

Avant-propos d’Elvis
Bienvenue au dizième numéro de la lettre d’information consacrée au NLP. Nous espérons que vous allez bien et que vous êtes en sécurité. Dans ce numéro, nous abordons des sujets qui vont des meilleures pratiques concernant les modèles de langue à la reproductibilité dans l’apprentissage automatique, en passant par le respect de la vie privée et la sécurité dans le traitement du langage naturel (NLP).
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai :
-
afin de faciliter l’exploration du jeu de données COVID-19 et afin d’obtenir des informations à partir de la littérature scientifique, nous avons publié un notebook qui retrace les étapes de la conception d’une application permettant de réaliser une recherche de similitude de texte à l’aide d’outils libres et de modèles linguistiques pré-entrainés en open-source.
-
nous avons organisé une formation virtuelle lors de la Open Data Science Conference la semaine dernière sur le thème “Deep Learning for Modern NLP”.
-
la semaine dernière, nous avons aussi publié deux articles en collaboration avec des membres de notre communauté. L’un d’entre eux concerne l’apprentissage progressif non supervisé, un problème qui implique un agent qui analyse une séquence de vecteurs de données non labellisées (flux de données) et en apprend des représentations. Le second article résume une approche de classification des intentions de citation utilisant ELMo.
-
Enfin nous avons récemment publié un notebook qui fournit des idées sur la manière de fine-tuner des modèles de langage pré-entrainés pour la tâche de classification des émotions.
Publications 📙
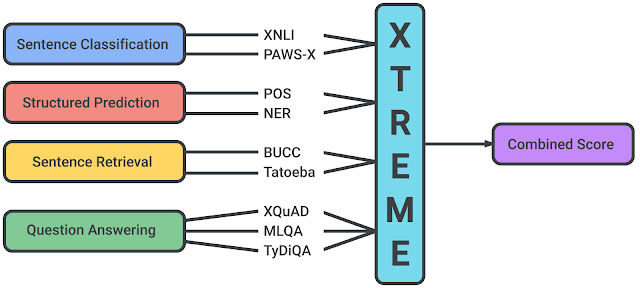
XTREME : Un benchmark multitâche multilingue pour l’évaluation de la généralisation interlinguistique
En début de semaine, des chercheurs de Google AI et DeepMind ont publié un benchmark multitâche appelé XTREME qui vise à encourager l’évaluation des capacités de généralisation multilingue des modèles linguistiques qui apprennent des représentations multilingues. Le benchmark porte sur 40 langues et 9 tâches différentes qui, collectivement, nécessitent de raisonner sur différents niveaux de signification, soit syntaxiquement, soit sémantiquement. Le document fournit également des résultats de référence en utilisant des modèles multilingues tels que mBERT, XLM et MMTE.
Source: Google AI Blog
Evaluer les machines par leur utilisation réelle de la langue
Il a été démontré que les modèles linguistiques sont relativement performants pour une variété de tâches telles que la réponse à des questions et l’étiquetage de séquences. Toutefois, un nouveau document propose un framework et un benchmark pour mieux évaluer si les modèles linguistiques peuvent fonctionner dans le monde réel avec des paramètres plus complexes (par exemple, en générant des conseils utiles pour des situations courantes). Les résultats empiriques montrent que les modèles actuels de pointe tels que le T5 génèrent des conseils aussi utiles que ceux écrits par l’homme que dans 9 % des cas. Ces résultats soulignent les lacunes des LM dans la capacité à comprendre et à modéliser la connaissance du monde et le raisonnement.
Donnez un peu d’amour à vos modèles textuels : le cas du basque
L’entraînement de modèles monolingues (FastText word embeddings et BERT) sur de grands ensembles de données spécifiques à une langue peut-il produire de meilleurs résultats que les versions multilingues préformées ? Dans un récent article, des chercheurs étudient l’effet et la performance de modèles pertinents utilisant des corpus basques plus importants. Les résultats indiquent qu’en effet, le modèle produit de meilleurs résultats sur les tâches telles que la classification des sujets, la classification des sentiments et le PoS pour le basque. Il pourrait être intéressant de vérifier si cela vaut pour d’autres langues et si des résultats intéressants ou de nouveaux défis pourraient se présenter.
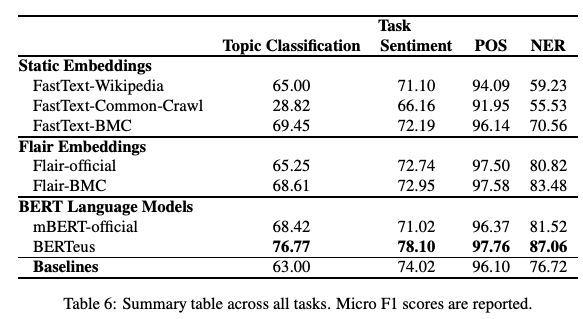
Figure par Agerri et al. (2020)
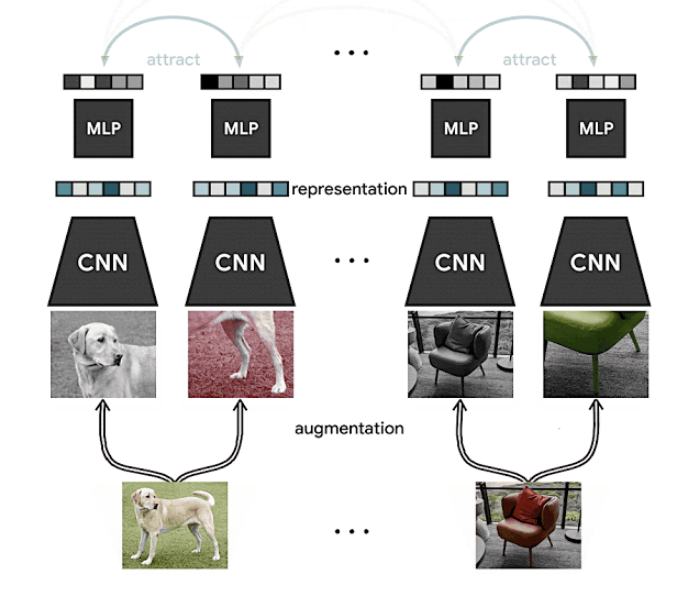
Faire progresser l’apprentissage auto-supervisé et semi-supervisé avec SimCLR
Dans un précédent numéro de la newsletter, nous avons présenté SimCLR, une méthode de Google AI qui propose un cadre pour l’apprentissage contrastif et aut-osurpervisé des représentations visuelles afin d’améliorer les résultats de la classification des images dans différents contextes tels que l’apprentissage par transfert et l’apprentissage semi-supervisé. Il s’agit d’une nouvelle approche de l’apprentissage auto et semi-supervisé pour apprendre des représentations visuelles à partir de données non labellisées. Les résultats démontrent qu’elle obtient des résultats de pointe sur ImageNet tout en ne s’appuyant que sur 1% de données labelissées, ce qui indique que la méthode pourrait également être bénéfique dans des environnements à faibles ressources.
Source: Google AI Blog
Il convient de mentionner que l’apprentissage auto-supervisé est l’un des sujets brûlants dans ce domaine. Si vous souhaitez en savoir plus, vous pouvez consulter les informations suivantes:
- Computers Already Learn From Us. But Can They Teach Themselves?
- The Illustrated Self-Supervised Learning
- Self-supervised learning and computer vision
Le Byte Pair Encoding est sous-optimal pour le pré-entraînement de modèles de langue
Kaj Bostrom et Greg Durrett ont publié un article dans lequel ils ont proposé une évaluation directe de l’impact de la tokenisation sur les performances des modèles linguistiques. Selon les auteurs, cette question est rarement examinée comme on le constate dans la littérature. Pour y parvenir, ils pré-entraînent les modèles à partir de zéro en utilisant des expériences contrôlées et appliquent différentes méthodes de tokenization, à savoir l’unigramme et le BPE. Ensuite, ils testent les modèles résultants sur plusieurs tâches. Les résultats montrent que la tokenization unigramme égale ou surpasse le BPE commun.
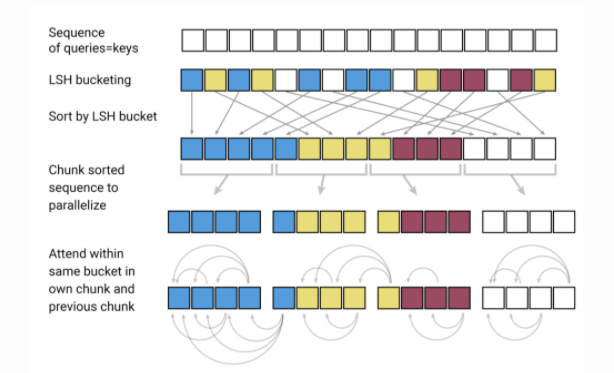
Longformer: Le Long-Document Transformer
Les chercheurs d’Allen AI ont publié un nouveau modèle appelé Longformer qui vise à être plus efficace sur des textes plus longs. Il est bien connu que l’une des limites des modèles basés sur les Transformers est qu’ils sont coûteux en termes de calcul en raison de l’échelle de l’opération d’auto-attention (quadratique avec la longueur de la séquence), ce qui limite la capacité à traiter des séquences plus longues. Récemment, de nombreux efforts ont été déployés, tels que les modèles Reformer et Sparse Transformers, pour permettre l’application de Transformers à de longs documents. Le Longformer combine la modélisation au niveau du caractère et l’auto-attention (mélange d’attention locale et globale) pour consommer moins de mémoire et améliorer l’efficacité de la modélisation des documents longs. Les auteurs montrent également que leur modèle pré-entraîné est plus performant que d’autres méthodes lorsqu’il est appliqué à des tâches comme les questions/réponses et la classification des textes.
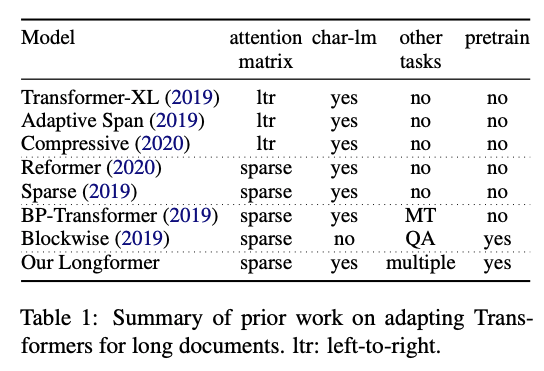
Figure par Beltagy et al. (2020)
Créativité, éthique et société 🌎
Reproductibilité en ML
-
Afin d’encourager une science plus ouverte, plus transparente et plus accessible, de nombreux efforts ont été déployés autour de la reproductibilité. Si vous voulez comprendre où se situe le domaine de l’apprentissage machine en termes de reproductibilité, consultez cette publication de Joelle Pineau et al.
-
Plus récemment, et inspirée par ces efforts, l’équipe Papers With Code (qui fait maintenant partie de Facebook AI) a publié un article de blog expliquant une liste de contrôle de la reproductibilité utile pour “faciliter la recherche reproductible présentée lors des grandes conférences sur le ML”. La liste de contrôle évalue la soumission des codes sur les points suivants :

Source: Papiers avec code
- Sur ce même thème, voici un tweet d’un chercheur en NLP offrant une prime à la personne qui sera capable de reproduire les résultats d’un article qu’un autre chercheur ne parvient pas à reproduire.
Protection de la vie privée et sécurité en NLP
Un modèle de langage pré-entraîné peut-il être volé ou impose-t-il des implications en matière de sécurité lorsqu’il est exposé pour être utilisé via des API ? Dans un nouvel article, les chercheurs visent à tester les API basées sur BERT pour en déterminer les implications en matière de sécurité, notamment en ce qui concerne l’utilisation de requêtes pour voler le modèle. En résumé, ils ont constaté qu’un adversaire peut voler un modèle fine-tuné en se contentant d’alimenter des séquences de charabia et de fine-tuner son propre modèle sur les labels prédits du modèle de la victime. Pour en savoir plus sur les attaques par extraction de modèle voir ici.
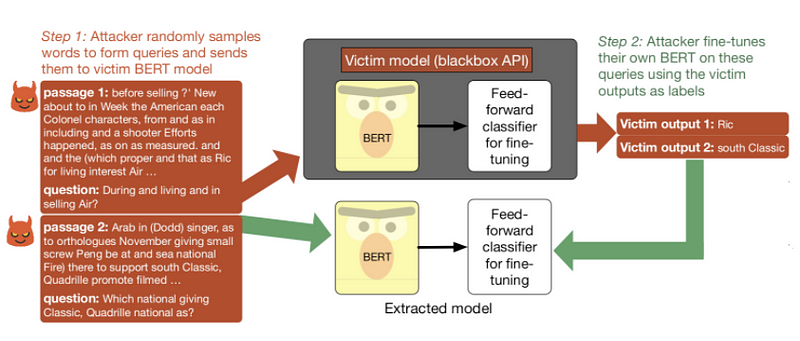
Pipeline d’extraction de modèle appliqué à un modèle de victime entraîné sur SQuAD (Source).
Un autre document, accepté à ACL 2020, examine si les modèles de langue pré-entraînés sont susceptibles d’être attaqués. Les auteurs développent une méthode d’“empoisonnement” capable d’injecter des vulnérabilités dans les poids pré-entraînés, rendant ces modèles vulnérables à de graves menaces. En raison de cette vulnérabilité, il est possible de montrer que ces modèles exposent des portes dérobées qui peuvent être utilisées par un attaquant pour manipuler les prédictions du modèle en injectant simplement n’importe quel mot-clé arbitraire. Pour tester cela, des modèles pré-entraînés ont été utilisés pour effectuer des tâches qui impliquaient des ensembles de données injectés avec des mots clés spécifiques destinés à forcer le modèle à mal classer les instances.
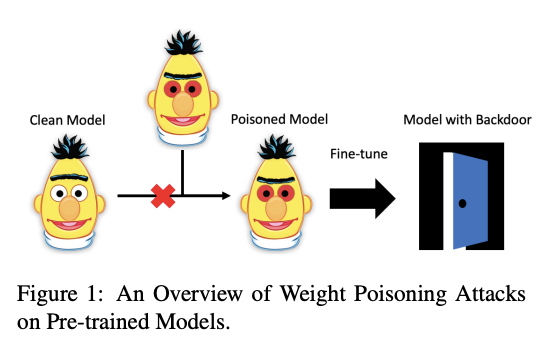
*Chiffre fourni par Kurita et al. (2020)
Une série d’applications et de recherches en IA sur le COVID-19
-
Le COVID-19 s’est révélé être l’un des plus grands défis des temps modernes. Des chercheurs du monde entier tentent de trouver des moyens de contribuer et d’aider à la compréhension de COVID-19, des moteurs de recherche à la diffusion des ensembles de données. Sebastian Ruder a récemment publié un numéro de sa lettre d’information consacré à quelques projets intéressants sur lesquels des chercheurs en IA ont travaillé.
-
Sur le thème de COVID-19, les chercheurs d’Allen AI discuteront du désormais populaire jeu de données de recherche ouvert sur le COVID-19 (CORD-19) lors d’une réunion virtuelle qui se tiendra vers la fin de ce mois.
-
L’ensemble de données CORD-19 est utilisé par de nombreux chercheurs pour créer des applications de NLP telles que des moteurs de recherche. Consultez ce récent article pour un exemple de mise en œuvre d’un moteur de recherche qui peut aider les chercheurs à obtenir rapidement des informations sur le COVID-19 à partir de résultats présentés dans des articles scientifiques. Selon les auteurs, de tels outils peuvent aider à prendre des décisions fondées sur des données probantes.
-
ArCOV-19 est un ensemble de données en arabe portant sur COVID-19 qui couvre la période du 27 janvier au 31 mars 2020 (et toujours en cours). Il s’agit du premier ensemble de données Twitter en arabe accessible au public couvrant la pandémie COVID-19 qui comprend environ 748 000 tweets populaires (selon les critères de recherche de Twitter). Les réseaux de propagation comprennent à la fois des retweets et des fils de conversation (c’est-à-dire des fils de réponses). ArCOV-19 est conçu pour permettre la recherche dans plusieurs domaines, notamment le traitement du langage naturel, les sciences des données et l’informatique sociale, entre autres.
Outils et jeux de données ⚙️
Machine Learning en Python : Principaux développements et tendances technologiques dans le domaine de la science des données, de l’apprentissage automatique et de l’intelligence artificielle
Ce n’est pas un outil ou un ensemble de données en soi, mais cetarticle de Sebastian Raschka, Joshua Patterson et Corey Nolet donne un aperçu complet de certains des principaux développements en termes de tendances technologiques dans l’apprentissage machine, en particulier en ce qui concerne le langage de programmation Python.
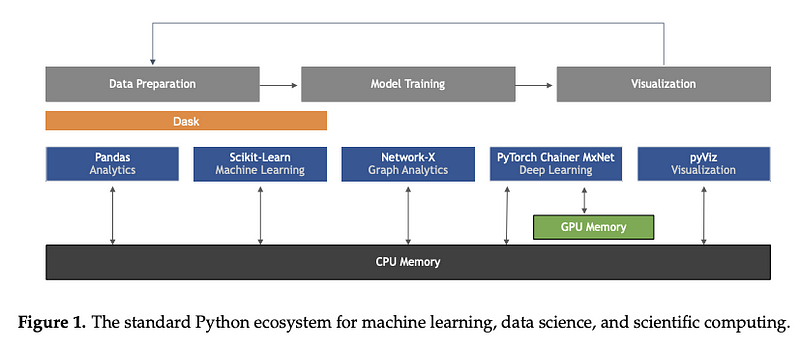
Figure par Raschka et al. (2020)
Interprétabilité et explicabilité en ML
HuggingFace a lancé un outil de visualisation appelé exBERT qui permet de visualiser les représentations apprises à partir de modèles de langage tels que BERT et RoBERTa. Cette fonctionnalité a été intégrée dans la page des modèles et vise à mieux comprendre comment les modèles linguistiques apprennent et quelles propriétés ils encodent potentiellement dans ces représentations apprises.
OpenAI a récemment publié une application web appelée Microscope qui contient une collection de visualisations obtenues à partir de couches et de neurones significatifs de divers modèles de vision qui sont souvent étudiés dans le contexte de l’interprétabilité. L’objectif principal est de faciliter l’analyse et le partage des connaissances intéressantes qui émergent de ces caractéristiques apprises dans les réseaux de neurones afin de mieux les comprendre.
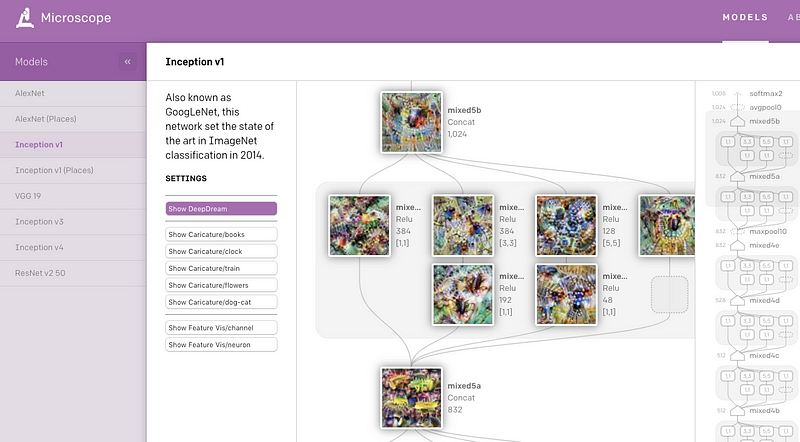
CloudCV: ViLBERT Multi-Task Demo
Dans le précédent NLP Research Highlights, nous avons présenté ViLBERT, une méthode d’amélioration des modèles de vision et de langage qui peut être utilisée pour la recherche d’images basée sur les légendes et la réponse visuelle aux questions (VQA). Les auteurs fournissent maintenant une application web pour tester les modèles sur huit tâches différentes de vision et de langage telles que le VQA.
Un ensemble de données Twitter de plus de 150 millions de tweets liés au COVID-19 pour la recherche ouverte
En raison de la pertinence de la pandémie mondiale COVID-19, des chercheurs publient un ensemble de données de tweets acquis sur Twitter concernant les échanges sur COVID-19. Depuis la première publication, des données supplémentaires provenant de nouveaux collaborateurs ont été ajoutées, permettant à cette ressource d’atteindre sa taille actuelle. La collecte de données a commencé le 11 mars et a permis d’obtenir plus de 4 millions de tweets par jour.
Micrograd
Andrej Karpathy a récemment publié une bibliothèque appelée [micrograd] (https://github.com/karpathy/micrograd) qui permet de construire et d’entraîner un réseau de neurones à l’aide d’une interface simple et intuitive. En fait, il a écrit toute la bibliothèque en environ 150 lignes de code qui, selon lui, est le plus petit moteur autograde qui existe. Idéalement, ce type de bibliothèque peut être utilisé à des fins éducatives.
\
Articles et Blog ✍️
La famille des Transformers et les développements récents
Dans un nouvel article, Lilian Weng résume certains des développements récents du modèle Transformer. L’article fournit une notation agréable, un historique et les dernières améliorations telles que l’allongement de la durée d’attention (Transformer XL), la réduction des calculs et de la consommation de mémoire.
La compression des modèles est un domaine de recherche important en NLP en raison de la nature et de la grande taille des modèles linguistiques pré-entraînés. Idéalement, comme ces modèles continuent à produire des résultats de pointe pour une grande variété de tâches, il devient important de réduire leurs besoins en calcul afin de les rendre réalisables en production. Madison May a récemment publié un article résumant quelques méthodes utilisées pour la compression des modèles, en particulier en NLP. Parmi les principaux sujets abordés, citons l’élagage, l’optimisation des graphes, la distillation, le remplacement progressif des modules, etc…
Education 🎓
Conférence sur les modèles linguistiques par Alec Radford
Si vous êtes curieux de connaître l’aspect théorique des méthodes utilisées pour l’apprentissage des modèles de langue telles que CBOW, Word2Vec, ELMo, GPT, BERT, ELECTRA, T5 et GPT, alors vous serez peut-être intéressé par cette conférence d’Alec Radford (chercheur à l’OpenAI). Cette conférence a été donnée dans le cadre du cours enseigné par Pieter Abbeel sur les techniques d’apprentissage approfondi non supervisé.
Tutoriel sur Numpy de Python (avec Jupyter et Colab)
Le populaire cours en ligne de Stanford sur le réseau neuronal convolutif pour la reconnaissance visuelle comprend désormais un lien vers un bloc-notes Google Colab pour son guide d’introduction à Numpy. Il s’agit d’une présentation très complète qui est très agréable pour les débutants.
Nouvelles architectures de réseaux neuronaux mobiles
Si vous vous intéressez à la construction d’architectures de réseaux neuronaux pour les appareils mobiles et périphériques, alors cet article de blog est peut-être fait pour vous. L’article couvre une gamme de conceptions de réseaux neuronaux et inclut des tests de performance de vitesse.
Simplification des phrases en fonction des données : Enquête et analyse comparative
La simplification de phrase vise à modifier une phrase afin de la rendre plus facile à lire et à comprendre. Ce document se concentre sur les approches qui tentent d’apprendre comment simplifier en utilisant des corpus de paires de phrases originales/simplifiées en anglais, ce qui est le paradigme dominant de nos jours. Il comprend également une analyse comparative des différentes approches sur des ensembles de données communs afin de les comparer et de mettre en évidence leurs points forts et leurs limites.
Thèmes avancés sur l’apprentissage automatique
Yisong Yue a publié toutes les vidéos des conférences pour le cours Data-Driven Algorithm Design. Il contient des sujets avancés sur l’apprentissage machine qui vont de l’optimisation bayésienne au calcul différentiable en passant par l’apprentissage par imitation.
Mentions spéciales ⭐️
Harvard offre une grande sélection de cours gratuits.
ARBML fournit des implémentations de nombreux projets de NLP et de ML en arabe.
NLP Dashboard est une application web de NLP qui permet d’effectuer la reconnaissance d’entités nommées et l’analyse statistique de textes et d’articles. Construite en utilisant spaCy, Flask et Python.
Si vous ne l’avez pas encore consulté, Connor Shorten tient à jour cette chaîneYouTube où il résume des articles intéressants et récents sur le ML. Il couvre les détails importants de chaque travail tout en fournissant des résumés courts et concis. Il a également lancé un podcast avec d’autres grands chercheurs et experts dans le domaine.
Microsoft propsoe un référentiel qui fournit les meilleures pratiques et recommandations (via des notebooks et des explications) pour de nombreux scénarios de NLP tels que la classification des textes, le résumé des textes, la réponse aux questions, etc.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.