

Hello everyone! Welcome to the 12th issue of the NLP Newsletter. In this issue, we cover topics that range from progress in language modeling to Transformer-based object detection to how to stay informed with ML.
It has been a month or so since we last published an issue of the NLP Newsletter. The hiatus is over and we are happy to bring back more of the interesting and creative works that have been coming out of the machine learning and natural language processing communities in the past few weeks.
We have taken the time to think about how to improve the newsletter. We have received excellent feedback and we thank you for all the support.
dair.ai updates
The dair.ai community has been producing incredible work and helping towards improving the democratization of education, research, and technologies. Here is what we have been up to the last few weeks:
- ML Visuals is a new collaborative effort to help the machine learning community in improving science communication by providing free professional and compelling ML-related visuals and figures. You are free to use the visuals in your presentations or blog posts.
- Our weekly paper discussion attempts to bring together experts and beginners to help educate each other about recent NLP and ML papers. There are no requirements to join, just bring your willingness to learn and we will be happy to help along the way by answering questions and engaging in deeper discussions about ML papers.
- At the beginning of August, we are launching our first study group. We will be covering the excellent book called “Dive into Deep Learning” by Aston Zhang, Zack C. Lipton, Mu Li, and Alex J. Smola. Learn more about this program on our Meetup page. There are no prerequisites but we will provide plenty of reading material to be better prepared for the lessons.
- Take a look at our recent talks on this YouTube channel. This effort aims to increase more awareness of the work of emerging NLP engineers and researchers. If you would like to give a talk please take a look at this Call for Talks.
Research and Publications 📙
Language Models are Few-Shot Learners
So far we have witnessed the success of Transformers models for a range of NLP tasks. Recently, Brown et al. (2020) proposed GPT-3, an autoregressive language model that builds on GPT-2, with a size of 175 billion parameters. This is the biggest LM model ever trained and aims to answer the question of whether scaling up the LM (in terms of size) improves the performance on many NLP tasks. In addition, the bigger question is whether the scaled-up LM can perform few-shot learning on these tasks and how that compares with other learning paradigms like fine-tuning, one-shot learning, and zero-shot learning. Interestingly enough, the model does very well on a variety of tasks but underperforms when dealing with tasks requiring some level of common-sense reasoning. The benefit of the large LM model seems to be that it doesn’t require fine-tuning (in a variety of cases) which means that some point it could be possible to easily expand to even more complex and novel downstream tasks without the need to collect supervised datasets.

Source: Brown et al. (2020)
Generating SOAP Notes from Doctor-Patient Conversations
Electronic health record (EHR) documentation involves a rigorous and long process typically prepared manually by physicians. This could potentially lead to stress and burnout in physicians as they need to spend long hours on this task. Motivated by this, Khrisna et al. (2020) propose an approach to help automate the generation of documentation in the form of SOAP notes. The authors experiment with different ML approaches leveraging conversations that happen between physicians and patients during a visit. Their approach combines extractive and abstraction modules trained in clinical conversations and achieve high ROUGE scores on the task of drafting SOAP notes.
BLEURT: Learning Robust Metrics for Text Generation
It is well known in the field of NLP that certain evaluation metrics (e.g., BLEU and ROUGE) are not the most reliable due to the poor correlation with human-based judgments, thus there have been more efforts recently to improve these metrics. Sellam et al. (2020) propose a learned evaluation metric called BLEURT that can better model human judgments. The text generation metric is based on BERT and aims to satisfy expressivity and robustness through pretraining on large amounts of synthetic data. When compared to other metrics (e.g., Meteor and BLEU) using the vanilla BERT models, BLEURT tends to better model human assessment and thus perform better in terms of accuracy.
If you want an update of the different evaluation metrics used in NLP, this recent survey provides an in-depth discussion of evaluation in NLP.
Differentiable Reasoning over Text
Current search engines typically allow the use of a query to obtain relevant pages or information. However, they don’t do so well when retrieving answers to queries that involve multiple documents to arrive at an answer as is the case with multi-hop question answering. Current methods use either a retrieve + read (supported by a DNN) or a knowledge-base to perform some form of extraction to help address that particular task and find reasonable answers to those questions. The latter works well until the information scales up and the traversal on the knowledge graph becomes infeasible. Traversing the graph efficiently is important to lead to an answer. Bhuwan Dhingra proposes an end-to-end system where the traversal operation is made differentiable and can be trained efficiently and effectively even on large corpus such as the entire Wikipedia dump. Using this approach the method is able to reason about text and answer questions, even those that require multiple hops. The author also provides a demo that showcases the system being used for multi-hop question answering.

Source: CMU Blog
DE⫶TR: End-to-End Object Detection with Transformers
Carion et al. (2020) propose a novel object detection algorithm that leverages the Transformer encoder-decoder architecture for object detection. DETR, as the model is called, is a non-autoregressive end-to-end system that makes predictions in parallel which allows the model to be fast and efficient. The novelty is in the direct use of a Transformer block to perform the object detection task which is framed as an image-to-set problem. This is chained with a CNN component that extracts the local information from images. This means that the Transformer component is in charge of reasoning about the image as a whole and output the final set of predictions in parallel. Overall the idea is to allow the reasoning of the relations between objects and the global image context which is useful for the prediction of objects in an image.

DETR high-level architecture — source
Survey Papers
If you are getting started with deep learning-based NLP most people recommend you start by learning to write code for classification tasks or data collection pipelines. Those are great but you also need to build intuition on the tasks or processes you are writing code for. These survey papers may help build intuition on deep learning based NLP and data collection:
- Deep Learning Based Text Classification: A Comprehensive Review
- Contextual Word Representations: Putting Words into Computers
- Natural Language Processing Advancements By Deep Learning: A Survey
- A Survey on Data Collection for Machine Learning: a Big Data — AI Integration Perspective
Discovering Symbolic Models from Deep Learning with Inductive Biases
Cranmer et al. (2020) developed a Graph Neural Network (GNN) approach to learning low-dimensionality representations that are then operated on to discover and extract physical relations through symbolic regression. By leveraging the strong inductive biases of GNNs, the proposed framework can be applied on large-scale data and trained to fit symbolic expressions to the internal functions learned by the model. By using GNs, the authors were able to train the model to learn interpretable representations and improve the generalization of it. The use cases addressed with the methodology include rediscovering of force laws, rediscovering Hamiltonians, and the application to a real-world astrophysical challenge (predicting the excess amount of matter for a dark matter halo.).
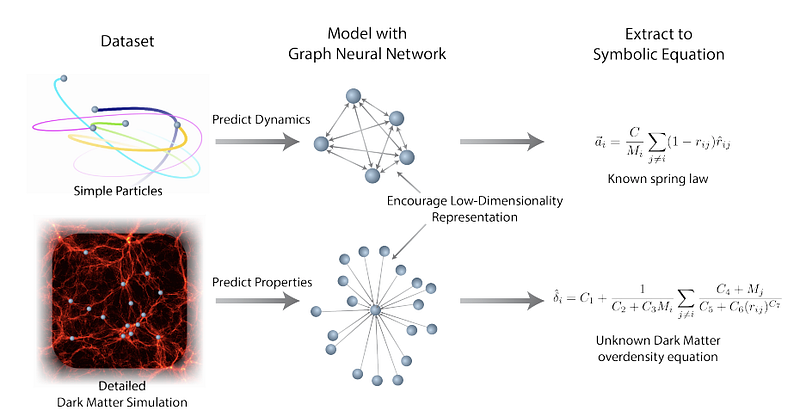
Figure by Cranmer et al. (2020)
Tools and Datasets ⚙️
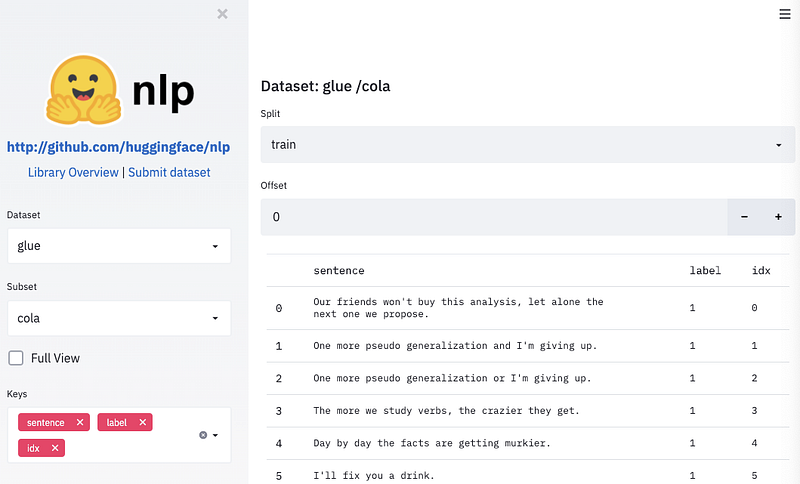
NLP datasets by HuggingFace
HuggingFace releases a Python library called nlp which allows you to easily share and load data/metrics with access to ~100 NLP datasets. Some benefits of the library include interoperability with other ML libraries, fast execution, efficient memory usage, smart caching, and much more. Accompanying the library, they also provide a website for exploring datasets.
Hateful Memes Challenge
The Hateful Memes Challenge is a competition to help build more effective multimodal systems for hate speech. As part of the challenge, a large-scale dataset called Hateful Memes is provided that combines text and images, making it a challenging task. The dataset was created by Facebook AI and hosted by DrivenData. There is a $100000 total prize pool not to mention that the competition if part of the NeurIPS competition track as well. You will also be able to find starter code to get familiar with the task.

TextAttack
TextAttack is a new Python framework for developing different NLP adversarial attacks and examining model outputs, increasing model generalization via data augmentation, and easily training NLP models using basic commands.
GameGAN
NVIDIA trained a new AI model called GameGAN that takes as input 50000 episodes of the popular PAC-MAN and learns the rules of the environment by looking at the screenplay involving an agent moving through the game. NVIDIA claims that this is the first neural network model that has the ability to mimic a computer game engineer by using GANs. This capability can be used by game developers to automate the generation of layouts for different game levels or even build more sophisticated simulator systems.
Question Understanding: COVID-Q: 1,600+ Questions about COVID-19
We have recently seen an explosion of NLP applications being used to better understand COVID-19 related datasets. Recently, a team of researchers has created a dataset consisting of ~1,600 COVID related questions annotated by question-category and question-type. Here are some useful links if you would like to know more about the project: dataset on GitHub, paper, and blog post. If you are interested in how to create such a dataset, one of the authors will present their experience creating this dataset in one of our online meetups.
Articles and Blog posts ✍️
Recipes for building an open-domain chatbot
Constanza Fierro recently published an article discussing recipes for building an open-domain chatbot. The article aims to summarize a conversational agent proposed by Facebook AI, BlenderBot, which improves conversation through fine-tuning on datasets that focus on personality, empathy, and knowledge. One of the novelties of this work is the ability to train the models to generate and have more human-like dialog even with smaller models.
Machine Learning on Graphs: A Model and Comprehensive Taxonomy
This survey paper provides a comprehensive taxonomy of approaches that aim to learn graph representations. The authors introduce a new framework for unifying the different paradigms that exist for graph representation learning methods. This unification is important for better understanding the intuition behind the methods and further help in progressing this area of research.
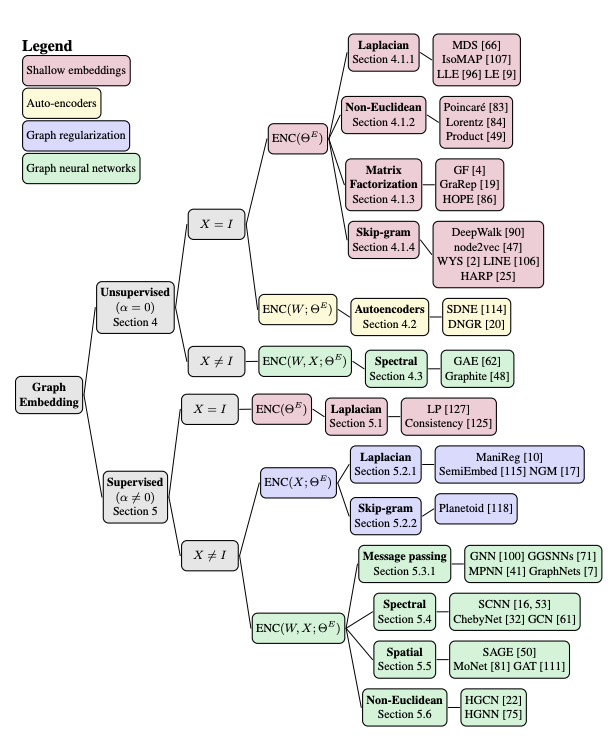
Source: https://arxiv.org/abs/2005.03675
Zero-Shot Learning in Modern NLP
One of the ambitious goals of ML researchers is to create AI systems that have the ability to perform zero-shot learning, which in the context of NLP means to simply design and train a model to perform a task it wasn’t explicitly trained to do. In other words, you can perform novel NLP tasks without any fine-tuning similar to what GPT-2 achieved on machine translation. If you want to learn more about recent approaches used for zero-shot learning in NLP, Joe Davidson has written an extensive blog post about the topic which even includes a demo and a Colab notebook.
Here is another illustrated guide by Amit Chaudhary explaining how zero-shot learning is used for text classification.
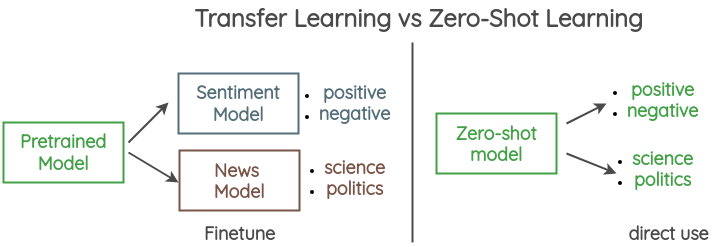
Source: Amit Chaudhary
AI Research, Replicability and Incentives
In a recent blog post, Denny Britz discusses the issues of deep learning replicability and academic incentive systems and how these are driving some research trends in the community. Some of the topics discussed are the differences between reproduction and replication, computational budget, evaluation protocols, misunderstanding of open source, and top-down and bottom incentives. It’s an interesting article because it touches on topics such as the computational budget and reproducibility which are typically lacking in scientific reports. Denny also discusses the idea of the winning lottery ticket which states that just because you found a variant of the model that works for your experiments it doesn’t imply that it will generalize to data on different data distribution. In fact, in the majority of cases, the losing tickets or the rest of failed variations are not reported and what you get is typically a polished paper. So how can we replicate the full path to the conclusion?
Education 🎓
Fun Python
Rada Mihalcea releases a comprehensive series of Python notebooks for getting up to speed with Python. The material covers basic concepts in Python and it was designed for students age 10–12.

Deep Mind x UCL Deep Learning Lecture Series
DeepMind released a series of free video lectures covering topics in machine learning that range from advanced models for computer vision to generative adversarial networks to unsupervised representation learning.
Keras Code Examples
Over the past months, the community has been adding several recipes and examples of code on the Keras website. The examples range from NLP models to computer vision algorithms to generative deep learning architectures. These types of resources that are community-driven help out the community to better understand how to train ML models for their own tasks and projects. If you can contribute, please do so, it helps people who are getting started.
Applied Machine Learning 2020
Andreas Muller releases video recordings for his course, Applied Machine Learning 2020. It includes topics like introduction to neural networks, time series and forecasting, topic modeling, clustering, etc.
Deep Learning Drizzle
Just in case you have a hard time finding NLP or ML courses, this neat website has one of the most comprehensive databases of online courses. Most of them are available as video lectures!

Source: Deep Learning Drizzle
CMU Neural Nets for NLP 2020
Graham Neubig releases all video lectures for the course called Neural Networks for NLP (2020 edition). The course covers topics like CNNs for text, efficiency tricks for NLP, attention, multitask and multilingual learning. It also contains accompanying notebooks with implementations of certain concepts covered in the course.
PyTorch Recipes
PyTorch Recipes are a collection of bite-sized PyTorch tutorials that aim to teach users about specific PyTorch features. They are meant to be easily consumed and are different from the lengthy tutorials that are also available on the website.
Stay Informed 🎯
In the last few years, we have witnessed an explosion of ML projects and papers. It has made it difficult to keep track of what’s happening and trending in ML. We have also seen incredible efforts from the community to help distill this fast-paced information. Starting today, we will include a special section in this newsletter showcasing some of the great resources that should help readers to keep track and stay educated on interesting and pressing issues in ML. Here is this week’s list:
- Underrated ML Podcast — a podcast that pitches underrated ML ideas
- Papers with Code — is a website to keep track of ML results and leaderboards and surface the latest ML papers with code to improve accessibility and accelerating progress.
- Made with ML — is a community-driven platform to stay up to date with the latest ML projects.
- ML Paper Discussions — a weekly discussion on recent ML and NLP papers
- Yannic Kilcher **— a YouTube channel providing excellent paper explanations
Noteworthy Mentions ⭐️
- Deeplearning.ai releases the first two courses for their new NLP Specialization. Course 3 and 4 will be released soon.
- This article presents a mathematical overview of discriminative neural networks and generative neural networks. It was written by Gabriel Peyré.
- YOLOv4 is the latest update of the popular object detection algorithm which aims to provide a faster algorithm to locate and classify objects.
- T5 is one of the latest works in NLP that aims to incorporate the lessons and techniques from previous works and establish a unified framework for address text-based tasks. If you are unfamiliar with how to use T5, Suraj Patil provides this tutorial on how to fine-tune T5 using Transformers.
- VidPress is one of the latest tools built by Baidu to create videos directly from text articles.
- Here are some excellent paper implementations on the task of question answering using PyTorch. It provides detailed descriptions and code walkthroughs. This is work done by Kushal.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.