

dair.ai updates
- We have added better categorization for all TL;DR and summaries included in the NLP paper summaries repo.
- All issues and translations of the NLP Newsletter are being maintained here.
- This week we also introduced Notebooks, a hub for easily sharing data science notebooks with the community at large. If you have any notebooks that you would love to share with the community get in touch.
- We shared a tutorial that provides steps on how to perform multiclass emotion classification using TextVectorization — an experimental feature in TensorFlow 2.1.0 that helps to manage text in a neural network.
Research and Publications 📙
Surveys on Contextual Embeddings and Language Models
This paper provides a light survey of approaches for learning contextual embeddings. It also includes a review of its applications for transfer learning, model compression methods, and model analyses. Another report involves a summary of methods used to improve Transformer based language models. Here is also another comprehensive survey on pretrained language models which provides a taxonomy of NLP pretrained models.
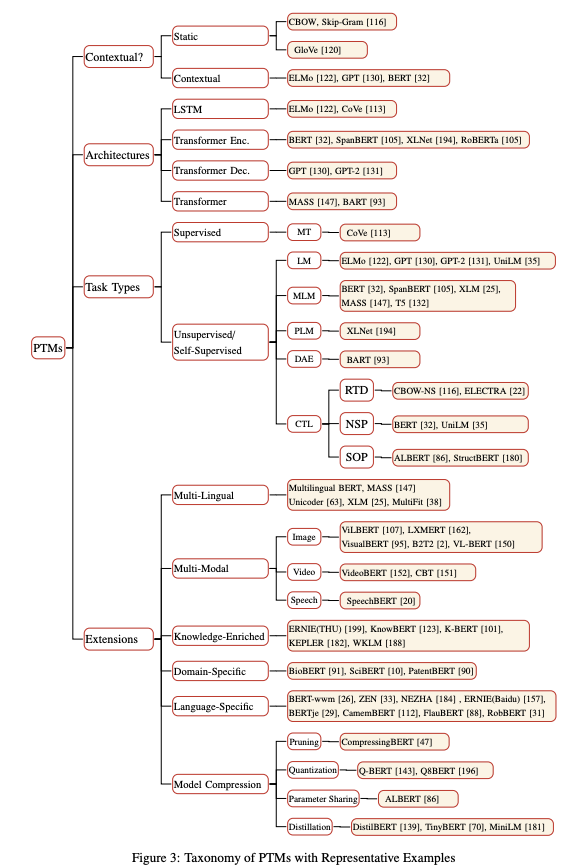
Visualizing Neural Networks with the Grand Tour
The Grand Tour is a linear approach (differs from the non-linear methods such as t-SNE) that projects a high-dimensional dataset to two dimensions. In a new Distill article, Li et al. (2020) propose to use the Grand Tour capabilities to visualize the behavior of a neural network as it trains. Behaviors of interest in the analysis include weight changes and how it affects the training process, layer-to-layer communication in the neural network, the effect of adversarial examples when they are presented to the neural network.
Source: Distill
Meta-Learning Initializations for Low-Resource Drug Discovery
It has been widely reported that meta-learning can enable the application of deep learning to improve on few-shot learning benchmarks. This is particularly useful when you have situations where there is limited data as is typically the case in drug discovery. A recent work applied a meta-learning approach called Model-Agnostic-Meta-Learning (MAML) and other variants to predict chemical properties and activities in low-resource settings. Results show that the meta-learning approaches perform comparably to multi-task pre-training baselines.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
An exciting work involving researchers from UC Berkeley, Google Research, and UC San Diego present a method (NeRF) for synthesizing novel views of complex scenes. Using a collection of RGB image inputs, the model takes 5D coordinates (spatial location and direction), train a fully-connected DNN to optimize a continuous volumetric scene function, and outputs the volume density and view-dependent emitted RGB radiance for that location. The output values are composed together along a camera ray and rendered as pixels. These rendered differentiable outputs are used to optimize the scene representations by minimizing the error of renderings all camera rays from RGB images. Compared to other top-performing approaches for view synthesis, NeRF is qualitatively and quantitatively better and addresses inconsistencies in rendering such as lack of fine details and unwanted flickering artifacts.

Introducing Dreamer: Scalable Reinforcement Learning Using World Models
Dreamer is a reinforcement learning (RL) agent proposed to address some limitations (e.g. shortsightedness and computational inefficiency) present in model-free and model-based agents for solving difficult tasks. This RL agent, proposed by DeepMind and Google AI researchers, is trained to model the world that also provides the ability to learn long-sighted behaviors via backpropagation using the model predictions. SoTA results are achieved on 20 continuous control tasks based on the provided image inputs. In addition, the model is data-efficient and makes predictions in parallel, making it more computationally efficient. The three tasks involved in training the agent that achieve the different goals are summarized in the figure below:
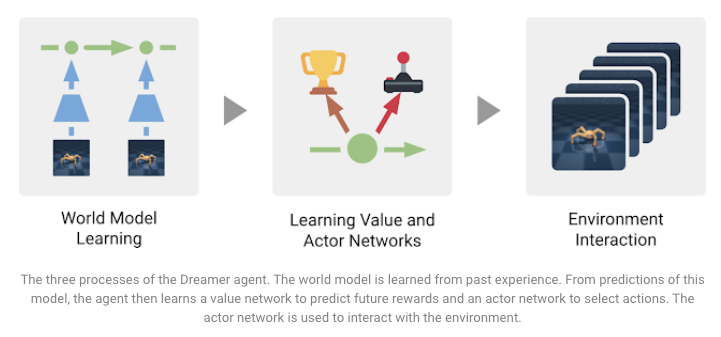
Source: Google AI Blog
Creativity, Ethics, and Society 🌎
COVID-19 Open Research Dataset (CORD-19)
In an effort to encourage the use of AI to fight COVID-19, the Allen Institute of AI published the COVID-19 Open Research Dataset (CORD-19), a free and open resource to promote global research collaboration. The dataset contains thousands of scholarly articles that can allow NLP inspired research to obtain insights that can help in the fight against COVID-19.
SECNLP: A survey of embeddings in clinical natural language processing
SECNLP is a survey paper that includes a detailed overview of a wide variety of NLP methods and techniques applied in the clinical domain. The overview emphasizes mostly on embedding methods, problems/challenges addressed with embeddings, and discussion of future research directions.
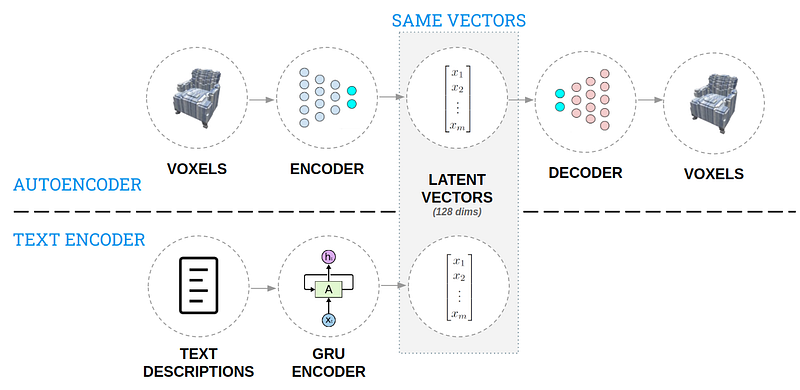
AI for 3D Generative Design
This article covers an approach that was used to generate 3D objects from natural language descriptions. The idea is to create a solution that allows a designer to quickly reiterate in the design process and be able to explore more broadly the design space. After creating a knowledge base of the design space consisting of 3D models and text descriptions, two autoencoders (see figure below) were used to encode that knowledge in a way that can be interacted with intuitively. The model put together can then accept a text description and generate a 3D design, try it out in this demo.
Tools and Datasets ⚙️
Stanza — A Python NLP Library for Many Human Languages
The Stanford NLP Group releases Stanza (formerly StanfordNLP), a Python NLP library that provides out-of-the-box text analytic tools for more than 70 languages. Capabilities include tokenization, multi-word token expansion, lemmatization, POS, NER, and much more. The tool is built on top of the PyTorch library with support for using GPU and pretrained neural models. Explosion has also built a wrapper around Stanza that allows you to interact with Stanza models as a spaCy pipeline.
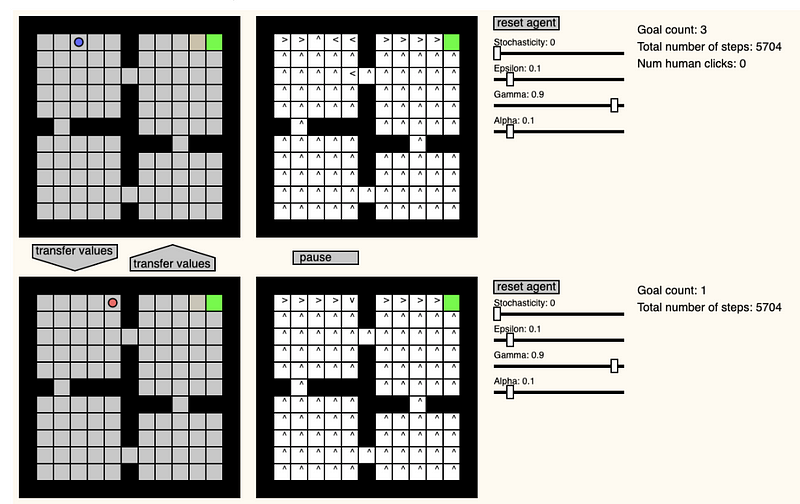
GridWorld Playground
Pablo Castro created an interesting website that provides a playground for creating a Grid World environment to observe and test how a reinforcement learning agent tries to solve the Grid World. Some features include the ability to change the learning/environment parameters in real-time, change the position of the agent, and transfer values between two agents.
X-Stance: A Multilingual Multi-Target Dataset for Stance Detection
Stance detection is the extraction of a subject’s reaction made to an actor’s claim which can be used for fake news assessment. Jannis Vamvas and Rico Sennrich recently published a large-scale stance detection dataset consisting of written text by electoral candidates in Switzerland. Multiple languages are available in the texts which could potentially lead to cross-lingual evaluations on the task of stance detection. The authors also propose the use of a multilingual BERT that achieves satisfactory performance on zero-shot cross-lingual and cross-target transfer. Learning across targets, in particular, is a challenging task so the authors used a simple technique involving standardized targets to train a single model on all the issues at once.
Create interactive textual heatmaps for Jupyter notebooks
Andreas Madsen created a Python library called TextualHeatMap that can be used to render visualizations that help to understand what parts of a sentence the model is using to predict the next word such as in language models.

Source: textualheatmap
Articles and Blog posts ✍️
How to generate text: using different decoding methods for language generation with Transformers
HuggingFace published an article explaining the different methods used for language generation in particular for Transformer based approaches. Among those techniques discussed are greedy search, beam search, sampling, top-k sampling, and top-p (nucleus) sampling. There are many articles like this out there but the authors spent more time explaining the practical side of these methods and how they can be applied via code snippets.
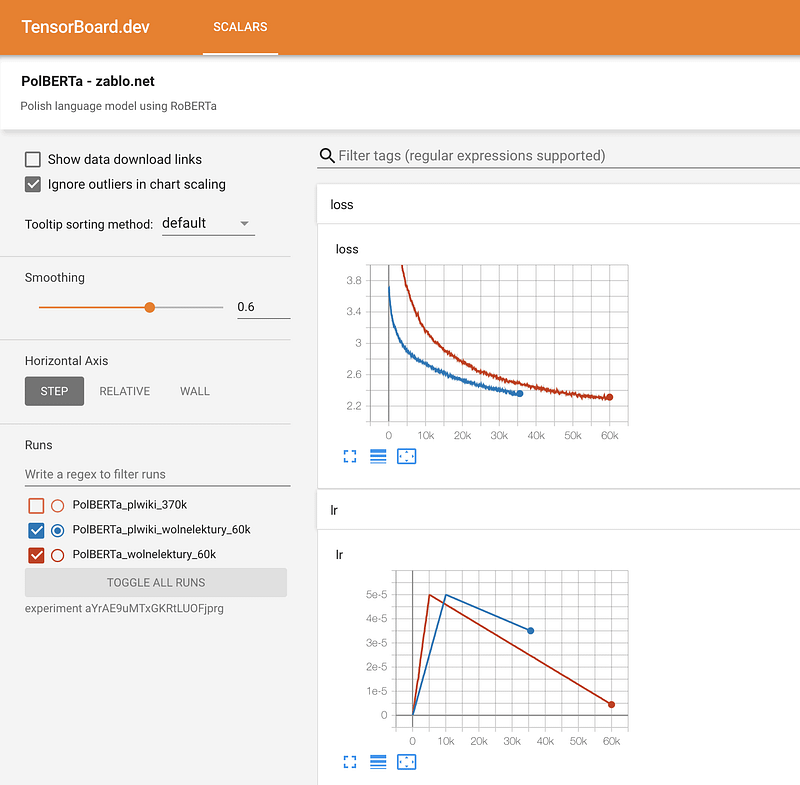
Training RoBERTa from Scratch — The Missing Guide
Motivated by the lack of a comprehensive guide for training a BERT-like language model from scratch using the Transformer’s library, Marcin Zablocki shares this detailed tutorial. The guide shows how to train a transformer language model for the Polish language with tips on what common mistakes to avoid, data preparation, pretraining configuration, tokenization, training, monitoring training process, and sharing the model.
Education 🎓
Getting started with JAX (MLPs, CNNs & RNNs)
Robert Lange recently published a comprehensive tutorial on how to train a GRU-RNN with JAX. In our previous newsletter, we also shared a couple of resources related to JAX.
NLP for Developers: Word Embeddings
Rachael Tatman published the first episode of a new series called NLP for Developers that will cover best practices on how to apply a wide range of NLP methods. The first episode includes an introduction to word embedding and how they are used and other common issues to avoid when applying them.
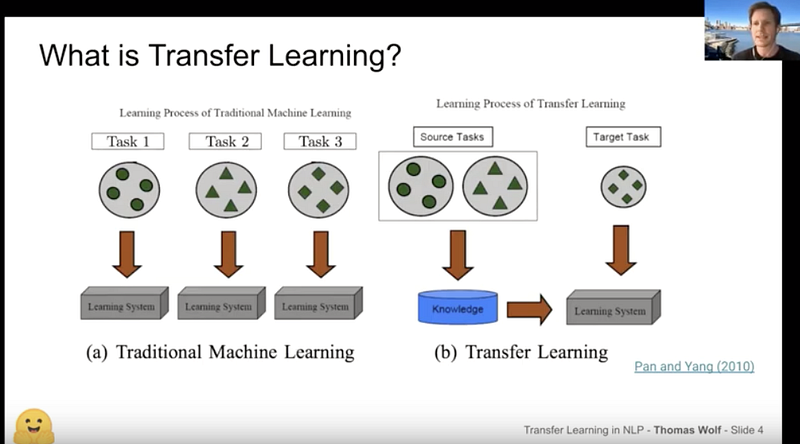
Thomas Wolf: An Introduction to Transfer Learning and HuggingFace
Thomas Wolf presented his talk on Transfer Learning for the NLP Zurich meetup providing a great introduction to transfer learning in NLP. The talk includes an overview of recent NLP breakthroughs and an introduction to Transformers and Tokenizers, two of the most popular libraries released by the HuggingFace team and contributors.
Noteworthy Mentions ⭐️
Did you know that Google Sheets provides a free translation feature? Amit Chaudhary shares an article that shows how to leverage the feature for back translation which is useful for augmenting your limited text corpus for NLP.
New York NLP will be hosting an online meetup for a talk titled “Using Wikipedia and Wikidata for NLP” where the presenter will talk about how to leverage Wikipedia for different NLP projects and use cases.
Lavanya Shukla wrote this nice tutorial on how to use PyTorch Lightning to optimize hyperparameters of a neural network while at the same time taking advantage of the simple code structures/styles provided in PyTorch Lightning. The resulting model and its performance using different hyper-parameters are visualized using the results produced by the WandB logger which can be provided as a logger parameter to a trainer object.
A group of researchers published a study investigating more in detail why batch normalization (BN) tends to degrade performance in Transformer based methods applied to different NLP tasks. Based on those findings, the authors propose a new approach called power normalization to deal with issues found in BN. The method outperforms both BN and layer normalization (commonly used these days) on a variety of NLP tasks.
This blog post contains a long list of books to get you started with ML.
If you have any datasets, projects, blog posts, tutorials, or papers that you wish to share in the next iteration of the NLP Newsletter, please free to reach out to me at ellfae@gmail.com or send me a message on Twitter.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.