

Bem-vindo à 9ª edição da NLP Newsletter. Esperamos que você e seus entes queridos
estejam bem e se mantenham seguros. Esta edição inclui tópicos que variam de uma
ferramenta de NLP que preserva a privacidade a ferramentas interativas para pesquisar
artigos relacionados ao COVID-19 até um guia ilustrado para representar graficamente redes
neurais.
Pesquisas e Publicações 📙
Neuroevolution of Self-Interpretable Agents
Tang et al. (2020) apresentam um trabalho
interessante e criativo que visa desenvolver um agente para absorver uma fração de sua
entrada visual com o objetivo de sobreviver a uma tarefa (por exemplo, evitar bater em um
curva e esquivar de bolas de fogo, como pode ser visto na figura abaixo). Usando
neuroevolution para treinar
self-attention architectures , os autores foram capazes de treinar agentes de
aprendizado por reforço para executar tarefas diferentes, permitindo apenas uma fração da
entrada. Os benefícios do modelo incluem uma redução substancial no tamanho dos
parâmetros, interpretabilidade e permitir que o modelo atenda apenas às task-critical
visual hints.

Introducing RONEC — the Romanian Named Entity Corpus
RONEC é um corpus named entity para o idioma
romeno que contém mais de 26.000 entidades em ~ 5.000 frases rotuladas, pertencentes a 16
classes distintas. As frases foram extraídas de um jornal sem direitos autorais, cobrindo
vários estilos. Esse corpus representa a primeira iniciativa de língua romena
especificamente direcionada ao reconhecimento de named entity. Está disponível nos
formatos BIO e CoNLL-U Plus e é gratuito para usar e estender
aqui.
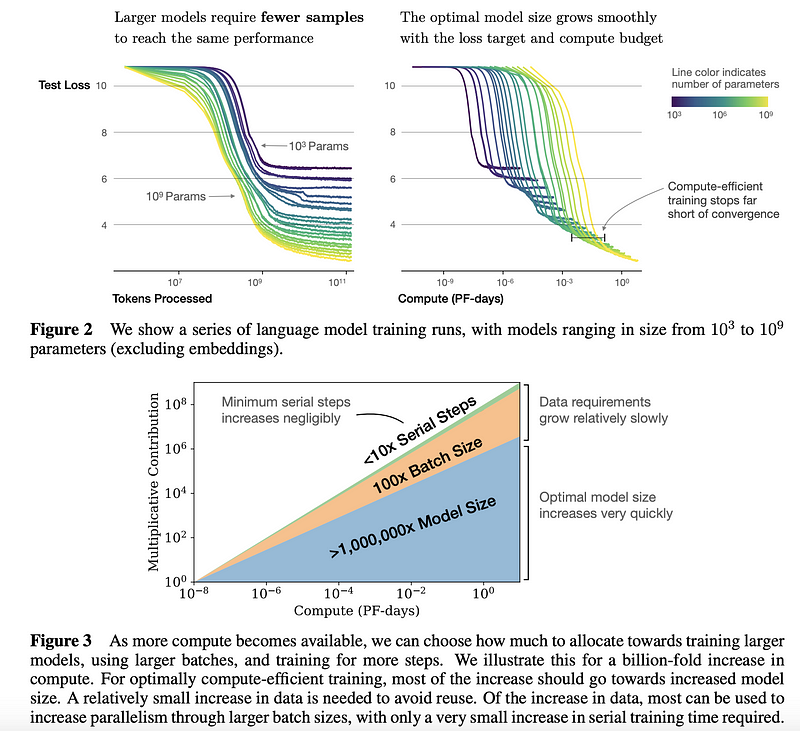
Scaling Laws for Neural Language Models
Pesquisadores de John Hopkins e da OpenAI conduziram um
estudo empírico para entender as leis de escala para o
desempenho de modelos de linguagem. Esse tipo de estudo pode ser usado como um guia para
tomar melhores decisões sobre como usar os recursos de maneira mais eficaz. No geral,
verificou-se que modelos maiores são significativamente mais eficientes em termos de
amostra; se houver computação e dados limitados, é melhor treinar um modelo grande com
algumas etapas de treinamento, em vez de treinar um modelo menor até convergir (consulte
os resultados sumarizados na figura abaixo). Os autores fornecem mais descobertas e
recomendações ao treinar modelos de linguagem grandes (por exemplo, Transformers) nos
aspectos de overfitting, escolhendo o tamanho ideal do batch size, o fine-tuning, as
decisões de arquitetura, etc.
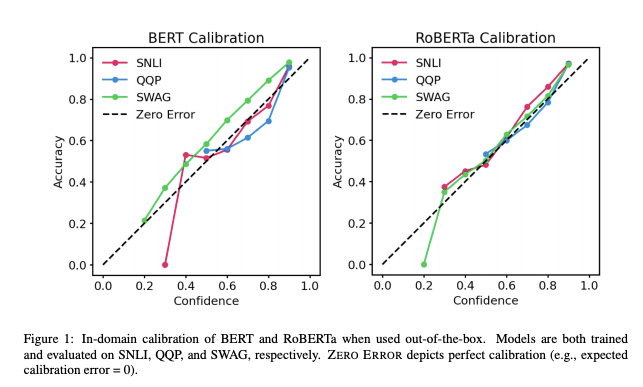
Calibration of Pre-trained Transformers
Com Transformers pré-treinados sendo cada vez mais usados em aplicações do mundo
real, é importante entender quão confiáveis são suas saídas. Recente
trabalho de UT Austin mostra que as probabilidades
posteriores do BERT e do RoBERTa são relativamente calibradas (isto é, consistentes
com resultados empíricos) em três tarefas (inferência de linguagem natural, detecção de
paráfrase e commonsense reasoning) com conjuntos de dados em domínio e desafiadores
fora do domínio. Os resultados mostram que: (1) quando usados fora da caixa, modelos
pré-treinados e prontos para uso são calibrados em domínio; e (2) escala de temperatura
é eficaz na redução adicional de erros de calibração em domínio, enquanto label
smoothing para aumentar a incerteza empírica ajuda a calibrar posteriores fora do
domínio.
Statistical Mechanics of Deep Learning
Um recente
artigo
examina mais de perto a conexão entre tópicos físicos/matemáticos e aprendizado
profundo. Os autores têm como objetivo discutir tópicos mais profundos que intersectam
mecânica estatística e aprendizado de máquina com o objetivo de responder perguntas que
ajudam a entender o lado teórico das redes neurais profundas e por que elas foram
bem sucedidas.
Towards an ImageNet Moment for Speech-to-Text
Em um novo
artigo publicado
no The Gradient, Alexander Veysov explica por que eles acreditam que o momento do
ImageNet para Speech-to-Text (STT) chegou no contexto da língua russa. Nos últimos dois
anos, os pesquisadores também fizeram essa afirmação sobre NLP. No entanto, para para
alcançar esse momento em STT, Alexander afirma que muitas peças precisam se unir, como
disponibilizar amplamente os modelos, minimizar os requisitos computacionais e melhorar a
acessibilidade de modelos grandes pré-treinados.
Criatividade, Ética, e Sociedade 🌎
Browsing and searching COVID-19 related articles
Na semana passada, apresentamos um conjunto de dados públicos chamado
CORD-19 que
contém documentos relacionados ao COVID. Gabriele Sarti escreveu uma ferramenta
interativa, que permite que você pesquise
e navegue com mais eficiência tais documentos, utilizando um modelo SciBERT com
fine-tuning.
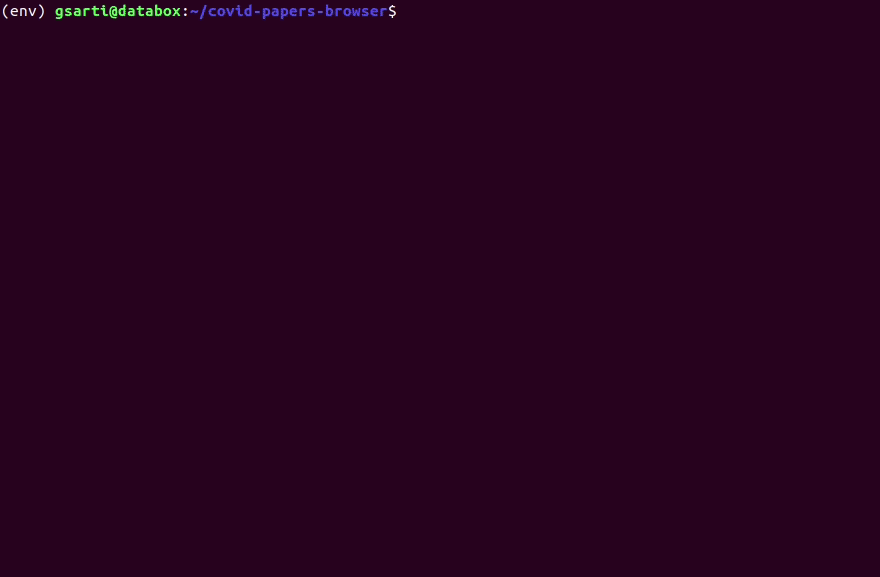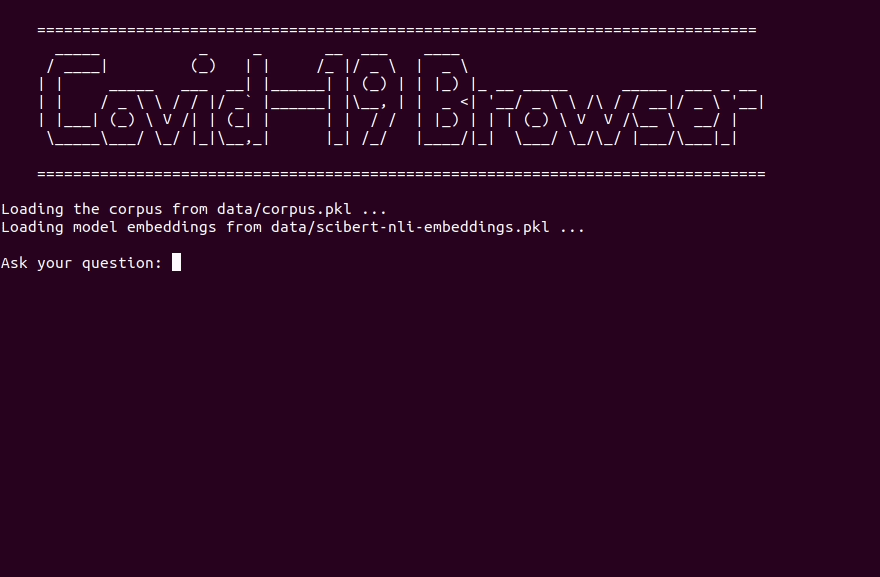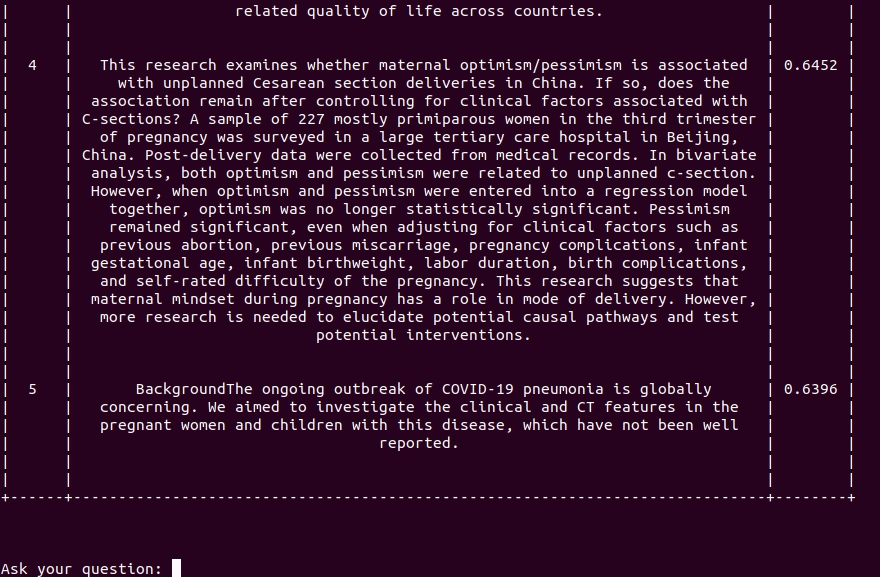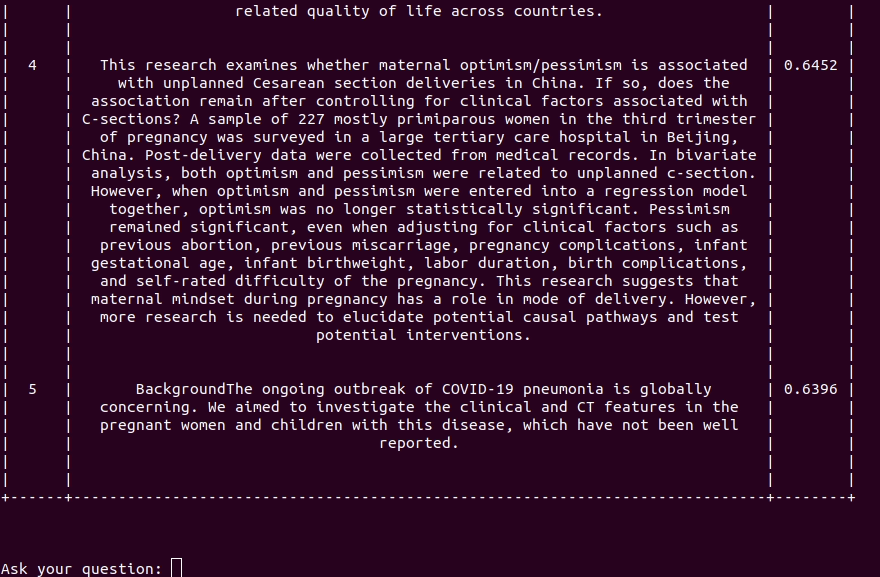
A reciTAL também lançou um projeto chamado COVID-19 Smart Search
Engine para ajudar a melhorar na pesquisa e
navegação de artigos relacionados ao COVID-19, com o objetivo de ajudar pesquisadores e
profissionais de saúde a encontrar e descobrir informações com rapidez e eficiência
relacionadas ao COVID-19.
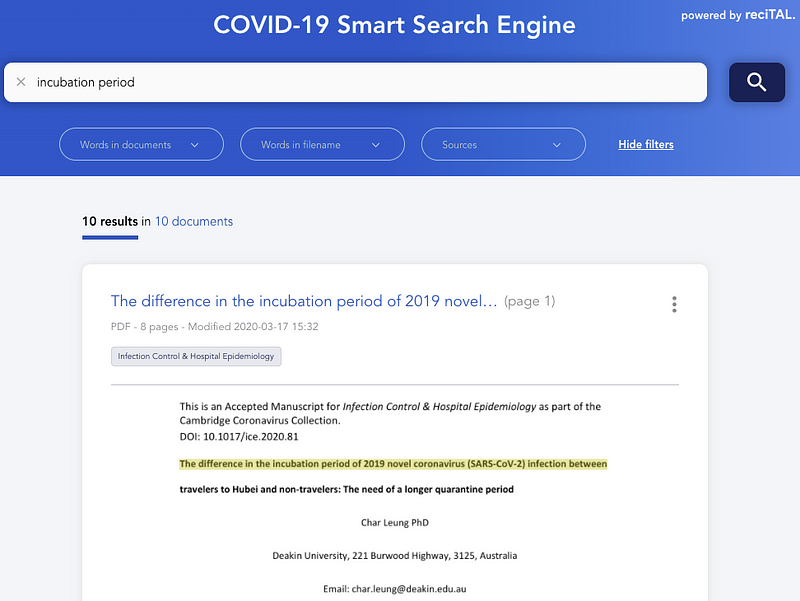
SyferText
A OpenMined liberou a SyferText, uma nova
biblioteca de NLP que visa preservar a privacidade e segurança em NLP, e o processamente
de texto para conjuntos de dados privados. Ainda está em estados iniciais, mas acreditamos
que isso é um esforço muito importante para sistemas de IA mais seguros e éticos. Aqui
estão alguns tutoriais
para começar.
David over Goliath: towards smaller models for cheaper, faster, and greener NLP
Maior é sempre melhor? Ao analisar a evolução do tamanho de modelos de linguagem nos
últimos anos, pode-se pensar que a resposta é sim. No entanto, o custo financeiro e
ambiental de treinar tais monstros é muito alto. Além disso, maior nesse caso geralmente
significa mais lento, mas a velocidade é crítica na maioria das aplicações. Isso motiva a
tendência atual de NLP a optar por modelos menores, mais rápidos e mais ecológicos, com o
desempenho preservado. Neste post de blog, Manuel
Tonneau apresenta
essa nova tendência que favorece modelos menores, com foco em três modelos recentes e
populares, DistilBERT da Hugging Face,
PD-BERT da Google e BERT-of-Theseus da
Microsoft.
A Survey of Deep Learning for Scientific Discovery
Muitas das grandes empresas hoje que concentraram esforços na pesquisa de IA acreditam que
aprendizado profundo pode ser usado como uma ferramenta para a descoberta científica. Este
artigo científico fornece uma visão abrangente de
modelos de aprendizado profundo comummente usados para diferentes casos de uso
científico. O artigo também compartilha dicas de implementação, tutoriais, outros sumários
de pesquisa e ferramentas.
Ferramentas e Conjunto de Dados ⚙️
TextVQA and TextCaps
Em um esforço para encorajar a construção de modelos que possam detectar e ler melhor
textos em imagens e depois argumentar para responder perguntas e gerar legendas, a
Facebook AI está hospedando duas competições separadas. As competições são chamadas
TextVQA Challenge e
TextCaps Challenge para abordar a tarefa de
visual question answering e geração de legendas, respectivamente.
KeraStroke
Um dos maiores obstáculos a superar ao projetar redes neurais é o overfitting. Técnicas
atuais de aprimoramento da generalização, como Dropout, regularização e Early Stopping
são muito eficazes para a maioria dos casos de uso; no entanto, elas tendem a ficar aquém
ao usar modelos grandes ou conjuntos de dados menores. Em resposta a isso, Charles Averill
desenvolveu a KeraStroke, um novo
conjunto de técnicas de melhoria de generalização úteis para modelos grandes ou pequenos
conjuntos de dados. Ao alterar os valores de peso em certos casos durante o treino, os
modelos se adaptam dinamicamente aos dados de treino a que eles estão sendo alimentados.
torchlayers
torchlayers é uma nova ferramenta criada
em cima do PyTorch, que permite a inferência automática de forma e dimensionalidade das
camadas disponível no módulo torch.nn, como convolucional, recorrente, transformer
etc. Isso significa que você não precisa definir explicitamente a forma das features de
entrada que devem ser especificadas manualmente nas camadas. Isso simplifica a definição
de um modelo em PyTorch. Veja um exemplo de um classificador básico implementado com a
torchlayers abaixo:

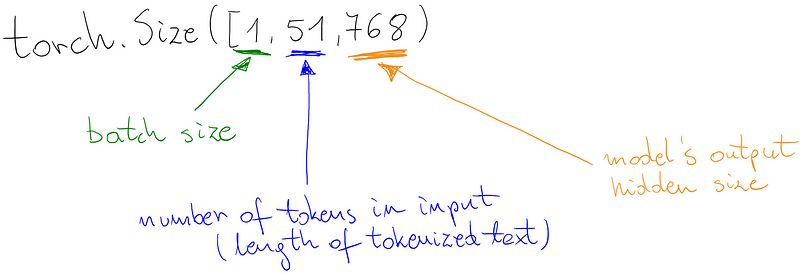
Podemos ver no snippet de código que a camada Linear requer apenas o tamanho das features de entrada, e não ambos tamanhos de saída e de entrada. Isto é inferido pela torchlayers com base no tamanho da entrada.
Haystack: Open-Source Framework for Question Answering at Scale
Haystack permite que você use modelos de
transformers em escala para question-answering. Ele usa um
Retriever-Reader-Pipeline, onde o Retriever é um algoritmo rápido para encontrar
documentos candidatos e o Reader é um Transformer que extrai a resposta
granular. Baseia-se nos Transformers da Hugging Face e da Elasticsearch. É
open-source, altamente modular e fácil de estender.
Teaching an AI to summarise news articles: A new dataset for abstractive summarisation
A Curation Corp está fornecendo 40.000 resumos de notícias escritos por profissionais.
Este
artigo
fornece uma boa introdução à sumarização de texto e aos desafios que existem com esta
tarefa particular. Além disso, apresenta o conjunto de dados, os problemas que podem ser
abordados, incluindo uma discussão sobre métodos de fine-tuning e de métricas de
avaliação para resumir o texto, e encerra com uma discussão para trabalhos
futuros. Instruções para acessar o conjunto de dados podem ser encontradas neste
repositório do Github, juntamente com
exemplos do uso
do conjunto de dados para o fine-tuning.
No tópico de text summarization, a equipe da HuggingFace adicionou ambos
BART e
T5
como parte de sua biblioteca de
Transformers . Essas adições
permitem todos os tipos de tarefas de NLP, como abstractive summarization, tradução e
question answering, entre outras.
Artigos e Postagens ✍️
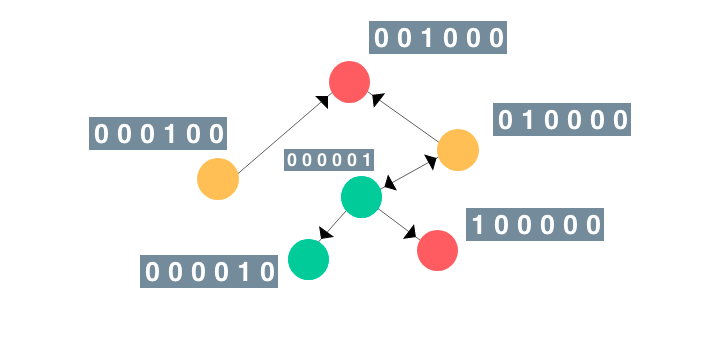
An Illustrated Guide to Graph Neural Networks
As redes neurais em grafo (GNN) recentemente tiveram mais adoção em tarefas como
melhorar modelos de visão computacional e previsão de efeitos colaterais devido a
interações medicamentosas. Nessa visão
geral, Rish apresenta um
guia intuitivo e ilustrado para GNNs. (Apresentado na dair.ai)
Finetuning Transformers with JAX + Haiku
No mês passado, a DeepMind deixou o código de Haiku livre, a versão JAX da Sonnet, sua
bliblioteca de redes neurais em TensorFlow. Esta postagem percorre a fonte
completa de uma porta do modelo pré-treinado RoBERTa para JAX + Haiku, depois demonstra
o fine-tuning do modelo para resolver uma tarefa especpifica (downstream). Ele
pretende ser um guia prático de uso das utilidades expostas pelo Haiku para permitir o uso
“módulos” de luz orientados a objetos, dentro do contexto das restrições de programação
funcional do JAX.
A small journey in the valley of Natural Language Processing and Text Pre-Processing for German language
Flávio Clésio escreveu um
artigo
sobre os desafios de lidar com os problemas de NLP no idioma alemão. Ele compartilha
muitas lições aprendidas, o que funcionou e o que não funcionou, discute vários métodos
estado da arte, problemas comuns a serem evitados e uma tonelada de recursos de
aprendizado, documentos e postagens de blog.
French language keeping pace with AI: FlauBERT, CamemBERT, PIAF
Nos últimos meses, foram desenvolvidos recursos interessantes de NLP em francês. Estamos
falando sobre o CamemBERT, FlauBERT e PIAF (Pour une IA Francophone, para uma IA
francesa falante). Os dois primeiros são modelos de linguagem pré-treinados e o último é
conjunto de dados native de question-answering(QA) em francês. Esta
postagem discute todos esses três
projetos e alguns dos desafios apresentados ao longo do caminho. Essa é uma boa leitura e
guia para aquelas pessoas que trabalham em modelos diferentes no seu próprio idioma.
Custom classifier on top of BERT-like language model
Marcin escreveu outro excelente
guia
mostrando como criar seu próprio classificador (por exemplo, um classificador de
sentimentos) em cima de modelos de linguagem como o BERT. É um ótimo tutorial, porque
também mostra como usar outras bibliotecas para as diferentes partes do modelo, como o
HuggingFace Tokenizer e PyTorchLightning. Encontre o notebbok do Google Colab
aqui.
Educação 🎓
Exploratory Data Analysis for Text Data
Neste passo a passo do código,
Yonathan Hadar passa por alguns métodos para análise exploratória de dados textuais com
vários exemplos de código. Apresentamos este tutorial na dair.ai porque é um tutorial
muito abrangente que usa métodos padrão para analisar dados que qualquer data scientist
achará útil. É um bom ponto de partida para quem começa a brincar
dados textuais.
Embeddings in Natural Language Processing
Mohammad Taher Pilehvar e Jose Camacho-Collados publicaram seu primeiro rascunho de seu
próximo
livro
chamado “Embeddings in Natural Language Processing”. A ideia deste livro é discutir o
conceito de embeddings, que representam algumas das técnicas mais amplamente usadas em
NLP. Como
declarado
pelos autores, o livro inclui “noções básicas de modelos de espaço vetorial e word
embeddings a técnicas mais recentes de embbedings contextualizados com base em modelos
de linguagem pré-treinados.”
A Brief Guide to Artificial Intelligence
O Dr. James V Stone publicou seu novo livro
sobre Um Guia Breve para a Inteligência Artificial (“A Brief Guide to Artificial
Intelligence”) com o objetivo de prover uma análise geral de sistemas de IA atuais e suas
conquistas para atuar em uma sére de tarefas. Como dito no sumário, o livro é escrito em
um estilo informal, com um glossário amplo e uma lista de leituras posteriores, o que faz
dele uma introdução ideal para o campo de evolução rápida que é a IA.

Cursos de ML e Aprendizado Profundo
Sebastian Raschka lançou dois
episódios
gravados para seu curso sobre “Introdução ao Aprendizado Profundo e Modelos
Generativos”. Você pode encontrar notas de aula e outros materiais neste
repositório.
Aqui está outro excelente conjunto de
palestras no tópico de
“Geometria Discreta Diferencial”.
Peter Bloem liberou o catálogo inteiro, incluindo vídeos e
slides de palestras, de seu curso introdutório de Aprendizado de Máquina, ministrado na
VU University Amsterdam. Os tópicos vão desde modelos lineares, busca e modelos
probabilísticos até modelos para dados sequenciais.
CNN Architecture — Implementations
Dimitris Katsios fornece um conjunto de excelentes
tutoriais
que fornecem orientações sobre como implementar arquiteturas de redes neurais
convolucionais (CNN) de seus artigos originais. Ele propõe uma receita sobre como proceder para
implementá-las enquanto compartilha o passo a passo que inclui diagramas e código com a
capacidade de inferir o estrutura do modelo. Há muito a aprender com esses guias em termos
de orientação sobre a implementação de artigos de forma mais eficiente.
Menções Honrosas ⭐️
Você pode encontrar as edições atenriores da newsletter aqui. Você também pode encontrar as versões traduzidas das edições anteriores da NLP Newsletter aqui.
Há alguns meses, apresentamos o excelente livro do Luis Serrano sobre Grokking Machine
Learning. Ouça
Luis discutindo um pouco mais sobre seu livro e sua jornada para se tornar um educador na
área de ML. pode valer sua atenção
Aqui estão muitas newsletters que podem valer sua atenção: Sebastian Ruder’s NLP
News, Made With
ML, SIGTYP’s
newsletter, MLT
Newsletter, Nathan’s AI
newsletter,
etc…
Jupyter agora vem com um debugger
visual. Isso irá
permitir que essa popular plataforma de ciência de dados seja usada mais facilmente para
fins gerais.
Abhishek Thakur tem um ótimo
canal no youtube por onde ele
percorre código mostrando como usar métodos modernos em aprendizado de máquina e
NLP. Alguns vídeos dele vão desde o fine-tuning dos modelos BERT até a classificação de
grafemas manuscritos até a construção um framework de aprendizado de máquina.
David Silver, renomado professor e pesquisador de aprendizado por reforço, foi
premiado com o Prêmio ACM em computação
para avanços inovadores em jogos de computador. Prata lidera a equipe Alpha Go que venceu
Lee Sedol em Go.
Para aqueles interessados em aprender as diferenças e o trabalho interno por trás de
métodos populares de NLP , como BERT e word2vec, Mohd
fornece
uma visão geral excelente, acessível e detalhada dessas abordagens.
O TensorFlow 2.2.0-rc-1 foi
liberado. Ele
inclui recursos como um Profiler que ajuda a identificar gargalos em modelos de ML e
orientar a otimização dos mesmos. Além disso, o Colab agora usa o TensorFlow 2 por
padrão.
Gabriel Peyré fornece um bom conjunto de
notas do seu
curso sobre otimização de ML. As notas incluem análise convexa, SGD, autodiff, MLP,
entre outros tópicos.
dair.ai updates
-
Call for Contributions to Open Science: Abrimos uma solicitação contribuições para a ciência livre (open science). Existem muitas colaborações interessantes no pipeline. Queremos abrir o convite para qualquer pessoa interessada em contribuir para a ciência livre. Estamos procurando por voluntários, escritores, revisores, editores, desenvolvedores, palestrantes, pesquisadores, e interessados em manter projetos,… Junte-se a nós!
-
NLP Research Highlights Issue #1: Caso você não tenha visto, nesse artigo nós destacamos algumas tendências e tópicos de NLP com um foco em sumarizar o que, o como e o porquê de uma seleção de artigos de NLP interessantes e importantes, publicados nos últimos meses.
Se você conhece alguma base de dados, projetos, postagens, tutoriais ou artigos que gostaria de ver na próxima edição da Newsletter de NLP, por favor submeta-os diretamente aqui usando esse formulário.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada.