

Avant-propos d’Elvis
Bienvenue au sixième numéro de la lettre d’information consacrée au NLP. Merci pour votre soutien et pour avoir pris le temps de lire les dernières nouvelles sur le ML et le NLP. Ce numéro traite de sujets allant de l’extension du modèle Transformer au ralentissement de la publication en ML, en passant par une série de livres et de lancements de projets en ML et en NLP.
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai.
Nous avons traduit la lettre d’information dans d’autres langues telles que le portugais brésilien, le chinois, l’arabe, l’espagnol, entre autres. Merci aux personnes qui ont aidé à la traduction. Vous pouvez également contribuer ici.
Il y a un mois, nous avons officiellement lancé notre nouveau site web. Vous pouvez consulter notre organisation GitHub pour plus d’informations sur dair.ai et ses projets. Si vous souhaitez voir comment d’autres personnes contribuent déjà à dair.ai ou si vous souhaitez contribuer à la démocratisation de la recherche, de l’éducation et des technologies en matière d’intelligence artificielle, consultez notre section sur les questions d’actualité.
Publications 📙
Une introduction à la BERTologie : Ce que nous savons sur le fonctionnement de BERT
Les modèles basés sur le Transformer se sont avérés efficaces pour aborder différents types de tâches de NLP allant de la classification de séquences à la réponse aux questions. L’un de ces modèles, appelé BERT (Devlin et al. 2019), est largement utilisé mais comme d’autres modèles qui utilisent des réseaux de neurones profonds, nous savons très peu de choses sur leur fonctionnement interne. Un nouvel article intitulé “ A Primer in BERTology: What we know about how BERT works “ vise à répondre à certaines des interrogations portant sur les raisons pour lesquelles BERT est performant dans un si grand nombre de tâches de NLP. Parmi les sujets abordés dans cet article, on trouve le type de connaissances acquises par BERT ainsi que leur représentation, la manière dont ces connaissances sont acquises et les autres méthodes utilisées par les chercheurs pour les améliorer.
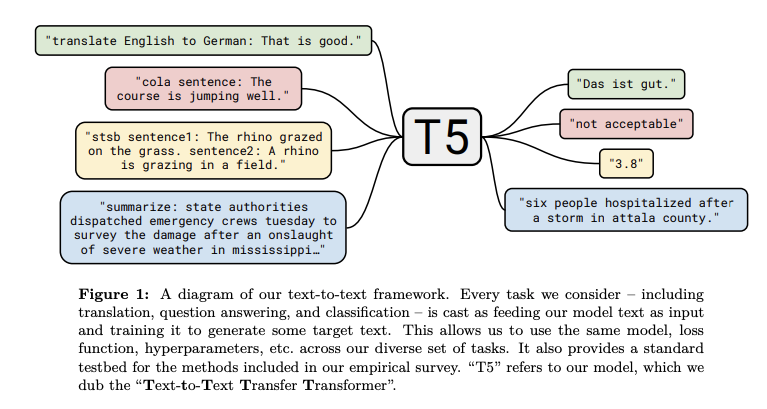
Explorer les limites de l’apprentissage par transfert avec un Transformer de texte à texte
Google AI a récemment publié une méthode qui rassemble tous les enseignements et les améliorations tirés des modèles de NLP basés sur l’apprentissage par transfert. Les auteurs l’ont appelé Text-to-Text Transfer Transformer (T5). Ce travail propose que la plupart des tâches de NLP puissent être formulées dans un format texte-texte, suggérant que les entrées et les sorties sont des textes. Les auteurs affirment que ce “ cadre fournit un objectif d’entraînement cohérent à la fois pour le pré-entraînement et le fine-tuning”.
Le T5 est essentiellement un Transformer encoder-decoder qui applique diverses améliorations, en particulier aux composantes d’attention qui composent le modèle. Le modèle a été pré-entraîné sur un ensemble de données récemment publié, le Colossal Clean Crawled Corpus et a été appliqué sur SOTA sur des tâches de NLP telles que le résumé, la réponse aux questions et la classification de textes.
12 en 1 : Apprentissage multitâche de la représentation de la vision et des langues
La recherche actuelle utilise des tâches et des ensembles de données indépendants pour effectuer des recherches sur la vision et le langage même lorsque les “compétences de compréhension du langage fondées sur la vision” requises pour effectuer ces tâches se chevauchent. Une nouvelle publication (qui sera présentée à la CVPR) propose une approche multitâche à grande échelle pour mieux modéliser et entraîner conjointement les tâches de vision et du langage afin de générer un modèle de vision et de langue plus générique. Le modèle réduit la taille des paramètres et fonctionne bien pour des tâches telles que la recherche d’images basée sur des légendes et la réponse visuelle à des questions.

BERT peut voir à l’extérieur de la boîte : Sur la transférabilité intermodale des représentations textuelles
Les chercheurs et collaborateurs de reciTAL ont publié un article qui vise à répondre à la question de savoir si un modèle BERT peut produire des représentations qui se généralisent à d’autres modalités que le texte, comme par exemple la vision. Ils proposent un modèle appelé BERT-gen qui exploite des représentations mono ou multimodales et qui obtient de meilleurs résultats sur les ensembles de données de génération de questions visuelles.

Créativité et société 🎨
La prochaine décennie en IA : quatre étapes vers une intelligence artificielle robuste
Gary Marcus a récemment publié un article dans lequel il explique une série de mesures que nous devrions prendre selon lui afin de construire des systèmes d’IA plus robustes. L’idée centrale dans ce papier est de se concentrer sur la construction de systèmes hybrides et axés sur la connaissance, guidés par des modèles cognitifs, plutôt que de se concentrer sur la construction de systèmes plus importants qui nécessitent plus de données et de puissance de calcul.
10 technologies de pointe pour 2020
La revue technologique du MIT a publié une liste des 10 percées qu’elle a identifiées et qui feront la différence dans la résolution de problèmes susceptibles de changer notre façon de vivre et de travailler. La liste - sans ordre particulier - comprend l’internet non piratable, la médecine hyper-personnalisée, l’argent numérique, les médicaments anti-âge, les molécules découvertes par l’IA, les méga-constellations de satellites, la suprématie quantique, l’IA minuscule, la confidentialité différentielle et l’attribution du climat.
Il est temps de repenser le processus de publication en ML
Yoshua Bengio a récemment fait part de ses préoccupations concernant les cycles rapides des publications du ML. La principale est qu’en raison de la rapidité de la publication, beaucoup d’articles publiés contiennent des erreurs et sont juste incrémentiels. A contrario, ceux sur lesquels plus de temps est consacré afin d’en assurer la rigueur, semble disparaître. De plus, ce sont les étudiants qui doivent faire face aux conséquences négatives de cette pression et de ce stress. Pour remédier à cette situation, Bengio parle de ses actions pour aider à ralentir le processus de publication des recherches pour le bien de la science.
Outils et jeux de données ⚙️
Mise en œuvre du réseau PointerGenerator dans AllenNLP
Les réseaux « Pointer-Generator » visent à augmenter les modèles d’attention utilisés pour améliorer la synthèse abstraite. Si vous souhaitez utiliser cette technique en utilisant AllenNLP, Kundan Krishna a développé une librairie qui vous permet d’exécuter un modèle pré-entraîné (fourni) ou d’entraîner votre propre modèle.
Questions/réponses pour différentes langues
Avec la prolifération des modèles de Transformer et leur efficacité pour les tâches de NLP, des efforts impressionnants ont été déployés pour publier différents types de jeux de données dans différentes langues. Par exemple, Sebastian Ruder a partagé une liste de jeux de données qui peuvent être utilisés pour des tâches de réponses aux questions dans différentes langues : DuReader, KorQuAD, SberQuAD, FQuAD, Arabic-SQuAD, SQuAD-it et Spanish SQuAD.
PyTorch Lightning
PyTorch Lightning est un outil qui vous permet de réaliser un entraînement abstrait qui nécessiterait l’utilisation de GPU/TPU d’une précision de 16 bits. PyTorch Lightning permet d’entraîner des modèles sur des plusieurs GPU et TPU sans avoir besoin de changer votre code PyTorch actuel.
Graph Neural Networks dans TensorFlow 2
Une équipe de recherche de Microsoft publie une librairie qui donne accès aux implémentations de nombreuses architectures de réseaux neuronaux en graphes (GNN). Cette librairie est basée sur TensorFlow 2 et fournit également des modules de manipulation de données qui peuvent être directement utilisés dans des boucles d’entrainement/évaluation.
Pré-entraînement de SmallBERTa - Un petit modèle pour s’entraîner sur un petit jeu de données
Avez-vous déjà voulu entraîner votre propre modèle linguistique à partir de zéro mais n’avez pas eu assez de ressources pour le faire ? Si c’est le cas, Aditya Malte vous propose un notebook qui vous apprend à entrainer un modèle linguistique à partir de zéro avec un ensemble de données plus restreint.
Ethique en IA 🚨
Pourquoi les visages ne disent pas toujours la vérité sur les sentiments
Depuis un certain temps, de nombreux chercheurs et entreprises ont tenté de construire des modèles d’IA qui comprennent et peuvent reconnaître les émotions dans un contexte textuel ou visuel. Un nouvel article relance le débat sur le fait que les techniques d’IA qui visent à reconnaître les émotions à partir des images de visages ne le font pas correctement. L’argument principal, soulevé par des psychologues, est qu’il n’existe aucune preuve d’expressions universelles pouvant être utilisées pour la détection d’émotions basées uniquement sur des images de visages. Il faudrait qu’un modèle comprenne mieux par exemple les traits de personnalité ou encore les mouvements du corps, afin de se rapprocher réellement d’une détection plus précise des émotions affichées par les humains.
Differential Privacy and Federated Learning Explained
L’une des considérations éthiques à prendre en compte lors de la construction de systèmes d’IA est la garantie du respect de la vie privée. Actuellement, cela peut être réalisé de deux manières, soit en utilisant une intimité différentielle, soit par un apprentissage fédéré. Si vous voulez en savoir plus sur ces sujets, Jordan Harrod nous fournit une excellente introduction dans cette vidéo qui comprend également une session de pratique avec l’utilisation d’un notebook.
Articles et Blog ✍️
Plongée dans le Reformer
Madison May a écrit un nouvel article sur son blog consacré au Reformer, proposé par Google AI. Nous avons également présenté le Reformer dans un précédent numéro de la newsletter. Pour une explication en français, vous pouvez consulter l’illustration suivante.
Une plateforme de blogging gratuite
fastpages vous permet de créer automatiquement et gratuitement un blog en utilisant les pages GitHub. Cette solution simplifie le processus de publication d’un blog et prend également en charge l’utilisation de documents Word et de notebook Jupyter.
Conseils pour un entretien chez Google
Pablo Castro, de l’équipe Google Brain, a publié un article sur son blog mettant en avant une liste de conseils pour les personnes intéressées par un entretien d’embauche chez Google. Parmi les sujets abordés figurent des conseils sur la façon de se préparer à l’entretien, sur ce à quoi il faut s’attendre pendant l’entretien et sur ce qui se passe après l’entretien.
Les Transformers sont des Graph Neural Networks
Les réseaux neuronaux de graphes (GNN) et les Transformers se sont avérés efficaces pour différentes tâches de NLP. Pour mieux comprendre le fonctionnement interne de ces approches et leurs relations, Chaitanya Joshi a écrit un article expliquant la connexion entre les GNN et les Transformers, ainsi que les différentes façons dont ces méthodes peuvent être combinées dans une sorte de modèle hybride.
CNNs et Equivariance
Fabian Fuchs et Ed Wagstaff discutent de l’importance de l’équivariance et de la manière dont les CNN la font respecter. Le concept d’équivariance est d’abord défini, puis discuté dans le contexte de CNN appliqués à la traduction.
L’auto-apprentissage avec les images
L’auto-apprentissage a été beaucoup évoqué dans les précédents numéros de la newsletter en raison du rôle qu’il a joué dans les techniques modernes de modélisation des langues. Ce billet de Jonathan Whitaker fournit une explication de l’auto-apprentissage dans le contexte des images. Si le sujet vous intéresse, Amit Chaudhary a également écrit un article décrivant le concept de manière visuelle.
Education 🎓
Stanford CS330: Deep Multi-Task et Meta-Learning
Stanford a récemment publié une playlist vidéo YouTube sur son nouveau cours consacré à l’apprentissage multi-tâches et au méta-apprentissage. Parmi les sujets abordés, citons le méta-apprentissage bayésien, le lifelong apprentissage, une introduction à l’apprentissage par renforcement, etc…
Notebooks PyTorch
dair.ai publie une série de notebook qui visent à vous faire découvrir les réseaux neuronaux profonds à l’aide de PyTorch. Il s’agit d’un travail en cours et certains sujets d’actualité comprennent la façon de mettre en œuvre un modèle de régression logistique à partir de zéro et la façon de programmer un NN ou un RNN à partir de zéro. Les notebooks sont également disponibles dans le dépôt GitHub.
Le livre de fastai book (ébauche)
Jeremy Howard et Sylvain Gugger ont publié une liste complète de notebooks (non terminés) en vue de leur prochain cours qui présentera des concepts de deep learning et différentes méthodes d’utilisation de PyTorch et la librairie fastai.
Cours gratuits sur la datascience
Au cas où vous l’auriez manqué, Kaggle propose une série de petits cours gratuits sur les outils de datascience. Certains de ces cours comprennent, entre autres, l’explication de l’apprentissage machine, une introduction à l’apprentissage machine et à Python, la visualisation de données, l’ingénierie des fonctionnalités et l’apprentissage approfondi.
Un autre cours de datascience en ligne propose un programme, des diapositives et des notebooks sur l’analyse exploratoire des données, l’interprétation des modèles ou encore le NLP.
8 créateurs et contributeurs parlent de leurs librairies PyTorch
nepture.ai a publié un vaste article qui contient des discussions détaillées avec les principaux créateurs et contributeurs de PyTorch (parcours, philosophie du projet, outils qui l’entourent, etc…).
Visualisation des modèles adaptatifs d’attention réduite
Sasha Rush partage un notebook qui explique et montre les détails techniques sur la manière de produire des sorties softmax sparses. Il aborde également la façon d’induire la sparcité dans la composante d’attention d’un modèle de Transformer, ce qui aide à produire une probabilité nulle pour les mots non pertinents dans un contexte donné, améliorant ainsi la performance et l’interprétabilité.
Mentions spéciales ⭐️
Conor Bell a codé un script python qui vous permet de visualiser et de préparer facilement un jeu de données pouvant être utilisé pour un modèle StyleGAN.
Manu Romero a contribué au fine-tuning d’un modèle POS pour l’espagnol. Le modèle est sur la librairie Transfomers d’Hugging Face. Il sera intéressant de voir cet effort dans d’autres langues.
Ce répertoire Github contient une longue liste de documents rédigés sur BERT qui abordent différents problèmes tels que la compression de modèles, les domaines spécifiques, le multi-modèle, la génération, les tâches en aval, etc.
Connor Shorten a publié une courte vidéo de 15 minutes expliquant un framework à aborder pour réduire l’effet des “raccourcis” dans l’auto-apprentissage de la représentation. C’est important car, s’il n’est pas bien fait, le modèle peut ne pas apprendre des représentations sémantiques utiles et se révéler potentiellement inefficace dans un contexte d’apprentissage par transfert.
Sebastian Ruder a publié un nouveau numéro de sa newsletter qui met en lumière des sujets et des ressources allant d’analyses d’articles sur le NLP et le ML de 2019 à des diapositives sur l’apprentissage par transfert et des éléments essentiels sur le deep learning. Vous pouvez le consulter ici.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.