

Avant-propos d’Elvis
Bienvenue à la Newsletter sur le NLP ! Le troisième numéro traite de sujets tels que l’amélioration des agents conversationnels, les versions de BERT spécifiques à chaque langue, les ensembles de données gratuits, les versions des bibliothèques d’apprentissage approfondi, et bien plus encore.
Publications 📙
Versions de BERT spécifiques à chaque langue
J’ai perdu le compte du nombre de modèles BERT spécifiques à chaque langue, mais voici quelques-unes des versions récentes :
- BERT néerlandais (RobBERT, BERTje)
- BERT allemand
- BERT portugais
- BERT français (CamemBERT, FlauBERT)
- BERT italien (AlBERTo, UmBERTo)
- BERT espagnol (BETO)
- BERT arabe (araBERT)
Notez que la plupart de ces modèles sont également disponibles par le biais de la librairie de Transformers d’Hugging Face, qui a récemment été mise à jour avec la version 2.4.1.
Résultats trop optimistes de prédictions sur des données déséquilibrées : défauts et avantages de l’application du sur-échantillonnage
Cette publication révèle et examine en détail certains des défauts et des avantages de l’application du sur-échantillonnage pour traiter les jeux de données déséquilibrés avant de les partitionner. En outre, le travail reproduit des études antérieures et identifie cette faille méthodologique qui produit des résultats trop optimistes.
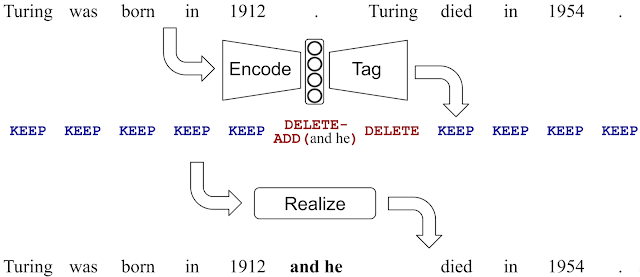
Encoder, étiqueter et réaliser : une approche contrôlable et efficace pour la génération de texte
Afin de réduire l’effet d’hallucination (production de sorties non supportées par le texte d’entrée) commun aux méthodes de génération de texte basées sur seq2seq, un groupe d’ingénieurs de Google a ouvert une méthode de génération de texte appelée LaserTagger.
L’idée principale de cette méthode est de produire des sorties en marquant des mots avec des opérations d’édition prédites (par exemple, KEEP, DELETE-ADD,, etc.) et en les appliquant aux mots d’entrée dans une étape dite de réalisation. Cette méthode remplace celle de génération de texte courante qui ne fait que générer des sorties à partir de zéro, ce qui est généralement lent et sujet à des erreurs. Le modèle offre d’autres avantages en plus de générer moins d’erreurs, tels que la possibilité de prévoir en parallèle les opérations d’édition tout en conservant une bonne précision et en surpassant une base de référence BERT dans des scénarios avec un nombre réduit d’exemples d’entraînement.
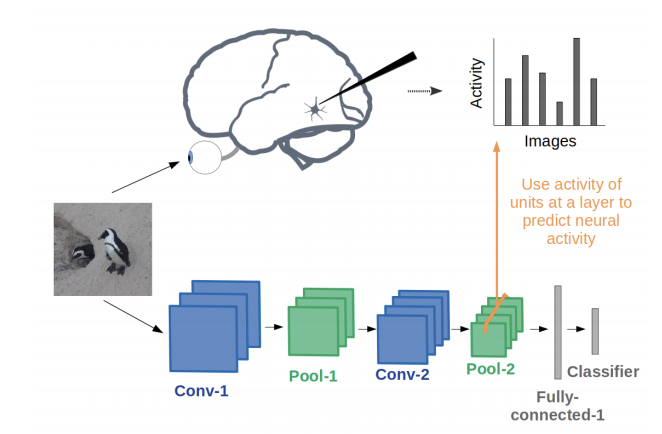
Les réseaux neuronaux convolutifs comme modèle du système visuel : passé, présent et futur
Grace Lindsay a publié ce rapport sur l’histoire des CNN et sur la manière dont ils sont évalués en tant que modèles de vision biologique, c’est-à-dire comment les représentations des CNN se comparent à celles du cerveau ? La discussion sur les nouvelles possibilités d’utilisation des CNN pour la recherche sur la vision est vivement recommandée aux lecteurs.
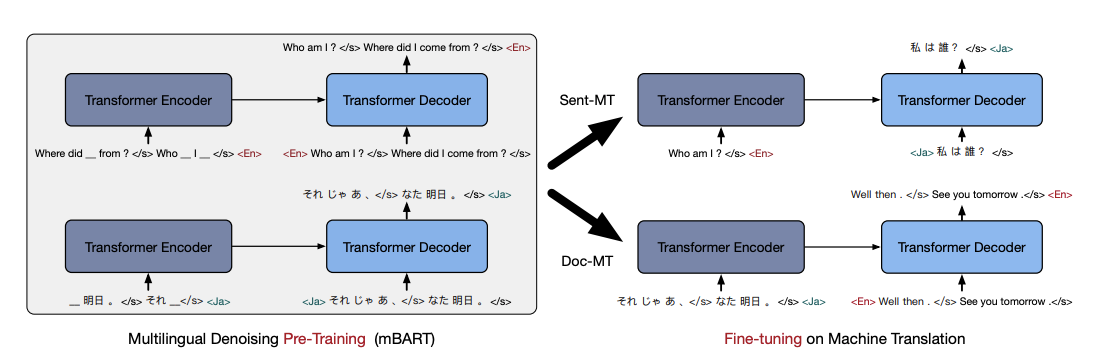
Multilingual Denoising Pre-training for Neural Machine Translation
Facebook AI a publié mBART, une méthode basée sur un auto-encodeur de débruitage multilingue seq2seq pré-entrainé sur des corpus monolingues à grande échelle pour la traduction automatique dans 25 langues.
Le texte d’entrée implique le masquage des phrases et la permutation des phrases (bruits). Un modèle basé sur un Transformer est appris pour reconstruire le texte dans plusieurs langues. Le modèle autorégressif complet n’est entraîné qu’une seule fois et peut être ajusté sur n’importe quelle paire de langues sans impliquer de modifications spécifiques à la tâche ou à la langue. Les problèmes de traduction au niveau du document et de la phrase sont abordés. En plus de montrer des gains de performance, les auteurs affirment que la méthode fonctionne bien sur la traduction automatique à faible ressource.
Sur l’amélioration des agents conversationnels
Meena est un agent conversationnel qui vise à mener des conversations plus sensibles et plus spécifiques ; des mesures définies pour saisir les attributs importants d’une conversation humaine (par exemple, la fluidité). Le modèle apprend le contexte de la conversation via un encodeur et formule une réponse sensible via le décodeur. Il est signalé que l’amélioration de la qualité des conversations a été possible en considérant des décodeurs plus puissants.
Vous pouvez également prendre connaissance des réflexions d’Alan Nichol (co-fondateur du siège de Rasa) sur ce travail.
Créativité et société 🎨
Test de compréhension de la lecture et analyseur de sentiments
Ming Cheuk a conçu cette application qui permet de tester les capacités de compréhension de lecture d’ALBERT. ALBERT est une version plus petite de BERT pour l’apprentissage des représentations des langues. L’auteur explique plus en détail le projet et les approches utilisées dans ce blog.
Hendrik Strobelt a également publié un petit projet dans lequel il montre comment réaliser un prototype d’un analyseur de sentiments interactif.

Le parcours d’un chercheur autodidacte sur l’IA chez Google
Dans cet entretien Emil, un chercheur de ML à Google Art & Culture, parle de son parcours en tant que chercheur autodidacte.
Outils et jeux de données ⚙️
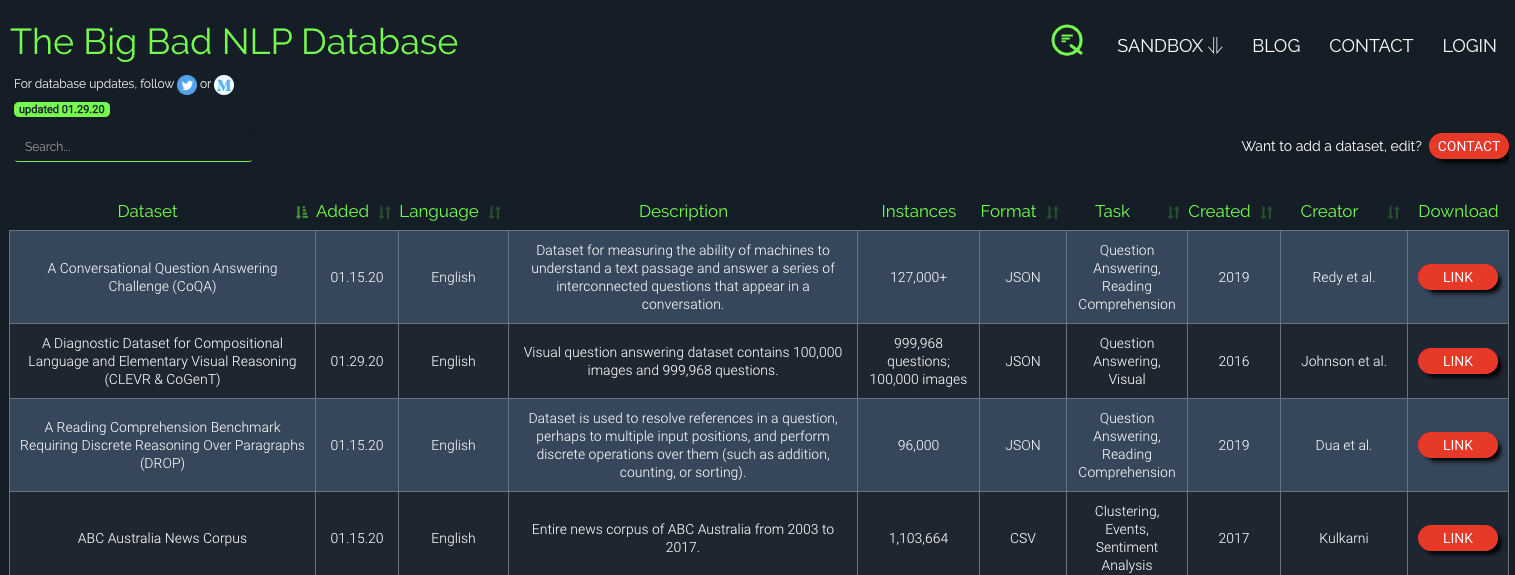
Jeux de données en libre accès
Google Dataset Search fournit désormais jusqu’à 25 millions de jeux de données. Il s’agit essentiellement d’un moteur de recherche pour les ensembles de données.
La base de données Big Bad NLP est un site web où vous pouvez rechercher une base de données dédiée de plus de 200 jeux de données de NLP de tous types pour des tâches telles que le raisonnement, l’analyse des sentiments, la réponse aux questions, l’inférence d’implication, etc…
Librairie d’apprentissage par renforcement
Chris Nota a développé et publié une librairie PyTorch pour la construction d’agents d’apprentissage par renforcement basés sur des algorithmes populaires tels que DQN, PPO et DDPG. L’accent de la librairie est mis sur la conception orientée objet et sur la mise en œuvre et l’évaluation rapides de nouveaux agents d’apprentissage par renforcement.
Explicabilité et interprétabilité du ML
Si vous travaillez actuellement avec des modèles linguistiques basés sur des textes et que vous souhaitez comprendre comment les interpréter plus facilement lorsqu’ils sont appliqués à différentes tâches linguistiques, alors vous pourriez être intéressé par Captum. Captum est une librairie d’interprétabilité qui peut être utilisée pour analyser l’importance des caractéristiques, interpréter des modèles de texte et de vision, interpréter des modèles multimodaux, et d’autres modèles tels que BERT utilisé pour la réponse aux questions.
Si vous vous intéressez à l’explicabilité des modèles, cet tutoriels peuvent également vous intéresser.
Libraries de ML et DL
L’équipe de Google Research a publié Flax, une libririe de réseaux neuronaux flexible et puissante basée sur JAX qui fournit un framework pour le calcul rapide et l’entraînement de modèles de ML en utilisant les API typiques de Numpy.

Flax syntax
Thinc est une librairie légère de deep learning développée par les créateurs de spaCy. Elle offre des API de programmation fonctionnelle pour composer, configurer et déployer des modèles personnalisés construits avec des librairies comme PyTorch et TensorFlow.
Lyft lance Flyte, une plateforme, prête pour la production et sans serveur, pour le déploiement dde travail de traitement de données et de ML.
Un outil pour l’IA conversationnelle
DeepPavlov offre une solution gratuite et facile à utiliser pour la construction de systèmes de dialogue et de systèmes conversationnels complexes. DeepPavlov est livré avec plusieurs composants prédéfinis pour résoudre les problèmes liés au NLP. Il intègre BERT (y compris le BERT conversationnel) dans trois tâches : la classification de textes, la reconnaissance d’entités nommées (et le marquage des séquences en général) et la réponse aux questions. En conséquence, il a permis d’améliorer considérablement toutes ces tâches. (Google Colab | Blog | Démo).
Ethique en IA 🚨
Reconnaissance faciale et vie privée
Le New York Times a rédigé un article sur les différentes perspectives concernant la vie privée impliquant la technologie de reconnaissance faciale. Ce reportage porte sur une “société secrète” appelée Clearview qui utiliserait la technologie d’IA pour construire une reconnaissance faciale universelle à partir d’images récupérées sur les réseaux sociaux tels que Twitter, Facebook et YouTube, etc… Cette technologie soulève des inquiétudes quant au respect de la vie privée, mais elle serait également utilisée principalement pour l’application de la loi. Pour en savoir plus, cliquez ici.
Progrès de l’IA au niveau humain
Dans cet article, Jeremy Kahn discute en détail de la différence entre « l’IA étroite » et « l’IA générale » dans le contexte des progrès actuels de la technologie. Outre les nombreux sujets abordés, de nombreuses questions se posent sur les bénéfices de la réalisation de l’IA générale. L’article mentionne également l’intérêt récent des grandes entreprises technologiques qui investissent dans ces efforts. L’article inclut plusieurs préoccupations soulevées par des chercheurs respectés qui dénoncent le comportement “irresponsable et contraire à l’éthique” de certains organismes de recherche qui tentent de manipuler les récits sur l’IA à leur profit.
Technologies d’IA préservant la vie privée
L’un des efforts mené afin de promouvoir une IA ethique, responsable et respectant la vie privée est celui de la communauté [OpenMined] https://twitter.com/OpenMinedOrg). Si vous voulez en savoir plus, vous pouvez écouter Andrew Trask, parler de cette initiative dans cette vidéo faisant partie de la série de conférences du MIT sur l’apprentissage profond.
Comprendre l’éthique et la sécurité
Le Dr David Leslie a publié ce rapport très détaillé sur des sujets qui aident à mieux comprendre l’IA dans le contexte de l’éthique et de la sécurité. Il vise à aider les développeurs et les chercheurs à mieux concevoir et mettre en œuvre des systèmes d’IA pour le secteur public.

Articles et Blog ✍️
Tutoriel sur l’accélération de la tokenisation
Steven van de Graaf a écrit cet article à propos des performances de la librairie Tokenizers d’Hugging Face par rapport au tokenizer standard intégré utilisé dans la librairie Transformers. Steven constate qu’une implémentation prend 10,6 secondes pour tokenizer 1 million de phrases et que le temps d’exécution est divisé par 9.
Les modèles linguistiques peuvent-ils vraiment comprendre ?
The Gradient a récemment publié ce post de Gary Marcus où il discute de ce qu’il croit être des défauts fondamentaux derrière des modèles de langage comme GPT-2. L’argument principal de Gary Marcus est qu’un modèle entraîné pour pouvoir prédire le mot suivant n’est pas nécessairement un modèle capable de comprendre ou de raisonner. C’est-à-dire que “la prédiction est une composante de la compréhension, pas l’ensemble”.
Curriculum for Reinforcement Learning
Lillian Weng résume plusieurs approches basées sur les curriculum et la façon dont cela peut être utilisé pour entraîner de façon efficace des agents d’apprentissage par renforcement. Weng aborde les défis de la conception d’une telle approche, qui nécessite généralement de trier la complexité des tâches et de fournir au modèle une séquence de tâches dont le niveau de difficulté augmente au cours de l’entraînement.
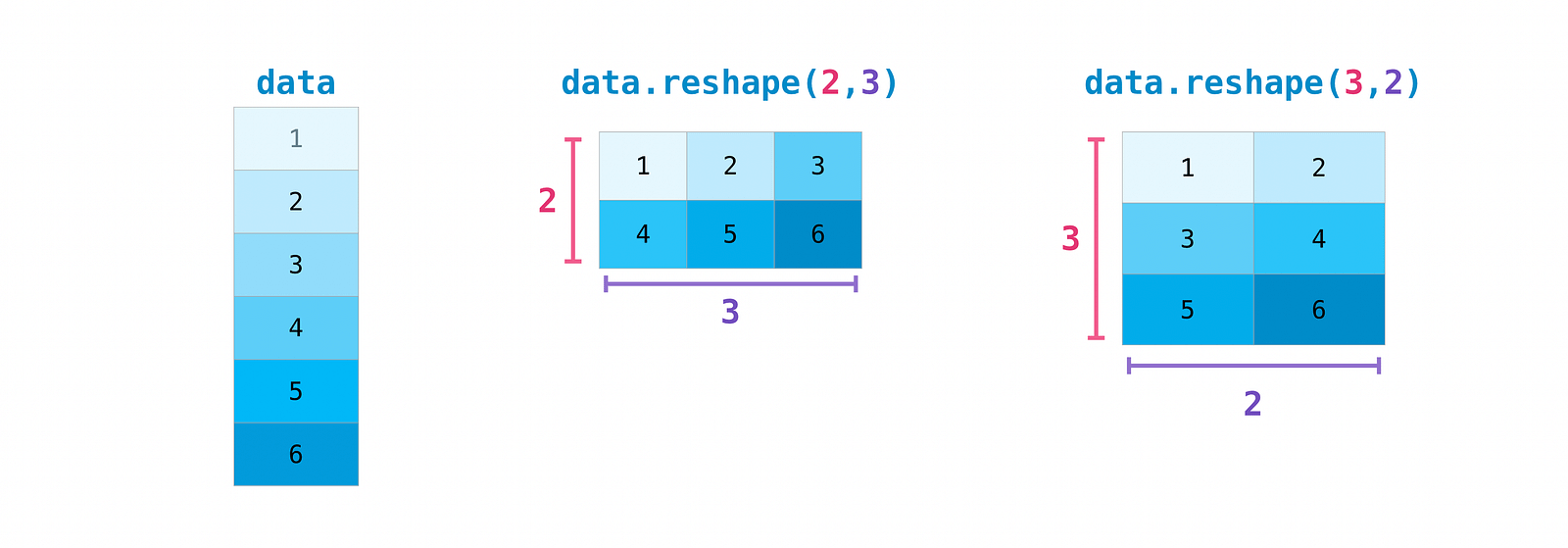
Introduction à NumPy
Anne Bonner a récemment publié ce tutoriel détaillé présentant les bases de NumPy. Il est constitue une base solide pour les personnes souhaitant s’initier à cette librairie.
Education 🎓
Fondements de l’apprentissage machine et de l’inférence statistique
Anima Anandkumar, du Caltech, a publié un cours intitulé “Fondements de l’apprentissage machine et de l’inférence statistique”. Le cours se concentre sur les concepts de ML tels que les matrices, les tenseurs, l’optimisation, les modèles probabilistes, les réseaux de neurones et bien plus encore. Ce cours aborde les aspects théoriques du ML. (la playlist vidéo | le programme du cours)
Série de conférences sur le DL
DeepMind s’est associé à l’UCL pour lancer une série de 12 conférences sur l’apprentissage profond données par des chercheurs de DeepMind.
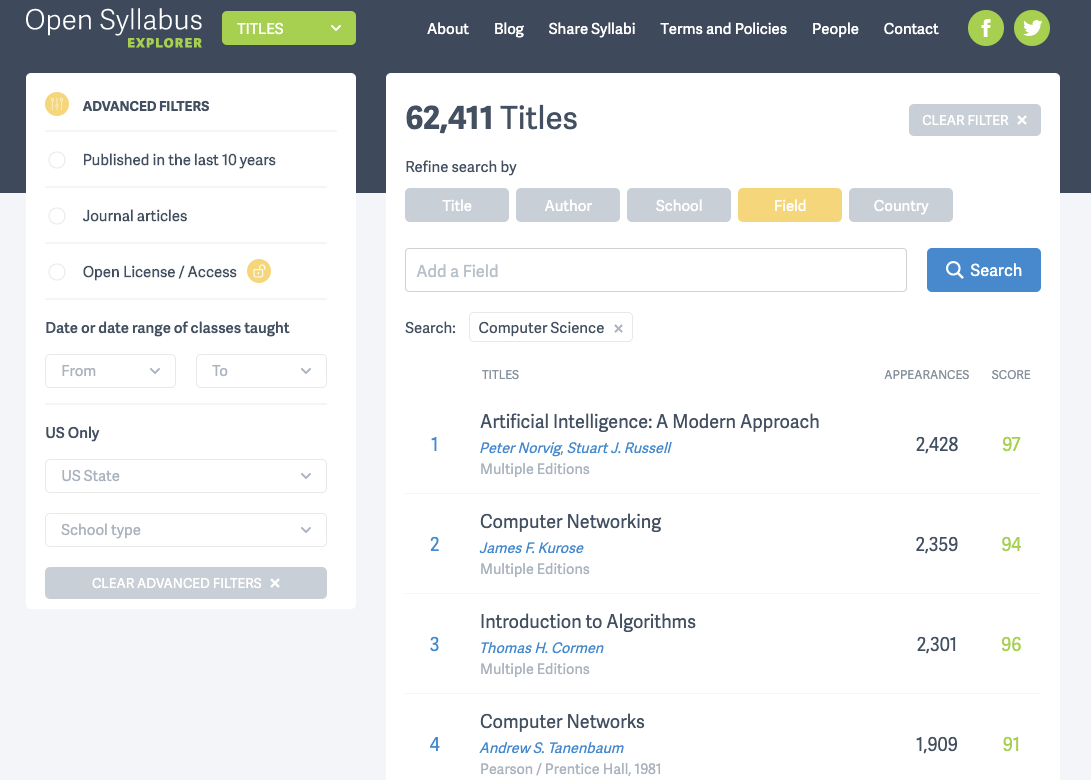
~7 million de programmes d’études
Open Syllabus est une organisation à but non lucratif qui utilise le crowdsourcing pour mettre en place un programme d’enseignement supérieur dans une base de données en ligne. Elle contient actuellement environ sept millions de programmes.
Discuter, partager et apprendre sur le ML
r/ResearchML est une nouvelle sous-rubrique de reddit consacré au ML. Celui-ci est davantage axé sur la recherche et encourage des discussions plus approfondies.
Mentions spéciales ⭐️
Découvrez comment GitHub exploite l’apprentissage machine pour repérer les problèmes faciles et personnalisés des développeurs afin qu’ils puissent s’attaquer aux questions qui correspondent à leurs intérêts. Cela encourage des contributions plus rapides et plus nombreuses de la part des contributeurs de logiciels libres.
Sebastian Ruder a publié une nouvelle newsletter. On y trouve une mise à jour des progrès du NLP, des rétrospectives sur la dernière décennie, de nouveaux cours de NLP, et d’autres sujets.
Jetez un coup d’œil à ces notebooks TensorFlow 2.0 qui vont de CycleGAN à Transformers en passant par les tâches de sous-titrage d’images. Ils ont été rendus publics par l’école d’apprentissage profond pour la science du LBNL.
Un blog pour s’initier aux réseaux neuronaux bayésiens.
John Schulman partage quelques conseils pour les futurs chercheurs du LBNL sur la façon de mieux choisir les problèmes de recherche et d’être plus stratégique dans la réalisation des tâches de recherche. John partage également des conseils pour le développement personnel et le progrès continu.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.