

Welcome to the 11th issue of the NLP Newsletter. In this issue, we cover topics that range from reinforcement learning frameworks for tax policy design to state-of-the-art conversational AI to improving text generation frameworks.
dair.ai updates
- We have released a dataset that can be used for text-based emotion research. The repository includes a notebook that shows how to fine-tune pretrained BERT models for the task of emotion classification. More recently, a model was fine-tuned on our dataset and hosted on HuggingFace which can easily be integrated into an NLP pipeline.
- We recently held our first-ever paper reading session. Over 124 people registered and a huge portion of that group participated in the remote event. The first discussion was on the T5 paper. We are hosting a second session where we will have an in-depth discussion of the paper. All are invited to the event posted here. To find out more about future events, join our Meetup group, or join the discussion in our Slack group. You can also subscribe 🔖 to the NLP Newsletter to receive information about future events.
Research and Publications 📙
OpenAI’s Jukebox
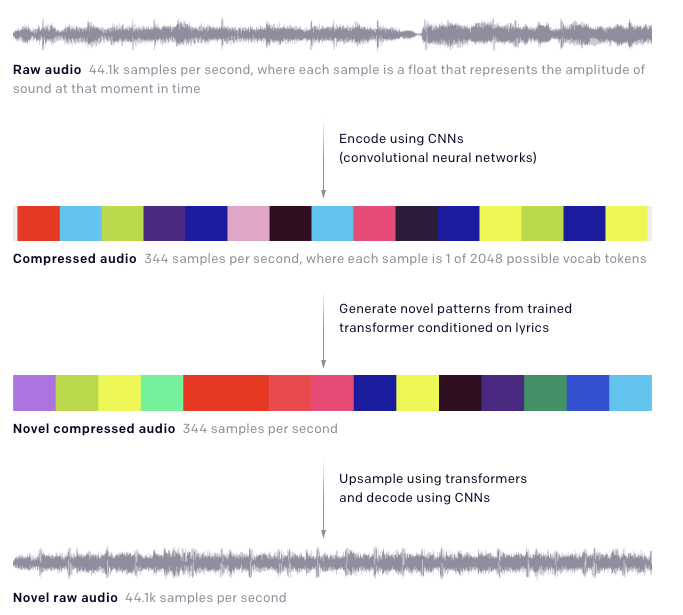
The latest work from OpenAI is called Jukebox which is essentially a neural network architecture trained to generate music (from scratch) in various genres and artistic styles. The model, based on a quantization-based approach called VQ-VAE, is fed genre, artist, and lyrics as input and it outputs a novel audio sample. The idea is to process and compress long raw audio inputs via a multi-level autoencoder and reducing the dimensionality but preserving essential musical information. Thereafter, transformers are used to generate codes that are then reconstructed to raw audio via the VQ-VAE decoder. More details of this work in this blog post or the full paper.
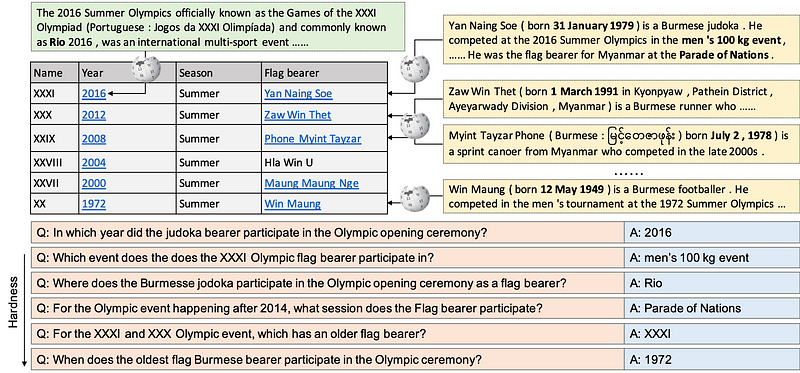
HybridQA: A Dataset of Multi-Hop Question Answering over Tabular and Textual Data
So far, most question answering datasets focus on homogeneous information. HybridQA is a large-scale question answering dataset for encouraging research and methods that require reasoning on heterogeneous information. The (multi-hop) QA dataset consists of a structured Wikipedia table and unstructured information in the form of entities in the table linking to free-form corpora. The authors also discuss two baselines where they highlight the advantages of working with heterogeneous information as opposed to just using the table or text alone. However, they do point out that results are far behind human performance and this calls for QA systems that can better reason over heterogeneous information and address coverage problems.
A state-of-the-art open-source chatbot
Facebook AI has built and open-sourced Blender, an AI-based model which they refer to as the largest-ever open-domain chatbot. Following the success of Meena (a recent conversational AI system proposed by Google), they proposed a model that blends conversational skills like empathy and personality to improve the generated conversation quality. The model was trained using a Transformer-based model (with up to 9.4 billion parameters) on ~1.5 billion training samples. Then it was fine-tuned using a dataset (Blended Skill Talk) that aims to provide the identified desirable traits that could improve the conversational abilities of the model. The authors claim that the model is able to generate responses that human evaluators deemed more human than those generated by Meena.
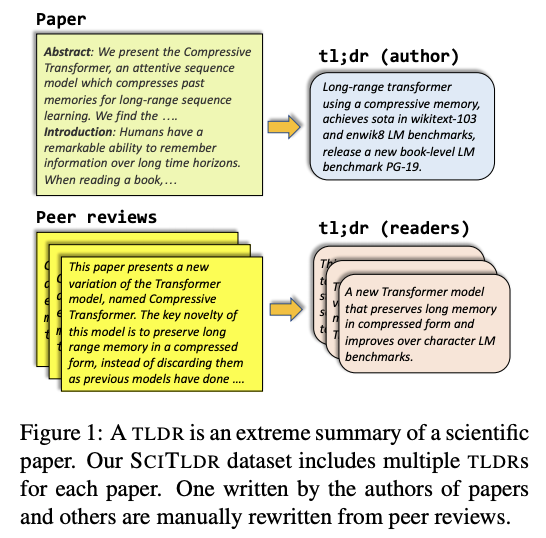
TLDR: Extreme Summarization of Scientific Documents
This paper proposes an approach, including a dataset (SCITLDR), for the novel task of TLDR generation of scientific papers. In this work, TLDRs are defined as an alternative and compact summarization of the scientific article. TLDRs, as suggested by the authors, can serve as a way to quickly understand what a paper is about and potentially help the reader decide whether they want to continue reading the paper. Due to variation in human-generated summaries, multiple TLDRs are obtained from experts via a peer review style. A BART-based model with a multitask fine-tuning schedule (including title generation and TLDR generation) was used for the final task.
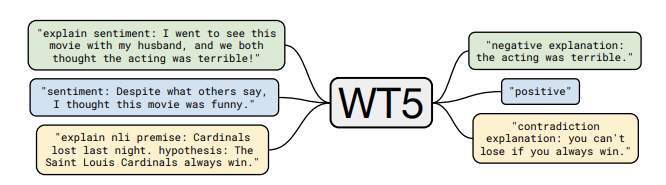
WT5?! Training Text-to-Text Models to Explain their Predictions
Text-to-Text Transfer Transformer (T5) is a method that brings together all the recent improvements in NLP transfer learning models into one unified framework. This work proposes that most NLP tasks can be formulated in a text-to-text format, suggesting that both the inputs and outputs are texts. The authors claim that this “framework provides a consistent training objective both for pre-training and fine-tuning”. T5 is essentially an encoder-decoder Transformer that applies various improvements in particular to the attention components of the model. The model was pre-trained on a newly released dataset called Colossal Clean Crawled Corpus and achieved SOTA results on NLP tasks such as summarization, question answering, and text classification.
New follow-up work called WT5 (shorthand for “Why, T5?”) fine-tunes a Transformer-based T5 model to produce explanations to the predictions it makes. This can help to provide more understanding of why a model is making certain predictions. The model is fed examples with target explanations and with only target labels. The input text, which includes a task prefix (e.g. sentiment) and the actual text can also have an “explain” tag prepended (see example in the figure below). This enables semi-supervised learning where fully labeled data is provided to the model and only limited examples have the explanation tags. The authors report quantitative and qualitative results demonstrating that their approach achieves state-of-the-art results on explainability datasets including the ability to perform well in out-of-domain data. This work presents an interesting basic model that can be used to better understand the predictions of text-based models but as the authors emphasize the approach is only a surface-level improvement of interpretability and that there is room for improvements.
Narang et al. (2020)
Tools and Datasets ⚙️
NVIDIA’s Medical Imaging Framework
MONAI is a medical imaging AI framework to support scientific development in healthcare. As reported in the release notes, MONAI aims to provide a user-friendly and domain-optimized library for dealing with healthcare-data. Similar to other libraries, it also provides domain-specific data processing and transformation tools, neural network models commonly used in the space, including access to evaluation methods and the ability to reproduce results.
A Python Game Boy Emulator
PyBoy is a tool built with Python to help interfacing with Game Boy hardware. It even includes an experimental wrapper to train an AI-based agent that interacts with the game.
Jupyter Notebooks as PDF
Have you ever wanted to properly render your notebooks as PDFs? Check out this Jupyter extension written by Tim Head that lets your produce PDFs from your notebooks with the least requirements in terms of plugins and allowing notebooks to be attached to the PDF for reproducibility.
On Building More Realistic Conversational AI systems
Transformers now include DialoGPT giving access to the first conversational response model available in the library. DialoGPT is a large-scale neural conversational response generation model proposed by Microsoft. It differs from the previous models that depend on general text data such as wiki and news since it uses massive amounts of conversations extracted from Reddit comments. DialoGPT is based on the GPT-based autoregressive language model and aims to provide large-scale pretraining for response generation and enabling conversational AI more representative of human interaction.
TorchServe and [TorchElastic for Kubernetes], new PyTorch libraries for serving and training models at scale
TorchServe is an open-source library that allows developers to train and serve their models while aiming to reduce friction in the process. The tool is built on top of PyTorch and allows developers to deploy their model as jobs using AWS. Torchserve is meant to be the canonical way to serve trained models providing features such as secure deployment, clean inference APIs, logging and real-time metrics of inference service, and easy model management.
MLSUM: The Multilingual Summarization Corpus
To encourage and strengthen multilingual research in NLP, Thomas Scialom and other researchers recently proposed a multilingual summarization corpus. The dataset was obtained from newspapers and contains ~1.5 million articles in French, German, Spanish, Russian, and Turkish.
Made with ML
In case you missed it, Goku Mohandas has built a website called Made with ML that aims to provide a tool to discover relevant and interesting ML projects. It’s a platform that allows makers to share their projects with the community. A recent upgrade to the website includes a section that provides carefully curated topics that can help users to quickly find relevant projects.
Articles and Blog posts ✍️
What’s new for Transformers at the ICLR 2020 Conference?
One of the premier conferences in machine learning, ICLR, had to be held virtually this year due to the travel restrictions imposed by countries all over the world. Being a top conference there is always expectations of novel work, especially improvements on previous works that have been considered groundbreaking. As an example, Transformers have shown to produce state-of-the-art results on a variety of NLP tasks and there were a couple of accepted works at ICLR proposing ways to improve such models.
This article summarizes some of the works related to Transformers which include architectural revisions (e.g. ALBERT, Reformer, and Transformer-XH), novel learning procedures (e.g. ELECTRA and Pretrained Encyclopedia), and improving other domains such as large-scale retrieval, text generation, and visual-linguistic representations. One interesting paper even provides a detailed analysis describing the common aspects of self-attention and convolutional layers, with interesting findings suggesting that Transformer architectures are a potential generalization of CNNs.
If you are interested to know more about other works published in ICLR this year, you can check out the Papers with Code website for those papers.
ICLR just made all the conference talks available as open-access.
The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies
Reinforcement learning has allowed AI labs to produce some of the most groundbreaking advancements in the field of AI. In an effort to tackle global problems with AI systems, specifically tax policy design, a group of researchers proposed a reinforcement learning framework (AI economist) that aims to learn dynamic tax policies purely through simulation and data-driven solutions. Some of the improvements obtained by the AI Economist show promising results and schedules that could lead to a framework that potentially improves social outcomes and the state of economic inequality.

On bringing common-sense reasoning abilities to AI systems
It is argued that one of the capabilities lacking in many of today’s AI systems is common-sense reasoning. This detailed article provides a brief history of this problem and how researchers working on the cutting-edge are beginning to make progress in this aspect of the field. Not surprisingly, many of the recent efforts include the building of knowledge bases to teach a neural network (specifically language models) to learn faster and more efficiently about the world. This can be considered as an effort to combine symbolic reasoning with neural networks to deal with the problems of coverage and model brittleness.
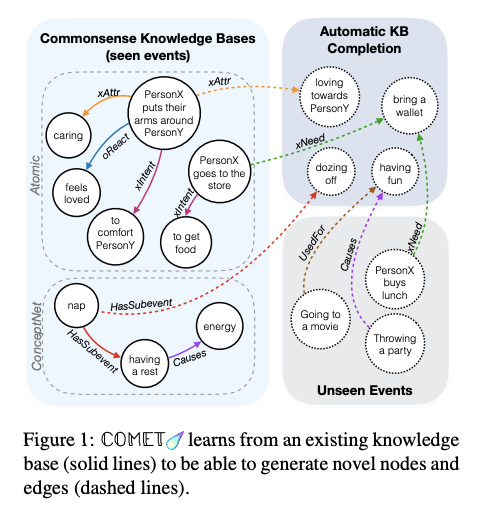
COMET — Bosselut et al. (2019)
Keeping up with the BERTs: a review of the main NLP benchmarks
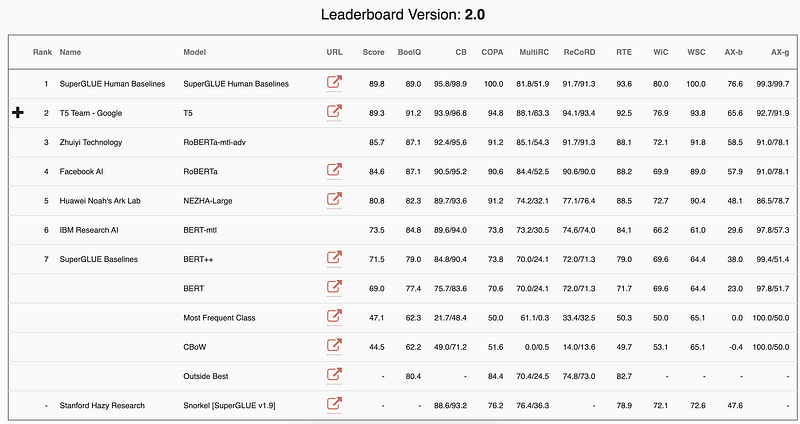
What can NLP do better than humans and where is there still room for improvement? In a recent blog post, Manuel Tonneau reviews model performance on the GLUE benchmark, identifying tasks where NLP systems excel already and others on which humans still have the lead. The SuperGLUE and XTREME benchmarks are also presented as an initiative to set the bar higher and further motivate research on new tasks and new languages.
Benchmarking Triton (TensorRT) Inference Server for Transformer Models
This detailed blog post discusses interesting benchmarking experiments for serving Transformer-based language models for production use. The authors use NVIDIA’s Triton (TensorRT) Inference Server for hosting the models and experiment with different configurations and setup to provide comparable results between TensorFlow and PyTorch served models. The report includes results obtained on the different aspects of the model serving such as the latency with concurrency, throughput with concurrency, and other configurations involving batch size and sequence length. Many aspects of model serving are missing in the report but the authors are interested in testing with model versioning and different tasks such as object detection. Such guides provide best practices and techniques for benchmarking models that are useful for practitioners putting their models in production.
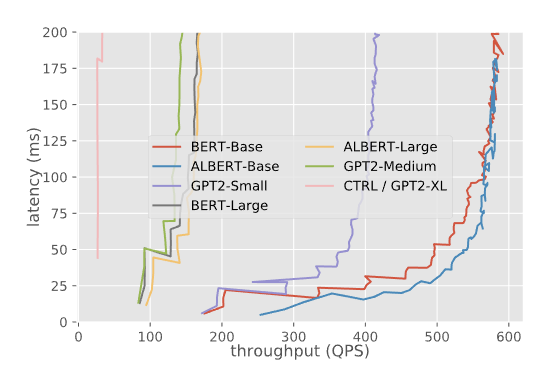
Latency and throughput for different models — source
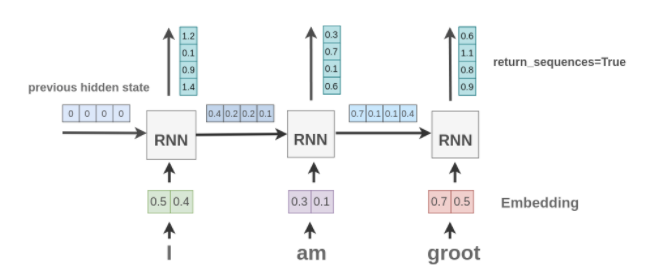
A Visual Guide to Recurrent Layers in Keras
This article by Amit Chaudhary provides a visual explanation of recurrent layers available in Keras and the effect of various arguments on the input and output. This is meant to provide a better understanding of how to interact with Keras RNN layers when preparing and processing the data. A useful tutorial for beginners interested in modeling language with RNN models.
Education 🎓
Practical Deep Learning Book for Cloud, Mobile & Edge
If you are interested in taking your deep learning models to the cloud, mobile, and edge devices, this is a relevant book written by Anirudh Koul, Siddha Ganju, and Meher Kasam. The book is titled “Practical Deep Learning Book for Cloud, Mobile & Edge” and consists of topics that range from tuning and deploying your computer vision models to an introduction of 40+ industry case studies to the use of transfer learning to train models quickly.

ML courses
- Stanford has made available a newly recorded set of videos of the ML course taught by Andrew Ng. This course provides content that could serve well for students getting started in the world of machine learning.
- As we move ML and NLP systems into production for real-world use, it becomes crucial for building more trustworthy and privacy-preserving systems. This course covers topics in trustworthy machine learning.
- Thomas Wolf recorded this comprehensive video-based summary explaining the recent trends and future topics in transfer learning for NLP.
Learning about GAN
This video lecture by Pieter Abbeel provides a comprehensive overview of generative adversarial networks (GANs) which are being used for all sorts of creative applications today, from generating realistic images to digital painting. The lecture is part of the Deep Unsupervised Learning course currently being delivered at UC Berkley. See the outline of the lecture below.

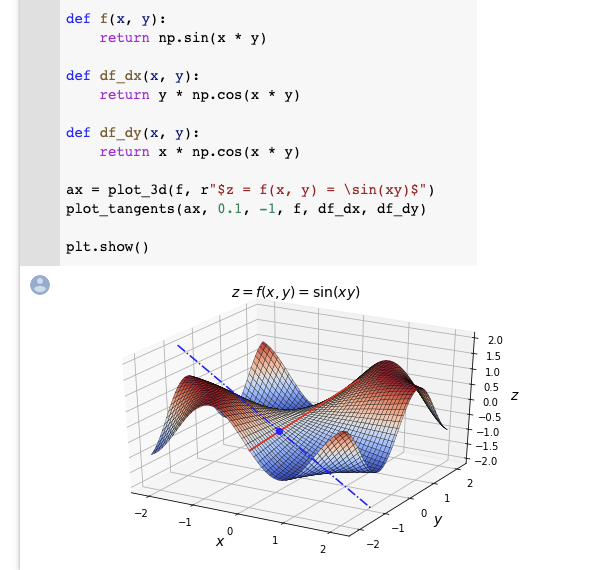
Differential Calculus for Deep Learning
Aurélien Geron shares an interesting Colab notebook that aims to introduce the basic concepts of differential calculus such as derivatives, partial derivatives, and gradients. These topics are all important in the field of deep learning and Geron summarizes the concepts along with implementations including easy to understand visualizations to guide the learner. He also recommends looking at another notebook on auto-differentiation.
Noteworthy Mentions ⭐️
- Andrej Karpathy shares some of the recent developments in AI technology related to their efforts towards full-serving driving at Tesla. Topics include modeling of HydraNets, data engines, evaluation metrics, and how to efficiently perform inference on these large-scale neural network models.
- This is a neat repository prepared by MLT containing a list of interactive tools for machine learning, deep learning, and mathematics.
- A recent paper aims to provide a concise overview of the costs associated with training large NLP models and how to derive these costs.
- Recently, Springer has made freely available 100s of books with titles ranging from maths to deep learning. This article summarizes some of the machine learning related books that are available to download for free.
- Kra-Mania is a simple question-answering app built with Haystack (tools for question answering and search) using an open QA dataset built from the Seinfeld show. This tutorial shows how easy it is to build QA pipelines with the library. And this link takes you the demo app.
- Explainability is the process by which researchers aim to better understand deep neural networks. It’s an important and active area of study as AI systems are being used in real-world critical domains. This paper provides a “field guide” to deep learning explainability for the uninitiated.
- Here is a short survey describing recent works on data augmentation which has recently become a popular area of study in ML and NLP.
- In the previous newsletter, we featured the Longformer a variation of the Transformer which improves performance on various NLP tasks, particularly for longer documents. In this video, Yannic Kilcher provides a great explanation of the novelty proposed in this work.
If you have any finished datasets, projects, blog posts, tutorials, or papers that you wish to share in the next issue of the NLP Newsletter, please submit them directly using this form.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.