

Avant-propos d’Elvis
Bienvenue au 9ème numéro de la lettre d’information consacrée au NLP. Nous espérons que vous et vos proches allez bien et que vous êtes en sécurité.
Avant d’entrer dans le vis du sujets, voici quelques mises à jour de dair.ai qui ont été effectuées :
-
Appel à contributions pour l’Open science De nombreuses collaborations intéressantes sont en cours et nous souhaitons inviter tous ceux qui sont intéressés à contribuer à l’Open science. Nous recherchons des bénévoles, des écrivains, des réviseurs, des éditeurs, des développeurs, des conférenciers, des chercheurs, des responsables de projets ,… Rejoignez-nous !
-
NLP Research Highlights Issue #1 au cas où vous l’auriez manqué, nous exposons dans cet article, une sélection d’articles intéressants et importants de NLP publiés au cours des derniers mois que nous résumons.
Publications 📙
Neuroévolution des agents auto-interprétables
Tang et al. (2020) présentent un travail qui vise à faire évoluer un agent pour qu’il utilise une fraction de son apport visuel dans le but de survivre à une tâche. Par exemple, éviter de s’écraser dans un virage ou d’esquiver les boules de feu, comme le montre la figure ci-dessous. En utilisant la neuroevolution pour entraîner des architectures d’auto-attention, les auteurs ont pu entraîner des agents à effectuer différentes tâches tout en ne permettant qu’une fraction de l’entrée. Les avantages du modèle sont une réduction substantielle de la taille des paramètres, la possibilité d’interpréter les politiques et le fait de permettre au modèle de ne tenir compte que des indices visuels essentiels à la tâche.

RONEC : Romanian Named Entity Corpus
RONEC est un corpus d’entités nommées pour la langue roumaine qui contient plus de 26 000 entités dans environ 5 000 phrases annotées et appartenant à 16 classes distinctes. Les phrases ont été extraites d’un journal libre de droits d’auteur, couvrant plusieurs styles. Ce corpus représente la première initiative dans l’espace linguistique roumain spécifiquement ciblée pour la reconnaissance des entités nommées. Il est disponible aux formats BIO et CoNLL-U Plus, et il est libre d’utilisation et d’extension ici.
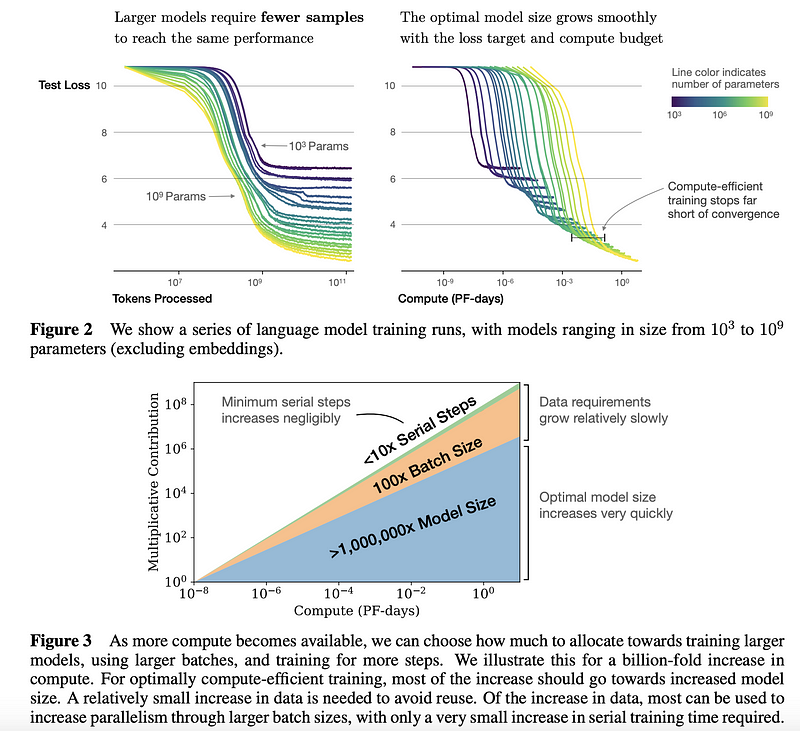
Lois de mise à l’échelle des performances des modèles linguistiques
Des chercheurs de John Hopkins et d’OpenAI ont mené une étude empirique pour comprendre les lois de mise à l’échelle des performances des modèles linguistiques. Ce type d’étude peut être utilisé comme un guide pour prendre de meilleures décisions sur la façon d’utiliser plus efficacement les ressources. Dans l’ensemble, il a été constaté que les grands modèles sont nettement plus efficaces en termes d’échantillonnage. Si les calculs et les données sont limités, il est préférable d’entraîner un grand modèle en quelques étapes plutôt que d’entraîner un modèle plus petit jusqu’à ce qu’il converge (voir les résultats résumés dans la figure ci-dessous). Les auteurs fournissent davantage de conclusions et de recommandations lorsqu’il s’agit d’entraîner de grands modèles linguistiques (par exemple, les Transformers) sur les aspects du sur-apprentissage, du choix de la taille optimale des batch, du fine-tunning, etc…
Calibration des transformers pré-entraînés
Les transformers pré-entraînés étant de plus en plus utilisés dans des applications du monde réel, il est important de comprendre à quel point leurs résultats sont “fiables”. Des travaux récents de l’UT Austin montrent que les probabilités postérieures de BERT et de RoBERTa sont relativement calibrées (c’est-à-dire conformes aux résultats empiriques) pour trois tâches : inférence en langage naturel, détection de paraphrase, raisonnement de bon sens. Ces résultats sont obtenus avec des ensembles de données à la fois dans le domaine et hors domaine. Les résultats montrent : (1) lorsqu’ils sont utilisés, les modèles pré- entraînés sont calibrés dans le domaine ; et (2) la mise à l’échelle de la température est efficace pour réduire davantage l’erreur de calibrage dans le domaine, tandis que le lissage des labels pour augmenter l’incertitude empirique aide à calibrer les données postérieures hors du domaine.
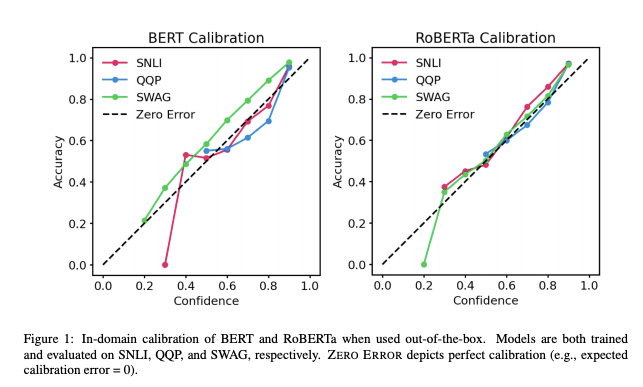 Desai and Durrett (2020)
Desai and Durrett (2020)
Les mécaniques statistiques de l’apprentissage profond
Un récent article examine de plus près le lien entre les sujets physiques/mathématiques et l’apprentissage approfondi. Les auteurs ont pour objectif de discuter de sujets qui recoupent la mécanique statistique et l’apprentissage machine, afin de répondre aux questions qui aident à comprendre le côté théorique des réseaux neuronaux profonds et les raisons de leur succès.
Vers un ImageNet pour le Speech-to-Text
Dans un nouvel article publié dans The Gradient, Alexander Veysov explique pourquoi ils pensent que la bascule semblable à ce que ImageNet a été pour la vision par ordinateur est arrivée pour le Speech-to-Text (STT) en langue russe. Ces dernières années, les chercheurs ont également fait cette affirmation à propos du NLP. Cependant, pour parvenir à un tel moment de STT, Alexander affirme que de nombreuses pièces doivent être réunies, comme la mise à disposition de modèles à grande échelle, la minimisation des besoins de calcul et l’amélioration de l’accessibilité des grands modèles pré-entraînés.
Créativité, éthique et société 🌎
Recherche d’articles liés au COVID-19
La semaine dernière, nous avons présenté un jeu de données public appelé CORD-19 qui contient des documents relatifs au COVID-19.
Gabriele Sarti a codé un outil interactif qui vous permet de rechercher et de parcourir plus efficacement les articles liés au COVID-19 en utilisant un modèle fine-tuné de SciBERT.
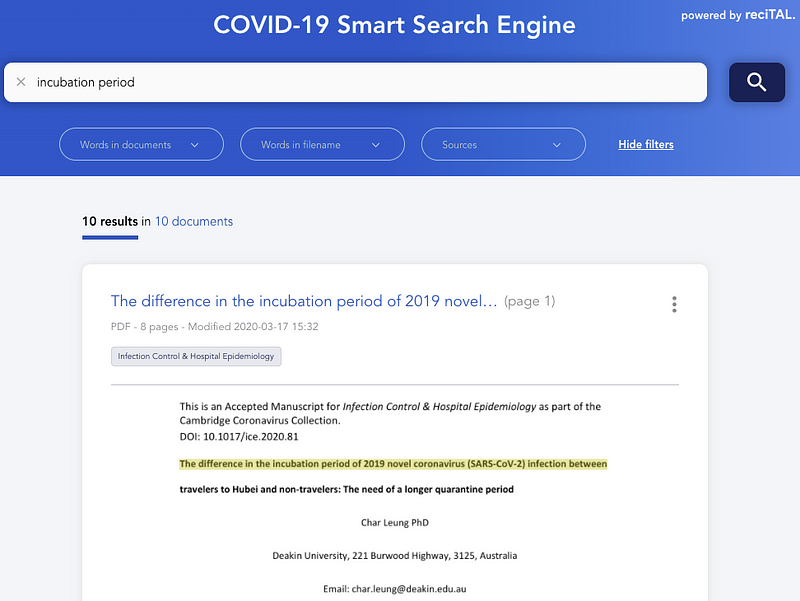
reciTAL a également lancé un projet appelé COVID-19 Smart Search Engine afin d’améliorer la recherche et la navigation sur les articles liés au COVID-19. Le but étant d’aider les chercheurs et les professionnels de la santé à trouver et à découvrir rapidement et efficacement les informations relatives au COVID-19.
SyferText
OpenMined a dévoilé SyferText, une nouvelle librairie qui vise à permettre une utilisation sécurisée et privée du NLP. Elle en est à ses débuts, mais nous pensons qu’il s’agit d’un effort très important vers des systèmes d’IA plus sûrs et éthiques. Voici quelques tutoriels pour commencer.
David contre Goliath : vers des modèles plus petits pour un NLP moins gourmand, plus rapide et plus écologique
Plus c’est gros, mieux c’est ? Lorsque l’on examine l’évolution de la taille des modèles linguistiques au cours des dernières années, on peut penser que la réponse est oui. Pourtant, le coût financier et environnemental de l’entraînement de tels modèles est très élevé. En outre, plus grand dans ce cas signifie généralement plus lent, mais la vitesse est essentielle dans la plupart des applications. C’est ce qui motive la tendance actuelle en NLP à promouvoir des modèles plus petits, plus rapides et plus écologiques tout en préservant les performances. Dans ce billet, Manuel Tonneau présente cette nouvelle tendance en faveur de modèles plus petits en se concentrant sur trois modèles récents et populaires, DistilBERT de Hugging Face, PD-BERT de Google et BERT-of-Theseus de Microsoft.
Une enquête sur l’apprentissage approfondi pour la découverte scientifique
De nombreuses grandes entreprises qui ont aujourd’hui concentré leurs efforts sur la recherche en IA estiment que l’apprentissage approfondi peut être utilisé comme un outil de découverte scientifique. Ce document donne un aperçu complet des modèles d’apprentissage approfondi couramment utilisés pour différents cas d’utilisation scientifique. Le document présente également des conseils de mise en œuvre, des tutoriels, d’autres résumés de recherche et des outils.
Outils et jeux de données ⚙️
TextVQA et TextCaps
Afin d’encourager la construction de modèles capables de mieux détecter et lire le texte compris dans des images, ainsi que d’améliorer le raisonnement pour répondre à des questions et générer des légendes, Facebook AI organise deux concours distincts. Les concours s’appellent TextVQA Challenge et TextCaps Challenge. Ils portent respectivement sur les tâches de réponse visuelle aux questions et sur la génération de légendes.
KeraStroke
L’un des plus grands obstacles à surmonter lors de la conception de réseaux neuronaux est le sur-apprentissage. Les techniques actuelles telles que le dropout, la régularisation et l’arrêt anticipé sont très efficaces dans la plupart des cas d’utilisation, mais elles peuvent avoir tendance à ne pas être à la hauteur lorsqu’on utilise de grands modèles ou de petits ensembles de données. En réponse à cela, Charles Averill a développé KeraStroke, une nouvelle suite de techniques d’amélioration de la généralisation utile pour les grands modèles ou les petits ensembles de données. En modifiant les valeurs de poids dans certains cas pendant l’entraînement, les modèles s’adaptent dynamiquement aux données d’entraînement qui leur sont fournies.
torchlayers
torchlayers est un nouvel outil construit sur PyTorch qui permet l’inférence automatique de la forme et de la dimension des couches disponibles dans le module torch.nn comme les couches convolutionnelles, récurrentes, de transformateur, etc. Cela signifie que vous n’avez pas besoin de définir explicitement la forme des caractéristiques d’entrée qui doivent être spécifiées manuellement dans les couches. Cela simplifie la définition d’un modèle dans PyTorch. Voir ci-dessous un exemple de classificateur de base implémenté avec les couches torche :

Nous pouvons voir, à partir de l’extrait de code, que la couche linéaire ne requiert que la taille des caractéristiques de sortie, par opposition à la taille de sortie et d’entrée. Ceci est déduit par les couches de torche en fonction de la taille d’entrée.
Haystack
Haystack vous permet d’utiliser des modèles de transformer pour répondre aux questions. Il utilise un Retriever-Reader-Pipeline, où le Retriever est un algorithme rapide pour trouver les documents candidats et le Reader est un transformer qui extrait la réponse granulaire. Il s’appuie sur Transformers d’Hugging Face et sur Elasticsearch. C’est un logiciel libre, très modulaire et facile à étendre.
Enseigner à une IA à résumer les articles de presse : un nouveau jeu de données pour le résumé abstrait
Curation Corp est une entreprise de libre accès qui fournit 40 000 résumés d’articles rédigés par des professionnels. Cet article constitue une belle introduction à la synthèse de textes et aux défis que pose cette tâche particulière. En outre, il présente l’ensemble de données, les problèmes qui peuvent être résolus avec celui-ci, des mesures d’évaluation pour la synthèse de texte, et se termine par une discussion pour le travail futur. Les instructions pour accéder à l’ensemble de données se trouvent dans ce dépôt Github, ainsi que des exemples d’utilisation de l’ensemble de données pour le réglage fin.
En ce qui concerne la synthèse des textes, l’équipe de HuggingFace a ajouté BART et T5 à sa librairie Transformers. Ces ajouts permettent d’effectuer toutes sortes de tâches, telles que le résumé abstrait, la traduction et les questions-réponses…
J’ai voulu utiliser la pipeline de traduction du T5 pour effectuer la traduction de cette newsletter. L’éxécution est plutôt lente et la qualité pas forcément au rendez-vous. Je suppose que cela viens du fait que la newsletter utilise un vocabulaire bien spécifique (mathématiques, NLP, etc…). Il faudrait effectuer des tests sur des corpus moins spécialisés. La traduction manuelle a encore quelques beaux jours 😉
Articles et Blog ✍️
Un guide illustré des réseaux neuronaux graphiques (GNN)
Les réseaux neuronaux graphiques ont récemment été adoptés pour des tâches telles que l’amélioration des modèles de vision par ordinateur et la prévision des effets secondaires dus aux interactions médicamenteuses. Dans cet aperçu, Rish présente un guide intuitif et illustré sur les réseaux de neurones graphiques. (Disponible sur dair.ai)
Finetuning avec JAX + Haiku
Le mois dernier encore, DeepMind a dévoilé Haiku, la version JAX de sa librairie Sonnet. Ce post présente un modèle RoBERTa pré-entraîné à JAX + Haiku, puis montre le finetuning du modèle pour résoudre une tâche en aval. Il se veut un guide pratique pour l’utilisation des utilitaires exposés par Haiku pour permettre l’utilisation de “modules” légers orientés objet dans le contexte des contraintes de programmation fonctionnelle de JAX.
Un petit voyage dans la vallée du traitement du langage naturel et du prétraitement de texte pour la langue allemande
Flávio Clésio a écrit un article très détaillé sur les défis que représente le traitement des problèmes de NLP en langue allemande. Il partage de nombreuses leçons apprises, ce qui a fonctionné et ce qui n’a pas fonctionné, discute de plusieurs méthodes de pointe, des problèmes communs à éviter, et d’une tonne de ressources d’apprentissage, de documents et de billets de blog.
PIAF
L’équipe de PIAF (Pour une IA Francophone, For a French Speaking AI) a récemment publié un article en anglais abordant leur projet d’une base de questions-réponses en français ainsi que la place de la francophonie dans le NLP. Il s’agit en réalité de la traduction d’un de leurs post datant de janvier que vous pouvez consulter en français ici.
Un classificateur personnalisé en plus du modèle de langage de type BERT
Marcin a écrit un nouveau guide montrant comment construire son propre classificateur (par exemple, le classificateur de sentiments) sur des modèles de langage de type BERT. Il montre également comment utiliser d’autres librairies modernes pour les différentes parties du modèle, telles que HuggingFace Tokenizer et PyTorchLightning. Vous trouverez le notebook Colab ici.
Education 🎓
Analyse exploratoire des données textuelles
Dans ce code, Yonathan Hadar passe en revue plusieurs méthodes d’analyse exploratoire de données textuelles avec divers exemples de codes. Nous avons présenté ce tutoriel sur le site dair.ai car il s’agit d’un tutoriel très complet qui utilise des méthodes standard d’analyse de données que tout spécialiste des données trouvera utiles. C’est un bon point de départ pour quiconque commence à jouer avec des données textuelles.
Embeddings in Natural Language Processing
Mohammad Taher Pilehvar et Jose Camacho-Collados ont publié la première ébauche d’un prochain livre intitulé “Embeddings in Natural Language Processing”. L’idée de ce livre est de discuter du concept d’embedding qui représente certaines des techniques les plus utilisées en NLP. Comme indiqué par les auteurs, le livre comprend “les bases des modèles d’espace vectoriel et du word embedding dans des phrases plus récentes et des techniques d’embedding contextualisée basées sur des modèles de langage pré-entraînés”.
A Brief Guide to Artificial Intelligence
Le Dr James V Stone a récemment publié son nouveau livre intitulé “A Brief Guide to Artificial Intelligence”, dont l’objectif est de fournir une vue d’ensemble des systèmes d’intelligence artificielle actuels et de leur capacité à accomplir une série de tâches. Comme indiqué dans le résumé, le livre est “écrit dans un style informel, avec un glossaire complet et une liste de lectures complémentaires, ce qui en fait une introduction idéale au domaine en rapide évolution de l’IA”.

Cours de ML et de DL
Sebastian Raschka a publié deux épisodes de son cours sur “Introduction to Deep Learning and Generative Models Vous pouvez trouver des notes de cours et d’autres documents dans ce repertoire.
Voici un autre ensemble de conférences sur le thème de la “géométrie différentielle discrète”.
Peter Bloem a publié les ressources (comprenant des vidéos et des diapositives) pour son cours d’introduction à l’apprentissage automatique dispensé à l’université d’Amsterdam. Les sujets abordés vont des modèles linéaires et de la recherche aux modèles probabilistes en passant par les modèles pour les données séquentielles.
CNN Architecture — Implementations
Dimitris Katsios fournit un ensemble de tutoriels qui donnent des conseils sur la façon de mettre en œuvre des architectures de réseaux neuronaux convolutifs (CNN) à partir d’articles originaux. Il propose une recette sur la façon de les mettre en œuvre tout en partageant les étapes qui comprennent des diagrammes et du code avec la possibilité de déduire la structure du modèle.
Mentions spéciales ⭐️
Il y a quelques mois, nous avons présenté le livre de Luis Serrano sur le ML de Grokking. Ici vous pouvez entendre Luis parler un peu plus de son livre et de son parcours.
Voici plusieurs newsletters qui pourraient mériter votre attention : Sebastian Ruder’s NLP News, Made With ML, SIGTYP’s newsletter, MLT Newsletter, Nathan’s AI newsletter, etc…
Jupyter est désormais doté d’un débogueur visuel 😊
Abhishek Thakur possède une chaîne YouTube où il se promène à travers le code pour montrer comment utiliser les méthodes modernes d’apprentissage automatique et de NLP.
David Silver, professeur et chercheur renommé en matière d’apprentissage par renfocement, a reçu le prix ACM de l’informatique pour ses avancées dans le domaine des jeux vidéo. Silver a dirigé l’équipe Alpha Go qui a battu Lee Sedol au Go.
Pour ceux qui souhaitent connaître les différences et le fonctionnement interne des méthodes populaires de NLP telles que BERT et word2vec, Mohd fournit un excellent aperçu, accessible et détaillé de ces approches.
TensorFlow 2.2.0-rc-1 a été publié. Il comprend des fonctionnalités telles qu’un profileur qui aide à repérer les goulots d’étranglement dans vos modèles de ML et à guider l’optimisation de ces modèles. De plus, Colab utilise désormais TensorFlow 2 par défaut.
Enfin, Gabriel Peyré fournit un ensemble de notes pour son cours sur l’optimisation du ML. Les notes incluent l’analyse convexe, le SGD, les MLP, etc…
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.e mail.