

Avant-propos d’Elvis
Tout d’abord, je ne saurais trop tous vous remercier pour le soutien et les encouragements incroyables que vous avez apportés à cette newsletter. Son élaboration nécessite des recherches et une rédaction fastidieuse que je trouve à la fois enrichissantes et utiles, afin de vous fournir le meilleur contenu. J’espère que vous les appréciez, car c’est le cas pour moi. 😉
Publications 📙
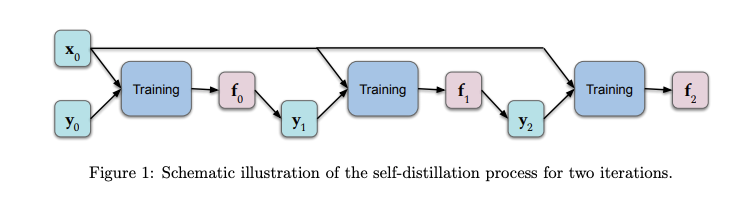
Une compréhension théorique de l’autodistillation
L’autodistillation est le processus de transfert de connaissances d’une architecture à une seconde qui est identique. Les prédictions du modèle original sont transmises comme valeurs cibles au second modèle pendant la phase d’entraînement. Outre les propriétés souhaitables, comme la réduction de la taille du modèle, les résultats empiriques montrent que cette approche fonctionne bien sur des ensembles de données maintenus. Un groupe de chercheurs a récemment publié un article qui fournit une analyse théorique visant à mieux comprendre ce qui se passe dans ce processus et pourquoi il est efficace. Les résultats montrent que quelques cycles d’autodistillation amplifient la régularisation (en limitant progressivement le nombre de fonctions de base qui représentent la solution), ce qui tend à réduire le sur-apprentissage. (Lire l’article complet ici)
Les années 2010 : Une décennie d’apprentissage approfondi / Perspectives pour les années 2020
Jürgen Schmidhuber, un pionnier de l’intelligence artificielle, a récemment publié un article sur son blog qui se concentre sur un aperçu historique de l’apprentissage profond depuis 2010. Parmi les sujets abordés, citons les LSTM, les feedforward NN, les GAN, l’apprentissage par renforcement, le méta-apprentissage, la distillation, l’apprentissage par l’attention, etc. L’article se termine par une perspective sur les années 2020, encourageant l’attention sur des questions urgentes telles que la vie privée et les marchés des données.
Utilisation des réseaux de neurones pour résoudre des équations mathématiques
Les chercheurs du FAIR de Facebook ont publié un article qui propose un modèle entraîné sur des problèmes mathématiques ainsi que leurs solutions associées, afin d’apprendre à prédire les solutions possibles pour des tâches telles que la résolution de problèmes d’intégration. L’approche est basée sur une approche similaire à celle utilisée dans la traduction automatique où les expressions mathématiques sont représentées comme une sorte de langage et les solutions sont traitées comme le problème de traduction. Ainsi, au lieu que le modèle produise une traduction, le résultat est la solution elle-même. Les chercheurs affirment ainsi que les réseaux neuronaux profonds ne sont pas seulement bons pour le raisonnement symbolique, mais aussi pour des tâches plus diverses.
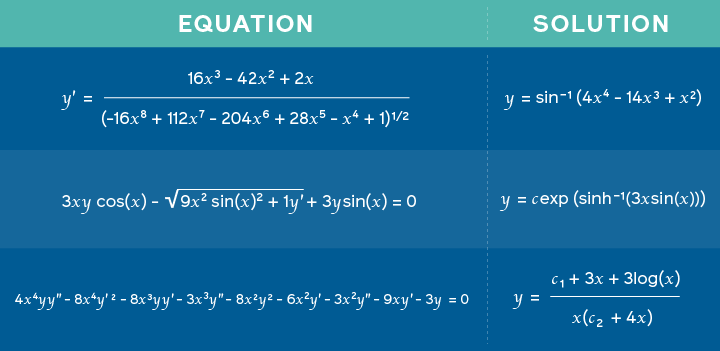
Équations fournies en entrée avec la solution correspondante fournie par le modèle – source
Créativité et société 🎨
L’IA au service de la découverte scientifique
Mattew Hutson rapporte comment l’IA peut être utilisée pour produire des émulateurs qui ont une utilité importante dans la modélisation de phénomènes naturels complexes qui pourraient, à leur tour, conduire à différents types de découvertes scientifiques. Le défi avec la construction de ces émulateurs est qu’ils nécessitent souvent d’importantes données et une exploration approfondie des paramètres. Un article récent propose DENSE, une approche basée sur la recherche d’architecture neurale pour construire des émulateurs précis tout en ne s’appuyant que sur une quantité limitée de données d’entraînement. Ils l’ont testée en effectuant des simulations pour des cas tels que l’astrophysique, la climatologie et la fusion, entre autres.
Améliorer la « traduction » de l’image à l’illustration
GANILLA est une approche qui propose l’utilisation de GAN pour améliorer le transfert à la fois du style et du contenu dans la tâche de traduction d’image à image non appariée. En particulier, un modèle d’illustration d’image à image est proposé (avec un réseau générateur amélioré) et évalué sur la base d’un nouveau cadre d’évaluation quantitative qui prend en compte à la fois le contenu et le style. La nouveauté de ce travail réside dans le réseau générateur proposé qui tient compte d’un équilibre entre le style et le contenu, ce que les modèles précédents n’ont pas réussi à atteindre. Des codes et modèles pré-entrainés sont mis à disposition. Lisez le document complet ici.

Andrew Ng parle de l’intérêt pour l’auto-apprentissage
Andrew Ng, le fondateur de deeplearning.ai, est intervenu dans un podcast sur l’intelligence artificielle pour parler de sujets tels que ses débuts dans le ML, l’avenir de l’IA, l’enseignement de l’IA, ses recommandations pour une bonne utilisation du ML, ses objectifs personnels et les techniques de ML auxquelles il faudra prêter attention dans les années 2020.
Andrew a expliqué pourquoi il est très enthousiaste à l’idée de s’initier à l’auto-apprentissage. L’auto-apprentissage supervisé consiste à formuler un problème d’apprentissage dont le but est d’obtenir une supervision à partir des données elles-mêmes. L’intérêt est d’utiliser de grandes quantités de données non labélisées, ce qui est plus disponibles en plus grande quantité que les données labélisées. Les représentations, par opposition à l’exécution de la tâche, sont importantes et peuvent être utilisées pour traiter des tâches en aval, comme c’est le cas dans les modèles linguistiques tels que le BERT.
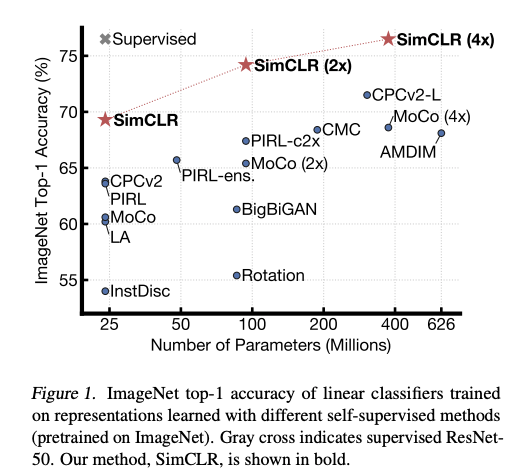
Il y a également beaucoup d’intérêt à utiliser l’auto-apprentissage supervisé](pour apprendre des représentations visuelles généralisées qui rendent les modèles plus précis dans des environnements à faibles ressources. Par exemple, une méthode récente appelée SimCLR (dirigée par Geoffrey Hinton) propose un cadre pour améliorer les résultats de la classification des images dans différents contextes tels que l’apprentissage par transfert et l’apprentissage semi-supervisé.
Outils et jeux de données ⚙️
Les libraries liées à JAX
JAX est une nouvelle bibliothèque qui combine NumPy et la différenciation automatique pour mener des recherches de ML de haut niveau. Afin de simplifier les pipelines utilisant JAX, DeepMind a publié Haiku et RLax. RLax simplifie l’implémentation de modèles basés sur l’apprentissage par renforcement et Haiku simplifie la construction de réseaux neuronaux en utilisant des modèles de programmation orientés objet.
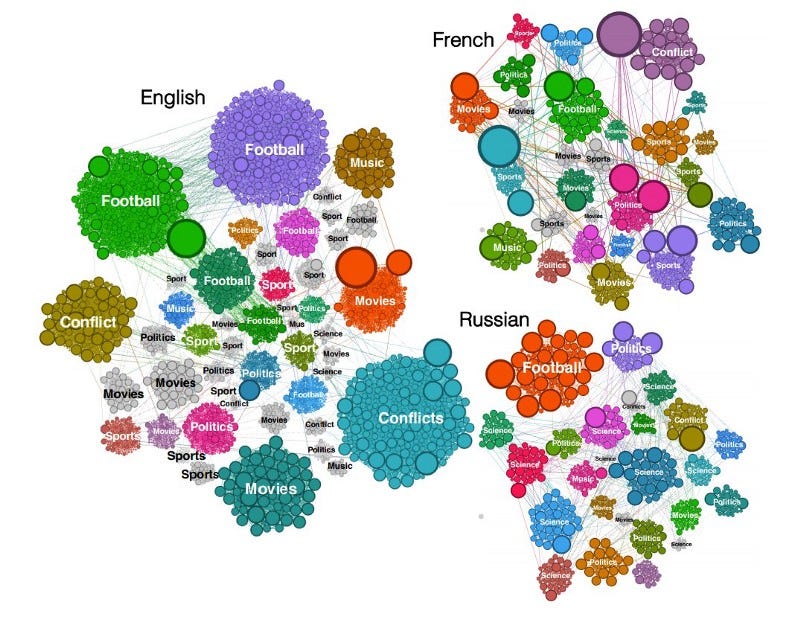
Un outil de traitement des données Wikipédia
Sparkwiki est un outil permettant de traiter les données de Wikipédia. Cette version s’inscrit dans le cadre de nombreux efforts visant à permettre des recherches intéressantes en matière d’analyse comportementale, telles que la capture des tendances et des biais linguistiques dans les différentes éditions linguistiques de Wikipédia. Les auteurs ont découvert qu’indépendamment de la langue, le comportement de navigation des utilisateurs de Wikipédia montre qu’ils ont tendance à partager des intérêts communs comme par exemples les films, la musique et le sport, mais que les différences deviennent plus apparentes avec les événements locaux et les particularités culturelles.
Mise à jour de la librairie Transformers
Une nouvelle version de la librairie Transformers d’Hugging Face est disponible. Elle comprend l’intégration de leur librairie Tokenizer qui vise à accélérer des modèles comme BERT, RoBERTa, GPT2, et d’autres modèles construits par la communauté.
Ethique en IA 🚨
Considérations éthiques pour les modèles de NLP et de ML
Dans un nouvel épisode des NLP Highlights, Emily Bender et les intervenants parlent de certaines considérations éthiques qui peuvent se poser lors du développement de modèles de NLP dans un contexte d’utilisation universitaire et grand public. Parmi les sujets abordés, citons les considérations éthiques lors de la conception des tâches de NLP, les approches de collecte de données et, finalement, la publication des résultats.
En plus de toutes les considérations ci-dessus, une préoccupation qui est toujours discutée dans la communauté de l’IA est de se concentrer trop sur l’optimisation d’une mesure, ce qui va à l’encontre des fondements de ce que l’IA vise à atteindre (càd une IA générale). Rachel Thomas et David Uminsky discutent des erreurs possibles en analysant de manière approfondie différents cas d’utilisation. Ils proposent également un cadre simple pour atténuer le problème, qui implique l’utilisation et la combinaison de plusieurs mesures, suivies par l’implication des personnes directement concernées par la technologie.
Articles et Blog ✍️
Le GPT2 annoté
Aman Arora a récemment publié un article sur son blog, intitulé le “The Annotated GPT-2”, qui explique le fonctionnement interne du GPT-2. Son approche s’inspire de “The Annotated Transformer” qui a adopté une approche d’annotation pour expliquer les parties importantes du modèle par le biais de code et d’explications faciles à suivre. Aman a fait de gros efforts pour réimplémenter le GPT-2 d’OpenAI en utilisant PyTorch et la bibliothèque Transformers de Hugging Face.

Au-delà de BERT ?
Sergi Castella expose son point de vue sur ce qui se trouve au-delà de BERT. Les principaux sujets abordés sont l’amélioration des mesures, la façon dont la librairie Transformers d’HuggingfFace permet de faire des recherches, les jeux de données intéressants à consulter, etc…
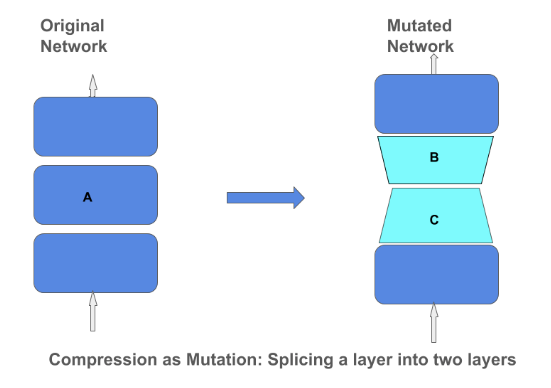
Opérateur de compression matricielle
TensorFlow blog a publié un article expliquant les techniques et l’importance de la compression des matrices dans un modèle de réseau neuronal profond. La compression des matrices peut aider à construire des modèles petits plus efficaces qui peuvent être incorporés dans des appareils tels que les téléphones et les assistants vocaux. En se concentrant sur la compression des modèles par des méthodes telles que la low-rank-approximation et la quantization, nous n’avons pas besoin de compromettre la qualité du modèle.
Education 🎓
Les bases du NLP
Elvis a publié une ébauche du chapitre 1 de sa nouvelle série intitulée “Les bases du NLP”. Il enseigne les concepts du NLP en partant des bases tout en partageant les meilleures pratiques, les références importantes, et les erreurs courantes à éviter. Un Google Colab est disponible et le projet sera maintenu ici.
[Online] Review/Discussion: Part I Mathematical Foundations Reading Session
Machine Learning Tokyo organise une discussion en ligne sur les chapitres qui ont été couverts lors de leurs récentes sessions d’étude en ligne. Le groupe avait auparavant étudié des chapitres basés sur le livre intitulé Mathematics For Machine Learning, écrit par Marc Peter Deisenroth, A Aldo Faisal et Cheng Soon Ong. L’événement est prévu pour le 8 mars 2020.
Recommandations de livres
Dans une partie précédente, nous avons discuté de l’importance de la compression matricielle pour la construction de petits modèles de ML. Si vous souhaitez en savoir plus sur la façon de construire des réseaux neuronaux profonds plus petits pour les systèmes embarqués, consultez cet excellent livre intitulé TinyML, écrit par Pete Warden et Daniel Situnayake.

Un autre livre intéressant à surveiller et qui est à paraître est “Deep Learning for Coders with fastai and PyTorch” : AI Applications Without a PhD” de Jeremy Howard et Sylvain Gugger. Ce livre vise à fournir les bases mathématiques nécessaires pour construire et former des modèles permettant d’aborder des tâches dans les domaines de computer vision et du NLP.

Mentions spéciales ⭐️
Torchmeta est une librairie qui permet d’utiliser facilement des chargeurs de données connexes pour la recherche sur le méta-apprentissage. Elle a été rédigée par Tristan Deleu.
Manuel Tonneau a écrit un article offrant un regard plus approfondi sur certains des mécanismes impliqués dans la modélisation du langage. Parmi les sujets abordés, citons la greedy recherche, la beam recherche et l’échantillonnage de noyaux.
Le MIT publie le programme complet et le calendrier du cours intitulé “Introduction to Deep Learning”. L’objectif est de publier chaque semaine des vidéos et des diapositives.
Apprenez comment entraîner un modèle de reconnaissance d’entités nommées (NER) en utilisant une approche basée sur Transformers en moins de 300 lignes de code. Vous pouvez trouver le programme Google Colab qui l’accompagne ici.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.