

dair.ai sitesinden güncellemeler
- Tüm TL;DR ve NLP bildiri özetlerini içeren repo’ya daha iyi bir kategorizasyon ekledik.
- NLP Haber Bülteni’nin tüm sayı ve çevirileri artık burada sürdürülecek.
- Bu hafta ayrıca, veri bilimi notebook‘larını genel olarak toplulukla kolayca paylaşmaya yönelik bir merkez olan Notebooks‘u açtık. Toplulukla paylaşmak istediğiniz notebook‘larınız varsa bizimle iletişime geçebilirsiniz.
- Sinir ağlarında (İng. neural networks) metinlerle çalışmayı kolaylaştıran TensorFlow 2.1.0’da deneysel yeni bir özellik olan TextVectorization‘ı kullanarak çok sınıflı duygu sınıflandırma (İng. multiclass emotion classification) yapmanın adımlarını anlatan bir tutorial paylaştık.
Araştırma ve Yayınlar 📙
Bağlamsal Gömmeler ve Dil Modelleri İncelemeleri
Bu bildiri bağlamsal gömme (İng. contextual embedding) öğrenmesine yönelik yaklaşımların kolay anlaşılır bir incelemesini sunmaktadır. Bildiri ayrıca, öğrenme aktarımı (İng. transfer learning), model sıkıştırma yöntemleri (İng. model compression methods) ve model analizinde kendi denemelerinin değerlendirmelerini de içeriyor. Buradaki bir başka rapor ise Transformatör (İng. transformer) tabanlı dil modellerini iyileştirmek için kullanılan yöntemlerin bir özetini içeriyor. Ayrıca, NLP’nin ön-eğitime tabi tutulmuş (İng. pre-trained) modellerinin taksonimisine ilişkin bir başka kapsamlı inceleme burada bulunabilir.
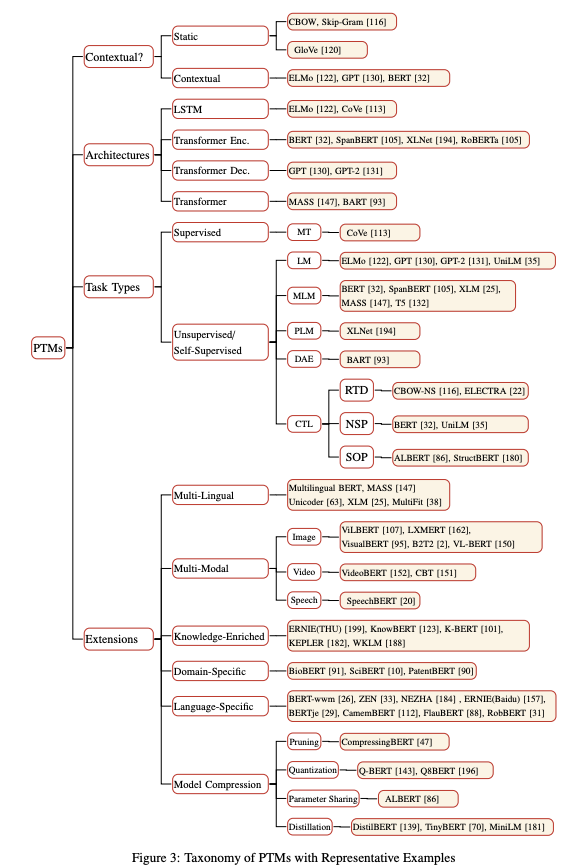
The Grand Tour ile Sinir Ağları Görselleştirmesi
The Grand Tour yüksek-boyutlu bir veri kümesini iki boyuta yansıtan doğrusal bir yaklaşımdır (t-SNE gibi doğrusal olmayan yöntemlerden farklı olarak). Distill’de yer alan yeni bir makale (Li et al. 2020)’de bir sinir ağının eğitilirkenki davranışlarını görselleştirmek için Grand Tour’un yeteneklerinin kullanılabileceği öneriliyor. Bu davranışlar arasında; ağırlık (İng. weight) değişimleri ve bu değişimlerin eğitim sürecini nasıl etkilediği, bir sinir ağında katmandan katmana iletişim ve bir sinir ağına karşıt örnekler verildiğinde oluşan etkiler bulunmaktadır.
Kaynak: Distill
Düşük Kaynaklı İlaç Keşfi için Meta-Öğrenme
Meta-öğrenmenin (İng. meta-learning), az-örnekli öğrenme (İng. few-shot learning) başarımı açısından derin öğrenme uygulamalarında iyileştirme sağlayabileceği birçok çalışmada raporlanmaktadır. Bu da özellikle ilaç keşfinde olduğu gibi sınırlı veri bulunan durumlarda meta-öğrenmenin çok kullanışlı olabileceğini gösteriyor. Yakında zamanda yapılan bu çalışmada, Model-Agnostic-Meta-Learning adı verilen bir meta-öğrenme yaklaşımı ve benzerleri az kaynağın/örneklemin bulunduğu koşullarda kimsayal özelliklerin ve davranışların tahmin edilebilmesi için denendi. Sonuçlar gösteriyor ki; meta-öğrenme yaklaşımı çok-görevli (İng. multi-task) ön-eğitime tabi tutulmuş modellerle karşılaştırılabilir bir performans ortaya koyuyor.
NeRF: Sahne Gösteriminde Görünüm Sentezi için Neural Radiance Fields
UC Berkeley, Google Research ve UC San Diego’dan araştırmacıların yaptığı heyecan verici bir çalışma, karmaşık sahnelerin yeni görünümlerini sentezlemek için bir yöntem ([NeRF] (http://www.matthewtancik.com/nerf)) sunuyor. RGB görsel girdilerinin bir koleksiyonunu kullanan model, 5-boyutlu koordinatlar alıyor, optimize bir sürekli hacimsel sahne fonksiyonu (İng. continuous volumetric scene function) ortaya çıkarmak için fully-connected bir DNN’i eğitiyor ve berlirli bir konumla ilgili hacim yoğunluğu ve görünüm bağımlı yayılan RGB ışıması çıktıları sağlıyor. Çıkış değerleri bir kamera ışını boyunca bir araya getiriliyor ve piksel olarak oluşturuluyor (render ediliyor). Bu farklılaştırılabilir çıktılar RGB görsellerden elde edilen tüm kamera ışınlarındaki hataların minimize edilmesiyle oluşan sahne gösterimlerinin optimize edilmesinde kullanılıyor. Görünüm sentezlemede en iyi performansı gösteren alternatifleriyle kıyaslandığında NeRF; kalitatif ve kantitatif açıdan daha iyi görünüyor ve yeterli detayın olmadığı görsellerdeki tutarsızlıkları ve istenmeyen yapay titremeleri giderebiliyor.

Dreamer’a Giriş: Dünya Modellerini Kullanarak Ölçeklenebilir Reinforcement (Takviyeli) Öğrenme
Dreamer, zorlu görevlerin çözümünde karşılaşılan bazı kısıtları aşmak için sunulan ücretsiz ve model tabanlı Takviyeli Öğrenme (RL) (İng. reinforcement learning) ajanıdır. DeepMind ve Google AI araştırmacıları tarafından önerilen bu RL ajanı, model tahminlerini kullanan geri yayılım (İng. backpropagation) aracılığı ile ileri görüşlü davranışları da öğrenebilen bir dünya modellemek için eğitildi. SoTA sonuçları, verilen görsel girdilere dayalı 20 sürekli kontrol görevleri üzerinden elde ediliyor. Ek olarak, modelin veri-efektif olduğu görülüyor ve tahminlerini onu hesaplama-efektif hale getirecek şekilde paralel yapabiliyor. Farklı hedefleri başarabilen bir ajan eğitmekle ilgili üç görev aşağıdaki gösterimde özetlenmiştir:
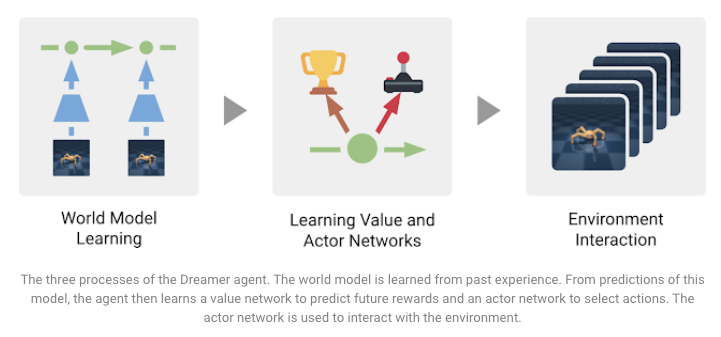
Kaynak: Google AI Blog
Yaratıcılık, Etik ve Toplum 🌎
COVID-19 Open Research Dataset (CORD-19)
COVID-19 ile mücadelede, dünyanın her bir yanından araştırmacıların birlik olmasını ve AI kullanımını teşvik etmek amacıyla Allen Institute of AI, ücretsiz ve açık kaynaklı olan COVID-19 Open Research Dataset (CORD-19) çalışmasını yayımladı. Veri seti, NLP’den ilham alan çalışmalardan ve COVID-19 ile mücadelede yardımcı olabilecek binlerce bilimsel makaleden oluşmaktadır.
SECNLP: Klinik doğal dil işlemede gömme metotları üzerine inceleme
SECNLP tıp alanında geniş ölçekte kullanılan NLP tekniklerine detaylı genel bakış sağlayan bir inceleme bildirisidir. Çalışma çoğunlukla gömme (İng. embedding) metotları, bu metotların zorlukları/problemleri ve gelecekteki araştırma yönlerinin değerlendirilmesini vurgulamaktadır.
3B Üretken Tasarım için Yapay Zeka (AI)
Bu yazı, doğal dil betimlemelerinden 3 boyutlu nesneleri oluşturmakta kullanılan bir yaklaşımı içermektedir. Yaklaşımın ana fikri, tasarımcının tasarım sürecini hızlı bir şekilde yinelemesine ve tasarım alanını daha geniş keşfedebilmesine olanak sağlamaktır. 3B modeller ve metin betimlemelerinden oluşan tasarım alanına dair bir bilgi tabanı oluşturulduktan sonra iki adet otokodlayıcı (İng. autoencoder) (aşağıdaki şekilde görülebilir) bu bilgiyi sezgisel bir etkileşime girilebilecek şekilde kodlamaktadır. Bir araya getirilen model, bir betimleme metni alıp üç boyutlu bir tasarım üretebilmektedir. Burada siz de deneyebilirsiniz.
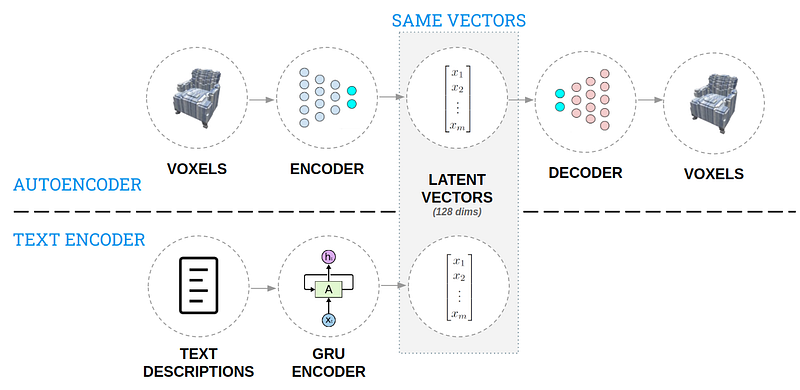
Araçlar ve Veri Setleri ⚙️
Stanza — Birçok İnsan Dili için Python NLP Kütüphanesi
Stanford NLP Group, 70’ten fazla dil için ezber bozan metin analiz araçları sağlayan bir Python NLP kütüphanesi, Stanza‘yı yayımladı. Kütüphane, tokenizasyon (İng. tokenization), çok-kelimeli token genişletme, kelime kökü bulma, cümleyi öğelerine ayırma (POS), varlık ismi tanıma (NER) (İng. named entity recognition) ve daha birçok NLP işlemi yapabilmeye olanak sağlamaktadır. GPU’nun ve ön-eğitime tabi tutulmuş sinir ağı modellerinin kullanımına destek veren PyTorch üzerine inşa edilmiştir. Diğer yandan, Explosion da Stanza modelleri ile spaCy işlem dizisi gibi etkileşime geçilebilmeyi sağlayan bir modül geliştirdi.
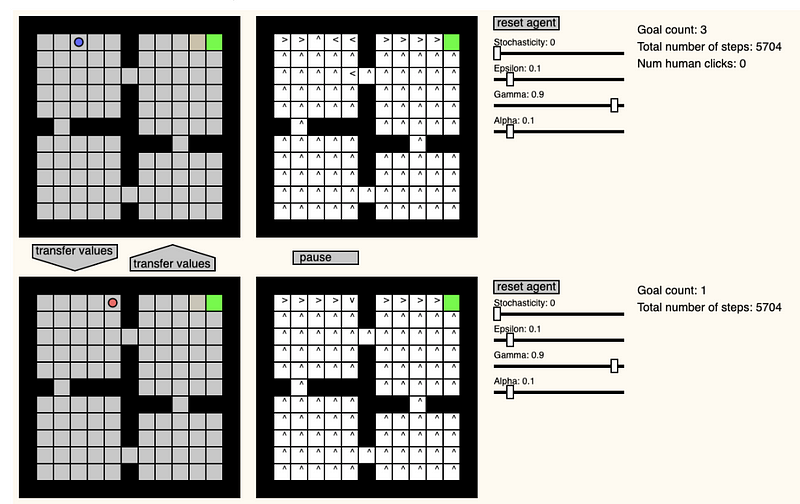
GridWorld Playground
Pablo Castro, kareli bir oyun alanı ortamı oluşturulabilecek ilginç bir internet sitesi geliştirdi. Oluşturulan ortamda takviyeli öğrenme ajanının GridWorld oyununu nasıl çözdüğü gözlemlenebilmektedir. Oyun esnasında gerçek zamanlı olarak ajanın pozisyonu, öğrenme/ortam parametreleri değiştirilebilir ve 2 ajan arasında değerler transfer edilebilir.
X-Stance: Duruş Tespiti için Çok Dilli Çok Hedefli Veri Seti
Duruş tespiti (İng. stance detection), bir aktörün herhangi bir konu hakkındaki iddiası karşısında deneğin verdiği tepkinin belirlenmesidir. Sahte haberlerin değerlendirilmesinde kullanılması amaçlanmaktadır. Jannis Vamvas ve Rico Sennrich, İsviçre’deki seçim adaylarının yazılı metinlerinden oluşan büyük ölçekli bir duruş tespit veri setini kısa bir süre önce yayımladılar. Metinler çok dilli bir şekilde kullanıma hazır haldeler. Bu sayede duruş tespiti görevinde diller-arası değerlendirmelere olanak sağlanabilecek. Yazarlar, çok dilli/hedefli doğal dil işleme problemlerinde ve eğitim veri setinde olmayan nesneleri anlamlandırmada tatmin edici performanslara ulaşan çok dilli BERT modelinin kullanılmasını da önermektedir. Özellikle farklı hedeflerin öğrenilmesi zorlayıcı bir görevdir. Bu yüzden yazarlar basitleştirilmiş hedefler ile veri setindeki bütün sorunların aynı anda eğitileceği sade bir model kullanmışlar.
Jupyter notebookları için bir metne ait interaktif sıcaklık haritaları oluşturun
Andread Madsen, dil modellerinde, modelin bir sonraki kelimeyi tahmin ederken cümlenin hangi kısımlarını kullandığını anlamaya yardımcı olacak, TextualHeatMap adında bir kütüphane geliştirdi. TextualHeatMap ile üzerinde çalışılan metne ait intraktif sıcaklık haritaları görselleştirilebilmektedir.

Kaynak: textualheatmap
Makaleler ve Blog gönderileri ✍️
Nasıl metin üretilir: Transformers Kütüphanesi ile dil üretmek için farklı kod çözme metotlarının kullanımı
Huggingface, özellikle transformatör tabanlı dil üretiminde kullanılan farklı teknikleri açıklayan bir makale yayımladı. Bahsedilen teknikler arasında açgözlü arama (İng. greedy search), ışın araması (İng. beam search), örnekleme (İng. sampling), en-iyi-k örnekleme (İng. top-k sampling) ve en-iyi-p örnekleme (top-p/nucleus sampling) yöntemleri yer almaktadır. Bu tarz makalelerden oldukça fazla olsa da yazarlar bahsi geçen tekniklerin pratik yönlerini ve kısa kod parçacıkları ile nasıl kullanılacaklarını açıklamada oldukça zaman harcamışlar.
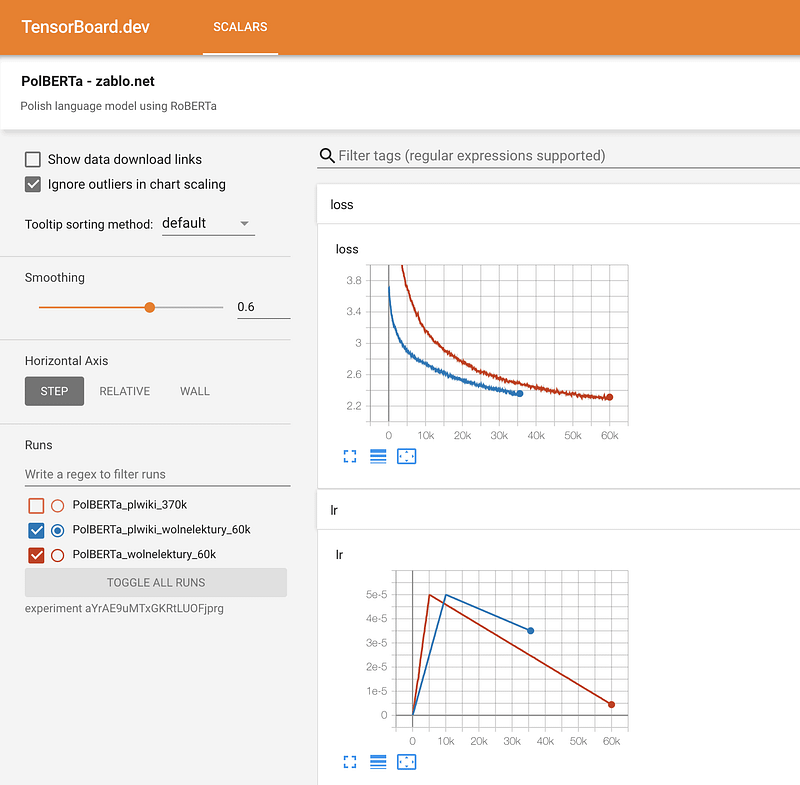
Sıfırdan RoBERTa Eğitimi — Kayıp Rehber
Bert tarzı modellerin Transformatörler kullanılarak sıfırdan eğitilmesine dair geniş kapsamlı rehber kıtlığından ilham alarak harekete geçen Marcin Zablocki, hazırladığı detaylı eğitici rehberini yayımladı. Rehber, sık yapılan hatalardan kaçınmak için ipuçları ile Lehçe dili için bir transformatör tabanlı dil modelinin nasıl eğitileceğini göstermektedir. Veriyi hazırlama, ön-eğitim ayarları, tokenizasyon, eğitim, eğitim sürecinin izlenmesi ve modelin paylaşımı gibi konular üzerinde birçok öneriye de sahip.
Eğitim 🎓
JAX’a Başlangıç (MLP, CNN & RNN)
Robert Lange, kısa bir süre önce JAX kullanarak nasıl GRU-RNN eğitilebileceğini anlattığı rehberini yayımladı. Bir önceki haber bülteni‘nde de JAX ile ilgili kaynakları paylaşmıştık.
Geliştiriciler için NLP: Kelime Gömmeleri
Rachael Tatman Geliştiriciler için NLP (İng. NLP for Developers) adını verdiği ve geniş ölçekli NLP uygulamalarının en iyi yöntemlerini kapsayacak serisinin ilk bölümünü yayımladı. İlk Bölüm, kelime gömmelerini, gömmelerin nasıl kullanıldığını ve gerçeklerken kaçınılması gereken yaygın hataları içermektedir.
Thomas Wolf: HuggingFace ve Öğrenme Aktarımına Giriş
Thomas Wolf, NLP Zürih buluşmasında öğrenme aktarımı üzerine yaptığı konuşmasını NLP’de öğrenme aktarımına çok iyi bir giriş yaparak sundu. Konuşma, NLP alanındaki en güncel büyük gelişmeleri ve HuggingFace takımı ile katkıda bulunan gönüllüler tarafından yayımlanan en popüler iki kütüphane, Transformers ve Tokenizers, üzerine genel bir bakış içermektedir.
Bunlara da bir göz atın ⭐️
Google E-Tablolar’ın ücretsiz tercüme özelliği sağladığını biliyor muydunuz? Amit Chaudhary, paylaştığı makalesinde bu özelliği kullanarak sınırlı metin derleminizi (İng. text corpus) NLP projeleriniz için nasıl çoğaltabileceğinizi göstermiş.
New York NLP, “Vikipedi ve NLP için Wikidata” başlıklı internet üzerinden yapılacak bir buluşmaya ev sahipliği yapacak. Etkinlikte sunucu, Vikipedi’nin farklı NLP projeleri ve kullanım senaryolarında nasıl kaldıraç olarak kullanılabileceği üzerine konuşma yapacak.
Lavanya Shukla PyTorch Lightning’i kullanarak bir sinir ağının hiperparametrelerinin nasıl optimize edileceğini anlatan bu güzel rehberini yazdı. Aynı zamanda PyTorch Lightning tarafından sağlanan sade kod yapılarının avantajlarından da yararlanılabilmektedir. Sonuç model ve farklı hiperparametrelerinin performansı, eğitici objeye parametre gönderilerek çağırılan WandB raporlama aracının ürettikleri ile görselleştirilebilmektedir.
Bir grup araştırmacı, yığın normalizasyonunun (İng. batch normalizaton) farklı NLP görevlerine uygulanmış Transformatör tabanlı modellerde performansı neden kötü yönde etkilediğini detaylı bir şekilde inceledikleri çalışmalarını yayımladılar. Bulunanlara göre, yığın normalizasyonunda ortaya çıkan sorunlara çözüm bulabilmek adına yazarlar, kuvvet normalizasyonu (İng. power normalization) adını verdikleri yeni bir yaklaşım önermektedirler. Bu yöntem, birçok NLP görevinde hem yığın hem de katman normalizasyonuna karşı daha üstün performans göstermektedir.
Bu blog gönderisi makine öğrenmesine başlamak için yararlanabileceğiniz kitapların uzun bir listesini içermektedir.
Eğer NLP Haber Bülteni’nin sonraki sayılarında paylaşmak istediğiniz veri seti, proje, blog, rehber veya bildiri varsa ellfae@gmail.com adresine mail ya da Twitter‘dan mesaj gönderebilirsiniz.
*🔖Gelen kutunuzda NLP Haber Bülteni’nin gelecek sayılarını görmek istiyorsanız buradan abone olabilirsiniz.