

dair.ai updates
- 我们为所有TL; DR和NLP论文摘要中包括的摘要增加了更好的分类,在这个repo中可以查看.
- 截止目前为止所有NLP简报的版本都可以在这里查看.
- 本周,我们还推出了Notebooks一个轻松与整个社区共享数据科学笔记本的中心。 如果您有任何想与社区共享的笔记本,请与我们联系。
- 我们共享了一个tutorial,其中提供了有关如何使用TextVectorization进行多类情感分类的步骤-TensorFlow 2.1.0中的一项实验功能,可帮助管理神经网络文本。
1、Research and Publications 📙
1.1 上下文嵌入以及预训练模型综述
这篇综述文章,A Survey on Contextual Embeddings提供了有关学习上下文嵌入的方法简要概述,论文中还回顾了其在迁移学习,模型压缩方法和模型分析中的应用。
另一份报告,IMPROVING TRANSFORMER LANGUAGE MODEL,介绍了改进基于Transformer的语言模型的方法。
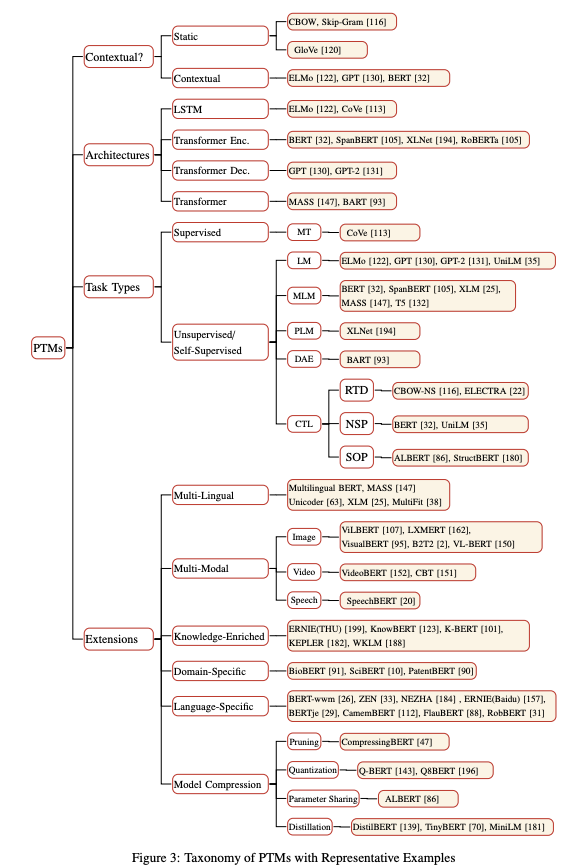
此外,复旦大学邱锡鹏老师团队整理了超全的NLP预训练模型综述,Pre-trained Models for Natural Language Processing: A Survey。该文从四个方面对用于NLP的预训练模型进行了全面的回顾:①首先简要介绍了语言表示学习及相关研究进展;②其次从四个方面对现有 PTM 进行系统分类(Contextual、Architectures、Task Types、Extensions);
1.2 通过Grand Tour可视化神经网络
Grand Tour是一种线性方法(不同于t-SNE等非线性方法),可将高维数据集投影到二维。Li等人在新的Distill文章,Visualizing Neural Networks with the Grand Tour中,提出使用Grand Tour功能来可视化神经网络在训练时的行为。分析了感兴趣的一些行为:包括权重变化及其对训练过程的影响,神经网络中的层到层通信,对抗示例在呈现给神经网络时的效果等。
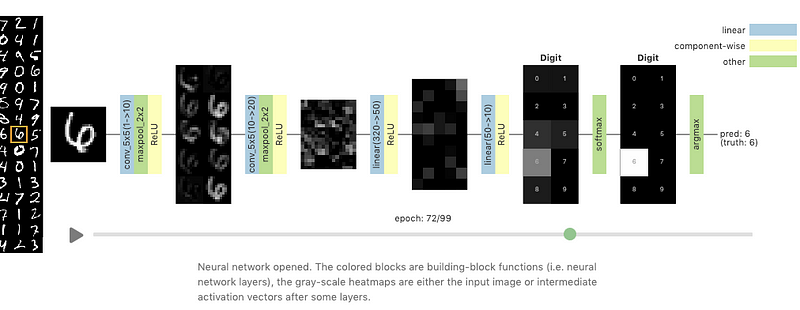
Source: Distill
1.3 低资源药物发现的元学习初始化
大量事实证明,元学习可以使得深度学习在少样本学习基准上有所改进,当遇到数据有限的情况时就非常有用,比如药物发现中的典型情况。最近的一项工作,Meta-Learning Initializations for Low-Resource Drug Discovery,应用了一种称为模型不可知元学习(Model-Agnostic-Meta-Learning,MAML)和其他变体的元学习方法来预测低资源环境下的化学性质和活性。 结果表明,元学习方法的性能与多任务预训练基准相当。
1.4 NeRF:将场景表示为用于视图合成的神经辐射场
加州大学伯克利分校,谷歌研究中心和加州大学圣地亚哥分校的研究人员进行了激动人心的工作,提出了一种用于合成复杂场景的新颖视图的方法,NeRF。该模型使用RGB图像输入集合,获取5D坐标(空间位置和方向),训练全连接的DNN以优化连续的体积场景功能,并为此位置输出体积密度和与视图相关的RGB辐射。输出值沿着照相机光线组合在一起并渲染为像素。 这些渲染的可微分输出用于通过最小化渲染RGB图像中所有摄像机光线的错误来优化场景表示。 与其他用于视图合成的性能最高的方法相比,NeRF在质量和数量上都更好,并且可以解决渲染中的不一致问题,例如缺少精细的细节和不必要的闪烁伪影。

1.5 Dreamer简介:使用世界模型的可扩展强化学习
Dreamer是一种强化学习(RL)代理,旨在解决模型中存在的一些局限性,例如shortsightedness和computational inefficiency。这是一种用于解决困难任务的model-free和model-based代理程序。这是由DeepMind和Google AI研究人员提出的RL代理,通过训练以对世界建模,还提供了使用模型预测通过反向传播学习long-sighted行为的能力。根据提供的图像输入,在20个连续控制任务上获得SoTA结果。 此外,该模型具有数据效率,并且可以并行进行预测,从而使计算效率更高。 下图总结了训练代理以实现不同目标的三个任务:
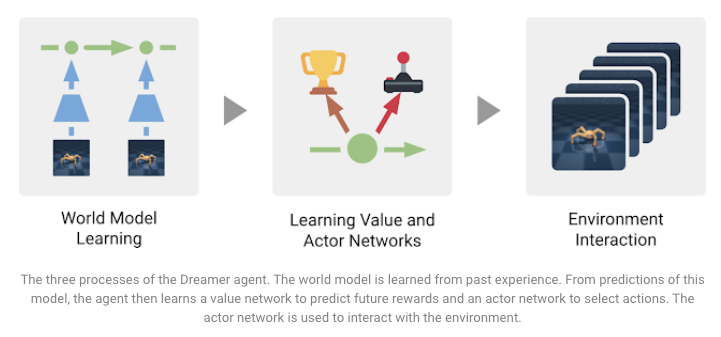
Source: Google AI Blog
2、Creativity, Ethics, and Society 🌎
2.1 COVID-19公开研究数据集
为了鼓励使用AI对抗COVID-19,AI的艾伦研究所发布了COVID-19开放研究数据集(CORD-19),这是一种免费开源资源,可促进全球研究合作。数据集包含数千篇学术文章,这些文章可以让NLP启发性研究有助于对抗COVID-19。
2.2 SECNLP:临床自然语言处理中的embedding综述
SECNLP是一份综述论文,其中详细介绍了在临床领域中应用的各种NLP方法和技术,概述主要强调嵌入方法,使用嵌入解决的问题/挑战以及对未来研究方向的讨论。
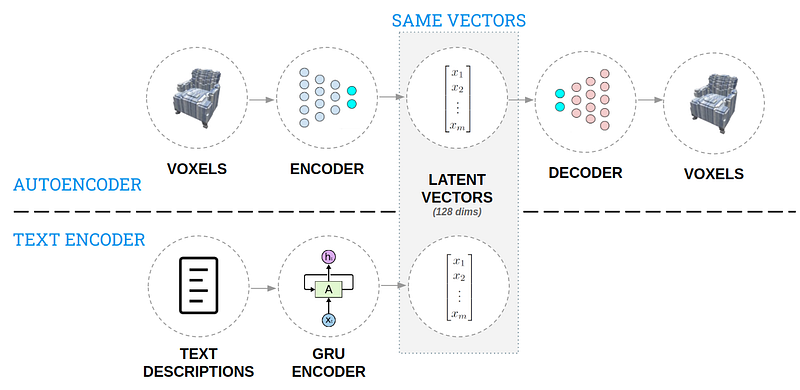
2.3 用于3D生成设计的AI
这篇文章,AI for 3D Generative Design介绍了一种用于从自然语言描述中生成3D对象的方法。这个想法是创建一个解决方案,使设计人员可以快速重申设计过程并能够更广泛地探索设计空间。在创建由3D模型和文本描述组成的设计空间的知识库之后,使用了两个自动编码器(请参见下图)以一种可以直观交互的方式对该知识进行编码。然后,放在一起的模型可以接受文本描述并生成3D设计,感兴趣可以在此3D生成设计demo中进行尝试。
3、Tools and Datasets ⚙️
3.1 Stanza:用于多种人类语言的Python NLP库
斯坦福NLP实验室发布了Stanza(以前称为StanfordNLP),这是一个Python NLP库,它提供了适用于70多种语言的即用型文本分析工具, 所有功能包括tokenization,multi-word token expansion,lemmatization,POS,NER等等。 该工具基于PyTorch库并支持使用GPU和预训练的神经模型。 Explosion还在Stanza构建了一个包装器,使你可以将其作为spaCy管道与Stanza模型进行交互。
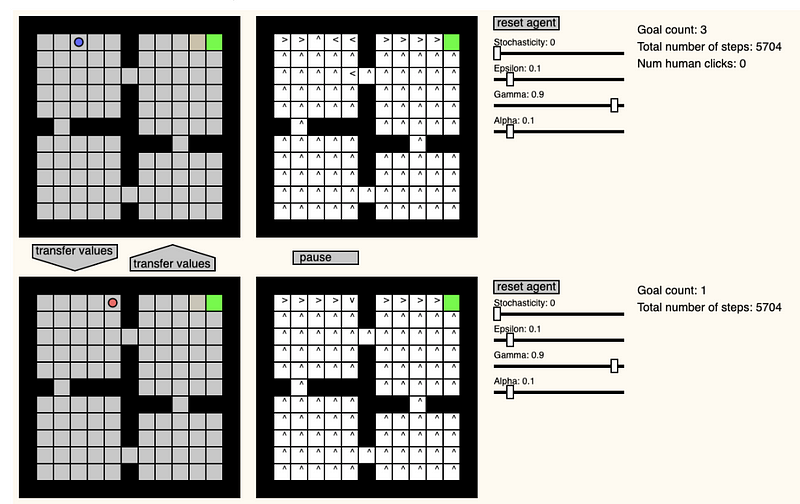
3.2 GridWorld
Pablo Castro创建了一个有趣的网站,GridWorld Playground,该操场为创建Grid World环境提供了一个场景,以观察和测试强化学习代理如何尝试解决Grid World。 一些功能包括实时更改学习/环境参数,更改代理的位置以及在两个代理之间传递值。
3.3 X-Stance:用于stance检测的多语言多目标数据集
Stance detection是主题对演员主张的反应的摘要,可用于假新闻评估。Jannis Vamvas和Rico Sennrich最近发布了一个大规模stance detection数据集,其中包含瑞士选举候选人的书面文字。文中提供了多种语言,这可能会导致对stance detection任务进行跨语言评估。作者还建议使用多语言BERT,以实现zero-shot跨语言和跨目标传输令人满意的性能。 特别地,跨目标学习是一项艰巨的任务,因此作者使用一种涉及标准化目标的简单技术,一次就所有问题训练了一个模型。
3.4 为Jupyter创建交互式文本热图
Andreas Madsen创建了一个名为TextualHeatMap的Python库,该库可用于呈现可视化效果,例如在语言模型中帮助理解模型中句子的哪些部分来预测下一个单词。

Source: textualheatmap
4、Articles and Blog posts ✍️
4.1 使用不同的解码方法通过Transformers生成语言
HuggingFace发表了一篇文章,How to generate text: using different decoding methods for language generation with Transformers,解释了用于语言生成的不同方法,特别是基于Transformer的方法。 在讨论的这些技术中,有贪婪搜索,波束搜索,采样,top-k采样和top-p(核)采样。 目前已经有很
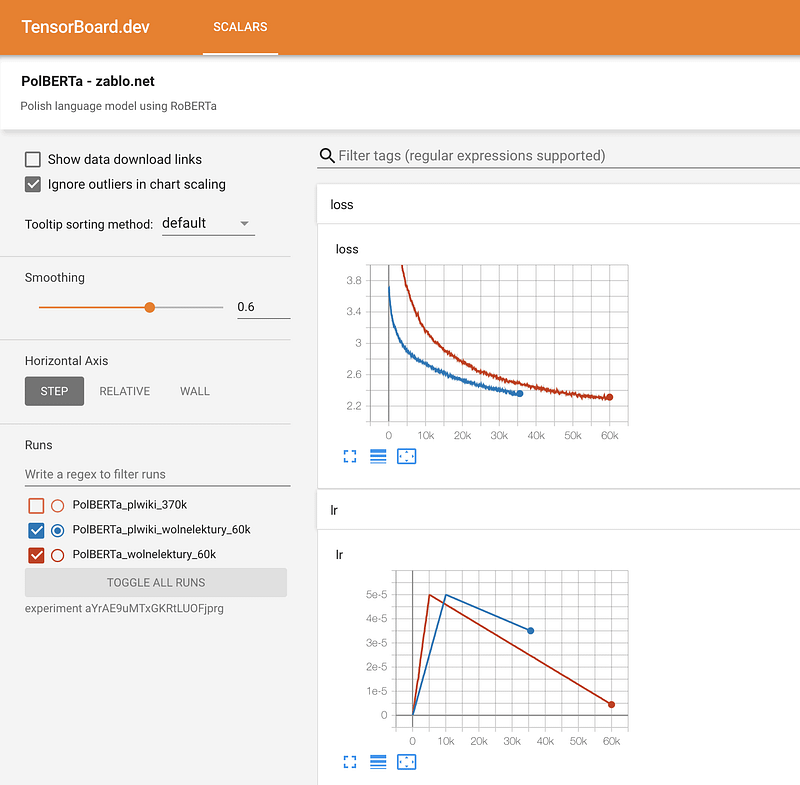
4.2 从零训练Roberta
由于缺乏使用transformer库从头开始训练类似BERT的语言模型的全面指南,Marcin Zablocki分享了这一详细的教程,training-roberta-from-scratch-the-missing-guide-polish-language-model。 该指南展示了如何为波兰语训练一个transformer语言模型,并给出了如何避免常见错误,数据准备,预训练配置,标记化,训练,监控训练过程以及共享模型的一些建议。
5、Education 🎓
5.1 JAX入门(MLP,CNN和RNN)
Robert Lange最近发布了关于如何使用JAX训练GRU-RNN的全面教程tutorial,Getting started with JAX (MLPs, CNNs & RNNs)。 在我们以前的NLP简报中,我们还分享了一个与JAX相关的资源。
5.2 NLP开发人员:单词嵌入
Rachael Tatman发布了一个名为NLP for Developers的系列教程,该系列涵盖了如何应用各种NLP方法的最佳实践。 其中第一集包括单词嵌入的介绍,如何使用以及其在应用它们时应避免的常见问题。
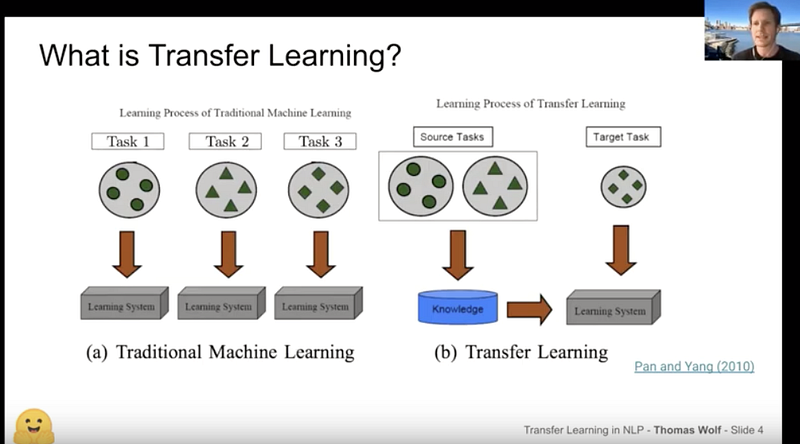
5.3 迁移学习和huggingface简介
Thomas Wolf在NLP Zurich meetup介绍了他关于迁移学习的演讲,transfer learning inNLP,为NLP的迁移学习提供了很好的介绍。演讲包括对NLP最新突破的概述,以及对HuggingFace团队和贡献者发布的两个最受欢迎的库Transformers和Tokenizers的介绍。
6、Noteworthy Mentions ⭐️
你知道Google表格提供免费的翻译功能吗? Amit Chaudhary分享了一篇文章,back-translation-in-google-sheets,其中显示了如何利用该功能进行反向翻译,这对于NLP任务中增强有限的文本语料库很有用。
New York NLP将举办一个在线会议,Using Wikipedia and Wikidata for NLP,主题为“使用Wikipedia和Wikidata 的NLP”,演讲者将讨论如何将Wikipedia用于不同的NLP项目和用例。
Lavanya Shukla撰写了一份不错的教程,Use Pytorch Lightning with Weights & Biases,有关如何使用PyTorch Lightning来优化神经网络的超参数,同时使用PyTorch Lightning中提供的简单代码结构。 使用WandB logger产生的结果,可以可视化结果模型及其在不同超参数下的性能,该结果可以作为记录器参数提供给训练对象。
一组研究人员发表了一份研究,Rethinking Batch Normalization in Transformers,详细研究了为什么批处理归一化(BN)会降低应用于不同NLP任务的基于Transformer的方法的性能。 基于这些发现,作者提出了一种称为功率归一化(power normalization,PN)的新方法来处理BN中发现的问题。 在各种NLP任务上,该方法的性能均优于BN和如今已普遍使用的层归一化。
这篇博客文章,22 Timeless Reference Books 包含一长串书籍,可帮助你开始使用ML。
如果您希望在下一期NLP新闻通讯中共享任何数据集,项目,博客文章,教程或论文,请随时通过ellfae@gmail.com或DM on Twitter。
Subscribe🔖至NLP新闻通讯,以在收件箱中接收以后的新闻。