

Welcome to the 9th issue of the NLP Newsletter. We hope that you and your loved ones are well and staying safe. This issue includes topics that range from a privacy-preserving NLP tool to interactive tools for searching COVID-19 related papers to an illustrated guide to graph neural networks.
Research and Publications 📙
Neuroevolution of Self-Interpretable Agents
Tang et al. (2020) present an interesting and creative work that aims to evolve an agent to take a fraction of its visual input with the goal to survive a task (e.g. avoid crashing on a curve and dodging fireballs, as seen in the figure below). Using neuroevolution to train self-attention architectures, the authors were able to train reinforcement learning agents to perform different tasks while only allowing a fraction of the input. The benefits of the model include a substantial reduction in the size of parameters, policy interpretability, and enabling the model to attend to only the task-critical visual hints.

Introducing RONEC — the Romanian Named Entity Corpus
RONEC is a named entity corpus for the Romanian language that contains over 26000 entities in ~5000 annotated sentences, belonging to 16 distinct classes. The sentences have been extracted from a copy-right free newspaper, covering several styles. This corpus represents the first initiative in the Romanian language space specifically targeted for named entity recognition. It is available in BIO and CoNLL-U Plus formats, and it is free to use and extend here.
Scaling Laws for Neural Language Models
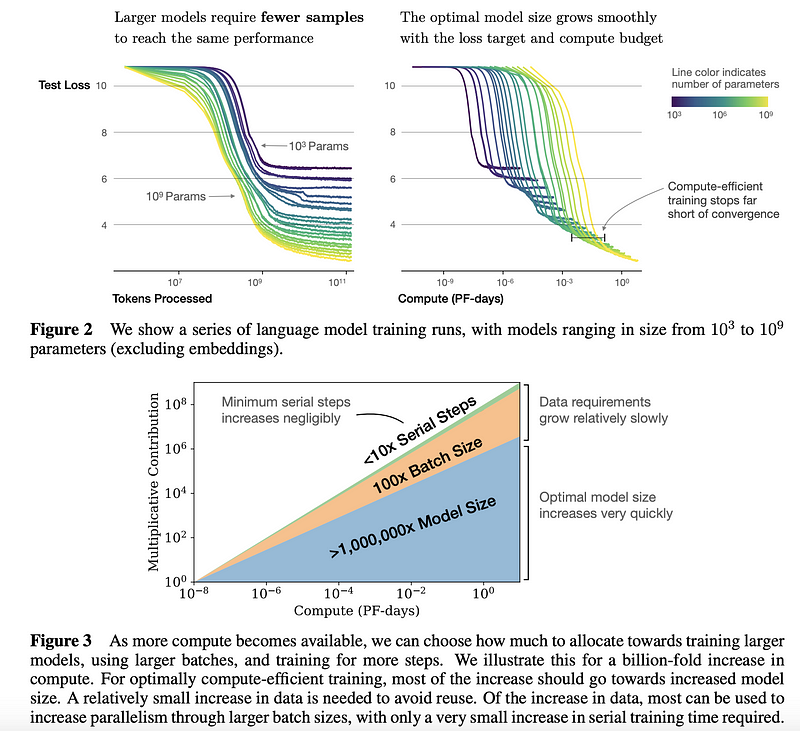
Researchers from John Hopkins and OpenAI have conducted an empirical study to understand the scaling laws for language model performance. This type of study can be used as a guide to making better decisions on how to more effectively use resources. Overall, it was found that larger models are significantly more sample-efficient; if there is limited compute and data, it is better to train a large model with a few steps of training as opposed to training a smaller model until it converges (see results summarized in the figure below). Authors provide more findings and recommendations when training large language models (e.g. Transformers) in the aspects of overfitting, choosing the optimal batch size, fine-tuning, architecture decisions, etc.
Calibration of Pre-trained Transformers
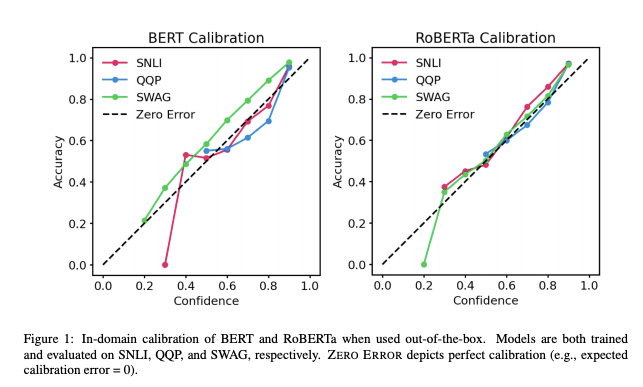
With pre-trained Transformers being used increasingly in real-world applications, it is important to understand how trustworthy their outputs are. Recent work by UT Austin shows BERT and RoBERTa’s posterior probabilities are relatively calibrated (i.e., consistent with empirical outcomes) on three tasks (natural language inference, paraphrase detection, commonsense reasoning) with both in-domain and challenging out-of-domain datasets. Results show that: (1) when used out-of-the-box, pre-trained models are calibrated in-domain; and (2) temperature scaling is effective at further reducing calibration error in-domain, while label smoothing to increase empirical uncertainty helps calibrate posteriors out-of-domain.
Statistical Mechanics of Deep Learning
A recent paper takes a closer look at the connection between physical/mathematical topics and deep learning. The authors aim to discuss deeper topics intersecting statistical mechanics and machine learning with the objective of answering questions that help to understand the theoretical side of deep neural networks and why they have been successful.
Towards an ImageNet Moment for Speech-to-Text
In a new article published in The Gradient, Alexander Veysov explains why they believe that the ImageNet moment for Speech-to-Text (STT) has arrived in the context of the Russian Language. In the last couple of years, researchers have also made this claim about NLP. However, in order to achieve such a moment in STT, Alexander claims that many pieces have to come together, such as making models widely available, minimize computational requirements and improve the accessibility of pre-trained large models.
Creativity, Ethics, and Society 🌎
Browsing and searching COVID-19 related articles
Last week we featured a public dataset called CORD-19 which contains COVID-related papers. Gabriele Sarti wrote an interactive tool that allows you to more efficiently search and browse through these papers by leveraging a SciBERT fine-tuned model.
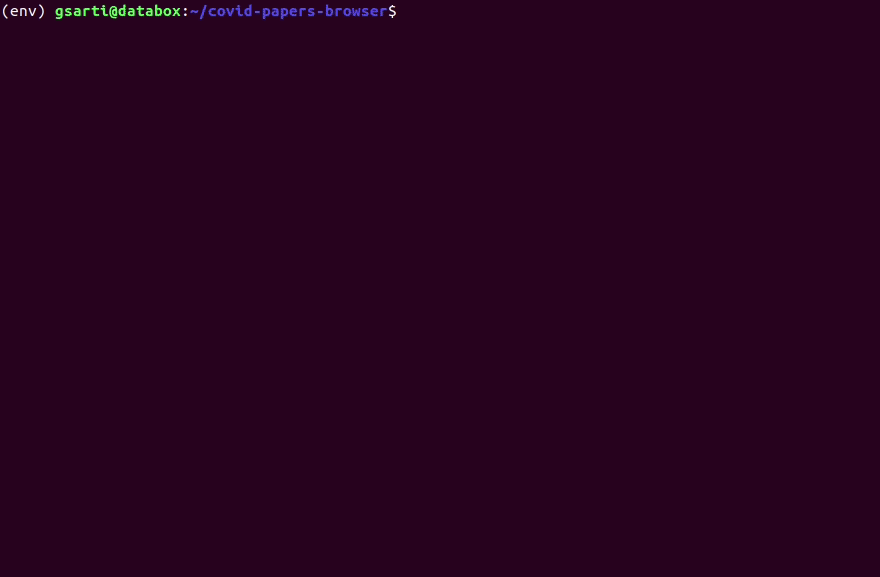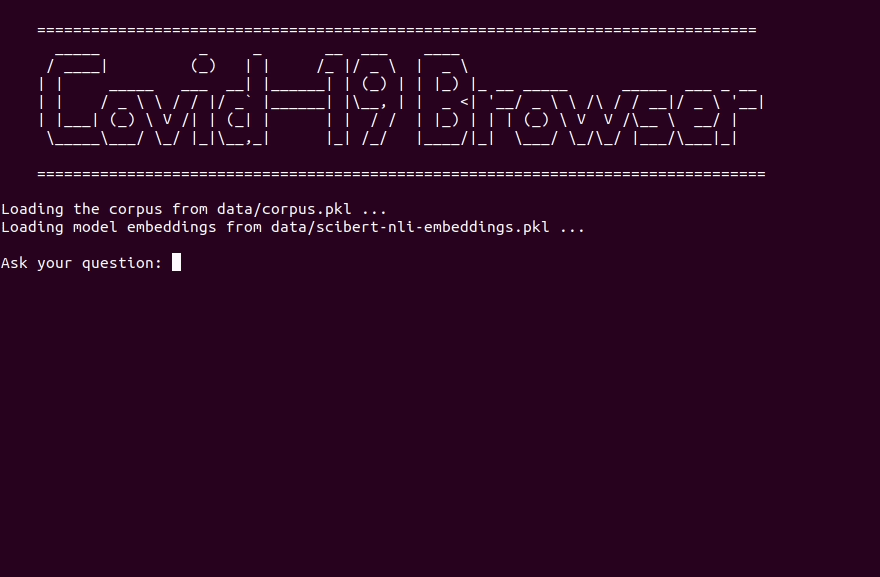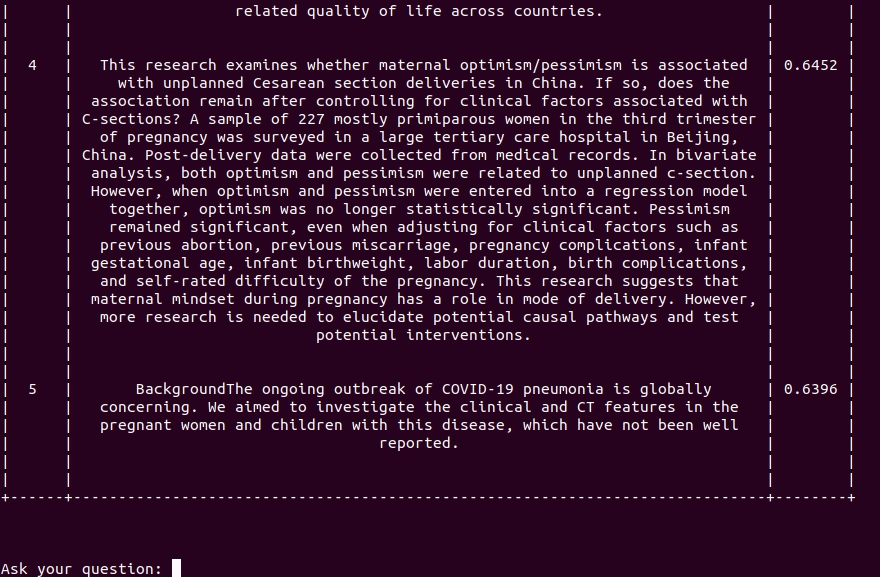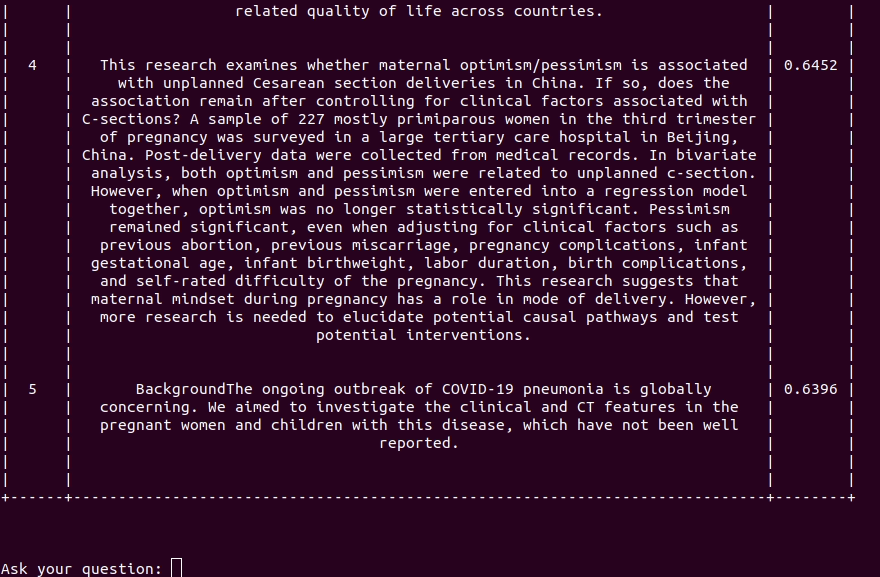
reciTAL has also released a project called COVID-19 Smart Search Engine to help improve search and browse on COVID-19 related articles with the goal to help researchers and healthcare professionals to quickly and efficiently find and discover information related to COVID-19.
SyferText
OpenMined releases SyferText, a new privacy-preserving NLP library that aims to enable secure and private NLP and processing of text for private datasets. It is in its early stages but we believe this is a very important effort towards safer and ethical AI systems. Here are some tutorials to get started.
David over Goliath: towards smaller models for cheaper, faster, and greener NLP
Is bigger always better? When looking at the evolution of language model size in the past few years, one may think the answer is yes. Yet, the financial and environmental cost of training such monsters is very high. Also, bigger in this case usually means slower, but speed is critical in most applications. This motivates the current trend in NLP pushing for smaller, faster, and greener models while preserving performance. In this blog post, Manuel Tonneau presents this new trend favoring smaller models focusing on three recent and popular models, DistilBERT from Hugging Face, PD-BERT from Google and BERT-of-Theseus from Microsoft.
A Survey of Deep Learning for Scientific Discovery
Many of the large companies today that have focused efforts in AI research believe that deep learning can be used as a tool for scientific discovery. This paper provides a comprehensive overview of the commonly used deep learning models for different scientific use cases. The paper also shares implementation tips, tutorials, other research summaries, and tools.
Tools and Datasets ⚙️
TextVQA and TextCaps
In an effort to encourage building models that can better detect and read the text in images and further reason about it to answer questions and generate captions, Facebook AI is hosting two separate competitions. The competitions are called TextVQA Challenge and TextCaps Challenge to address the visual question answering and caption generation tasks, respectively.
KeraStroke
One of the largest hurdles to overcome while designing neural nets is overfitting. Current generalization-improvement techniques such as Dropout, Regularization, and Early Stopping are very effective for most use cases, however, they can tend to fall short when using large models or smaller datasets. In response to this, Charles Averill has developed KeraStroke, a novel generalization-improvement technique suite useful for large models or small datasets. By altering weight values in certain cases during training, models dynamically adapt to the training data they’re being fed.
torchlayers
torchlayers is a new tool built on top of PyTorch that allows for automatic shape and dimensionality inference of layers available in the torch.nn module such as convolutional, recurrent, transformer, etc. This means that you don’t need to explicitly define the shape of input features which has to be specified manually in the layers. This simplifies a model’s definition in PyTorch. See an example of a basic classifier implemented with torchlayers below:

We can see from the code snippet that the Linear layer only requires the size of output features as opposed to both the output and input size. This is inferred by the torchlayers based on the input size.
Haystack: Open-Source Framework for Question Answering at Scale
Haystack allows you to use transformer models at scale for question-answering. It uses a Retriever-Reader-Pipeline, where the Retriever is a fast algorithm to find candidate documents and the Reader is a Transformer that extracts the granular answer. It’s building upon Hugging Face’s Transformers and Elasticsearch. It’s open-source, highly modular and easy to extend.
Teaching an AI to summarise news articles: A new dataset for abstractive summarisation
Curation Corp is open-sourcing 40,000 professionally-written summaries of news articles. This article provides a nice introduction to text summarisation and challenges that exist with this particular task. In addition, it introduces the dataset, the problems that can be addressed with it, including a discussion around fine-tuning methods and evaluation metrics for text summarization, and wrapping up with a discussion for the future work. Instructions for how to access the dataset can be found in this Github repository, along with examples of using the dataset for fine-tuning.
On the topic of text summarization, the HuggingFace team has added both BART and T5 as part of their Transformers library. These additions allow for all sorts of NLP tasks such as abstractive summarization, translation, and question-answering, among others.
Articles and Blog posts ✍️
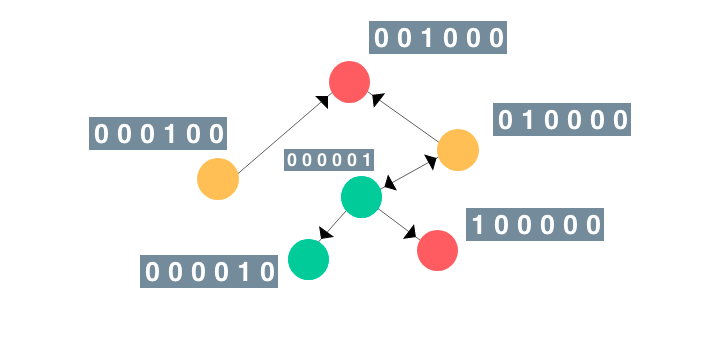
An Illustrated Guide to Graph Neural Networks
Graph neural networks have recently seen more adoption for tasks such as enhancing computer vision models and predicting side-effects due to drug interactions. In this overview, Rish presents an intuitive and illustrated guide to GNNs. (Featured on dair.ai)
Finetuning Transformers with JAX + Haiku
Just last month DeepMind open-sourced Haiku, the JAX version of their TensorFlow neural network library Sonnet. This post walks through the full source of a port of the RoBERTa pre-trained model to JAX + Haiku, then demonstrates finetuning the model to solve a downstream task. It’s intended to be a practical guide to using the utilities Haiku exposes for allowing the use of light object-oriented “modules” within the context of JAX’s functional programming constraints.
A small journey in the valley of Natural Language Processing and Text Pre-Processing for German language
Flávio Clésio wrote a very detailed article about the challenges of dealing with NLP problems in the German language. He shares many lessons learned, what worked and didn’t work, discusses several state-of-the-art methods, common issues to avoid, and a ton of learning resources, papers and blog posts.
French language keeping pace with AI: FlauBERT, CamemBERT, PIAF
Over the last few months, interesting French NLP resources were developed. We are talking about CamemBERT, FlauBERT, and PIAF (Pour une IA Francophone, For a French Speaking AI). The first two are pre-trained language models and the last one is a native French Question-Answering (QA) dataset. This blog post discusses all these three projects and some of the challenges presented along the way. This is a nice read and guide for those people working on different models in their own language.
Custom classifier on top of BERT-like language model
Marcin wrote another excellent guide showing how to build your own classifier (e.g. sentiment classifier) on top of BERT-like language models. It’s a great tutorial because it also shows how to use other modern libraries for the different parts of the model such as HuggingFace Tokenizer and PyTorchLightning. Find the Google Colab notebook here.
Education 🎓
Exploratory Data Analysis for Text Data
In this code walkthrough, Yonathan Hadar goes through several methods for exploratory analysis of textual data with various code examples. We featured this tutorial at dair.ai because it is a very comprehensive tutorial that uses standard methods for analyzing data that any data scientist will find useful. It’s a good starting point for anyone starting to play with textual data.
Embeddings in Natural Language Processing
Mohammad Taher Pilehvar and Jose Camacho-Collados publicly released their first draft of an upcoming book called “Embeddings in Natural Language Processing”. The idea with this book is to discuss the concept of embeddings which represent some of the most widely used techniques in NLP. As stated by the authors, the book includes “basics in vector space models and word embeddings to more recent sentence and contextualized embedding techniques based on pre-trained language models.”
A Brief Guide to Artificial Intelligence
Dr. James V Stone recently published his new book on “A Brief Guide to Artificial Intelligence” with the goal to provide a comprehensive overview of current AI systems and their achievement to perform a series of tasks. As stated in the summary, the book is “written in an informal style, with a comprehensive glossary and a list of further readings, which makes it an ideal introduction to the rapidly evolving field of AI.”

ML and Deep Learning Courses
Sebastian Raschka has released two recorded episodes for his course on “Introduction to Deep Learning and Generative Models”. You can find lecture notes and other materials in this repo.
Here is another excellent set of lectures on the topic of “Discrete Differential Geometry”.
Peter Bloem has released the full syllabus, including videos and lecture slides, for their introductory course on Machine Learning delivered at the VU University Amsterdam. Topics range from linear models and search to probabilistic models to models for sequential data.
CNN Architecture — Implementations
Dimitris Katsios provides a set of excellent tutorials that provide guidance on how to implement convolutional neural network (CNN) architectures from original papers. He proposes a recipe on how to go about implementing these while sharing the step-by-step that includes diagrams and code with the ability to infer the structure of the model. There is a lot to learn from these guides in terms of guiding others to more efficiently implementing papers.
Noteworthy Mentions ⭐️
You can find the previous newsletter here. You can also find the translated versions of the previous issues of the NLP Newsletter here.
A couple of months back we featured Luis Serrano’s excellent book on Grokking Machine Learning. Listen to Luis discuss a bit more about his book and his journey to becoming a successful educator in the field of ML.
Here are several newsletters that may be worth your attention: Sebastian Ruder’s NLP News, Made With ML, SIGTYP’s newsletter, MLT Newsletter, Nathan’s AI newsletter, etc…
Jupyter now comes with a visual debugger. This will allow this popular data science framework to be used more easily for general purposes.
Abhishek Thakur has a great YouTube channel where he walks through code showing how to use modern methods in machine learning and NLP. Some of his videos range from fine-tuning BERT models to performing handwritten grapheme classification to building a machine learning framework.
David Silver, a renowned reinforcement learning professor and researcher, is awarded the ACM Prize in Computing for breakthrough advances in computer game-playing. Silver lead the Alpha Go team that beat Lee Sedol in Go.
For those interested to learn the differences and the inner working behind popular methods for NLP such as BERT and word2vec, Mohd provides an excellent, approachable, and detailed overview of these approaches.
TensorFlow 2.2.0-rc-1 has been released. It includes features such as a Profiler that helps spot bottlenecks in your ML models and guide optimization of these models. Also, Colab now uses TensorFlow 2 by default.
Gabriel Peyré provides a nice set of notes for his course on ML optimization. Notes include convex analysis, SGD, autodiff, MLP, among other topics.
dair.ai updates
-
Call for Contributions to Open Science: We have opened a call for contributions to open science. There are many interesting collaborations in the pipeline. We want to open the invitation to anyone that’s interested in contributing to open science. Looking for volunteers, writers, reviewers, editors, developers, speakers, researchers, project maintainers,… Join us!
-
NLP Research Highlights Issue #1: ICYMI, in this article we highlight some NLP trends and topics with a focus on summarizing the what, how, and why of a selection of interesting and important NLP papers published in the last few months.
If you have any datasets, projects, blog posts, tutorials, or papers that you wish to share in the next issue of the NLP Newsletter, please submit them directly using this form.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.