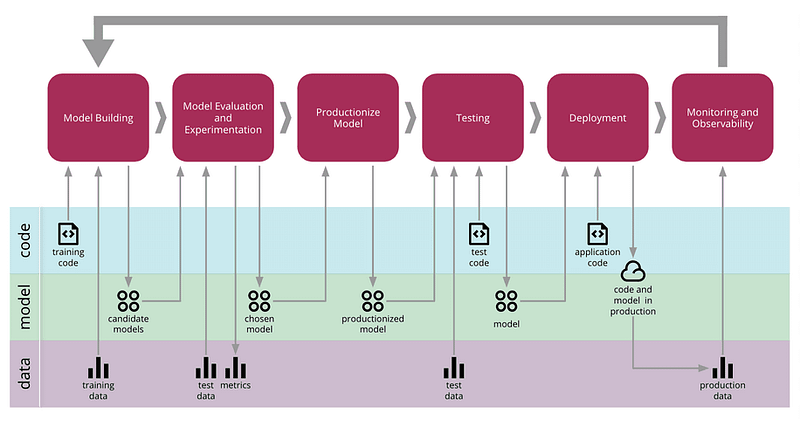 Surveillance dans le cycle de vie du ML - Source de la figure
Surveillance dans le cycle de vie du ML - Source de la figure
En savoir plus 🎓
Si vous souhaitez continuer à vous informer sur la surveillance des systèmes d’apprentissage machine et sur les MLOps en général, nous partageons quelques références ci-dessous :
- Applied ML est un répertoire avec une liste d’articles et de blogs sur la science des données et l’apprentissage machine en production
- Cet article est un guide complet sur la complexité et l’importance de la surveillance, et fournit des conseils pratiques sur la surveillance des systèmes de blanchiment d’argent.
- L’intégration continue est une pratique de développement de logiciels qui consiste à tester automatiquement chaque modification apportée à la base de code. Cela permet de détecter le changement granulaire qui entraîne l’échec des tests et permet à l’équipe de résoudre le problème d’intégration au début du cycle de développement. Dans cette vidéo, découvrez comment cette pratique peut être appliquée aux projets d’apprentissage machine avec des outils tels que Continuous Machine Learning (CML).
Big Bird pour des séquences plus longues
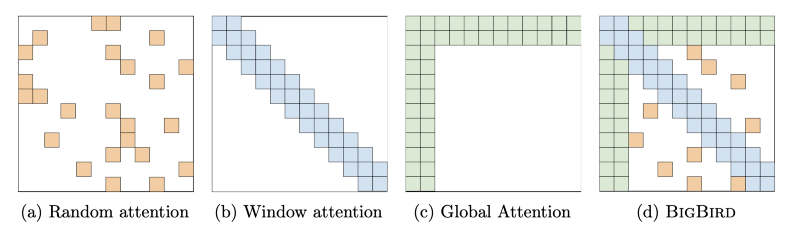 La figure montre comment Big Bird est capable de maintenir les propriétés de trois mécanismes d’attention différents - Zaheer et al. (2020).
La figure montre comment Big Bird est capable de maintenir les propriétés de trois mécanismes d’attention différents - Zaheer et al. (2020).
Il est bien connu que les modèles de langage basés sur des transformers reposent sur le mécanisme d’auto-attention ont une complexité quadratique dans le nombre de tokens. Big Bird est un modèle basé sur Transformer qui vise à soutenir plus efficacement les tâches de NLP nécessitant des contextes plus longs en réduisant la complexité du mécanisme d’attention à une complexité linéaire dans le nombre de tokens.
Pourquoi est-ce important ? Le traitement et l’extraction d’informations à partir de séquences plus longues sont utiles lorsqu’il s’agit de textes longs tels que des livres ou des articles scientifiques. Dans de tels cas, nous voudrions minimiser l’empreinte mémoire, c’est pourquoi il est important de réduire la complexité de la composante du mécanisme d’attention dans l’architecture de modélisation du langage. La réduction de la complexité est importante, tout comme le fait de conserver les propriétés originales du modèle. La façon dont Big Bird y parvient est de considérer l’auto-attention comme un graphe entièrement connecté et de tirer parti des propriétés du graphe, en augmentant notamment la vitesse de circulation des informations entre les paires de nœuds. Les auteurs affirment qu’avec la nouvelle attention réduite proposée, leur modèle peut gérer des séquences “d’une longueur pouvant atteindre 8 fois ce qui était possible auparavant avec un matériel similaire “.
En savoir plus 🎓
Si vous voulez avoir plus d’informations sur les choix de conception de Big Bird, Yannic Kilcher fournit une explication de ce modèle dans cette vidéo.
Pénétrer dans l’apprentissage profond et le NLP
L’un des plus grands changements auxquels beaucoup d’entre nous ont dû s’habituer cette année en raison de la pandémie est l’idée d’apprendre à distance. Cela a également ouvert de nombreuses possibilités d’apprentissage non seulement pour les communautés locales mais aussi pour les étudiants du monde entier. Dans cette partie de la newsletter, nous partageons quelques ressources pour ceux qui cherchent à se lancer dans l’apprentissage approfondi ou le NLP.
Groupe d’étude « Dive into Deep Learning »
Le week-end dernier, dair.ai a accueilli la première session du nouveau groupe d’étude sur l’apprentissage approfondi. La session a duré plus d’une heure et s’est concentrée sur un large aperçu de l’apprentissage approfondi. Plus de 150 personnes venant du monde entier ont participé à la session en direct (voir l’enregistrement ici). La deuxième session visera à couvrir quelques préliminaires tels que la probabilité et les statistiques, l’algèbre linéaire, et d’autres concepts importants pour l’étude et l’application des concepts de l’apprentissage approfondi. Si vous souhaitez vous joindre aux prochaines sessions, découvrez ce groupe d’étude ici.
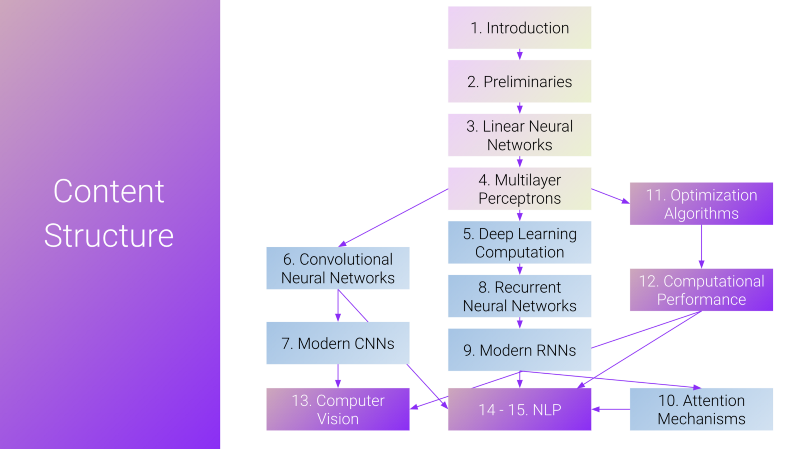 La structure du contenu du programme d’étude de l’apprentissage profond
La structure du contenu du programme d’étude de l’apprentissage profond
S’initier au NLP grâce à deeplearning.ai
Récemment, deeplearning.ai a publié une nouvelle spécialisation axée sur le NLP. Lors d’une récente table ronde, Andrew Ng a été rejoint par des experts du domaine et a discuté de sujets intéressants autour de “l’entrée dans le NLP”. La discussion a mis l’accent sur les tendances duNLP et sur d’autres conseils pour les étudiants. Elvis a écrit un fil de discussion sur les points qu’il a retenus de cette session, qui vont des conseils aux étudiants aux domaines de recherche intéressants et aux tendances du NLP.
LxMLS Lisbon Machine Learning School
Le LxMLS 2020 à l’Instituto Superior Técnico(IST) a eu lieu à distance et toutes les conférences ont été données et diffusées publiquement en ligne. Ce programme est considéré comme l’un des meilleurs programmes d’apprentissage de la NLP en Europe. Plusieurs chercheurs renommés ont soit participé au programme dans le passé, soit enseigné dans le cadre du programme. La 10e édition du LxMLS comprenait des conférences par exemple sur la modélisation de données séquentielles ou encore l’application de l’apprentissage par renforcement dans le contexte du NLP. Vous pouvez trouver toutes les conférences sur YouTube.
Apprentissage profond pour la vision par ordinateur
Justin Johnson a récemment annoncé qu’ils ont publié toutes les conférences vidéo pour leur nouveau cours sur l’apprentissage approfondi de la vision par ordinateur. Selon Justin, il s’agit d’une évolution du cours CS231n qui a été dispensé à Stanford par lui et d’autres. Tout le contenu a été actualisé et les conférences incluent maintenant de nouveaux sujets comme la vision 3D et les transformers appliqués dans le contexte de la vision par ordinateur.
Rester informé 🎯
NLP with Friends est un effort pour rassembler les étudiants afin de discuter de sujets de recherche intéressants liés au NLP. Des discussions sont organisées chaque semaine sur Zoom afin que vous puissiez vous joindre aux sessions à distance.
En savoir plus 🎓
Voici quelques concours et ateliers liés au NLP que nous avons trouvés utiles pour vous faire participer:
- Contradictoire, mon cher Watson : Détecter la contradiction et l’implication dans un texte multilingue en utilisant les TPU.. Il s’agit d’un concours de type “terrain de jeu” basé sur l’inférence en langage naturel (NLI) pour déterminer si des paires de phrases sont liées. Les participants doivent créer un modèle de NLI à partir d’un ensemble de données comprenant des textes de 15 langues différentes.
- Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) fournit un forum et un défi pour promouvoir la recherche multilingue sur la détection des contenus problématiques. Cette année, l’ensemble de données contient 10 000 tweets annotés en anglais, allemand et hindi. La première sous-tâche consiste à détecter les contenus haineux, offensants ou profanes dans le texte. La deuxième sous-tâche est plus granulaire pour discriminer et classer les tweets. Il existe une sous-piste distincte pour le CodeMix de Dravidian (nous en avons parlé dans notre précédente newsletter). La date limite d’inscription est fixée au 30 août 2020.
Pourquoi vous devriez faire du NLP sur des langues autres que l’anglais
Dans ce récent article, Sebastian Ruder explique pourquoi les chercheurs en NLP devraient se concentrer sur d’autres langues que l’anglais. Pour commencer, le blog souligne l’énorme disparité dans la disponibilité des données en ligne entre une poignée de langues à haute ressource (dont l’anglais, le français, l’espagnol, …) et des milliers d’autres langues. La discussion principale est centrée sur les facteurs qui devraient encourager davantage d’initiatives de recherche dans d’autres langues, du point de vue sociétal, linguistique, de l’apprentissage machine, culturel et normatif, et cognitif.
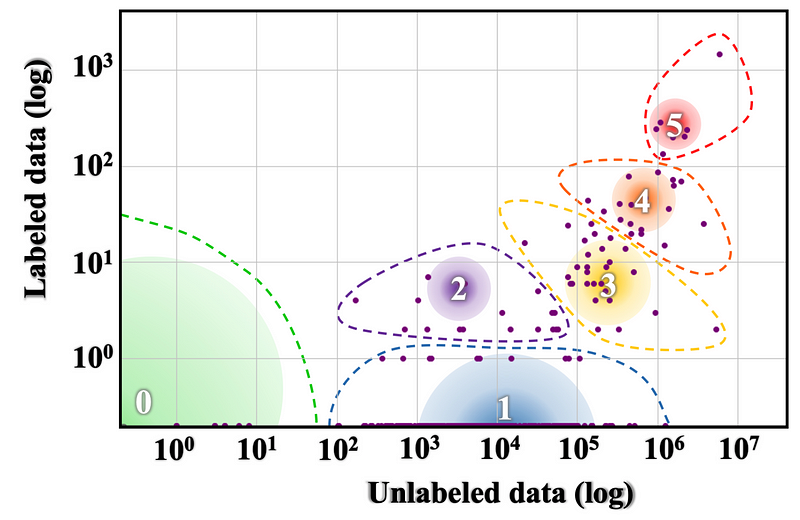 Distribution des ressources linguistiques de Joshi et al. (2020). Les groupes 5 et 4 sont des langues qui sont bien étudiées alors que les autres groupes sont largement négligés.
Distribution des ressources linguistiques de Joshi et al. (2020). Les groupes 5 et 4 sont des langues qui sont bien étudiées alors que les autres groupes sont largement négligés.
L’un des points abordés est la manière dont les modèles spécifiques à l’anglais peuvent limiter l’accès à la connaissance en raison des barrières linguistiques, provoquer des préjugés et des discriminations à l’encontre des non-anglophones, ainsi que mettre en danger une langue elle-même dans des cas extrêmes. D’un point de vue linguistique, de nombreuses langues riches en ressources sont morphologiquement pauvres, ce qui signifie que nous passons à côté de la capacité de généralisation en ignorant les autres langues qui peuvent aider les modèles à apprendre ces informations. Considérer les choses d’un point de vue ML, étant donné que la plupart des langues ont des données limitées disponibles, jeter beaucoup de données et espérer le meilleur résultat ne peut être la solution. Les approches qui tiennent compte des langues et qui peuvent fonctionner avec peu de données ont plus de chances d’avoir un réel impact. Le blog se termine par un appel à l’action pour de futures recherches, notamment la création d’ensembles de données dans plusieurs langues, l’évaluation d’une approche dans plusieurs langues et le respect de la règle de Bender.
CoVoST V2 : Développer l’ensemble de données de traduction de la parole au texte multilingue le plus vaste et le plus diversifié
Les ensembles de données multilingues permettent de mieux tester la robustesse des modèles d’apprentissage automatique qui visent à traiter soit la modélisation du langage, soit la reconnaissance vocale. Un domaine de l’apprentissage automatique qui pourrait bénéficier de ce type de données est celui des applications de traduction vocale multilingue. Ces types de modèles peuvent contribuer à lever les obstacles qui sont très courants avec les outils de communication en ligne, où les utilisateurs proviennent de cultures différentes. Ils peuvent également contribuer à enrichir les conversations des personnes qui ne maîtrisent pas certaines langues et à amplifier leur voix en ligne. Il existe toute une série d’autres façons d’utiliser l’ensemble de données et les applications qui en dépendent, comme la création de compositeurs intelligents ou d’outils de recherche plus accessibles.
Facebook AI [publié] (https://ai.facebook.com/blog/covost-v2-expanding-the-largest-most-diverse-multilingual-speech-to-text-translation-data-set/) CoVoST V2, qu’ils considèrent comme le plus grand ensemble de données multilingues parole-texte disponible à ce jour. La nouvelle version de l’ensemble de données ajoute de nouvelles langues à la première version précédente, avec un total de 2900 heures de parole. Avant de la publier, les chercheurs ont vérifié la qualité des données et ont constaté qu’elle variait selon des critères tels que l’âge, le sexe et les accents. Avec ce nouvel ensemble de données, on espère qu’il favorisera la recherche en matière de traduction vocale multilingue et qu’il permettra à un seul modèle de prendre en charge de nombreuses paires de langues, en particulier pour les paires comportant moins de données.
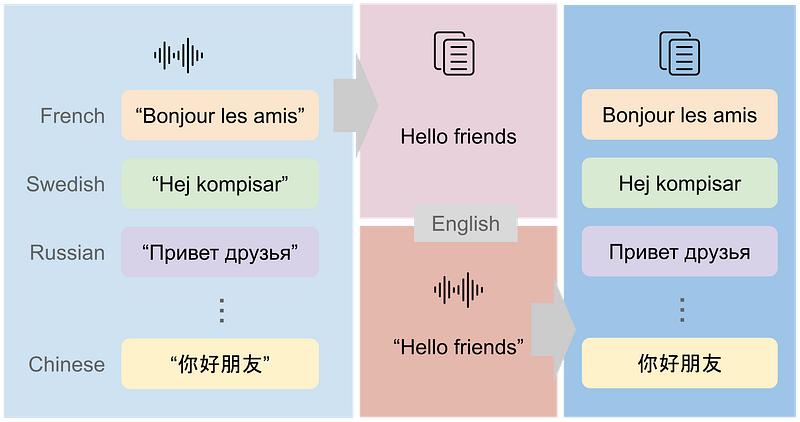 Source : Blog Facebook AI
Source : Blog Facebook AI
L’avenir des systèmes d’IA conversationnelle
Lors d’une récente table ronde sur ce que les développeurs d’IA conversationnelle devraient savoir sur le ML et la linguistique, Vladimir Vlasov, Emily Bender, Thomas Wolf et Anna Rogers ont partagé leurs points de vue et leurs préoccupations. Le consensus général est que les modèles linguistiques actuels sont capables d’obtenir des résultats remarquables dans certaines tâches, mais les experts pensent que nous ne testons pas les modèles pour les bonnes choses. Ce n’est pas parce qu’un modèle linguistique pré-entraîné peut déjà être utilisé pour construire des applications créatives que cela signifie que nous avons résolu le problème de la modélisation linguistique.
D’autres sujets de discussion intéressants ont porté sur les moyens d’améliorer l’évaluation des modèles linguistiques et de mieux comprendre ce que les modèles apprennent réellement. À l’heure actuelle, il est vraiment difficile de dire quels aspects de la langue ces modèles captent réellement. Cela devient d’autant plus difficile qu’un nombre croissant de ces modèles pré-entraînés, reposant sur des architectures différentes et construits sur des objectifs différents, continuent à émerger rapidement. Nous devons donc nous concentrer davantage sur la normalisation des méthodes d’évaluation et nous pencher sur la question de savoir ce que ces modèles capturent réellement et comment éviter leur utilisation néfaste d’un point de vue pratique, par exemple lors de la construction de systèmes d’IA conversationnels.
N’hésitez pas à consulter ce fil de discussion sur Twitter ou à vous rendre directement à la table ronde.
Mentions spéciales ⭐️
Comprendre et mettre en œuvre SimCLR en PyTorch - Un guide ELI5
Auparavant, nous avons abordé le cadre SimCLR utilisé pour entraîner des représentations visuelles riches et pour améliorer les performances par rapport aux méthodes d’apprentissage auto-supervisé et semi-supervisé sur ImageNet. SimCLR est basé sur un apprentissage contrastif qui tente d’entraîner un modèle à distinguer les choses similaires et dissemblables*. Marcin a récemment écrit un article détaillé fournissant une description et une explication du code de ce cadre en utilisant PyTorch.
L’hypothèse du billet de loterie
Est-il possible de trouver des sous-réseaux dont les performances sont similaires à celles du réseau neuronal d’origine pour des tâches spécifiques ? En utilisant des techniques d’élagage, la recherche actuelle soutient que c’est effectivement possible, affirmant que la façon dont les modèles sont initialisés a beaucoup à voir avec l’obtention de cet effet. Pour en savoir plus sur ce domaine de recherche, consultez ce bref résumé.
NodeNet : Un réseau neuronal régularisé par graphique pour la classification des nœuds
Les algorithmes d’apprentissage basés sur des graphes utilisent efficacement les données et les informations connexes pour construire des modèles supérieurs. L’apprentissage neural par graphes (NGL) est une de ces techniques qui utilise un algorithme d’apprentissage machine traditionnel avec une fonction de perte modifiée pour exploiter les bords de la structure du graphe. Ce travail propose un modèle utilisant NGL - NodeNet, pour résoudre la tâche de classification des nœuds pour les graphes de citation. Les auteurs affirment que NodeNet permet d’obtenir des résultats de pointe sur des articles avec du code pour les ensembles de données Pubmed et Citeseer.
Quand est-ce qu’un embedding contextuel vaut la peine d’être utilisé ?
Dans ce billet de blog, Viktor Karlsson résume un article qui traite de situations où il pourrait être judicieux d’utiliser des embeddings contextuels (par exemple, BERT) et où cela ne vaut pas la peine.
Apprentissage simple et efficace du traitement du langage naturel, avec Moshe Wasserblat, Intel AI
Dans cette conférence, Moshe Wasserblat, Intel AI, présente des méthodes simples et efficaces d’apprentissage profond en NLP. L’orateur donne des informations sur les vecteurs d’optimisation les plus populaires et des conseils sur la distillation de BERT pour une inférence beaucoup plus rapide avec une pénalité de précision durable. Les résultats de l’ensemble de données dair.ai emotion dataset et d’autres points de référence populaires ont également été abordés.
DeText : Un cadre NLP pour une compréhension intelligente des textes
DeText est un cadre permettant de tirer parti des technologies comme BERT pour la compréhension des textes. DeText offre des fonctionnalités qui rendent possible l’utilisation de grands modèles qui nécessitent des coûts de calcul élevés dès le départ. Grâce à ce cadre, il est possible de mettre en œuvre un classement neuronal pour les systèmes de recherche et de recommandation.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newsletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.