

欢迎阅读NLP简报第9期。 我们希望您和您的亲人身体健康并保持安全。 本期主题包括保护隐私的NLP工具、用于搜索与COVID-19相关的论文的交互式工具、图解图神经网络指南等主题。
1、Research and Publications 📙
1.1 Neuroevolution of Self-Interpretable Agents
唐等提出了一个有趣且有创意的工作,Neuroevolution of Self-Interpretable Agents,旨在发展一种代理以吸收一部分视觉输入,以使任务得以生存(例如,避免崩溃)。 曲线和闪避的火球,如下图所示)。 使用neuroevolution来训练“自我注意”架构,作者能够训练强化学习代理执行不同的任务,而只允许输入的一小部分。 该模型的好处包括参数大小的大幅减少,策略的可解释性,以及使模型仅能够关注关键的视觉提示。

1.2 RONEC
RONEC是罗马尼亚语的命名实体语料库,在约5000个带注释的句子中包含超过26000个实体,属于16个不同的类。 这些句子摘自无版权的报纸,内容涉及多种样式。 该语料库是罗马尼亚语言领域针对命名实体识别的第一个举措。 它具有BIO和CoNLL-U Plus格式,可以在此处免费使用和扩展。
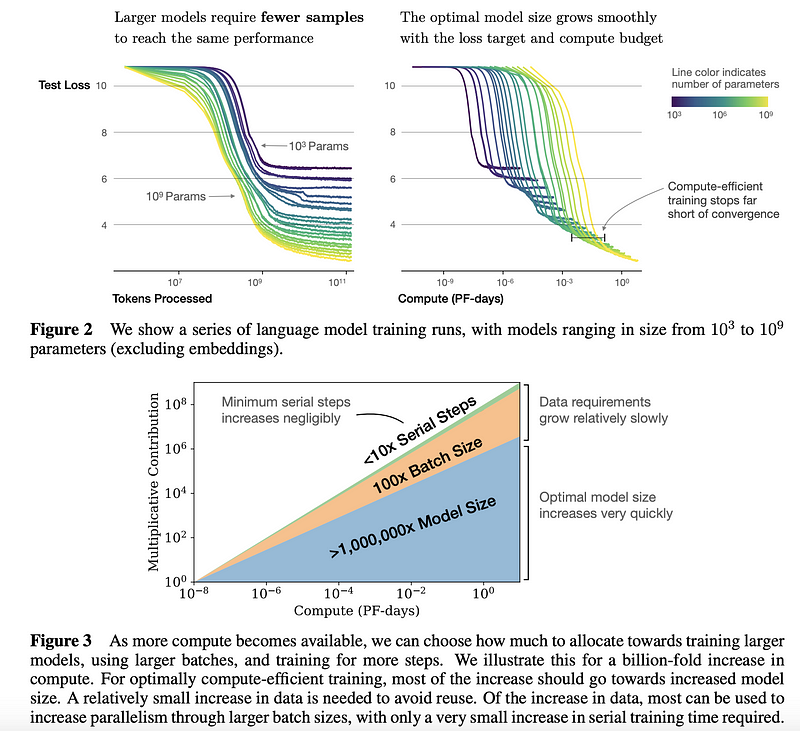
1.3 Scaling Laws for Neural Language Models
John Hopkins和OpenAI的研究人员进行了一项实验性研究,Scaling Laws for Neural Language Models,以了解语言模型性能的scaling laws。 这种类型的研究可以用作一种指导,以便就如何更有效地利用资源做出更好的决策。 总体而言,研究发现较大的模型的样本效率明显更高; 如果计算和数据有限,则最好通过几步训练来训练大型模型,而不是训练较小的模型直到收敛为止,见下图中汇总的结果。 作者为训练大型语言模型(如Transformer)中的过拟合,最佳批大小,微调,架构等方面提供了更多建议。
1.3 预训练Transformers校准
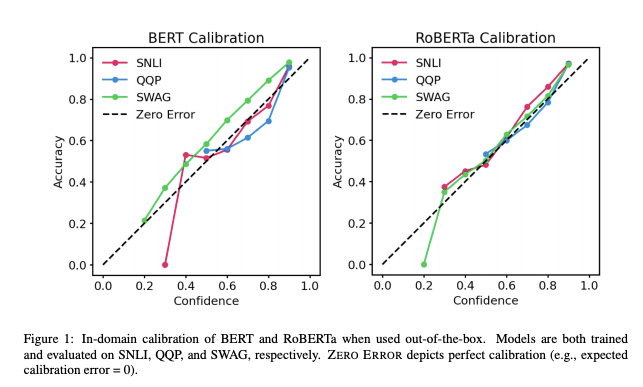
随着在实际中越来越多地使用经过预训练的Transformer模型,尤其重要的是要了解其输出的“可信赖性”。 UT Austin最近的一项工作,Calibration of Pre-trained Transformers,研究显示在三个任务(自然语言推理、释义检测、常识推理)的领域内以及领域外数据集上,BERT和RoBERTa的后验概率上相对校准(即与经验结果一致)。 结果表明:(1)开箱即用时,预训练的模型在域内校准; (2)temperature scaling有效地进一步减小了域内的校准误差,而标签平滑处理增加了经验不确定性则有助于校准领域外后验概率。
1.4 深度学习的统计学
最近的一篇论文,Statistical Mechanics of Deep Learning,仔细研究了物理/数学与深度学习之间的联系。 作者的目的是讨论统计力学和机器学习相交的更深层次的主题,有助于理解深度神经网络的理论及其成功原因的问题。
1.5 Speech-to-Text的ImageNet时刻
在Gradient中发布的新文章,Towards an ImageNet Moment for Speech-to-Text中,Alexander Veysov解释了为什么他们认为在俄语中语音转文本(Speech-to-Text,STT)的ImageNet时刻已经到来。 在最近几年中,研究人员也对NLP领域提出了这一说法。但是,为了在STT中实现这一里程碑,Alexander声称必须将许多部分放在一起,例如使模型广泛可用,最小化计算要求并提高预训练大型模型的可使用性。
2、Creativity, Ethics, and Society 🌎
2.1 浏览和搜索COVID-19相关文章
在上一期NLP简报中,我们介绍了一个名为CORD-19的公开数据集,其中包含与COVID相关的论文。 Gabriele Sarti编写了一个交互式工具,通过使用SciBERT精细调整的模型,可以让你更有效地搜索和浏览这些文件。
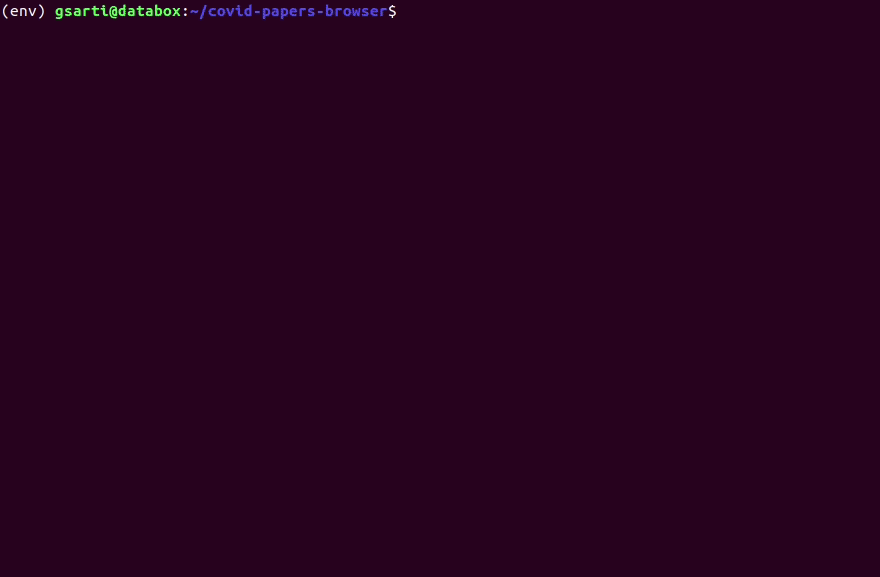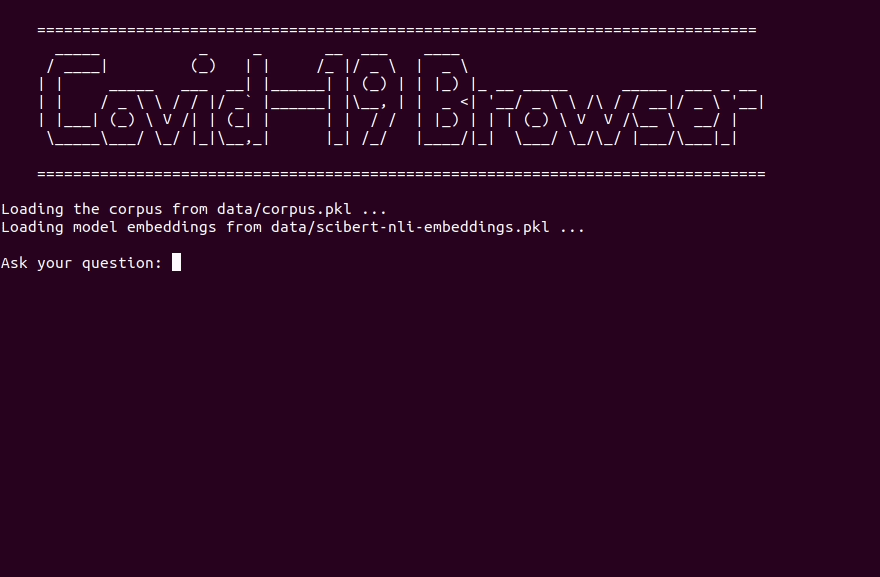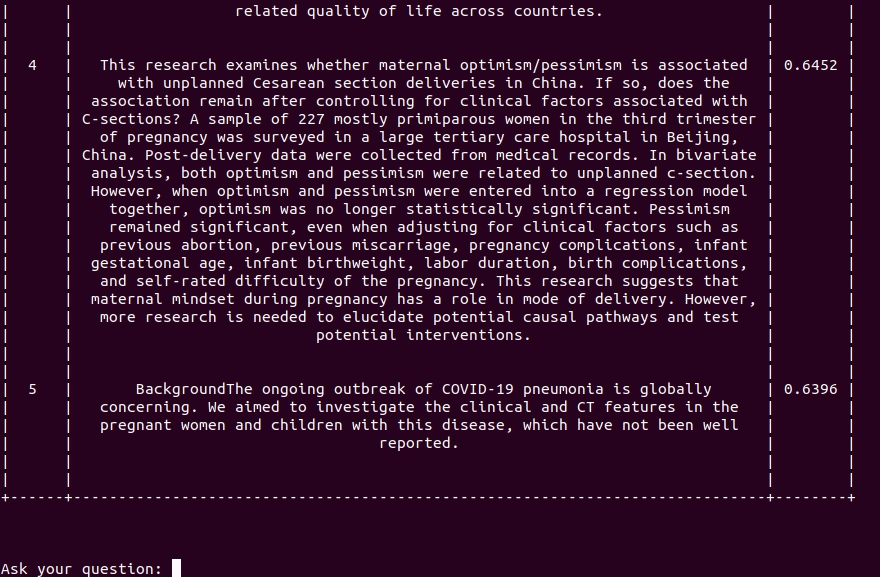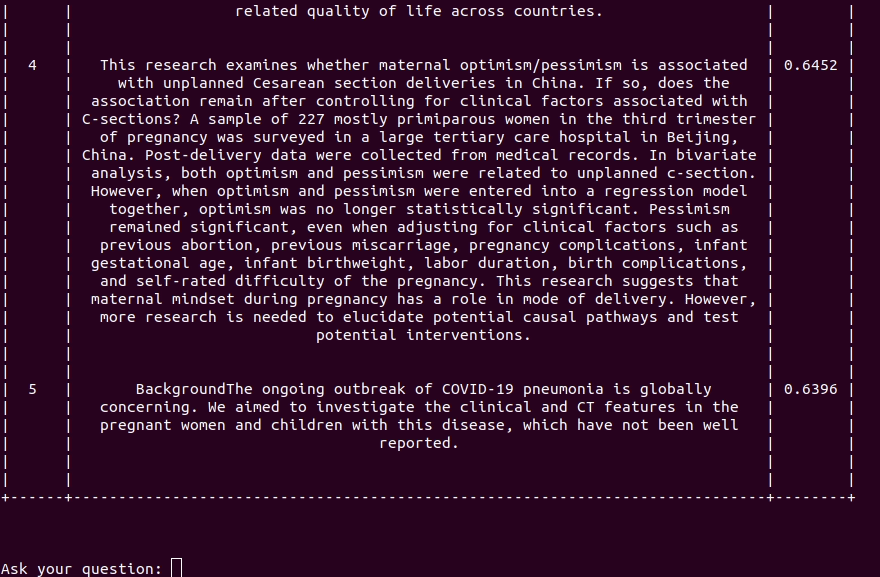
reciTAL还发布了一个名为COVID-19 Smart Search Engine的项目,以帮助改进对COVID-19相关文章的搜索和浏览,目的是帮助研究人员和医疗保健专业人员快速并有效地发现与COVID-19相关的信息。
2.2 SyferText
OpenMined发布了SyferText,这是一个新的隐私保护NLP库,旨在实现安全和私有的NLP以及私有数据集的文本处理。 它尚处于初期阶段,但我们认为这是朝着更安全,更道德的AI系统迈出的重要一步。 这是一些SyferText入门教程。
2.3 David over Goliath: towards smaller models for cheaper, faster, and greener NLP
模型总是越大越好吗? 当回顾过去几年语言模型规模的演变时,人们可能会认为答案是肯定的。 然而,训练这种怪物的经济和环境成本很高。 同样,在这种情况下,较大通常意味着速度较慢,但在大多数应用中速度至关重要。 这激发了当前NLP趋势,即在保持性能的同时推动更小,更快和更环保的模型。 在此博客文章中,Manuel Tonneau提出了这一新趋势,该趋势偏向于以较小的模型为重点,着重于三种近期流行的模型,Hugging Face的DistilBERT、Google的PD-BERT和Microsoft的BERT-of-Theseus。
2.4 科学发现的深度学习综述
如今,许多致力于AI研究的大公司都认为深度学习可以用作科学发现的工具。 最近的一篇论文,A Survey of Deep Learning for Scientific Discovery提供了针对不同科学用例的常用深度学习模型的全面综述。 论文中还分享了实现技巧,教程,其他研究摘要和工具。
3、Tools and Datasets ⚙️
3.1 TextVQA 和 TextCaps
为了鼓励建立可以更好地检测和读取图像中文本的模型,并进一步说明其回答问题和生成标题的方式,Facebook AI举办了两个独立的竞赛。 这些竞赛分别称为TextVQA挑战赛和TextCaps挑战赛,分别针对视觉问题回答和字幕生成任务。
3.2 KeraStroke
设计神经网络时要克服的最大障碍之一是过拟合。 当前的泛化改进技术(例如Dropout,Regularization和Early Stoping)在大多数用例中非常有效,但是,当使用大型模型或较小的数据集时,它们往往会略显不足。 为此,Charles Averill开发了KeraStroke,这是一种新颖的泛化改进技术套件,适用于大型模型或小型数据集。 通过在训练过程中的某些情况下更改权重值,模型可以动态地适应他们所输入的训练数据。
3.3 torchlayers
torchlayers是在PyTorch之上构建的新工具,可自动推断torch.nn模块中可用层的形状和尺寸,例如卷积,递归,transformer等等。这意味着你无需显式定义必须在图层中手动指定的输入要素的形状。这简化了PyTorch中模型的定义。可以参考下面的用Torchlayers实现的基本分类器的示例:

从代码片段中我们可以看到,线性层仅需要输出要素的大小,而不是输出和输入的大小。 这是由torchlayers根据输入大小来推断的。
3.4 Haystack
Haystack允许你大规模使用transformer模型进行问答任务。 它使用Retriever-Reader-Pipeline,其中Retriever是查找候选文档的快速算法,而Reader是提取细粒度答案的Transformer。 它基于Hugging Face的Transformers和Elasticsearch,它是开源的,高度模块化的且易于扩展。
3.5 教AI总结新闻
Curation Corp正在开源40,000个新闻报道的专业摘要。 该篇文章,Teaching an AI to summarise news articles: A new dataset for abstractive summarisation为文本摘要提供了很好的介绍 和这项特定任务所面临的挑战。 此外,它介绍了数据集,以及可以解决的问题,包括围绕微调方法和文本摘要评估指标的讨论,并为将来的工作进行了总结。 有关如何访问数据集的说明,可以在此Github repo中找到,以及使用数据集进行微调的案例。
关于文本摘要,HuggingFace团队为其Transformers库库添加了BART和T5。 这些附加功能可进行各种NLP任务,例如抽象摘要,翻译和问题解答。
4、Articles and Blog posts ✍️
4.1 图神经网络指南
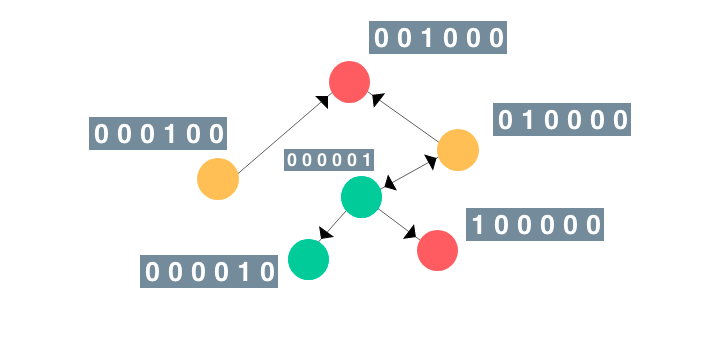
图神经网络最近已经被越来越多的任务采用,例如增强计算机视觉模型和预测由于药物相互作用而产生的副作用等。 在此文章中,An Illustrated Guide to Graph Neural Networks,Rish提出了有关GNN的直观说明性指南。
4.2 使用JAX和Haiku微调transformer
就在上个月DeepMind开源Haiku,即TensorFlow神经网络库Sonnet的JAX版本。 这篇博客,finetuning-transformers-with-jax-and-haiku讲述了RoBERTa预训练模型的端口到JAX + Haiku的完整信息,然后进行了演示,微调模型以解决下游任务。 它旨在作为使用Haiku公开的实用程序的实用指南,以允许在JAX的功能编程约束范围内使用轻量级的面向对象的“模块”。
4.3 德语NLP进展
FlávioClésio写了一篇非常详细的文章,A small journey in the valley of Natural Language Processing and Text Pre-Processing for German language,介绍了德语自然语言处理方面的挑战。 他分享了许多经验教训,哪些是行之有效的,什么是行不通的,讨论了几种最新方法,应避免的常见问题以及大量学习资源,论文和博客文章。
4.4 法语NLP进展
在过去的几个月中,出现了很多有趣的法语NLP资源。 我们之前讨论过的是CamemBERT,FlauBERT和PIAF(Pour une IA Francophone)。前两个是经过预训练的语言模型,最后一个是法语QA数据集。 这篇博客,French language keeping pace with AI: FlauBERT, CamemBERT, PIAF讨论了这三个项目以及此过程中提出的一些挑战。 对于使用自己的语言开发不同模型的人们来说,这是一本不错的阅读指南。
4.5 在类BERT的语言模型之上自定义分类器
Marcin撰写了一份非常出色的指南,Custom classifier on top of BERT-like language model,展示了如何构建自己的分类器(例如情感分类器)接在类似BERT的语言模型上。 这是一个很棒的教程,因为它还显示了如何针对模型的不同部分使用其他代码库,例如HuggingFace Tokenizer和PyTorchLightning。 在此处查看Google Colab notebook。
5、Education 🎓
5.1 文本数据的探索性数据分析
Yonathan Hadar通过各种代码示例介绍了几种探索性分析文本数据的方法,并提供了详细的代码实战。 我们在dair.ai上介绍了此教程,因为它是非常全面的教程,它使用标准方法来分析任何数据科学家都认为有用的数据。 对于任何想要使用文本数据的人来说,这都是一个很好的开始。
5.2 NLP中的嵌入
Mohammad Taher Pilehvar和Jose Camacho-Collados公开发布了即将出版的新书的初稿(,称为“Embeddings in Natural Language Processing”。 本书的想法是讨论嵌入的概念,这些概念代表了NLP中使用最广泛的技术。 正如作者介绍,该书包括“向量空间模型和单词嵌入的基础知识,以及基于预训练语言模型的最新句子和上下文嵌入技术。”
5.3 人工智能简要指南
James V Stone博士最近发表了他的新书,“A Brief Guide to Artificial Intelligence”,目的是全面概述 当前的AI系统及其完成一系列任务的成就。如摘要所述,该书“以非正式的风格编写,具有全面的词汇表和更多的阅读材料清单,这使其成为快速发展的AI领域的理想介绍。”

5.4 ML和DL课程
Sebastian Raschka发布了两份课程Introduction to Deep Learning and Generative Models视频。 n 可以在此repo中找到讲义和其他材料。
这是关于“离散微分几何”主题的另一套极好的讲座。
Peter Bloem已发布在VU University Amsterdam开设的机器学习入门课程完整的教学大纲,包括视频和演讲幻灯片,主题范围从线性模型和搜索到概率模型到序列数据模型。
5.5 CNN架构实现
Dimitris Katsios提供了一组出色的教程,CNN Architectures - implementations | MLT,它们为如何从原始论文中实现卷积神经网络(CNN)架构提供了指导。 他提出了有关如何逐步实现这些目标的方法,其中包括图表和代码,并具有推断模型结构的能力。 从这些指南中可以学到很多,可以指导其他人更有效地复现论文。
6、Noteworthy Mentions ⭐️
你可以在此处找到以前的新闻通讯。 您还可以在此处找到NLP简报先前版本的翻译版本。
几个月前,我们介绍了Luis Serrano关于Grokking Machine Learning的出色著作,听Luis探讨更多有关他的书以及他成为ML领域成功的教育者的故事,Grokking Machine Learning with Luis Serrano 。
以下是一些可能会引起您注意的新闻简报:Sebastian Ruder的NLP新闻简报,Made With ML,SIGTYP的新闻简报,MLT新闻简报,Nathan的AI新闻通讯等…
Jupyter现在带有可视调试器,这将使这个流行的数据科学框架更易于用于广泛用途。
Abhishek Thakur开放了一个很棒的YouTube频道,Abhishek Thakur,他在其中演示了如何在机器学习和NLP中使用现代方法的代码,一些视频包括从微调BERT模型分类到建立机器学习框架。
著名的强化学习教授和研究员David Silver因其在计算机游戏方面的突破性进展而被授予ACM计算奖,Silver带领Al Go团队击败了Lee Sedol。
对于那些有兴趣了解NLP流行方法(例如BERT和word2vec)的差异和背后工作原理的人,Mohd提供了关于这些方法的极好易懂且详细的概述,Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework。
TensorFlow 2.2.0-rc-1 已经发布,它包括诸如Profiler之类的功能,可以帮助你发现ML模型中的瓶颈并指导对这些模型的优化。 此外,Colab现在也已经默认使用TensorFlow 2。
GabrielPeyré在ML优化课程中提供了一组不错的笔记,包括凸分析,SGD,autodiff,MLP等。
dair.ai 更新
-
Call for Contributions to Open Science: We have opened a call for contributions to open science. There are many interesting collaborations in the pipeline. We want to open the invitation to anyone that’s interested in contributing to open science. Looking for volunteers, writers, reviewers, editors, developers, speakers, researchers, project maintainers,… Join us!
-
NLP Research Highlights Issue #1: ICYMI, in this article we highlight some NLP trends and topics with a focus on summarizing the what, how, and why of a selection of interesting and important NLP papers published in the last few months.
如果您希望在下一期NLP新闻通讯中共享任何数据集,项目,博客文章,教程或论文,请直接填写这份问卷.
Subscribe🔖至NLP新闻通讯,以在收件箱中接收以后的新闻。