

Avant-propos d’Elvis
Bonjour et bonne année ! Suite à de nombreuses demandes, j’ai décidé de recommencer la Newsletter consacrée au NLP. Cette fois-ci, je vais la garder courte et ciblée (également maintenue dans ce reportoire). L’objectif de ce bulletin est de vous tenir informé de certaines des avancées intéressantes et récentes liées au NLP et au ML sans prendre trop de temps sur votre journée chargée.
Publications 📙
Système d’IA pour la détection de cancers du sein
DeepMind a publié un article dans Nature intitulé “International evaluation of an AI system for breast cancer screening”. Le travail porte sur l’évaluation d’un système d’IA qui surpasse les experts humains en matière de dépistage du cancer du sein. Ces systèmes font toujours l’objet d’un débat notamment la manière dont ils sont évalués. Vous trouverez ici un bref résumé de l’article.
Extraction d’informations
Pankaj Gupta a rendu publique sa thèse de doctorat intitulée “Extraction d’informations neurales à partir d’un texte en langage naturel”. Le sujet principal porte sur la manière d’extraire efficacement les relations sémantiques d’un texte en langage naturel en utilisant des approches basées sur les neurones. Cette recherche vise à contribuer à la construction de bases de connaissances structurées, qui peuvent être utilisées dans une série d’applications de NLP, telles que la recherche sur le web, les questions-réponses, entre autres tâches.
Améliorer les recommandations
Des chercheurs du MIT et d’IBM ont mis au point une méthode (publiée l’année dernière au NeurIPS) de catégorisation, d’affichage et de recherche de documents pertinents, basée sur une combinaison de trois outils d’analyse de texte très utilisés : la modélisation de sujets, le word embedding et le transport optimal. La méthode donne également des résultats prometteurs pour le tri des documents. Ces méthodes sont applicables à une grande variété de scénarios nécessitant des suggestions telles que les systèmes de recherche et de recommandation.
Créativité et société 🎨
Carrières
Le rapport 2019 de l’AI Index suggère qu’il y a plus de demandes que d’offres de diplômés en AI. Toutefois, certains aspects des emplois liés à l’IA, tels que les transitions de carrière et les entretiens, ne sont pas encore bien définis.
Dans ce post, Vladimir Iglovivok décrit en détail sa carrière et son aventure dans le domaine de l’IA. Allant de la construction de systèmes de recommandation traditionnels à la construction de modèles de vision par ordinateur qui ont remporté des concours sur Kaggle. Il travaille maintenant sur des véhicules autonomes à Lyft, mais le chemin pour y parvenir n’a pas été si facile.
Si vous êtes intéressé par une carrière dans l’IA, la société d’Andrew Ng, deeplearning.ai, a fondé Workera, qui vise à aider les scientifiques spécialisés dans les données et les ingénieurs en apprentissage machine dans leur carrière en IA. Obtenez leur rapport officiel ici.
Outils et jeux de données ⚙️
Un tokenizer utra rapide
Hugging Face, la start-up de NLP derrière la librairie Transformers, dispose de tokenizers open-source, une implémentation ultra-rapide de tokenisation qui peut être utilisée dans les pipelines. Consultez la documentation sur l’utilisation des tokenizers sur le site de GitHub.
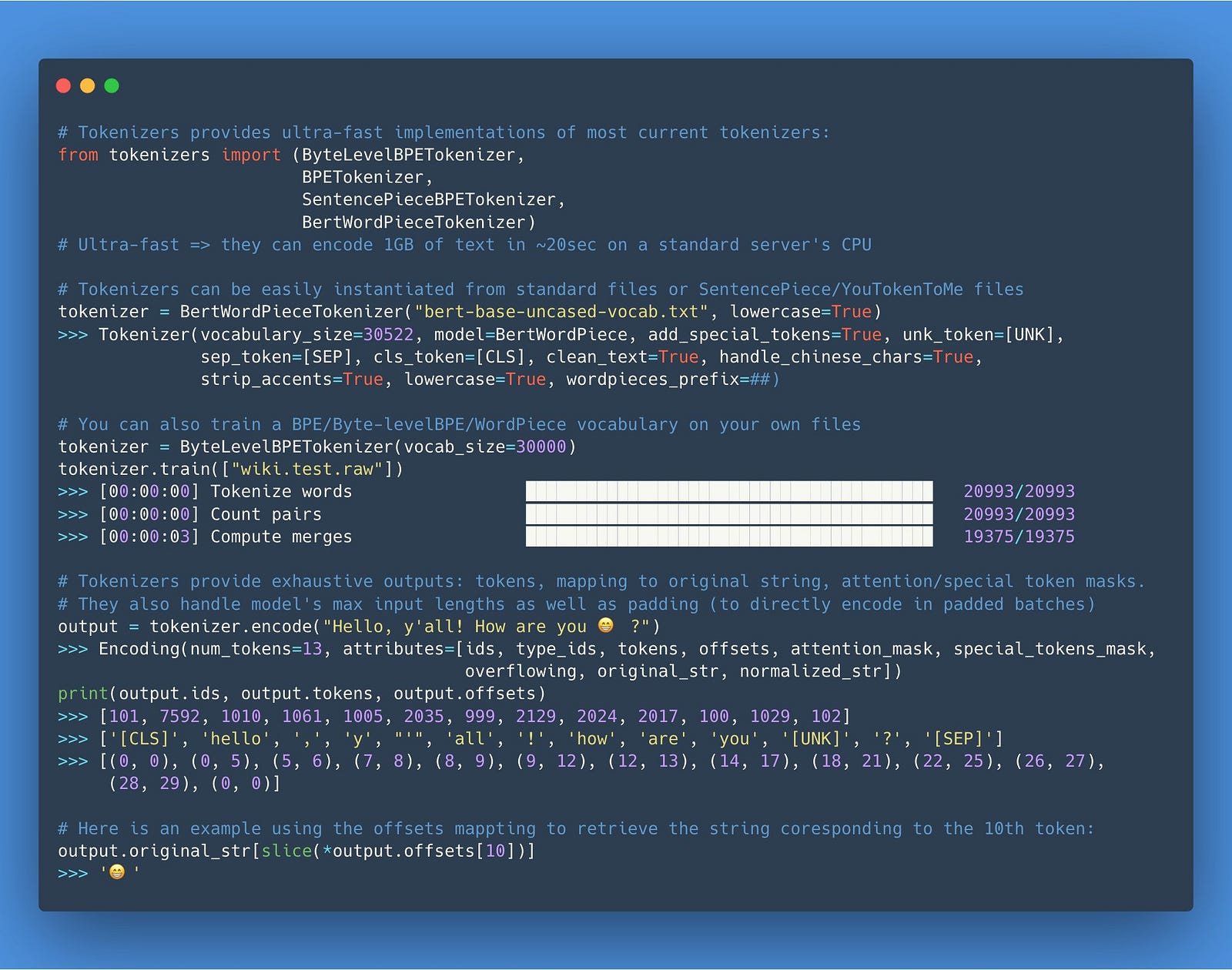
TensorFlow 2.1 intègre une nouvelle couche
TextVectorization qui vous permet de traiter facilement les chaînes de caractères brutes et d’effectuer efficacement la normalisation du texte, la tokenisation, la génération de n-grammes et l’indexation du vocabulaire. Vous pouvez aussi consulter le Google Colab de François Chollet qui montre comment utiliser cette fonctionnalité pour la classification de texte.
Le NLP et le ML pour la recherche
L’un des domaines qui a fait d’énormes progrès l’année dernière est le NLP. La recherche est l’un des domaines qui pourrait potentiellement bénéficier de l’apprentissage par transfert.
Il existe une opportunité de construire des moteurs de recherche qui améliorent la recherche sémantique en utilisant des techniques modernes de NLP telles que les représentations contextualisées d’un modèle basé sur les Transformers comme BERT. Google a publié il y a quelques mois un article sur leur blog sur la façon dont ils utilisent les modèles BERT pour améliorer et comprendre les recherches.
Si vous êtes curieux de savoir comment les représentations contextualisées peuvent être appliquées à la recherche à l’aide de technologies ouvertes telles que Elasticsearch et TensorFlow, vous pouvez consulter ce billet ou celui-ci.
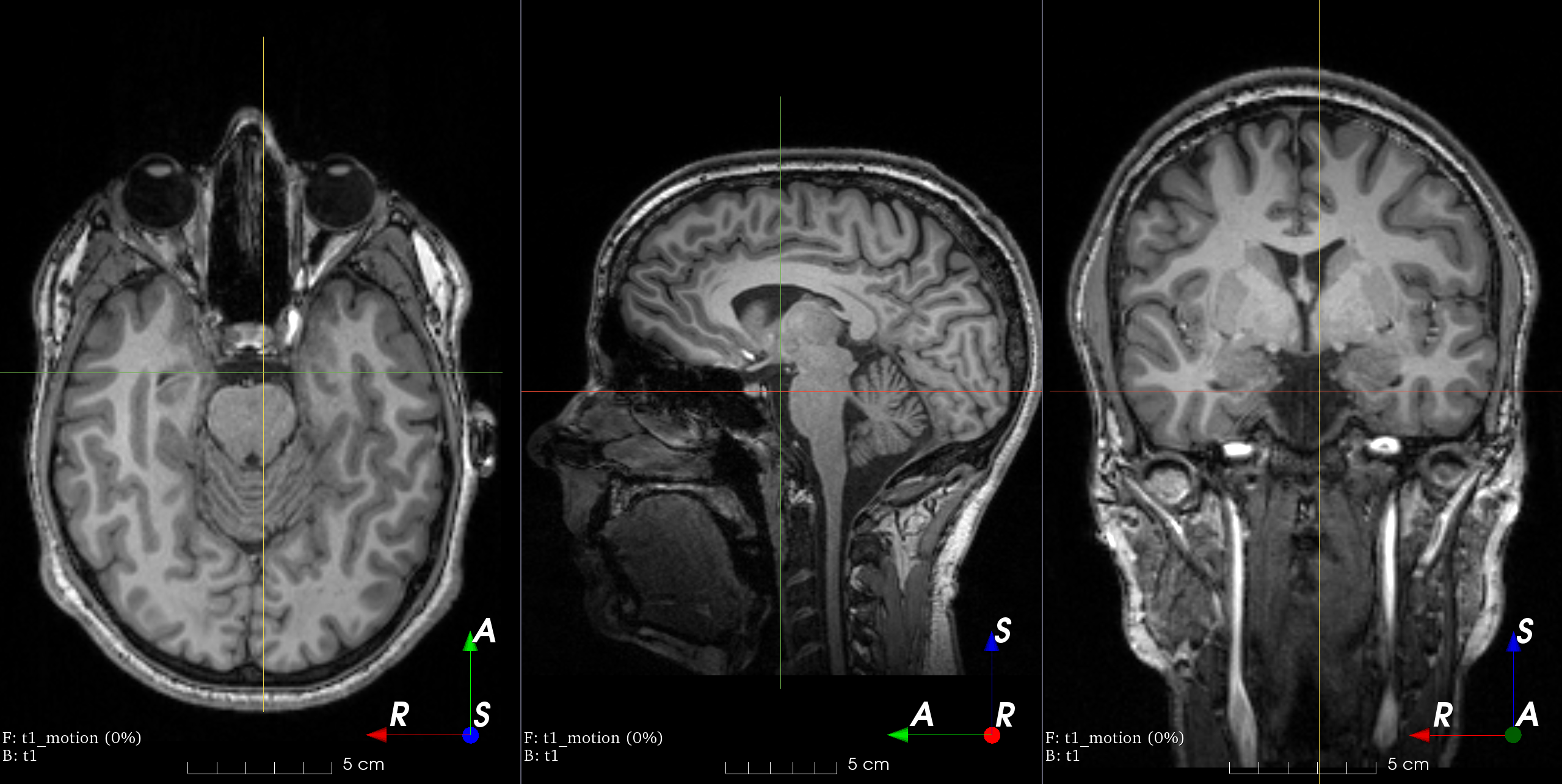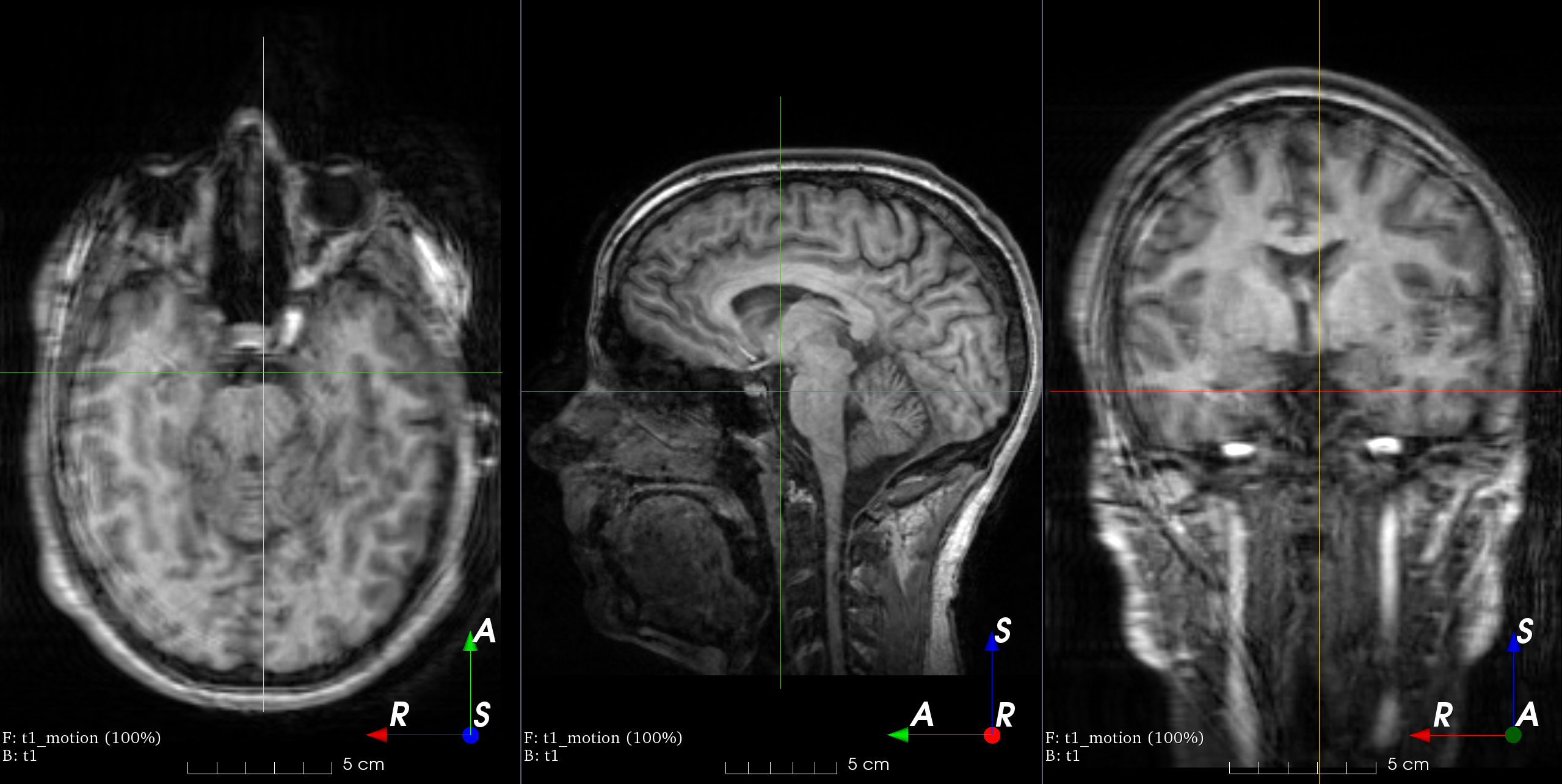
Analyse d’images médicales
TorchIO est un package Python basé PyTorch. TorchIO offre des fonctionnalités permettant de lire et d’échantillonner facilement et efficacement des images médicales en 3D. Les fonctionnalités comprennent des transformations spatiales pour l’augmentation et le prétraitement des données.
Ethique en IA 🚨
Comportement frauduleux dans la communauté du ML
Les gagnants de la première place d’un concours Kaggle ont été disqualifiés pour activité frauduleuse. L’équipe a utilisé des tactiques intelligentes mais irresponsables et inacceptables pour remporter la première place du concours. L’histoire complète est disponible ici. Cette histoire met en évidence un des nombreux comportements graves et inacceptables que la communauté de l’apprentissage machine veut atténuer. L’utilisation correcte et éthique des technologies de ML est la seule façon de progresser.
Biais concernant le genre dans la traduction automatique
Sur la question de savoir si les systèmes de traduction automatique reflètent des préjugés sexistes, un groupe de chercheurs a publié cet article présentant une étude de cas utilisant Google Translate. L’un des résultats revendiqués par les auteurs est que Google Translate “présente une forte tendance aux défauts masculins, en particulier pour les domaines liés à une répartition déséquilibrée des sexes, comme les emplois dans les STEM (Science, Technology, Engineering and Mathematics)”.
Biais en ML et équité
Si vous voulez vous familiariser avec l’éthique et l’équité en matière d’IA, vous pouvez écouter ce podcast avec Timnit Gebru et animé par TWIML.
Timnit est un chercheur dans le domaine de l’équité en ML qui, avec Eun Seo Jo, a publié un article dans lequel ils identifient cinq approches clés dans les pratiques de collecte de données pouvant ainsi fournir des méthodes plus fiables dans le domaine du ML socioculturel. Cela pourrait potentiellement conduire à des méthodes de collecte de données plus systématiques, issues de la recherche collaborative interdisciplinaire.
Sina Fazelpour et Zachary Lipton ont récemment publié un article dans lequel ils affirment qu’en raison de la nature non idéale de notre monde, il est possible qu’un ML équitable basé sur la pensée idéale puisse potentiellement conduire à des politiques et des interventions mal orientées. En fait, leur analyse démontre “que les lacunes des algorithmes à vocation équitable proposés reflètent les problèmes plus larges rencontrés par l’approche idéale”.
Articles et Blog ✍️
Lacunes en NLP
Benjamin Heinzerling a publié un article dans The Gradient où il aborde les domaines dans lesquels le NLP est défaillant, comme la compréhension des arguments et le raisonnement. Benjamin fait référence à un article récent de Nivin & Kao qui remet en question les capacités de l’apprentissage par transfert et les modèles linguistiques pour une compréhension poussée du langage naturel.
Temps forts du NLP et du ML en 2019
Pour la nouvelle année, Elvis (créateur de cette newsletter et du site dair.ai) a publié un document sur certains des points intéressants du NLP et du ML qu’il a rencontré en 2019.
Sebastian Ruder a également écrit récemment un article détaillé sur les dix principales orientations de recherche en ML et en NLP qu’il a trouvées percutantes en 2019. Parmi la liste figurent des sujets tels que l’entraînement universel non supervisée, l’augmentation des modèles pré-entrainés, les Transformers, entre autres.

“VideoBERT ([Sun et al., 2019*](https://arxiv.org/abs/1904.01766 une récente variante multimodale de BERT qui génère des “tokens” vidéo en fonction d’une recette (ci-dessus) et prédit les futurs tokens à différentes échelles de temps en fonction d’un tokens vidéo (ci-dessous).” — source
Google AI Research publie un résumé des recherches qu’ils ont menées au cours de l’année et les futures orientations de recherche auxquelles ils prêtent attention.
Education 🎓
Démocratisation des cours d’IA
Dans un effort pour démocratiser l’enseignement de l’IA et pour éduquer les masses sur les implications de la technologie de l’IA, l’Université d’Helsinki s’est associée à Reaktor pour publier un cours gratuit couvrant les bases de l’IA. Ce cours s’intitule “Elements de l’IA” et aborde des sujets tels que l’éthique de l’IA, la philosophie de l’IA, les réseaux de neurones, la règle de Bayes naïve, entre autres sujets fondamentaux.
*Cours de Stanford CS224N
Stanford CS224N est de retour avec une nouvelle session de leurs cours “Natural Language Processing with Deep Learning”. Le cours a officiellement débuté le 7 janvier de cette année. Si vous souhaitez le suivre, rendez-vous sur leur site web pour obtenir le programme complet, des diapositives, des vidéos, des suggestions de lecture de documents, etc.
Machine Learning avec les méthodes à noyaux
Les méthodes à noyaux telles que l’ACP et les K-means existent depuis un certain temps et ont été appliquées avec succès pour une grande variété d’applications telles que les graphes ou les séquences biologiques. Sur le sujet, pouvez consulter cette série de diapositives de Partis Tech couvrant un large éventail de méthodes du noyau et leur fonctionnement interne. Vous pouvez aussi jeter un œil au blog de Francis Bach qui traite de certains aspects des méthodes du noyau et d’autres sujets liés à l’apprentissage machine.
Mentions spéciales ⭐️
Le blog tenu par John Langford qui aborde les aspects théoriques de l’apprentissage machine.
Si vous souhaitez apprendre à concevoir et à construire des applications de ML et les amener jusqu’à la production, vous pouvez lire le livre d’Emmanuel Ameisen.
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.