

Publications 📙
Turing-NLG: Un modèle linguistique de 17 milliards de paramètres par Microsoft
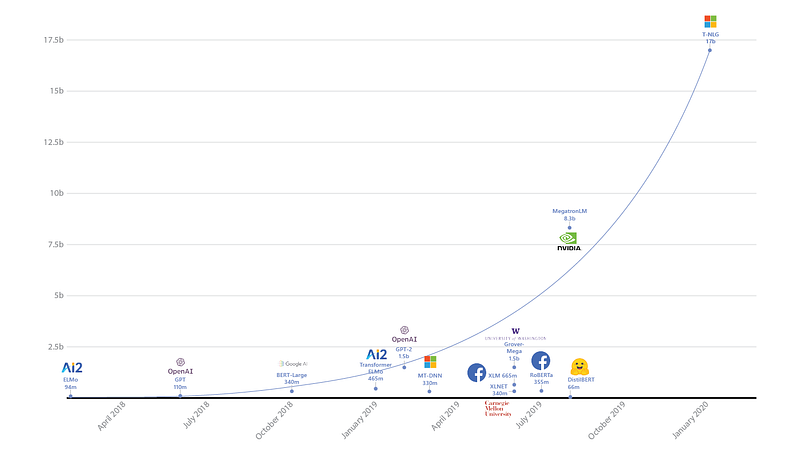
Turing Natural Language Generation (T-NLG) est un modèle de 17 milliards de paramètres proposé par les chercheurs en IA de Microsoft. Il est à ce jour, le plus grand modèle de langage connu (illustré dans la figure ci-dessous) et est basé sur un Transformer à 78 couches qui surpasse les résultats précédents (détenus par Megatron-LM de NVIDIA) sur la perplexité de WikiText-103. Il a été testé sur des tâches telles que la réponse à des questions et le résumé abstrait. Le modèle est rendu possible par une librairie d’optimisation de l’entraînement appelée DeepSpeed avec ZeRO, qui est également présentée plus loin dans cette newsletter.
Neural based Dependency Parsing
Miryam de Lhoneux a publié sa thèse de doctorat intitulée “Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages”. Ce travail porte sur l’utilisation d’approches neurales pour l’analyse des dépendances dans les langues typologiquement diverses (c’est-à-dire les langues qui construisent et expriment le sens de manière structurellement différente). Ce travail rapporte que les RNN et les couches récursives pourraient être utiles pour l’incorporation dans les parsers car elles aident à informer les modèles avec des connaissances linguistiques importantes nécessaires pour l’analyse. D’autres idées comprennent l’utilisation de l’analyse syntaxique polyglotte et des stratégies de partage de paramètres pour l’analyse syntaxique dans des langues apparentées et non apparentées.
Extraction d’informations de bout en bout dans le cloud avec BERT
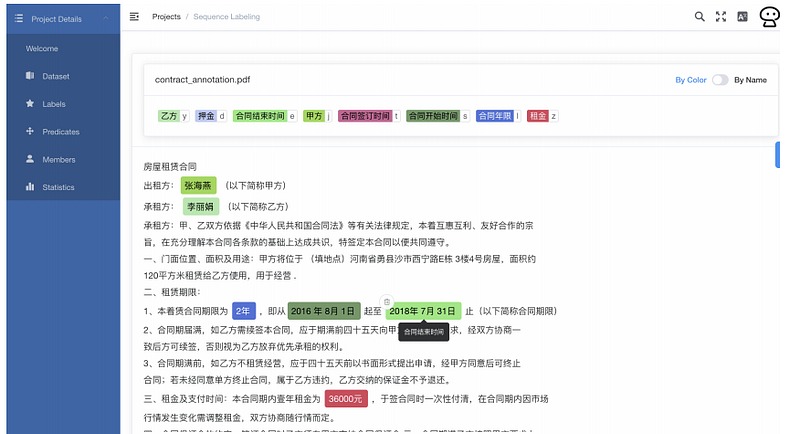
Une équipe de chercheurs a publié un article décrivant comment des modèles de Transformers comme BERT peuvent aider à l’extraction d’informations de bout en bout dans des documents commerciaux spécifiques à un domaine, tels que les dépôts réglementaires et les contrats de location de propriété. Non seulement ce type de travail peut aider à optimiser les opérations commerciales, mais il montre également l’applicabilité et l’efficacité des modèles basés sur BERT sur des régimes avec très peu de données annotées. Une application, et ses détails de mise en œuvre, qui fonctionne sur le cloud est également proposée (voir figure ci-dessous).
Question Answering Benchmark
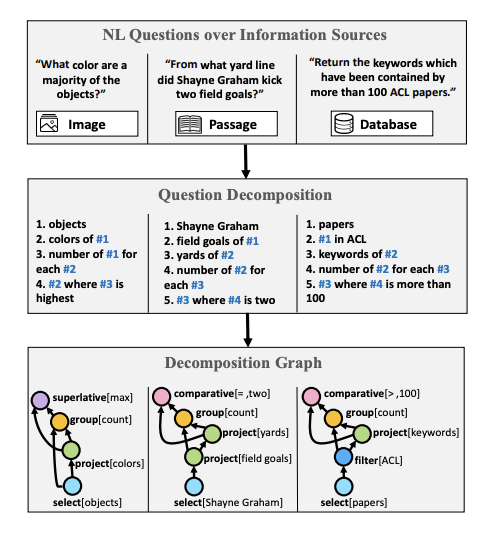
Wolfson et al. (2020) ont publié un benchmark pour la compréhension des questions ainsi qu’une méthode pour décomposer une question qui est nécessaire pour calculer une réponse appropriée. Ils s’appuient sur le crowdsourcing pour annoter les étapes nécessaires à la décomposition des questions. Pour montrer la faisabilité et l’applicabilité de l’approche, ils améliorent la réponse aux questions du domaine ouvert en utilisant l’ensemble de données HotPotQA.
Données radioactives : le traçage par l’entraînement
Les chercheurs de Facebook AI ont récemment publié un travail qui vise à marquer les images (appelées données radioactives) afin de vérifier si un jeu de données particulier a été utilisé pour l’entraînement d’un modèle de ML. Ils ont découvert qu’il est possible d’utiliser un marqueur intelligent qui déplace les caractéristiques dans une direction, que le modèle utilise pour aider à détecter l’utilisation de données radioactives même si seulement 1 % des données d’entraînement sont radioactives. C’est un défi car tout changement dans les données peut potentiellement dégrader la précision du modèle. Selon les auteurs, ce travail peut « aider les chercheurs et les ingénieurs à savoir quel jeu de données a été utilisé pour entraîner un modèle, afin de mieux comprendre comment les différents ensembles de données affectent les performances des différents réseaux neuronaux ». Cette approche semble importante pour les applications critiques de ML. Consultez le document complet ici.
REALM: Retrieval-Augmented Language Model Pre-Training
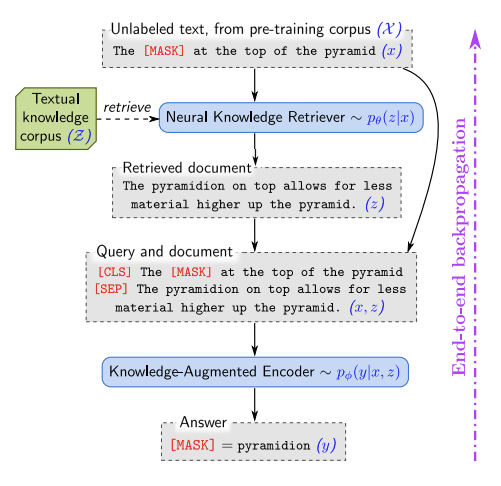
REALM est une approche d’extraction à grande échelle qui utilise un corpus de connaissances textuelles pour pré-entraîner un modèle de langue de manière non supervisée. Les tâches abordées et évaluées à l’aide de REALM comprennent des questions ouvertes répondant à des critères de référence. Outre l’amélioration de la précision du modèle, les autres avantages comprennent les composantes de modularité et d’interprétabilité.
Créativité et société 🎨
Permettre la présentation à distance de documents et d’affiches lors de conférences scientifiques
La semaine dernière, une pétition a été lancée pour permettre la présentation à distance de documents et d’affiches lors de conférences scientifiques comme celles liées au ML. Il semble que Yoshua Bengio, plaide pour que les gens aillent signer la pétition. Il l’a clairement indiqué dans son nouveau blog.
Défi de l’abstraction et du raisonnement
François Chollet a récemment mis en ligne un concours Kaggle où il a publié le Corpus d’abstraction et de raisonnement (ARC). Il vise à encourager les utilisateurs à créer des systèmes d’IA capables de résoudre des tâches de raisonnement auxquelles ils n’ont jamais été exposés. L’espoir est de commencer à construire des systèmes d’IA plus robustes, capables de résoudre mieux et rapidement de nouveaux problèmes par eux-mêmes, ce qui pourrait aider à résoudre les applications du monde réel les plus difficiles, comme l’amélioration des voitures autonomes.
Publications de ML et NLP en 2019
Marek Rei publie son analyse annuelle sur les statistiques en lien avec l’apprentissage machine et le NLP pour l’année 2019. Les conférences incluses dans l’analyse sont ACL, EMNLP, NAACL, EACL, COLING, TACL, CL, CoNLL, NeurIPS, ICML, ICLR, et AAAI.
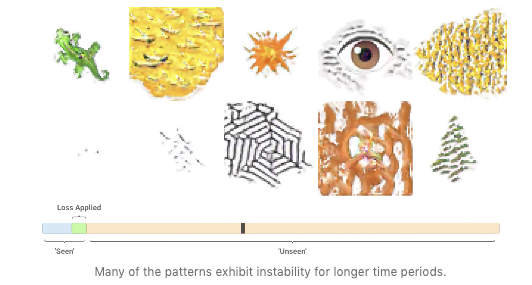
La croissance d’automates cellulaires neuronaux
La morphogenèse est un processus d’auto-organisation par lequel certaines créatures comme les salamandres peuvent se régénérer ou réparer des dommages corporels. Ce processus est robuste aux perturbations et de nature adaptative. Inspirés par ce phénomène biologique et par le besoin de mieux comprendre le processus, les chercheurs ont publié un article intitulé “Growing Neural Cellular Automata”, qui adopte un modèle différenciable pour la morphogenèse visant à reproduire les comportements et les propriétés des systèmes d’autoréparation. L’espoir est de pouvoir construire des machines autoréparatrices qui possèdent la même robustesse et plasticité que la vie biologique. En outre, cela permettrait de mieux comprendre le processus de régénération lui-même. Les applications qui peuvent en bénéficier comprennent la médecine régénératrice et la modélisation des systèmes sociaux et biologiques.
Visualiser l’attention des Transformers
Hendrik Strobelt a partagé ce repertoire qui montre comment construire rapidement une visualisation interactive simple de l’attention d’un Transformer à travers une application web en utilisant la bibliothèque HuggingFace et d3.js.
SketchTransfer : Une nouvelle tâche stimulante pour explorer l’invariance des détails et les abstractions apprises par les réseaux
SketchTransfer propose une nouvelle tâche pour tester la capacité des réseaux neuronaux à supporter l’invariance en présence/absence de détails. On a longtemps débattu du fait que les réseaux ne peuvent pas se généraliser à des variations qui n’ont pas encore été observées pendant l’entraînement, comme par exemple traiter les détails visuels manquants lorsqu’ils regardent des dessins animés. Le document examine et publie un ensemble de données pour aider les chercheurs à étudier attentivement le problème de « l’invariance des détails » en fournissant des croquis non étiquetés et des exemples étiquetés d’images réelles.

Outils et jeux de données ⚙️
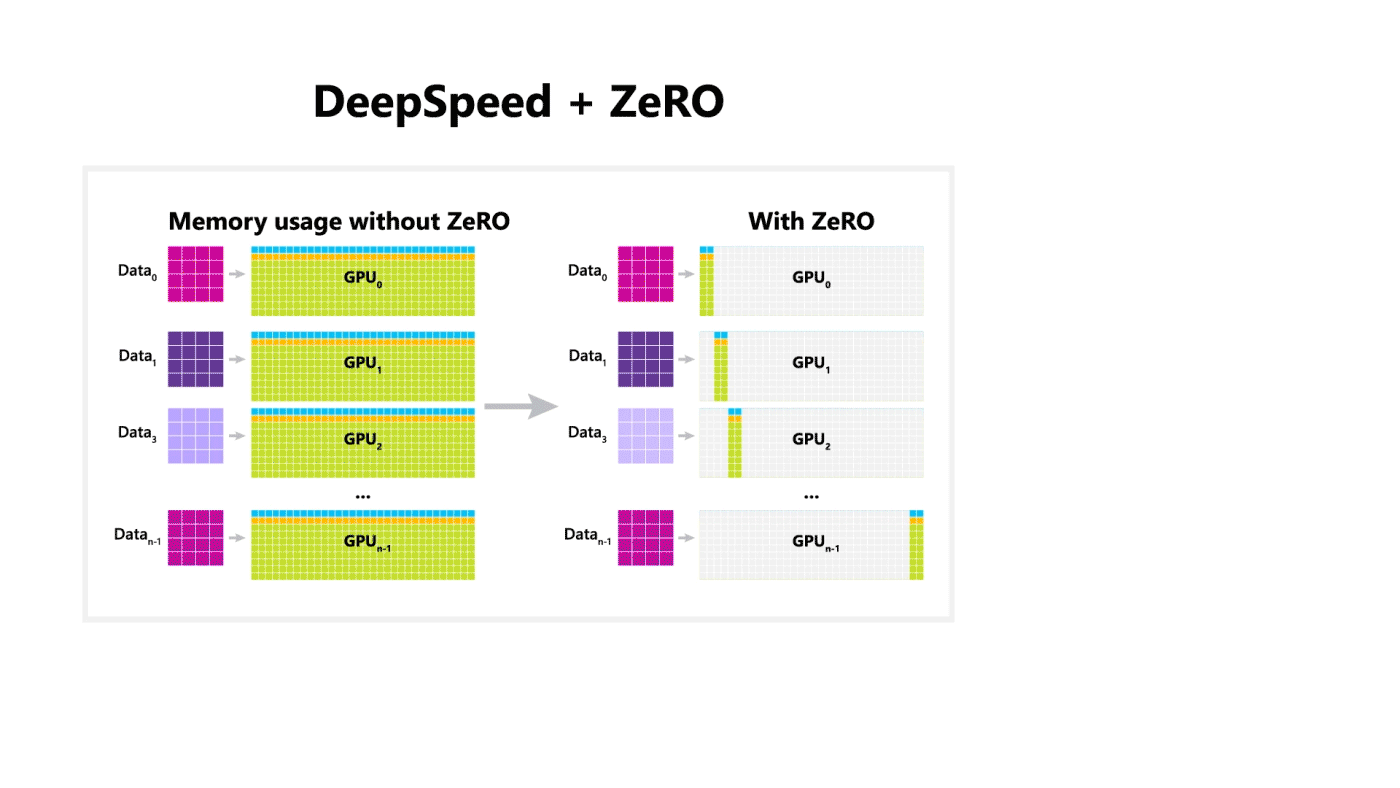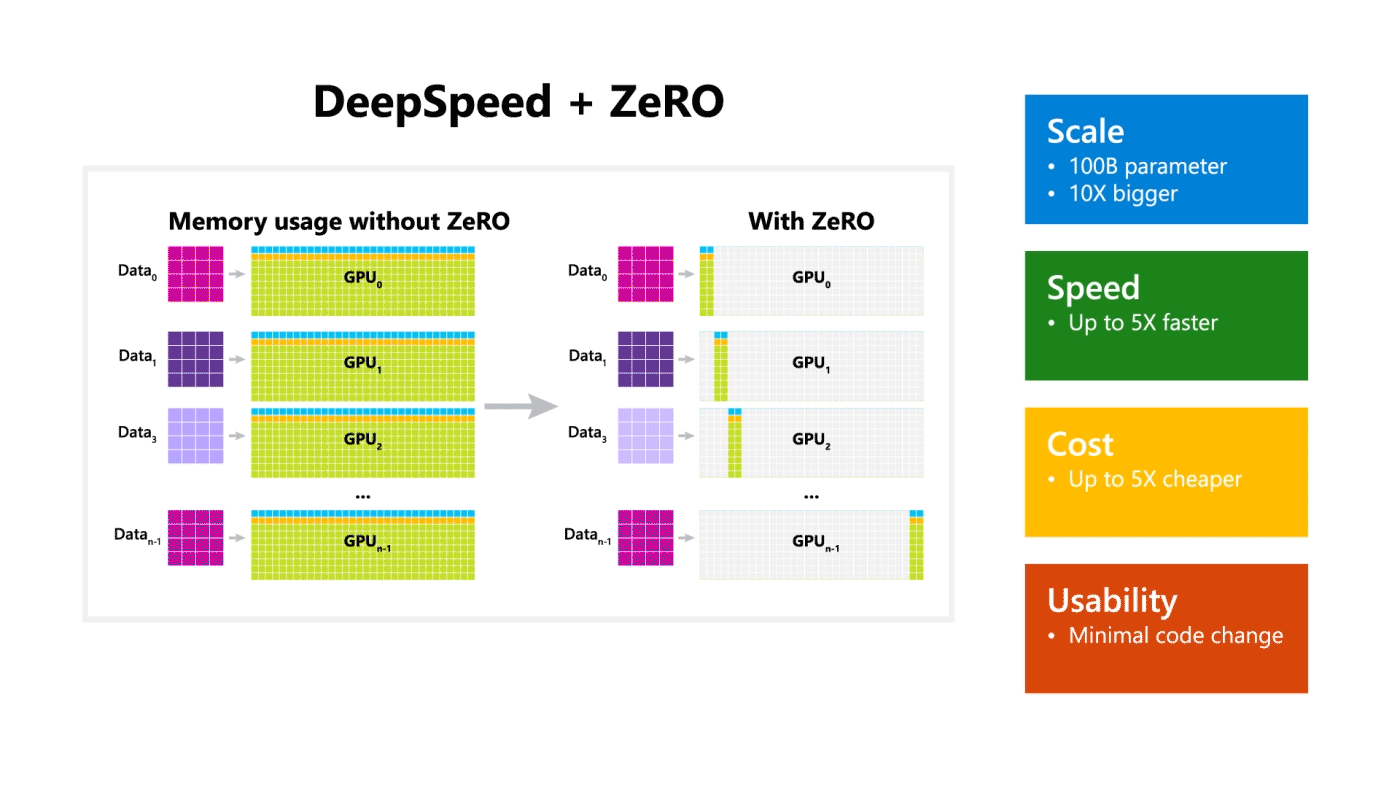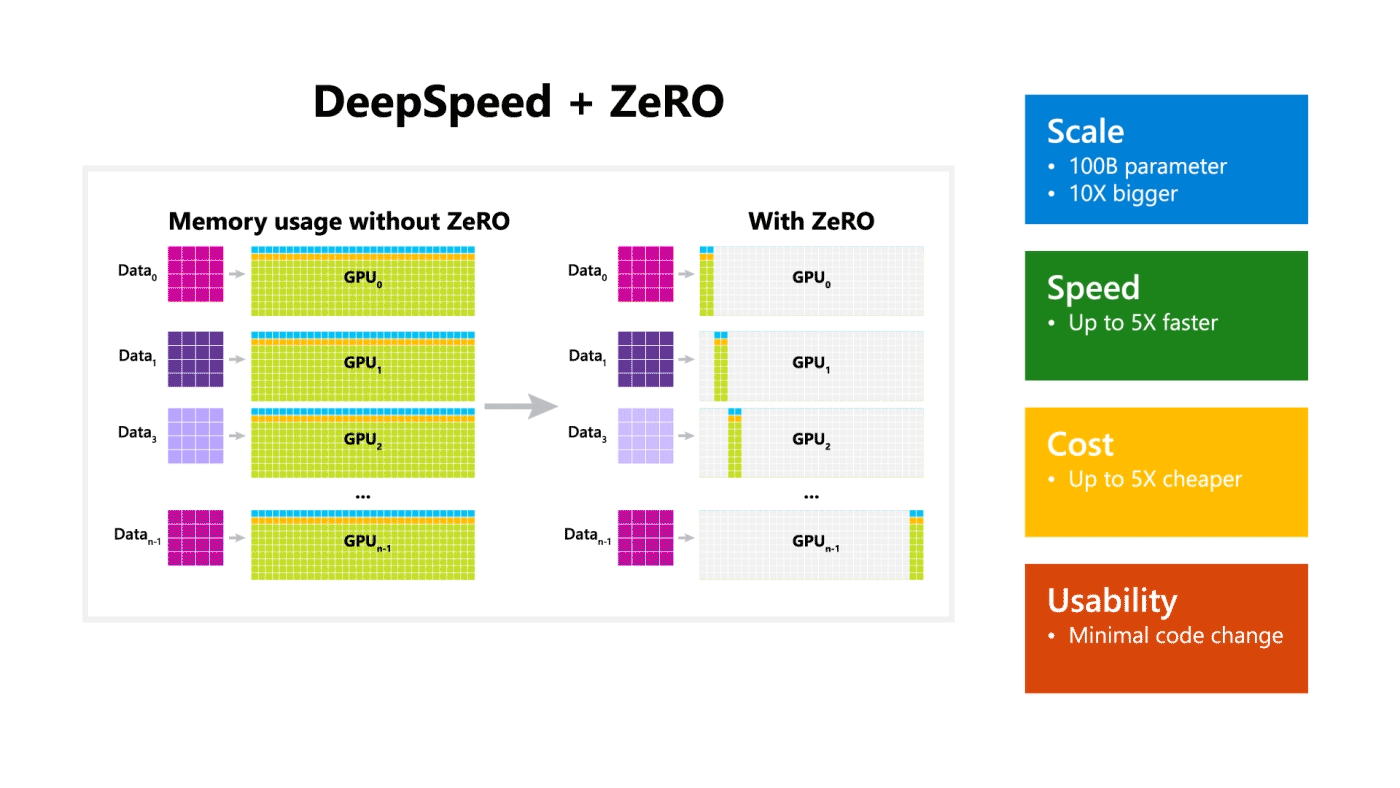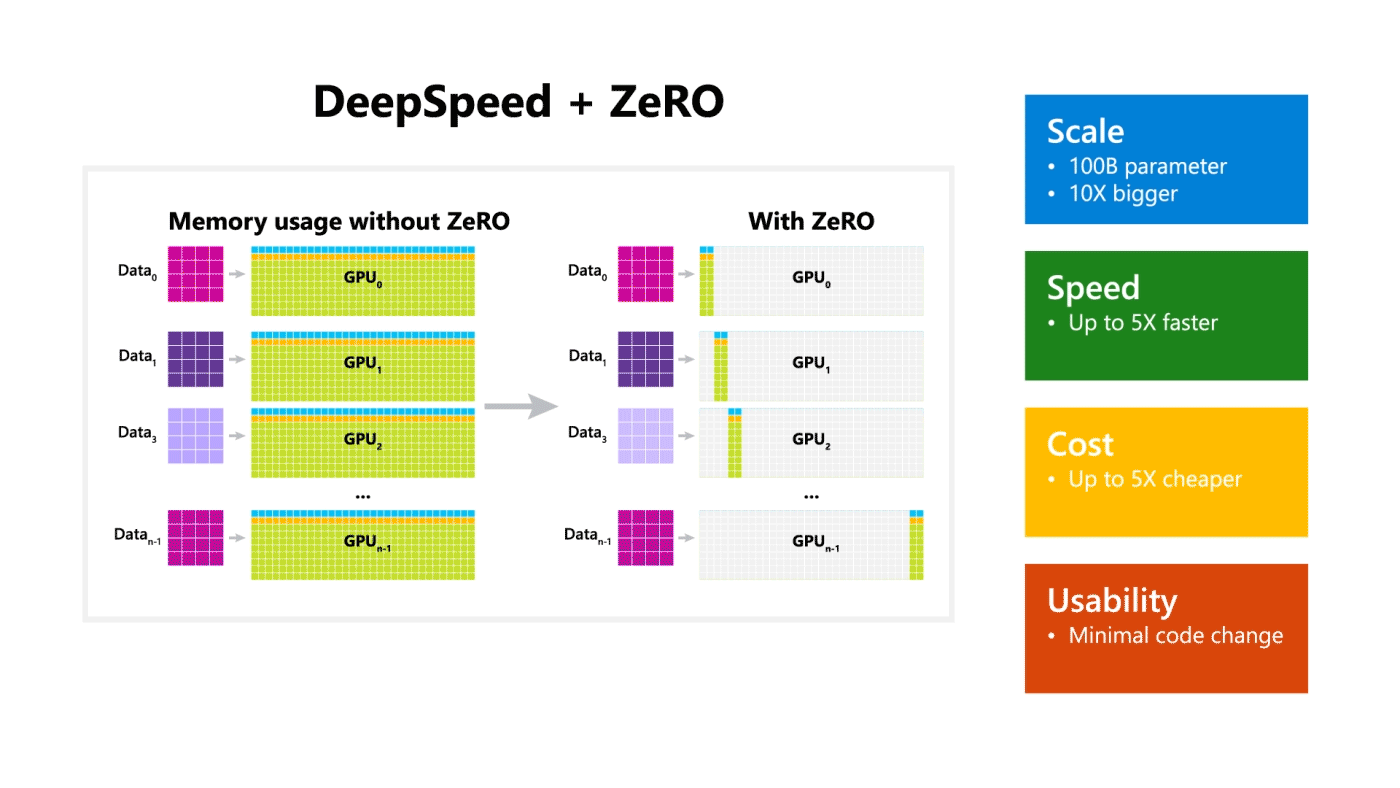
DeepSpeed + ZeRO
Microsoft a dévoilée une librairie d’optimisation pour l’entrainement appelée DeepSpeed. Elle est compatible avec PyTorch et peut permettre l’entrainement d’un modèle de 100 milliards de paramètres. La librairie se concentre sur quatre aspects importants de l’entrainement d’un modèle : l’échelle, la vitesse, le coût et la convivialité. DeepSpeed a été lancé en même temps que ZeRO. ZeRO est une technologie d’optimisation de la mémoire qui permet de faire du deep learning distribué à grande échelle sur GPU tout en améliorant le débit de trois à cinq fois plus que le meilleur système actuel.
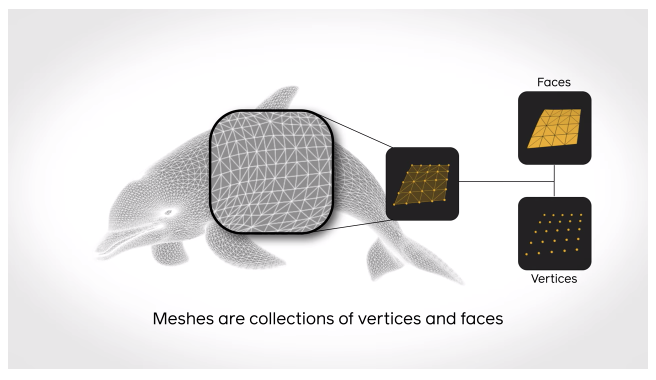
Une librairie pour mener des recherches rapides et efficaces sur le DL en 3D
PyTorch3D est une boîte à outils open-source pour la recherche sur le DL en 3D. La librairie consiste en des implémentations rapides et optimisées d’opérateurs 3D et de fonctions de perte fréquemment utilisés. Elle est également dotée d’un moteur de rendu modulaire et différenciable qui permet de mener des recherches sur des entrées 3D complexes et de faire des prévisions 3D de haute qualité.
Gestion de la configuration de projets de ML
Hydra est un outil pour gérer plus efficacement les projets de ML complexes. Il est destiné à aider les chercheurs de PyTorch en offrant une réutilisation fonctionnelle des configurations. Son principal avantage est qu’il permet au programmeur de gérer la configuration comme du code de composition, ce qui signifie que le fichier de configuration peut être facilement écrasé. Hydra peut également aider à gérer automatiquement le répertoire de travail des résultats de votre projet de ML, ce qui est utile lorsque vous avez besoin de sauvegarder et d’accéder aux résultats de plusieurs expériences pour des travaux multiples. Pour en savoir plus, cliquez ici.
Une boîte à outils pour l’inférence causale avec les réseaux bayésiens
CausalNex est une boîte à outils pour “l’inférence causale avec les réseaux bayésiens”. L’outil vise à combiner l’apprentissage machine et le raisonnement causal pour découvrir des relations structurelles dans les données. Les auteurs ont également préparé un guide d’introduction sur le pourquoi et le comment de l’inférence causale avec les réseaux bayésiens en utilisant la librairie Python proposée.

Google Colab Pro est maintenant disponible
Google Colab propose désormais une édition Pro, qui offre des avantages tels qu’un accès exclusif à des GPU et TPU plus rapides, des durées d’exécution plus longues et plus de mémoire.
TyDi QA: Un benchmark pour le Question/Anwsering multilingues
Google AI publie TyDi QA, un ensemble de données multilingues qui peut encourager les chercheurs à répondre à des questions dans des langues plus typologiquement diverses. C’est à dire qui construisent et expriment le sens de différentes manières. L’idée est de motiver les chercheurs à construire des modèles plus robustes sur des langues typologiquement éloignées, telles que l’arabe, le bengali, le coréen, le russe, le télougou et le thaï, afin de généraliser à encore plus de langues.

Question Answering pour Node.js
Hugging Face publie une librairie de questions/réponses basée sur DistilBERT. Ce modèle peut fonctionner en production en utilisant Node.js avec seulement 3 lignes de code. Le modèle tire parti de la mise en œuvre rapide de Tokenizers, et de TensorFlow.js (une bibliothèque populaire pour l’utilisation de modèles d’apprentissage machine avec Javascript).
Ethique en IA 🚨
Identifier les biais subjectifs dans les textes
Ce podcast présente Diyi Yang, chercheur en sciences sociales computationnelles, qui explique comment les systèmes d’IA peuvent aider à identifier les biais subjectifs dans les informations textuelles. Il s’agit d’un domaine de recherche important impliquant les systèmes d’IA et de NLP. En particulier lorsque nous discutons de la consommation de médias textuels tels que les news qui peuvent être facilement encadrés pour biaiser les consommateurs alors qu’en réalité ils devraient viser à être plus objectifs. Du point de vue de l’application, il devient essentiel d’identifier automatiquement le biais subjectif présent dans les médias textuels afin d’aider les consommateurs à devenir plus conscients du contenu qu’ils consomment. L’épisode traite également de la manière dont l’IA peut également perpétuer le biais.
Intelligence artificielle, valeurs et alignement
L’essor des systèmes d’IA et la manière dont ils s’alignent sur les valeurs humaines est un domaine de recherche actif qui implique l’éthique dans les systèmes d’IA. DeepMind a récemment publié un papier qui examine plus en profondeur les questions philosophiques entourant l’alignement de l’IA. Le rapport se concentre sur deux parties : technique (c’est-à-dire comment coder les valeurs qui rendent les résultats des agents d’IA fiables) et normative (quels principes seraient justes à coder dans l’IA). Le document préconise une approche fondée sur des principes visant à préserver à préserver un traitement équitable malgré la différence de croyances et d’opinions.
Sur l’audit des systèmes d’IA
VentureBeat rapporte que Google Researchers, en collaboration avec d’autres groupes, a créé un framework appelé SMACTR qui permet aux ingénieurs de vérifier les systèmes d’IA. La raison de ce travail est de combler le fossé de responsabilité qui existe avec les systèmes d’IA actuels qui sont mis dans la nature pour être utilisés par les consommateurs. Pour plus d’informations, lire les deux documents suivants : ici et ici.
Articles et Blog ✍️
La distillation de modèle en NLP
Dans un podcast de NLP Highlights, Thomas Wolf et Victor Sanh parlent de la distillation de modèles et de la façon dont elle peut être utilisée comme une approche réalisable pour comprimer de grands modèles comme BERT. Ce concept est discuté plus en détail dans la méthode qu’ils proposent, appelée DistilBERT, dans laquelle ils construisent des modèles plus petits (basés sur la même architecture qu’un modèle plus grand) pour essayer d’imiter le comportement du modèle plus grand. En substance, le petit modèle (l’étudiant) essaie de s’adapter à la distribution de probabilité de l’enseignant.
BERT, ELMo, & GPT-2: Dans quelle mesure les représentations contextuelles des mots sont-elles contextualisées ?
On a beaucoup parlé du succès des méthodes contextualisées comme BERT pour aborder une grande variété de tâches complexes de NLP. Dans cet article, Kawin Ethayarajh tente de répondre à la question qui consiste à savoir comment sont contextualisés les mots dans les modèles comme BERT, ELMo et le GPT-2. Les sujets abordés comprennent les mesures de la contextualité, la spécificité du contexte et les comparaisons entre les embeddings statiques et les représentations contextualisées.
Sparsity in Neural Networks
François Lagunas, a écrit cet article Medium pour discuter de son optimisme quant à l’adoption de tenseurs clairsemés dans les modèles de réseaux de neurones. L’espoir est d’utiliser une forme de rareté pour réduire la taille des modèles actuels qui, à un moment donné, deviennent peu pratiques en raison de leur taille et de leur vitesse. Ce concept pourrait être intéressant à explorer en ML en raison de la taille même des modèles actuels comme les Transformers. Cependant, les détails de mise en œuvre ne sont pas aussi clairs du point de vue des outils de développement disponibles, et c’est quelque chose sur lequel la communauté travaille déjà.
Entraîner votre propre modèle linguistique
Si vous souhaitez apprendre à entrainer un modèle de zéro, consultez ce tutoriel d’Hugging Face. Ils utilisent évidemment leurs propres bibliothèques Transformers et Tokenizers pour entraîner le modèle.
Tokenizers: Comment les machines lisent
Cathal Horan a publié un article sur la manière dont les modèles de NLP les plus récents utilisent les tokenizers. Il explique également pourquoi la tokenisation est un domaine de recherche actif, passionnant et important. L’article vous montre même comment entraîner vos propres tokenizers en utilisant des méthodes de tokenisation comme SentencePiece et WordPiece.
Education 🎓
ML à l’université d’Amsterdam
Vous pouvez désormais suivre en ligne le cours d’apprentissage machine 2020 MLVU, qui comprend des diapositives, des vidéos et le programme. Il s’agit d’une introduction au ML, mais il comporte également d’autres sujets liés à l’apprentissage approfondi, tels que les VAE et les GAN.

Ressources mathématiques pour le ML
Suzana Ilić et le Machine Learning Tokyo (MLT) ont fait un travail remarquable en termes de démocratisation de l’éducation au ML. Par exemple, consultez ce répertoire qui présente une collection de ressources en ligne gratuites pour apprendre les fondements des concepts mathématiques utilisés en ML.
Introduction au Deep Learning
Suivez le cours “Introduction to Deep Learning” du MIT sur ce site. De nouveaux cours seront publiés chaque semaine et toutes les diapositives, vidéos et codes seront publiés.
Deep Learning avec PyTorch
Alfredo Canziani a publié les diapositives et les notebooks pour son mini-cours sur l’apprentissage profond avec PyTorch. Le dépôt contient également un site web complémentaire qui comprend des descriptions textuelles des concepts enseignés dans le cours.
Missing Semester of Your CS
Le “Missing Semester of Your CS” est un cours en ligne pouvant être utile aux spécialistes des données ayant une formation autre que celle du développement. Il comprend des sujets tels que les outils shell, les scripts et le contrôle de version. Le cours a été publié par des membres du corps enseignant du MIT.
Deep Learning avancé
La CMU a publié les diapositives et le programme du cours “Advanced Deep Learning” qui comprend des sujets tels que les modèles autorégressifs, les modèles générateurs et l’apprentissage autosurveillé/prédictif. Le cours s’adresse aux étudiants de master ou de doctorat ayant une formation avancée en ML.
Mentions spéciales ⭐️
Xu et ses collaborateurs (2020) ont proposé une méthode pour remplacer et compresser progressivement un modèle BERT en le divisant en ses composantes d’origine. Le modèle proposé surpasse les autres approches de distillation sur le référentiel GLUE.
Le cours “Introduction à l’apprentissage machine” couvre les bases du ML, la régression supervisée, les forêts aléatoires, le tuning des paramètres et bien d’autres sujets fondamentaux du ML.
Le modèle grec de BERT (GreekBERT) est maintenant disponible sur Transformers.
Jeremy Howard publie un article décrivant la librairie fastai. Il s’agit d’une lecture recommandée aux développeurs de logiciels qui travaillent à la création et à l’amélioration des librairies d’apprentissage profond et de ML.
Deeplearning.ai complète la publication des quatre cours de TensorFlow : Data and Deployment Specialization. Cette spécialisation vise principalement à apprendre aux développeurs comment déployer efficacement des modèles dans différents scénarios et utiliser les données de manière intéressante.
Sebastian Raschka a récemment publié un article intitulé “Machine Learning in Python” : Principaux développements et tendances technologiques en matière de science des données, d’apprentissage automatique et d’intelligence artificielle”. Ce document est un examen complet du paysage des outils d’apprentissage machine. Il permet de comprendre les avantages de certaines librairies et les concepts utilisés dans l’ingénierie ML. En outre, un mot sur l’avenir des bibliothèques d’apprentissage machine basées sur Python est fourni.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.