

Welcome to the sixth issue of the NLP Newsletter. Thanks for all the support and for taking the time to read through the latest in ML and NLP. This issue covers topics that range from extending the Transformer model to slowing publication in ML to a series of ML and NLP book and project launches.
A few updates about the NLP Newsletter and dair.ai
We have been translating the newsletter to other languages such as Brazilian Portuguese, Chinese, Arabic, Spanish, among others. Thanks to those folks that have helped with the translations 🤗. You can also contribute here.
A month ago, we officially launched our new website. You can look at our GitHub organization for more information about dair.ai and projects. If you are interested in seeing how others are already contributing to dair.ai or are interested in contributing to democratizing artificial intelligence research, education, and technologies, check our issues section.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.
Publications 📙
A Primer in BERTology: What we know about how BERT works
Transformer-based models have shown to be effective at approaching different types of NLP tasks that range from sequence labeling to question answering. One of those models called BERT (Devlin et al. 2019) is widely used but, like other models that employ deep neural networks, we know very little about their inner workings. A new paper titled “A Primer in BERTology: What we know about how BERT works” aims to answer some of the questions about why BERT performs well on so many NLP tasks. Some of the topics addressed in the paper include the type of knowledge learned by BERT and where it is represented, and how that knowledge is learned and other methods researchers are using to improve it.
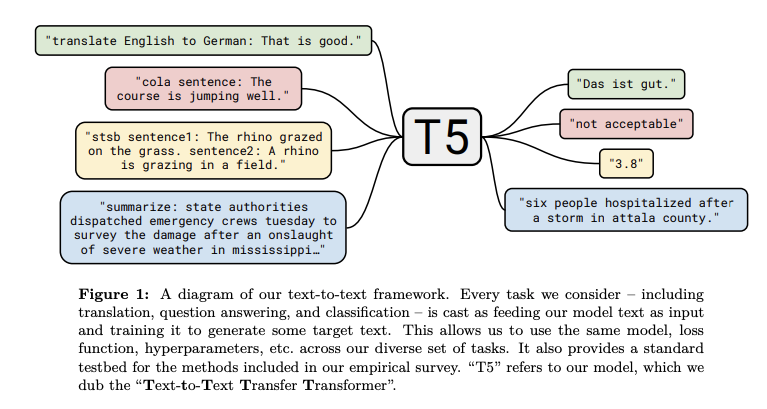
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Google AI recently published a method that brings together all the lessons learned and improvements from NLP transfer learning models into one unified framework called Text-to-Text Transfer Transformer (T5). This work proposes that most NLP tasks can be formulated in a text-to-text format, suggesting that both the inputs and outputs are texts. The authors claim that this “framework provides a consistent training objective both for pre-training and fine-tuning”. T5 is essentially an encoder-decoder Transformer that applies various improvements in particular to the attention components of the model. The model was pre-trained on a newly released dataset called Colossal Clean Crawled Corpus and achieved SOTA results on NLP tasks such as summarization, question answering, and text classification.
12-in-1: Multi-Task Vision and Language Representation Learning
Current research uses independent tasks and datasets to perform vision-and-language research even when the “visually-grounded language understanding skills” required to perform these tasks overlap. A new paper (to be presented at CVPR) proposes a large-scale multi-task approach to better model and jointly train vision-and-language tasks to generate a more generic vision-and-language model. The model reduces the parameter size and performs well on tasks like caption-based image retrieval and visual question answering.

BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations
reciTAL researchers and collaborators published a paper that aims to answer the question of whether a BERT model can produce representations that generalize to other modalities beyond text such as vision. They propose a model called BERT-gen that leverages mono or multi-modal representations and achieve improved results on visual question generation datasets.

Creativity and Society 🎨
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
Gary Marcus recently published a paper where he explains a series of steps that, in his view, we should be taking to build more robust AI systems. Gary’s central idea in this paper is to focus on building hybrid and knowledge-driven systems guided by cognitive models as opposed to focusing on building larger systems that require more data and computation power.
10 Breakthrough Technologies 2020
MIT Technology Review published a list of the 10 breakthroughs they have identified that will make a difference in solving problems that could change the way we live and work. The list — in no particular order — includes unhackable internet, hyper-personalized medicine, digital money, anti-aging drugs, AI-discovered molecules, satellite mega-constellations, quantum supremacy, Tiny AI, differential privacy, and climate attribution.
Time to rethink the publication process in machine learning
Yoshua Bengio recently wrote on his concerns about the fast-paced cycles of ML publications. The main concern is that due to the velocity of publishing, a lot of papers get published that contain errors and are just incremental, whereas spending more time and ensuring rigour, which is how it used to work many years ago, seems to be vanishing. On top of it all, students are the ones that have to deal with the negative consequences of this pressure and stress. To address the situation, Bengio talks about his actions to help in the process of slowing down research publications for the good of science.
Tools and Datasets ⚙️
PointerGenerator network implementation in AllenNLP
Pointer-Generator networks aim to augment sequence-to-sequence attentional models that are used to improve abstractive summarization. If you wish to use this technique for abstractive summarization using AllenNLP, Kundan Krishna has developed a library that allows you to run a pretrained model (provided) or train your own model.
Question answering for different languages
With the proliferation of Transformer models and their effectiveness for large-scale NLP tasks performed in other languages, there has been an impressive amount of effort to release different types of datasets in different languages. For instance, Sebastian Ruder shared a list of datasets that can be used for question answering research in different languages: DuReader, KorQuAD, SberQuAD, FQuAD, Arabic-SQuAD, SQuAD-it, and Spanish SQuAD.
PyTorch Lightning
PyTorch Lightning is a tool that allows you to abstract training that could require setting up GPU/TPU training and the use of 16-bit precision. Getting those things to work can become tedious but the great news is that PyTorch Lightning simplifies this process and allows you to train models on multi GPUs and TPUs without the need to change your current PyTorch code.
Graph Neural Networks in TF2
A Microsoft Research team releases a library that provides access to implementations of many different graph neural network (GNN) architectures. This library is based on TensorFlow 2 and also provides data-wrangling modules that can directly be used in training/evaluation loops.
Pre-training SmallBERTa — A tiny model to train on a tiny dataset
Have you ever wanted to train your own language model from scratch but didn’t have enough resources to do so? If so, then Aditya Malte have you covered with this great Colab notebook that teaches you how to train an LM from scratch with a smaller dataset.
Ethics in AI 🚨
Why faces don’t always tell the truth about feelings
For some time now, many researchers and companies have attempted to build AI models that understand and can recognize emotions either in the textual or visual context. A new article reopens the debate that AI techniques that aim to recognize emotion directly from face images are not doing it right. The main argument, raised by prominent psychologists in the space, is that there is no evidence of universal expressions that can be used for emotion detection from face images alone. It would take a model better understanding of personality traits, body movement, among other things to really get closer to more accurately detecting the emotions displayed by humans.
Differential Privacy and Federated Learning Explained
One of the ethical considerations when building AI systems is to ensure privacy. Currently, this can be achieved in two ways, either using differential privacy or federated learning. If you want to know more about these topics, Jordan Harrod provides us a great introduction in this video which also includes a hands-on practice session with the use of a Colab notebook.
Articles and Blog posts ✍️
A Deep Dive into the Reformer
Madison May wrote a new blog post that provides a deep dive into Reformer, which is a new and improved Transformer-based model recently proposed by Google AI. We also featured Reformer in a previous issue of the newsletter.
A free blogging platform
fastpages allows you to automatically set up a blog using GitHub pages for free. This solution simplifies the process of publishing a blog and it also supports the use of exported word documents and Jupyter notebooks.
Tips for interviewing at Google
Pablo Castro, from the Google Brain team, published an excellent blog post highlighting a list of tips for those interested in interviewing for a job at Google. Topics include advice on how to prepare for the interview, what to expect during the interview, and what happens after the interview.
Transformers are Graph Neural Networks
Both graph neural networks (GNNs) and Transformers have shown to be effective at different NLP tasks. To better understand the inner workings behind these approaches and how they relate, Chaitanya Joshi wrote a great article explaining the connection between GNNs and Transformers and different ways these methods can be combined in a sort of hybrid model.
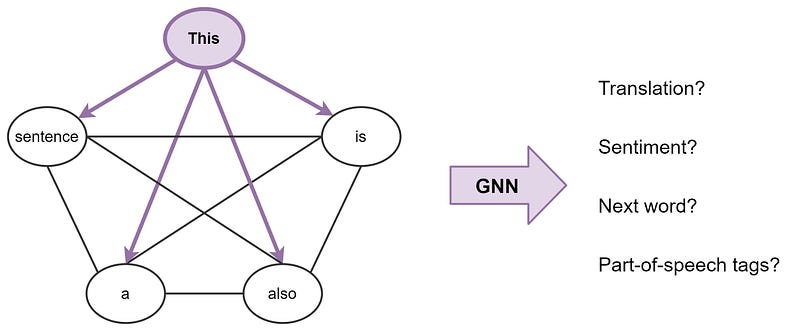
Representing a sentence as a fully-connected word graph — source
CNNs and Equivariance
Fabian Fuchs and Ed Wagstaff discuss the importance of equivariance and how CNNs enforce it. The concept of equivariance is first defined and then discussed in the context of CNNs with respect to translation.
Self-supervised learning with images
Self-supervised has been discussed a lot in previous issues of the NLP Newsletter due to the role it has played in modern techniques for language modeling. This blog post by Jonathan Whitaker provides a nice and intuitive explanation of self-supervision in the context of images. If you are really interested in the topic, Amit Chaudhary also wrote an excellent blog post describing the concept in a visual way.
Education 🎓
Stanford CS330: Deep Multi-Task and Meta-Learning
Stanford recently released video recordings, in the form of a YouTube playlist, for their new course on deep multi-task and meta-learning. Topics include bayesian meta-learning, lifelong learning, a reinforcement learning primer, model-based reinforcement learning, among others.
PyTorch Notebooks
dair.ai releases a series of notebooks that aim to get you started with deep neural networks using PyTorch. This is a work in progress and some current topics include how to implement a logistic regression model from scratch and how to program a neural network or recurrent neural network from scratch. Colab notebooks are also available in the GitHub repository.
The fastai book (draft)
Jeremy Howard and Sylvain Gugger release a comprehensive list of draft notebooks for an upcoming course that introduces deep learning concepts and how to develop different methods using PyTorch and the fastai library.
Free Data Science courses
In case you missed it, Kaggle provides a series of free micro-courses to get you started with your Data Science journey. Some of these courses include machine learning explainability, an intro to machine learning and Python, data visualization, feature engineering, and deep learning, among others.
Here is another excellent online data science course that provides a syllabus, slides, and notebooks on topics that range from exploratory data analysis to model interpretation to natural language processing.
8 Creators and Core Contributors Talk About Their Model Training Libraries From PyTorch Ecosystem
nepture.ai published an extensive article that contains detailed discussions with core creators and contributors about their journey and philosophy of building PyTorch and tools around it.
Visualizing Adaptive Sparse Attention Models
Sasha Rush shares an impressive Colab notebook that explains and shows the technical details of how to produce sparse softmax outputs and induce sparsity into the attention component of a Transformer model which helps to produce zero probability for irrelevant words in a given context, improving performance and interpretability all at once.
Visualizing probability distribution of a softmax output
Noteworthy Mentions ⭐️
You can access the previous issue of the 🗞 NLP Newsletter here.
Conor Bell wrote this nice python script that allows you to view and prepare a dataset that can be used for a StyleGAN model.
Manu Romero contributes a fine-tuned POS model for Spanish. The model is available for use in the Hugging Face Transformer library. It will be interesting to see this effort in other languages.
This repo contains a long list of carefully curated BERT-related papers that approach different problems such as model compression, domain-specific, multi-model, generation, downstream tasks, etc.
Connor Shorten published a short 15-minute video explaining a new general framework that aims to reduce the effect of “shortcut” features in self-supervised representation learning. This is important because if not done right, the model can fail to learn useful semantic representations and potentially prove ineffective in a transfer learning setting.
Sebastian Ruder published a new issue of the NLP News newsletter that highlights topics and resources that range from an analysis of NLP and ML papers in 2019 to slides for learning about transfer learning and deep learning essentials. Check it out here.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.