

Avant-propos d’Elvis
Bienvenue à cette nouvelle newsletter consacrée au NLP ! Ce deuxième numéro aborde des sujets qui vont de l’interprétabilité des modèles au repliement des protéines en passant par l’apprentissage par transfert actif.
Publications 📙
Sur l’incertitude de la confiance dans un modèle
Un article récent de Google AI, publié au NeurIPS, examine si les probabilités sorties par un modèle reflètent sa capacité à prévoir les données décalées et hors distribution. Ils ont constaté que les ensembles profonds ont de meilleures performances (c’est-à-dire une meilleure incertitude du modèle) sur le décalage de l’ensemble de données, tandis que d’autres modèles ne sont pas devenus de plus en plus incertains sur le décalage de l’ensemble de données, mais se sont plutôt trompés avec confiance. (Lire l’article ici et le résumé ici).

image corruption — source
Généralisation systématique
Un travail intéressant publié dans ICLR présente une comparaison entre les modèles modulaires et les modèles génériques concernant leur efficacité pour la généralisation systématique dans la compréhension des langues. Sur la base d’une évaluation effectuée des questions/réponses en lien avec une tâche visuelle, les auteurs concluent qu’il peut être nécessaire d’utiliser des régularisateurs et des antécédents explicites pour parvenir à une généralisation systématique.
Le Reformer
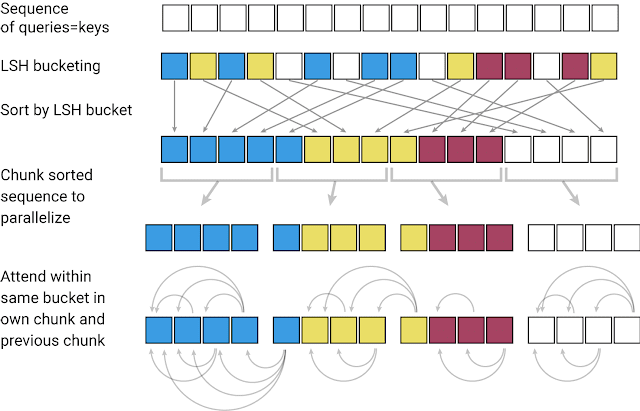
Un Transformer est limité au niveau de la fenêtre de contexte qu’il peut couvrir en raison des calculs coûteux effectués dans la couche d’attention. Ainsi, il est possible d’appliquer le Transformer qu’à des tailles de texte limitées ou de générer que de courtes phrases / morceaux de musique. GoogleAI a récemment publié une variante efficace du modèle Transformer, appelée Reformer. L’objectif principal de cette méthode est de pouvoir traiter des séquences de contexte beaucoup plus grandes tout en réduisant les besoins de calcul et en améliorant l’efficacité de la mémoire. Reformer utilise le “locality-sensitive-hashing” (LSH) pour regrouper des vecteurs similaires et créer des segments à partir de ceux-ci. Cela permet ainsi un traitement en parallèle. L’attention est ensuite portée sur ces segments plus petits et sur les parties voisines correspondantes, réduisant la charge de calcul. L’efficacité de la mémoire est obtenue grâce à des couches réversibles qui permettent de recalculer à la demande les informations d’entrée de chaque couche tout en s’entraînant par rétropropagation. C’est une technique simple qui évite au modèle de devoir stocker en mémoire les activations. Une description de ce modèle est disponible en langue française sur ce site. Pour voir comment le Reformer peut être appliqué à une tâche de génération d’images, je vous invite à consulter ce Google Colab.
Adaptation non supervisée de domaines pour la classification de textes
Ce travail propose une combinaison de mesures de distance qui incorporées dans une fonction de perte lors de l’entraînement d’un modèle, permet d’améliorer l’adaptation du domaine non supervisé. Le modèle est étendu à un modèle « DistanceNet Bandit ». Le problème clé abordé par cette méthode est de comprendre comment traiter la dissimilitude entre les données de différents domaines.
Amélioration des représentations contextualisées
Ce document propose une tâche de pré-entraînement, appelée token detection, qui se révèle plus efficace pour entraîner un modèle linguistique que les méthodes de basées sur un pré-entaînement avec des masques telles que BERT par exemple. Le modèle est baptisé ELECTRA et ses représentations contextualisées surpassent celles de BERT et XLNET à données identiques et à taille de modèle identique. La méthode fonctionne particulièrement bien sur des machines à faible capacité de calcul. Il s’agit d’un effort pour construire des modèles de langage plus petits et moins chers.
Interprétabilité des modèles
Distill a publié un document intitulé “Visualizing the Impact of Feature Attribution Baselines” qui traite des gradients intégrés utilisés pour interpréter les réseaux neuronaux dans divers problèmes. Dans le contexte de l’interprétabilité du modèle, le défi consiste à ce que la méthode puisse garantir que le modèle ne considère pas les caractéristiques manquantes comme étant importantes mais aussi que le modèle évite de donner aux entrées de la baseline une importance nulle (ce qui peut facilement arriver). L’auteur propose d’évaluer quantitativement les différents effets de certains choix précédemment utilisés et propose des choix de baseline qui préservent mieux la notion de manque.
Créativité et société 🎨
L’inadéquation des sentiments
Cette étude longitudinale révèle que les émotions extraites via l’utilisation d’algorithmes basés sur le texte ne sont souvent pas les mêmes que les émotions autodéclarées.
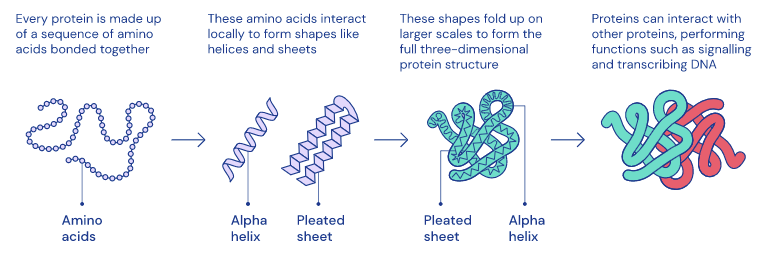
Compréhension de la dopamine et repliement des protéines
DeepMind a récemment publié deux articles intéressants dans Nature. Le premier vise à mieux comprendre le fonctionnement de la dopamine dans le cerveau grâce à l’apprentissage par renforcement. Le second est lié au repliement des protéines et tente de mieux comprendre ce fonctionnement afin de pouvoir éventuellement découvrir des traitements pour un large éventail de maladies.
Entretiens sur le ML
Dans une vidéo de Wired, Refik Anadol discute du potentiel des algorithmes d’apprentissage automatique pour créer des œuvres d’art.
L’un des secteurs où l’IA pourrait avoir un impact majeur est celui de l’éducation. Dans un nouvel épisode de “The Future of Everything”, Russ Altman et Emma Brunskill ont une discussion approfondie sur l’apprentissage assisté par ordinateur.
Outils et jeux de données ⚙️
Modèles PyTorch en production
Cortex est un outil permettant d’automatiser l’infrastructure et de déployer les modèles PyTorch en tant qu’API en production avec AWS. Pour en savoir plus sur la façon dont cela se fait, cliquez ici.
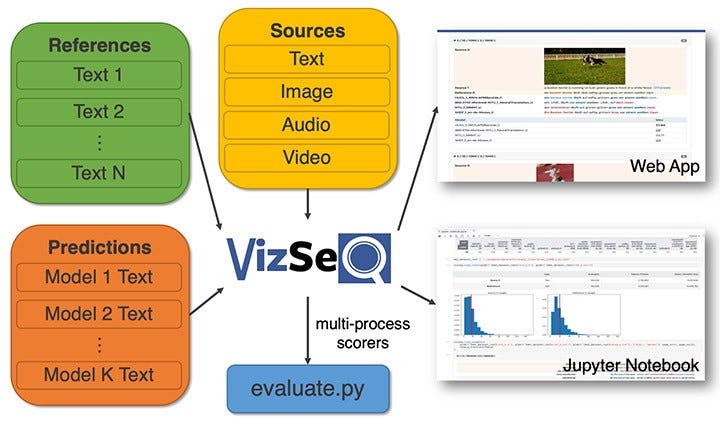
Visualisation des séquences de génération de texte
Facebook AI a lancé VizSeq, un outil qui aide à évaluer visuellement les séquences de textes générées sous des métriques comme BLUE et METEOR. L’objectif principal de cet outil est de fournir une analyse plus intuitive des ensembles de données textuelles via des visualisations. Pour lire l’article complet, cliquez ici.
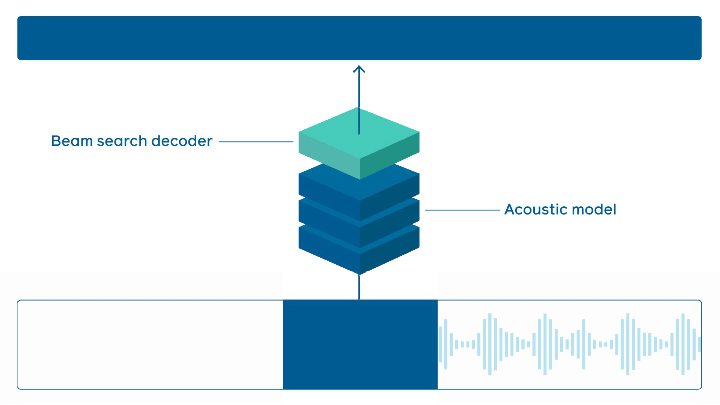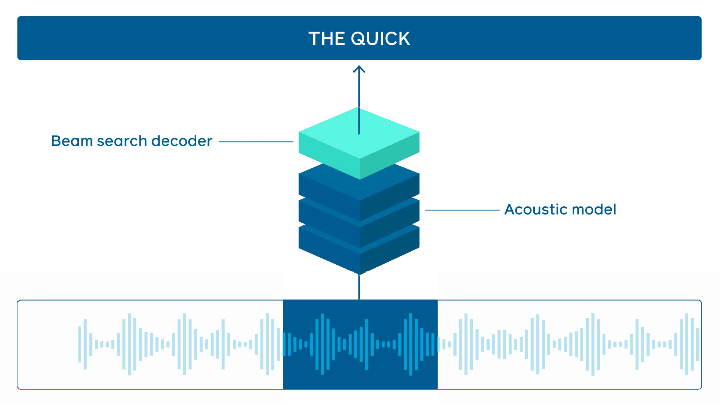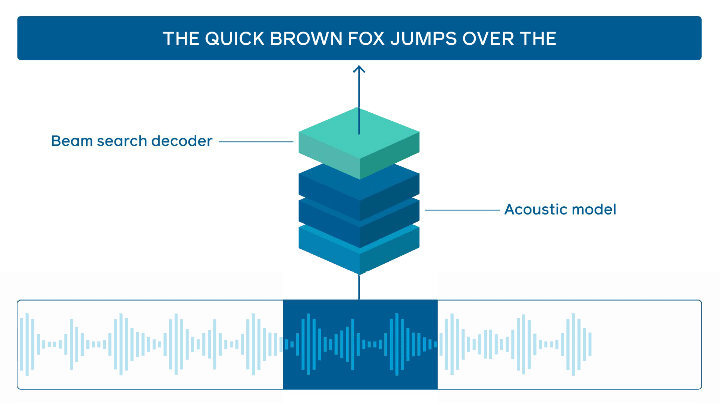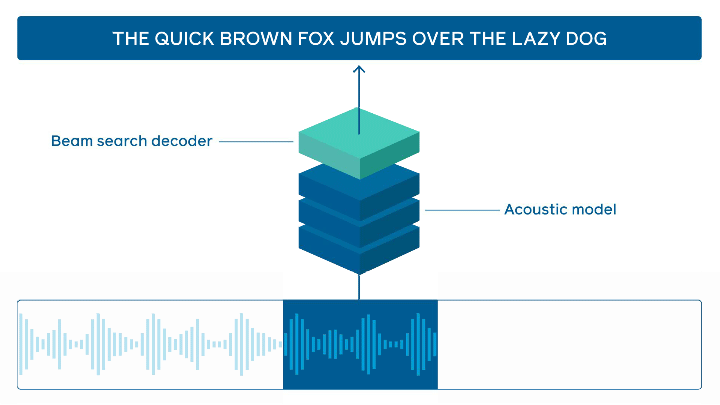
Reconnaissance vocale en ligne
Facebook AI a mis en open source son outil wav2letter@anywhere. Il s’agit d’un framework basé sur un Transformer acoustique afin d’établir un état de l’art en ligne de la reconnaissance vocale. Les principales améliorations portent sur la taille du modèle et la réduction de la latence entre l’audio et la transcription, deux éléments importants pour accélérer l’inférence en temps réel.
Ethique en IA 🚨
Implications de l’IA
Dans un objectif de prévenir les abus et les actions contraires à l’éthique des systèmes d’IA sur le public, l’Union européenne envisage d’interdire la technologie de reconnaissance faciale au public pendant cinq ans. (Article complet).
Coûts environnementaux des modèles de NLP modernes
Cet article aborde les considérations énergétiques et politiques des approches modernes en NLP. Les modèles actuels reposent sur des millions/milliards de paramètres et par conséquent sur d’importantes ressources de calcul. En résulte une consommation d’énergie très importante. Les auteurs espèrent sensibiliser davantage les chercheurs aux coûts environnementaux liés à l’entraînement de ces modèles de NLP.
Zachary Lipton parle d’équité, d’interprétabilité et des dangers du solutionnisme dans cette conférence donnée à l’Université de Toronto. Les principaux sujets tournent autour des considérations et des implications des approches d’équité en matière de blanchiment d’argent.
Articles et Blog ✍️
ML open source
Thomas Wolf, responsable scientifique de Hugging Face, donne des conseils à ceux qui envisagent d’utiliser du code open-source ou de faire des recherches. Trouvez le fil de discussion Twitter ici.
Introduction à l’apprentissage auto-supervisé en computer vision
Jeremy Howard a écrit cet article de blog qui présente brièvement le concept d’apprentissage auto-supervisé dans le contexte de la vision par ordinateur.
TinyBERT
Nous avons déjà constaté le succès de nombreuses variantes des modèles BERT (par exemple, DistilBERT) qui utilisent une certaine forme de distillation des connaissances pour réduire considérablement la taille du modèle et améliorer la vitesse. TinyBERT est une variante de BERT que ses auteurs ont appliqué à une solution de recherche par mots-clés. Ce projet a été inspiré par cette publication de Google. L’intérêt de l’architecture est qu’elle fonctionne sur un CPU standard et peut être utilisée pour améliorer et comprendre les résultats de recherche.
Transfert Learning actif
Rober Monarch a écrit un article Medium sur l’apprentissage actif par transfert, extrait de son prochain livre, Human-in-the-loop Machine Learning. Il écrit aussi d’autres articles sur les méthodes permettant de combiner l’intelligence humaine et l’intelligence machine pour résoudre des problèmes. Ses propos sont accompagnés de code Pytorch.
Les sombres secrets de BERT
Anna Roger a écrit cet article de blog qui parle de ce qui se passe réellement avec un BERT bien fine-tuné. Les résultats des analyses proposées suggèrent que BERT est sévèrement surparamétré et que les avantages identifiés de l’auto-attention ne sont pas nécessairement aussi affirmés, en particulier en ce qui concerne les informations linguistiques qui sont encodées et utilisées pour l’inférence.
Education 🎓
Neural Nets for NLP
Graham Neubig, professeur de NLP à la CMU, a publié des vidéos pour le cours “Neural Nets for NLP” dispensé ce semestre.
DeepMath
Vous voulez vous plonger dans les mathématiques qui se cachent derrière les méthodes d’apprentissage approfondies ? Voici une série de conférences vidéo accueillant un large éventail d’intervenants.
Cours et tutoriels Python
Google a publié le “Google IT Automation with Python Professional Certificate”. Pour en savoir plus sur le moyen d’obtention de ce certificat cliquez ici et pours en savoir plus sur les cours, cliquez ici.
Bien que le cours ne soit pas directement lié à la ML ou à l’IA, cela peut consister en un cours de base pour maîtriser le langage Python. Des bourses d’études sont également disponibles.
Voici une autre série de vidéos intitulée “Deep Learning (for Audio) with Python”, qui met l’accent sur l’utilisation de Tensorflow et de Python pour construire des applications liées à l’audio/musique en tirant parti de l’apprentissage profond.
Andrew Trask a publié une série de tutoriels, pour parvenir, étape par étape, à un apprentissage approfondi décentralisé et respectueux de la vie privée. Tous les notebooks contiennent des implémentations de PyTorch et sont destinés aux débutants.
Etats de l’art du deep learning
Cette conférence de Lex Fridman traite de la recherche et le développement récents dans le domaine de l’apprentissage approfondi. Il parle des grandes avancées sur des sujets tels que les perceptrons, les réseaux de neurones, la rétropropagation, CNN, l’apprentissage profond, ImageNet, les GAN, AlphaGo et les Transformers plus récemment. Cette conférence fait partie de la série “Deep Learning” du MIT.
Groupes d’études
Deux groupes d’étude / lectures d’articles conseillés par Elvis : le MLT et le nightai.
Le paysage de l’apprentissage par renforcement
Découvrez avec le Dr Katja Hofmann de Microsoft, les concepts et méthodes clés de l’apprentissage par renforcement dans sa série d’articles.
Mentions spéciales ⭐️
Jettez un œil à cette implémentation PyTorch utilisant de ResNet-18 appliquée à CIFAR-10 permettant d’atteindre une précision de 94%.
PyTorch 1.4 est sorti ! Consultez les notes de mise à jour ici.
Elona Shatri a rédigé un résumé sur la façon dont elle entend aborder la reconnaissance optique de la musique par un apprentissage approfondi.
Le titre de cet article de blog est explicite : “Les arguments en faveur de l’apprentissage approfondi bayésien”.
Chris Said partage son expérience dans l’optimisation de la taille des échantillons pour les tests A/B, une partie importante de la science des données pratiques. Les sujets abordés comprennent les coûts et les avantages des grandes tailles d’échantillon et les meilleures pratiques pour les praticiens.
Neural Data Server (NDS) est un moteur de recherche dédié à l’obtention de données d’apprentissage par transfert. Pour en savoir plus sur la méthode cliquez ici, et sur le service cliquez ici.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.