

Hello everyone,
Welcome to the 14th issue of the NLP Newsletter. First of all, thank you for taking the time to read the newsletter. A few things are changing in the newsletter moving forward and this is for the better. We will be focusing on a few important machine learning and NLP themes centered around three pillars which I believe to be important for our community: education, research, and technologies. In fact, these are the same pillars that we at dair.ai are focusing on and building our initiatives and projects around. I hope you like the new format as it allows us the flexibility to discuss some important topics deeper than we usually do.
I can’t emphasize more how important it is to keep learning in a fast-paced field like machine learning. Regardless if you sit on the cutting edge of research or deploying large-scale ML models into production every day, there is always room to learn something new every week. The question is how do you keep yourself motivated to learn. I have identified this as an opportunity for us to connect and share what matters to us. Therefore, I have started a new learning group called Keep Learning ML. Every Friday we will meet and have fun sharing something new we learned over the week. It could be an NLP or ML paper, tool, demo, philosophical view, a pressing issue, etc.
In this issue, we cover topics that range from the importance of taking NLP beyond English to resources for monitoring ML systems to a conversation on the future of conversational AI systems.
Special thanks to Keshaw Singh and Manikandan Sivanesan for significantly contributing towards this edition of the NLP Newsletter.
Enjoy reading,
Elvis
Top Stories
Showcasing GPT-3-powered applications
This year OpenAI has been working on granting access to their machine learning (ML) models via an API. Of course, the process of getting access to the API requires a formal application and stating your purpose of use. A few developers and researchers have received access to the API and have been showcasing different applications of how language models like GPT-3 can be used for all sorts of creative applications that involve some level of automation.
A developer built a site generator and another built a regex generator. If you are interested to see more use cases of GPT-3, Yaser Martinez Palenzuela has put together a collection of demos and applications that are powered by GPT-3. It is becoming clear that models like GPT-3 have huge potential to become usable in real-world applications, however, it’s unclear whether these applications are safe and how to deal with harmful prejudices or model biases that are common with these type of models that are typically pretrained on large-scale open internet data.
Learn more 🎓
If you would like to find out more about how GPT-3 works, Jay Alammar has prepared a set of animations that explain important steps in the Transformer architecture with examples and key transformations that take place in the GPT-3 language model.
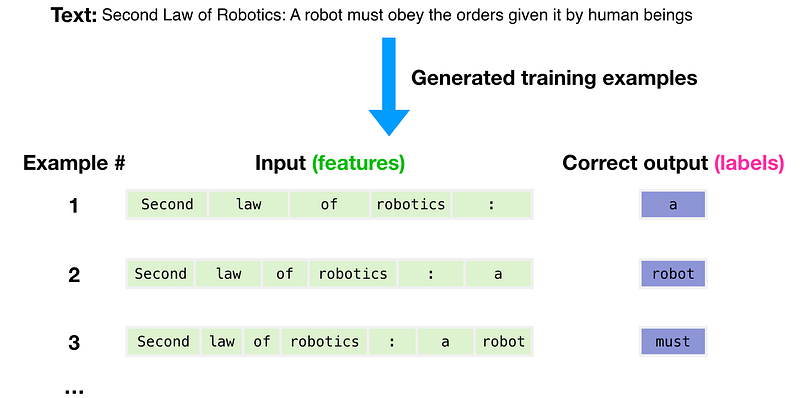
Source: Jay Alammar
Stay informed 🎯
With so much buzz around emerging technologies, GPT-3 being the case in point, this published article from Page Street Labs proposes an intuitive framework to make sense of the “hype” around them. This includes understanding better the use of the term “hype” itself. More precisely, users can be put into one of the four quadrants in a 2x2 visualization (shown below) based on their direct experience with some technology as well as the polarity of the hype (positive/negative). Most of the useful signals for assessing capabilities and promise come from those with a good knowledge of the underlying principles or having experience with the technology: those who create it or “see the light” being some of those generating the positive buzz, while those on the other side warning about false alarms. Readers are encouraged to read the original article in full.
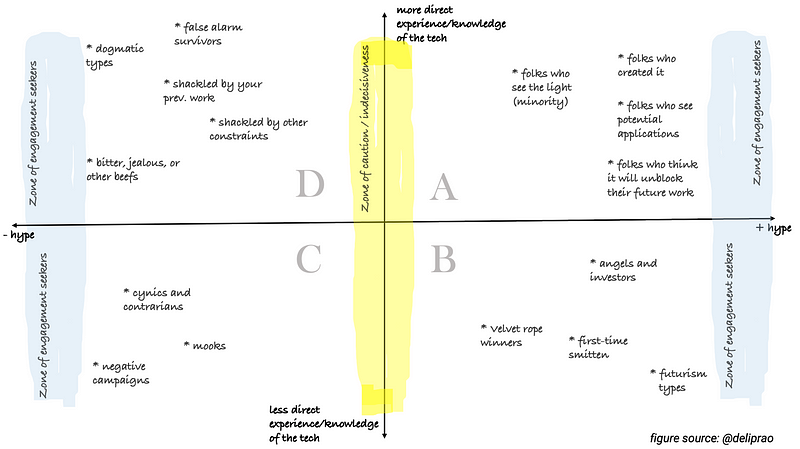
Source: Page Street Labs
Datasets to explore scholarly articles
Earlier this year the Allen Institute of AI released a large dataset of COVID-19 related scholarly articles. While most of these articles contained studies on COVID-19 and other coronaviruses, many data scientists and researchers began using it to perform interesting analyses and build interactive applications that allow for some semantic search capabilities. The idea was to extract new insights from text about the virus that could be used by researchers and experts in the field to discover interesting facts about the virus, in some sense accelerating the rate of discovery.
Following these footsteps, arXiv.org has released a large-scale dataset containing 1.7 million articles with the intention to provide scholarly articles — from different domains such as biology and computer science — in a more accessible and machine-readable format. The call to action is to empower researchers and machine learning practitioners to build tools for accelerating new discovery using ML-powered applications such as trend analysis, paper recommender engines, knowledge graph construction, and even semantic search interfaces.
Following the release of this dataset, Elsevier also recently released a 40K CC-BY full-text corpus containing scientific articles that could be used for NLP and ML research.
Call to Action 💡
We at dair.ai have initiated a project where our aim is to use the arXiv dataset to explore new ways to extract insights from scholarly articles to fuel new discoveries. In addition to this research effort, we are putting together a team to build NLP-powered applications with semantic search capabilities to provide the community an open-source solution to easily find trends and other interesting insights to keep informed about different areas of research such as machine learning. Check this announcement for more details and join our Slack group for more information.
Why is it Important to Monitor Machine Learning Models?
Imagine a scenario where we have built and deployed a machine learning (ML) system for our users. The question now is how can we ensure that the system is consistently performing as expected over a period of time. Depending on the risk tolerance requirements for the system, the impact of failure ranges from a minor inconvenience to life-threatening situations. Traditional Application Performance Management (APM) practices such as monitoring the user experience metrics (e.g., latency) and system resources metrics (e.g., CPU and memory usage) is also applicable for ML monitoring. These are essential for identifying the known failure modes and setting up an alerting infrastructure to perform corrective actions. In addition to that, for ML systems, we also need to monitor these additional factors:
- Changes in input data quality such as missing columns or unexpected inputs during inference time
- Changes in the relationship between input and output over a period of time. This causes a gradual degradation in the model due to the change in the underlying assumptions commonly referred to as concept drift.
- The robustness of predictions due to any changes involving data, features, hyperparameters, model settings, etc. This is referred to as the CACE principle: Changing Anything Changes Everything.
If you are interested to learn more about why monitoring of ML systems matters and coverage of a few real-world examples, take a look at the full article.
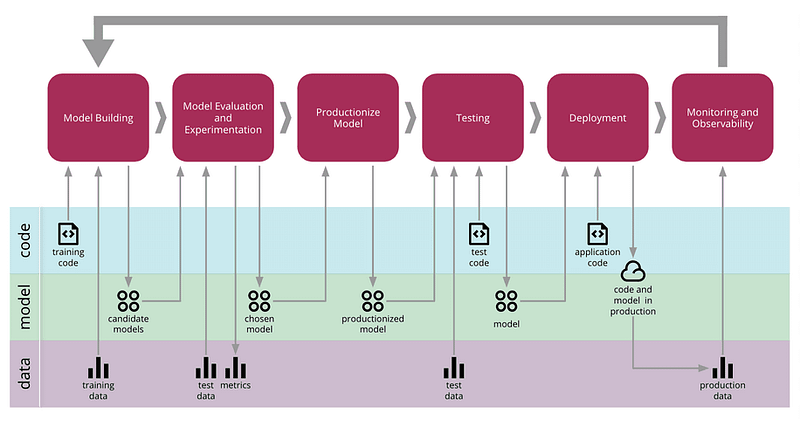
Monitoring in ML Lifecycle — Figure source
Learn more 🎓
If you are interested to continue learning about monitoring of machine learning systems and MLOps in general, we share a few references below:
- Applied ML is a repository with a list of curated papers, articles, and blogs on data science & machine learning in production
- This article provides a comprehensive guide covering the complexity, importance of monitoring, and providing practical guidance on monitoring ML Systems.
- Continuous Integration is a software development practice of testing each change made to the code base automatically. This helps to detect the granular change that causes the tests to fail and enable the team to fix the integration problem early in the development cycle. In this video, learn more about how this practice can be applied for machine learning projects with tools such as Continuous Machine Learning (CML).
Big Bird for longer sequences
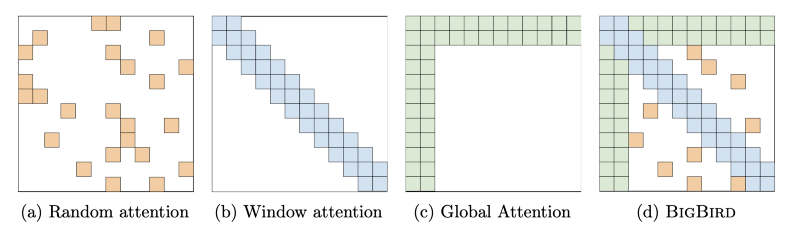
The figure shows how Big Bird is able to hold the properties of three different attention mechanisms — Zaheer et al. (2020).
It is well known that Transformer based language models like BERT that rely on self-attention mechanism have a quadratic complexity in the number of tokens. Big Bird is a Transformer based model that aims to more effectively support NLP tasks requiring longer contexts by reducing the complexity of the attention mechanism to linear complexity in the number of tokens.
Why is this important? Processing and extracting valuable information from longer sequences is useful when dealing with long text such as books or scholarly articles. In such cases, we would like to minimize the memory footprint which is why reducing the complexity of the attention mechanism component in the language modeling architecture is important. Reducing the complexity is important as is the case for keeping the original properties of the model. The way this is achieved by Big Bird is through viewing self-attention as a fully connected graph and taking advantage of graph properties, specifically increasing how fast the flow of information happens between pairs of nodes. The authors claim that with the new proposed sparse attention, their model can handle “sequences with length of up to 8x of what was previously possible using similar hardware.”
Learn more 🎓
If you want to get better intuitions about the design choices of Big Bird, Yannic Kilcher provides an accessible explanation of Big Bird in this video.
Breaking into deep learning and NLP
One of the biggest changes this year that a lot of us needed to get used to due to the pandemic is this idea of learning remotely. This has also opened many learning opportunities for not only localized communities but also learners all around the world. In this portion of the newsletter, we share a few resources for those looking to break into deep learning or NLP.
Dive into Deep Learning Study group
This past weekend, dair.ai hosted the first session of the new deep learning study group. The session lasted more than one hour and focused on a broad overview of deep learning. More than 150 learners joined the live session from all over the world (find the recording here). The second session will aim to cover a few preliminaries such as probability and statistics, linear algebra, and other important concepts important for studying and applying deep learning concepts. If you are interested to join upcoming sessions, find out more about this study group here.
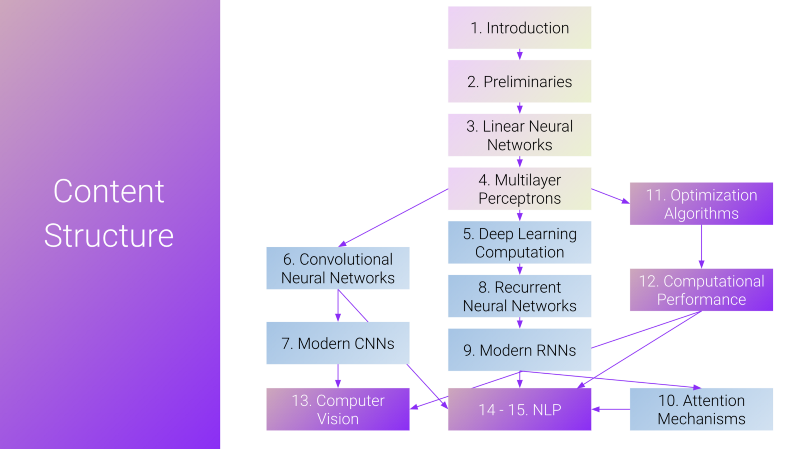
The content structure of the deep learning study program
Breaking into NLP by deeplearning.ai
Recently, deeplearning.ai released a new specialization focused on NLP. In a recent panel discussion, Andrew Ng was joined by some experts in the field and discussed interesting topics around “breaking into NLP”. The discussion emphasized on trends in NLP and other advice for students of ML and NLP. Elvis wrote a detailed twitter thread about his takeaways of this session, which range from advice to students to interesting research areas and trends in NLP.
LxMLS Lisbon Machine Learning School
The 2020 LxMLS at Instituto Superior Técnico (IST) took place remotely and all lectures were delivered and publicly streamed online. This is considered one of the best programs in Europe to learn about NLP. Several well-known NLP researchers either attended the program in the past or taught in the program. The recent 10th edition of LxMLS included lectures around NLP topics that ranged from preliminaries to modeling sequential data to applying reinforcement learning in the context of NLP. You can find all the lecture recordings on YouTube.
Deep Learning for Computer Vision
Justin Johnson recently announced that they published all video lectures for their new course on Deep Learning for Computer Vision. According to Justin, this course is an evolution of the CS231n course which was delivered at Stanford by him and others. All the content has been refreshed and lectures now include new topics like 3D vision and Transformers applied in the context of computer vision.
Stay informed 🎯
NLP with Friends is an effort to bring students together to discuss interesting research topics related to NLP. Talks are being hosted weekly on Zoom so you can join the sessions remotely.
Learn more 🎓
Here are some NLP-related competitions and workshops we found useful for you to get involved:
- Contradictory, My Dear Watson: Detecting contradiction and entailment in multilingual text using TPUs. This is a playground type competition based on Natural Language Inferencing (NLI) to determine whether pairs of sentences are related. Participants are challenged to create an NLI model from a dataset including text from 15 different languages.
- Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) **provides a forum and data challenge for promoting multilingual research on detecting problematic content. This year the dataset contains 10K annotated tweets from English, German, and Hindi. The focus of the first subtask is to detect hate, offensive, or profane content in the text. The second subtask is more granular to discriminate and classify the respective type. There is a separate sub-track for Dravidian CodeMix (this was shared in our previous newsletter). The deadline for registration is 30 August 2020.
Why you should do NLP Beyond English
In this recent article, Sebastian Ruder makes an argument for why NLP researchers should focus on languages other than English. To begin with, the blog highlights the huge disparity in online data availability between a handful of high-resource languages (including English) and thousands of other languages. The main discussion is centered around the factors that should encourage more research initiatives in other languages as seen from societal, linguistic, machine learning, cultural and normative, and cognitive perspectives.
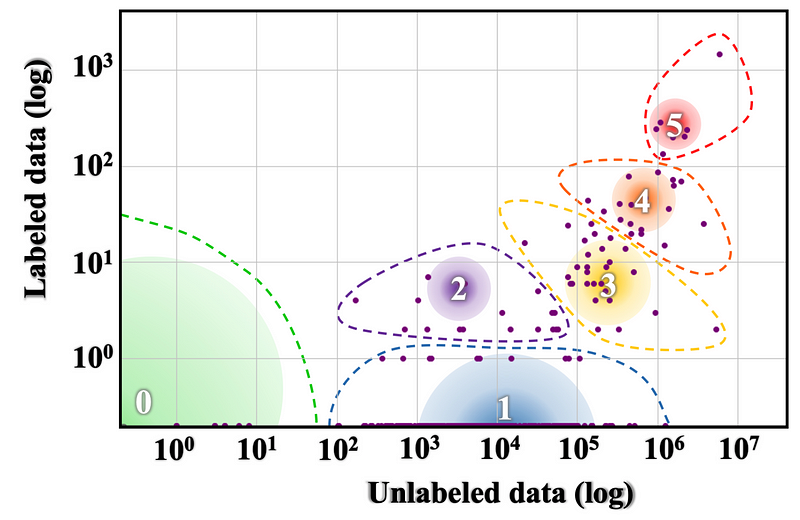
Language resource distribution of Joshi et al. (2020). Groups 5 and 4 are languages that are well studied while other groups are largely neglected.
One of the talking points is how English-specific models can limit access to open knowledge due to language barriers, cause bias and discrimination against non-English speakers, as well as endanger a language itself in extreme cases. From a linguistic perspective, many resource-rich languages are morphologically poor, meaning we are missing out on generalization capacity by ignoring other languages which can help models learn this information. Considering things from an ML viewpoint, given that most of the languages have limited data available, throwing a lot of data and hoping for the best outcome cannot be the solution. Approaches that are language-aware and can work with few data may have more likelihood of making a real impact. The blog ends with a call-to-action for future research, including the creation of datasets in multiple languages, evaluating an approach across several languages, and following the Bender Rule.
CoVoST V2: Expanding the largest, most diverse multilingual speech-to-text translation data set
Multilingual datasets are beneficial for enabling ways to better test the robustness of machine learning models that aim to address either language modeling or speech recognition. One area of machine learning that could benefit from such type of data is applications in multilingual speech translation. These types of models can help with removing barriers that are very common with online communication tools, where users come from different cultures. It can also help to enable richer conversations among people that are not proficient in certain languages and amplify their voices online. There is a range of other possible ways to use the dataset and applications that depend on it such as building smart composers or more accessible search tools.
Facebook AI released CoVoST V2 which they consider the largest multilingual speech-to-text dataset available to date. The new version of the dataset adds new languages to the previous first version with a total of 2900 hours of speech. Before releasing it, researchers made sure to check for data quality and that it varied across dimensions such as age, gender, and accents. With this new dataset, the hope is that it fosters research for multilingual speech translation and enables a single model to support many language pairs, especially for pairs with less data.
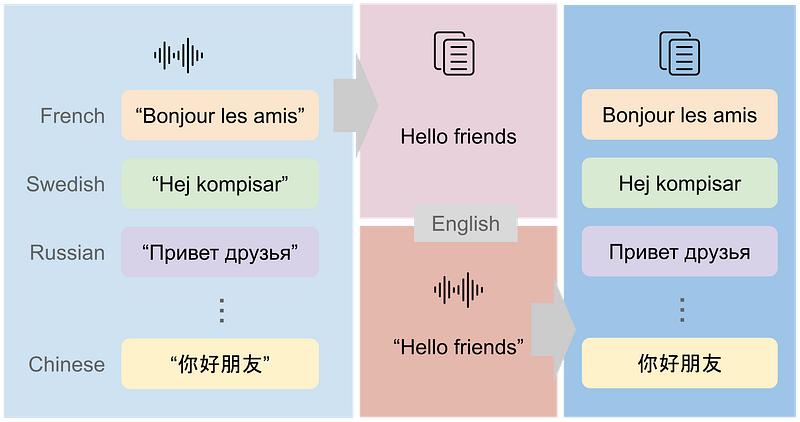
Source: Facebook AI Blog
The future of conversational AI systems
In a recent panel discussion about how much should conversational AI developers know about ML and linguistics, Vladimir Vlasov, Emily Bender, Thomas Wolf, and Anna Rogers share their views and concerns. The overall consensus is that current language models are capable of achieving remarkable results in some tasks but experts believe that we are not testing the models for the right things in terms of really wanting to understand how well the models actually do at language modeling. Just because a pretrained language model can already be used to build creative applications it doesn’t imply that we have solved language modeling.
Other interesting topics of discussion were ways to improve the evaluation of language models and better understand what the models are really learning. At the current moment, it’s really difficult to tell what aspects of language these models are actually capturing. This becomes even more difficult as more of these pretrained models, relying on different architectures and built on different objectives, keep rapidly emerging. The call to action is that we focus more on standardizing methods for evaluation and deal with the question of what these models are really capturing and how to avoid their harmful use from a practical standpoint such as when building conversational AI systems.
If you want more takeaways, feel free to check out this Twitter thread or check the panel discussion directly.
Noteworthy Mentions ⭐️
Understanding and Implementing SimCLR in PyTorch — An ELI5 Guide
Previously, we covered the SimCLR pre-training framework used for learning rich visual representations and achieving performance improvements over methods for self-supervised and semi-supervised learning on ImageNet. SimCLR is based on contrastive learning which attempts to train a model to distinguish between similar and dissimilar things. Marcin recently wrote an extensive article providing a code walkthrough and explanation of the framework using PyTorch.
The Lottery Ticket Hypothesis
Is it possible to find subnetworks that perform similar to the original neural network on specific tasks? Using pruning techniques, current research argues that indeed this is possible, stating that the way the models are initialized has a lot to do with achieving this effect. Learn more about this area of research in this short summary.
NodeNet: A Graph Regularised Neural Network for Node Classification
Graph-based learning algorithms utilize the data and related information effectively to build superior models. Neural Graph Learning (NGL) is one such technique that utilizes a traditional machine learning algorithm with a modified loss function to leverage the edges in the graph structure. This work proposes a model using NGL — NodeNet, to solve the node classification task for citation graphs. The authors claim that NodeNet achieves state of the art results on papers with code for Pubmed and Citeseer datasets.
When are Contextual Embeddings Worth Using?
In this blog post, Viktor Karlsson summarizes a paper that discusses situations when it might actually make sense to use contextual embeddings (e.g., BERT) and when it may not be worth it.
Simple and Efficient Deep Learning for Natural Language Processing, with Moshe Wasserblat, Intel AI
In this talk, Moshe Wasserblat, Intel AI, presents simple and efficient deep learning methods for NLP. The speaker provides background on popular optimization vectors for NLP and great tips on distilling BERT for vastly faster inference with a sustainable accuracy penalty. Results on the dair.ai emotion dataset and other popular benchmarks were also discussed.
DeText: A deep NLP framework for intelligent text understanding
DeText is a framework for leveraging deep learning-based NLP technologies like BERT for text understanding. DeText offers features that make it feasible to use large models that require heavy computation costs out of the box such as BERT. With this framework, it is possible to implement neural ranking for search and recommender systems.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.