

Publications 📙
Turing-NLG: A 17-billion-parameter language model by Microsoft
Turing Natural Language Generation (T-NLG) is a 17-billion-parameter language model proposed by Microsoft AI researchers. Besides being the largest known language model to date (depicted in the figure below), T-NLG is a 78-layers Transformer-based language model that outperforms the previous state-of-the-art results (held by NVIDIA’s Megatron-LM) on WikiText-103 perplexity. It was tested on a variety of tasks such as question answering and abstractive summarization while demonstrating desirable benefits such as zero short question capabilities and minimizing supervision, respectively. The model is made possible by a training optimization library called DeepSpeed with ZeRO, which is also featured later in this newsletter.
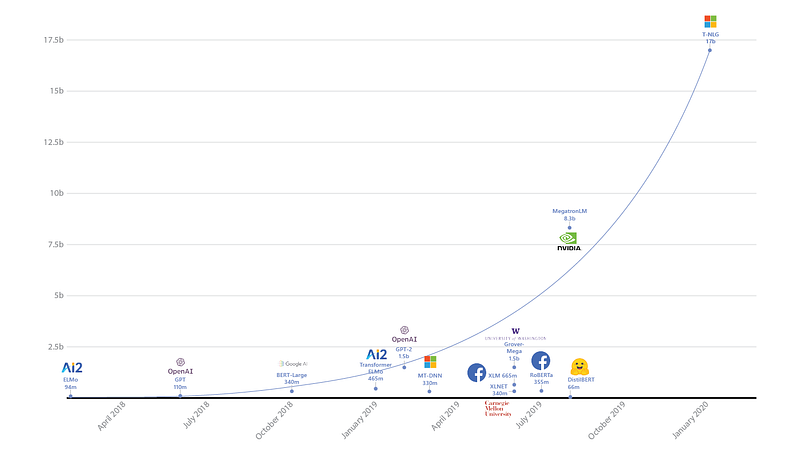
Language model sizes represented by parameters — source
Neural based Dependency Parsing
Miryam de Lhoneux released her Ph.D. thesis titled “Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages”. This work is about using neural approaches for dependency parsing in typologically diverse languages (i.e. languages that construct and express meaning in structurally different ways). This paper reports that RNNs and recursive layers could be beneficial for incorporating into parsers as they help to inform models with important linguistic knowledge needed for parsing. Other ideas include the use of polyglot parsing and parameter sharing strategies for parsing in related and unrelated languages.
End-to-end Cloud-based Information Extraction with BERT
A team of researchers published a paper describing how Transformer models like BERT can help for end-to-end information extraction in domain-specific business documents such as regulatory filings and property lease agreements. Not only can this type of work help to optimize business operations but it also shows the applicability and effectiveness of BERT-based models on regimes with very low annotated data. An application, and its implementation details, that operates on the cloud is also proposed and discussed (see figure below).
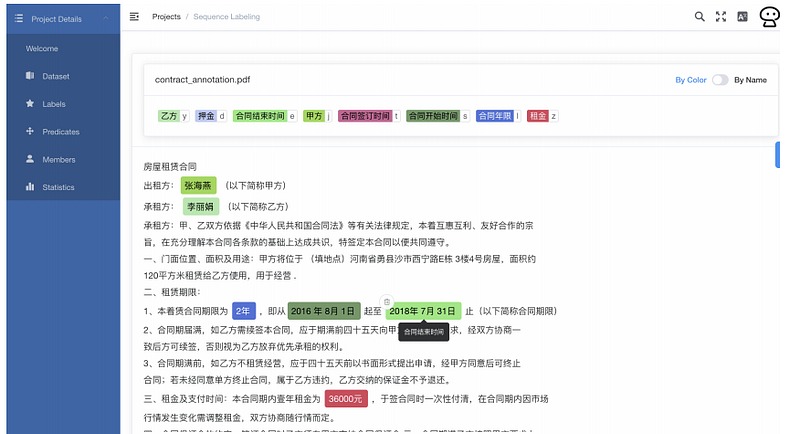
Question Answering Benchmark
Wolfson et al. (2020) published a question understanding benchmark and a method for breaking down a question that is necessary for computing an appropriate answer. They leverage crowdsourcing to annotate the required steps needed to break down questions. To show the feasibility and applicability of the approach, they improve on open-domain question answering using the HotPotQA dataset.
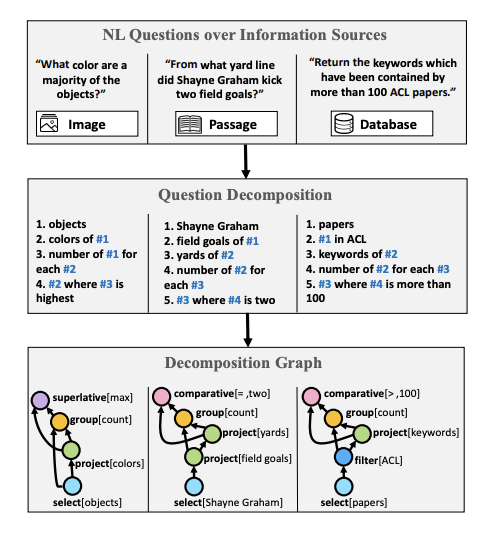
“Questions over different sources share a similar compositional structure. Natural language questions from multiple sources (top) are annotated with the QDMR formalism (middle) and deterministically mapped into a pseudo-formal language (bottom).” — source
Radioactive data: tracing through training
Facebook AI researchers recently published an interesting work that aims to mark images (referred to as radioactive data) so as to verify if that particular data set was used for training the ML model. They found that it is possible to use a clever marker that moves features towards a direction, which the model uses to help detect the usage of radioactive data even when only 1 percent of the training data is radioactive. This is challenging since any change in the data can potentially degrade the model accuracy. According to the authors, this work can “help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks”. It seems like an important approach in mission-critical ML applications. Check out the full paper here.
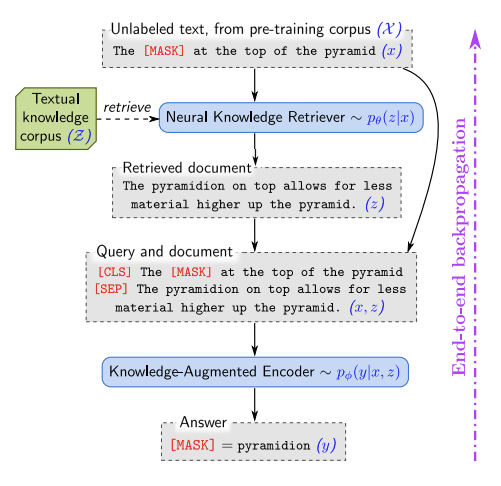
REALM: Retrieval-Augmented Language Model Pre-Training
REALM is a large-scale neural-based retrieval approach that makes use of a corpus of textual knowledge to pre-train a language model in an unsupervised manner. This approach essentially aims to capture knowledge in a more interpretable way by exposing the model to world knowledge that is used for training and predictions via backpropagation. Tasks approached and evaluated using REALM include open-domain question answering benchmarks. Besides the improvements in the accuracy of the model, other benefits include the modularity and interpretability components.
Creativity and Society 🎨
Allowing remote paper & poster presentations at scientific conferences
The past week there was the circulation of a petition to allow for remote paper and poster presentations at scientific conferences like ML related ones. Go read more about it on change.org. It seems Yoshua Bengio, a pioneer in deep learning, is advocating for people to go and sign the petition. He made this clear in his new blog.
Abstraction and Reasoning Challenge
François Chollet has recently posted a Kaggle competition where he released the Abstraction and Reasoning Corpus (ARC) that aims to encourage users to create AI systems that can solve reasoning tasks it has never been exposed to. The hope is to begin to build more robust AI systems that are able to better and quickly solve new problems on its own which could help to address the more challenging real-world applications such as improving self-driving cars that operate in extreme and diverse environments.
ML and NLP Publications in 2019
Marek Rei releases his yearly analysis of machine learning and NLP publication statistics from 2019. The conferences included in the analysis are ACL, EMNLP, NAACL, EACL, COLING, TACL, CL, CoNLL, NeurIPS, ICML, ICLR, and AAAI.
Growing Neural Cellular Automata
Morphogenesis is a self-organization process by which some creatures such as salamanders can regenerate or repair body damage. The process is robust to perturbations and adaptive in nature. Inspired by this biological phenomenon and a need to understand the process better, researchers published a paper titled “Growing Neural Cellular Automata”, which adopts a differentiable model for morphogenesis that aims to replicate behaviors and properties of self-repairing systems. The hope is to be able to build self-repairing machines that possess the same robustness and plasticity as biological life. In addition, it would help to better understand the process of regeneration itself. Applications that can benefit include regenerative medicine and modeling of social and biological systems.
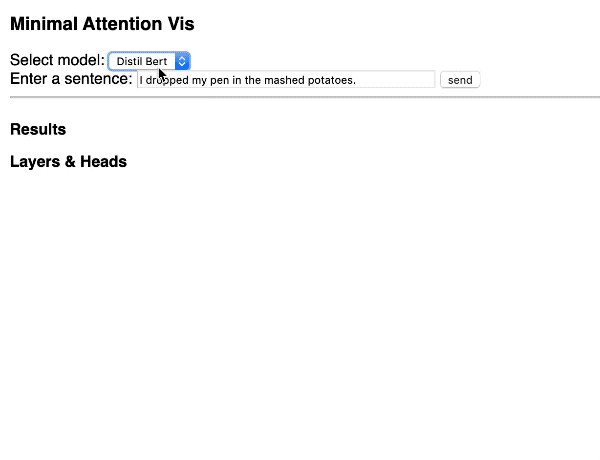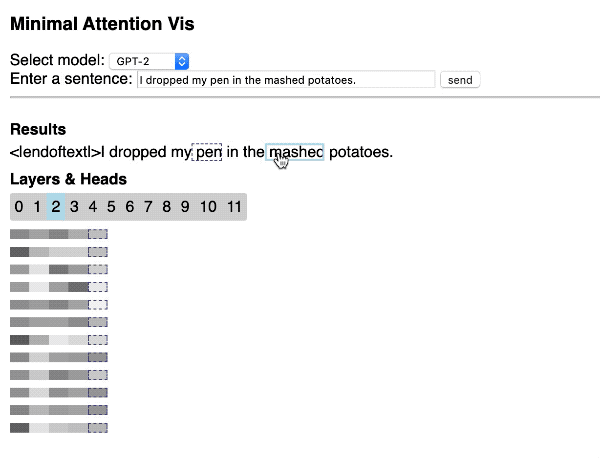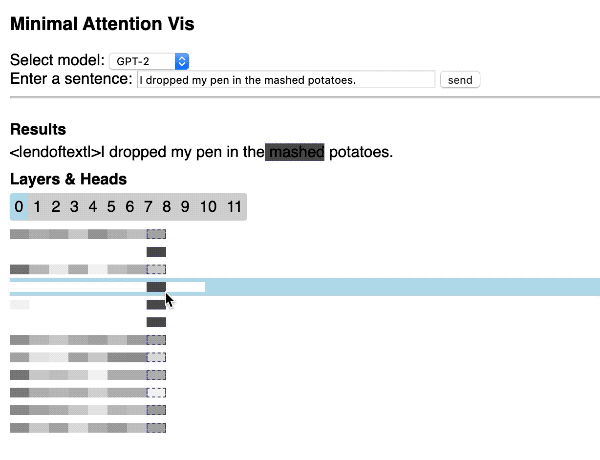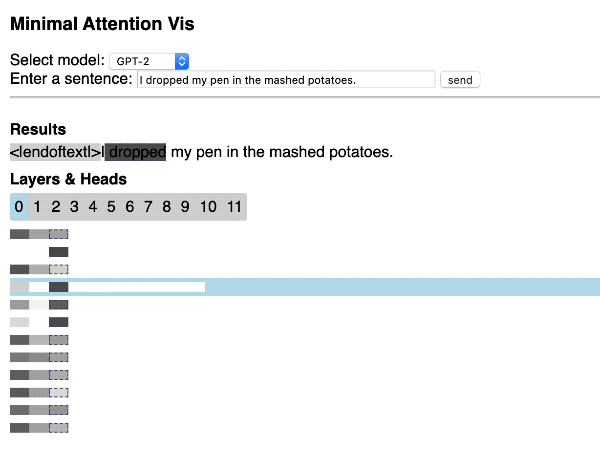
Visualizing Transformer attention
Hendrik Strobelt shared this great repository that shows how to quickly build a simple interactive Transformer attention visualization through a web application by using the Hugging Face library and d3.js.
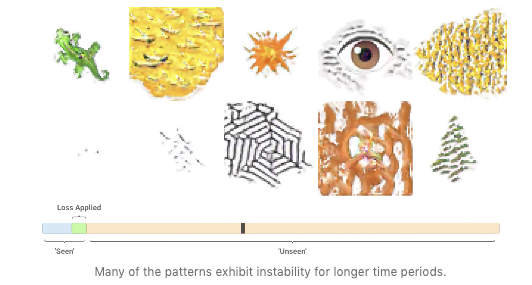
SketchTransfer: A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks
SketchTransfer proposes a new task to test the ability of deep neural networks to support invariance in the presence/absence of details. It has long been debated that deep networks cannot generalize to variations that have not yet been seen during training, something humans can do with relative ease such as dealing with the missing visual details when watching cartoons. The paper discusses and releases a dataset to help researchers carefully study the “detail-invariance” problem by providing unlabelled sketch images and labeled examples of real images.

Tools and Datasets ⚙️
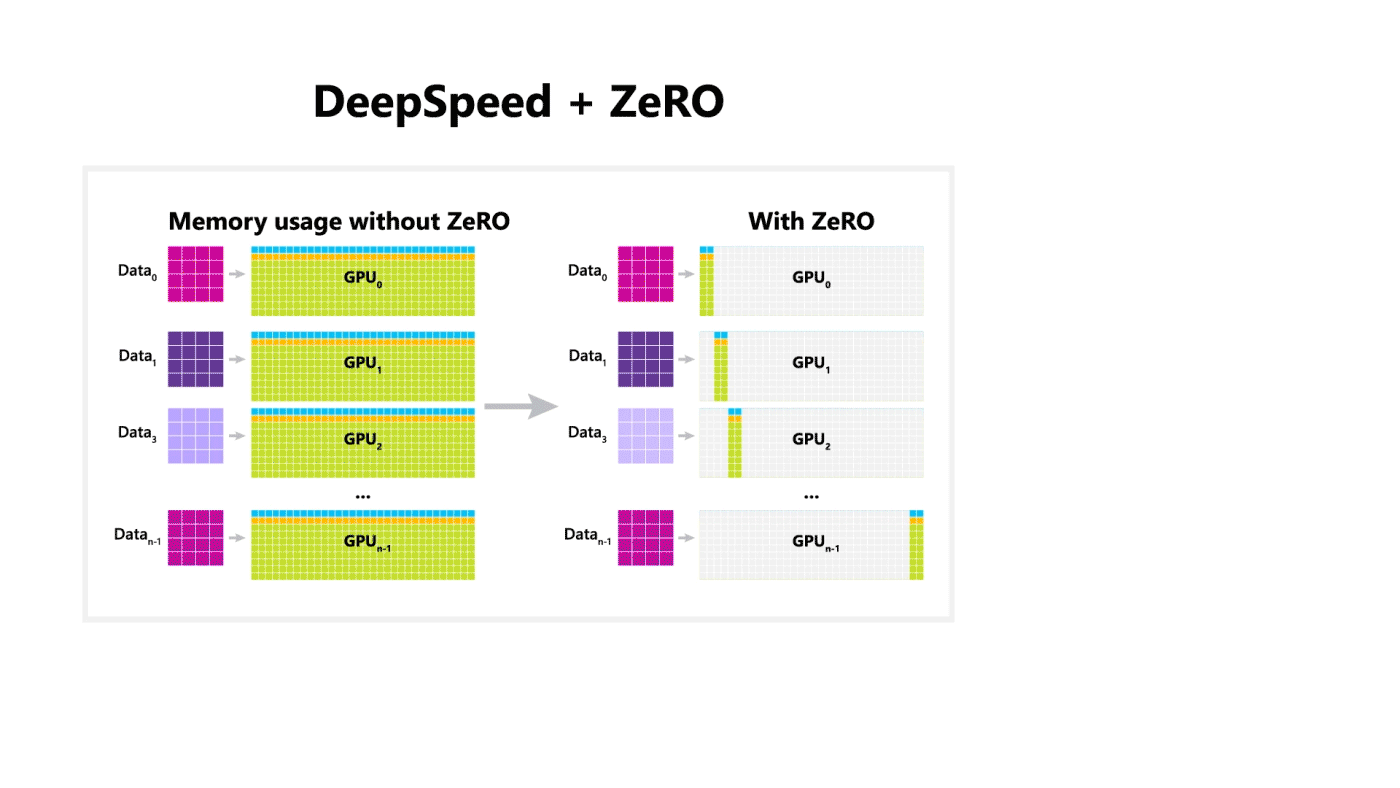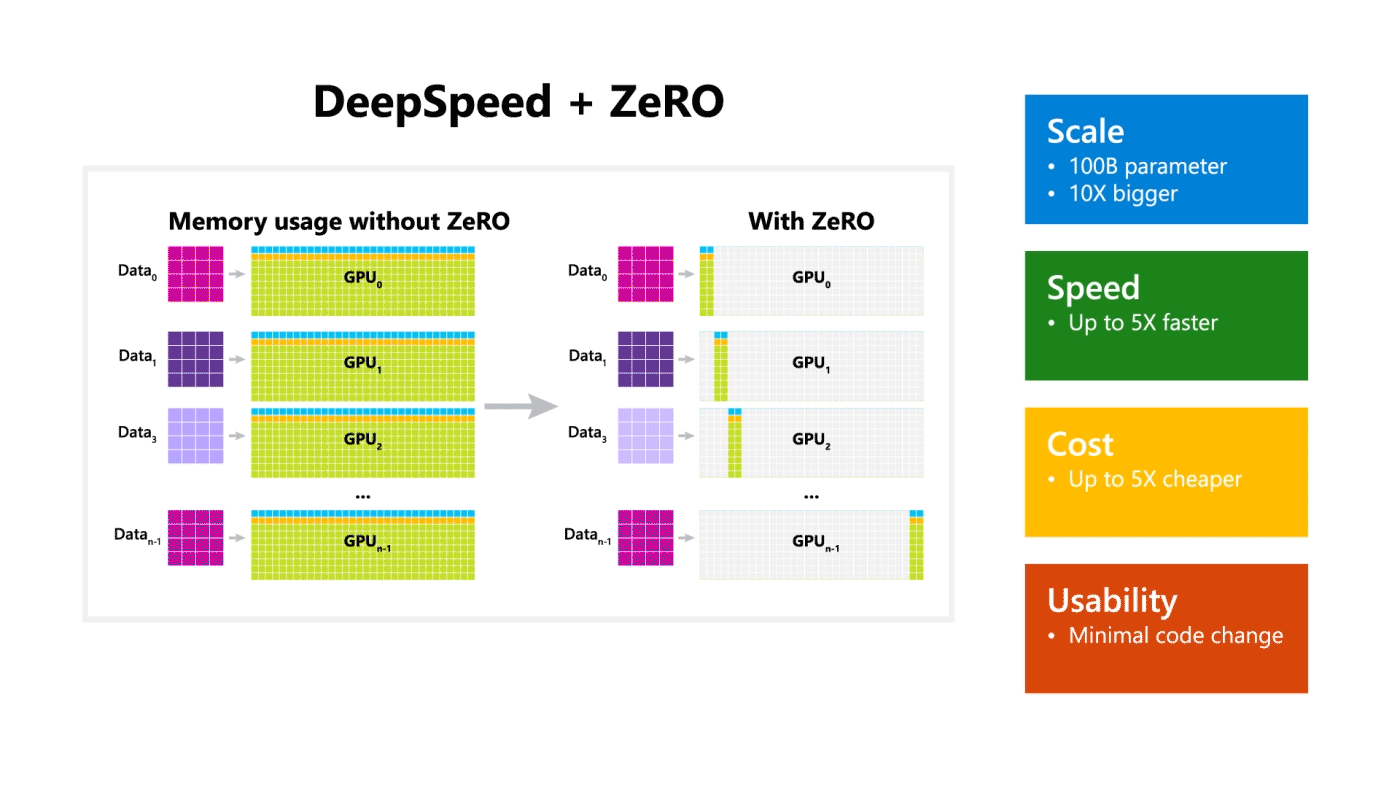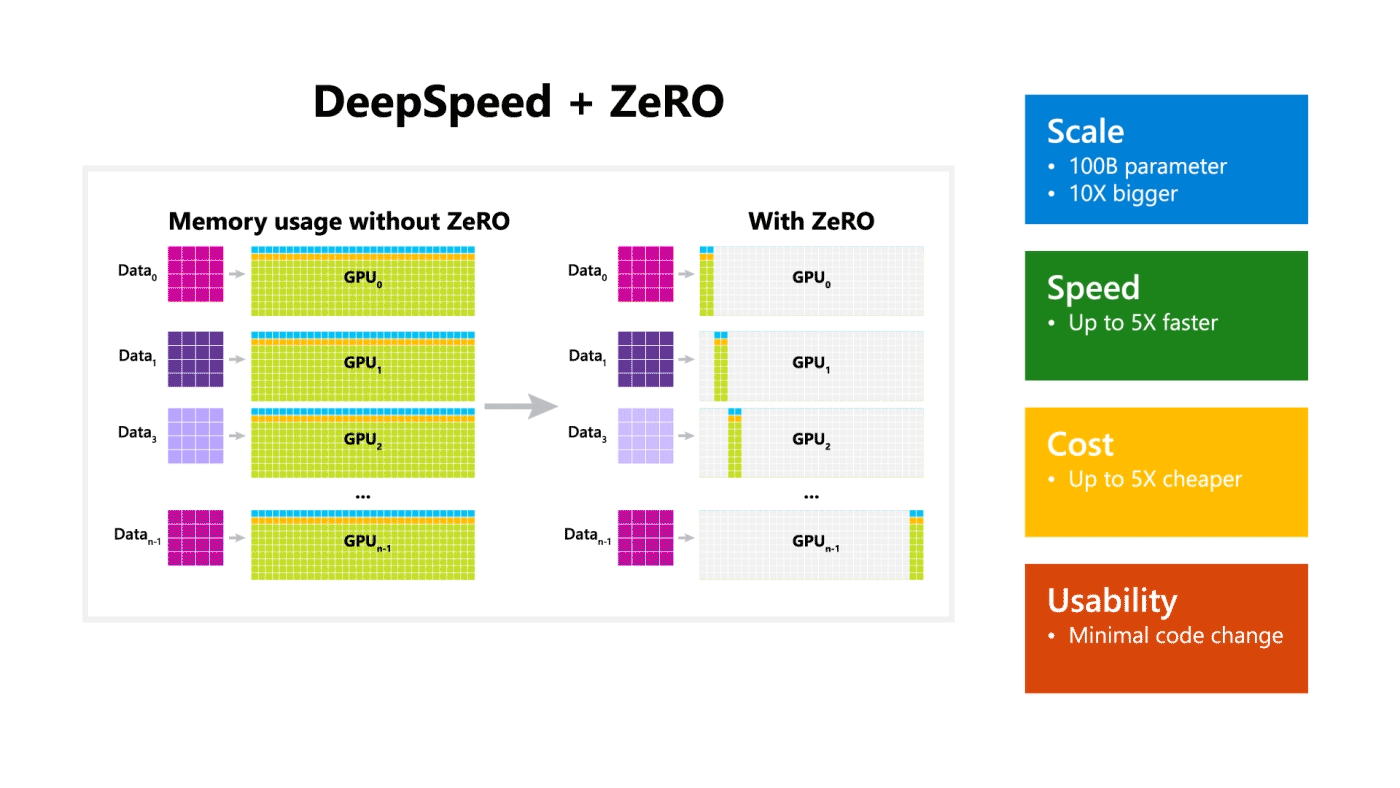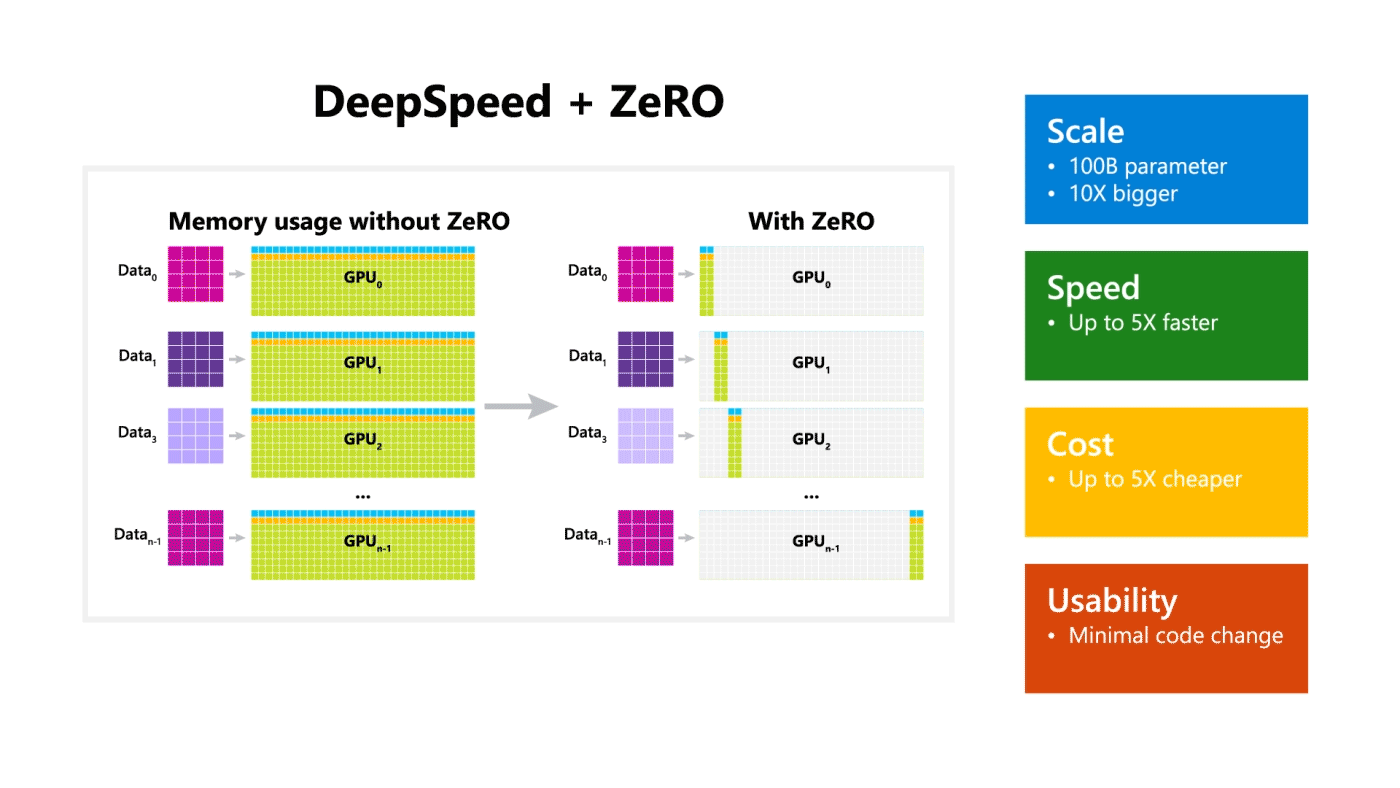
DeepSpeed + ZeRO
Microsoft open sources a training optimization library called DeepSpeed, which is compatible with PyTorch and can enable the ability to train a 100-billion-parameter model. The library focuses on four important aspects of training a model: scale, speed, cost, and usability. DeepSpeed was released together with ZeRO which is a memory optimization technology for enabling large-scale distributed deep learning in current GPU technology while improving throughput three to five times more than the best current system. ZeRO allows the training of models with any arbitrary size that can fit in the aggregated available memory in terms of shared model states.
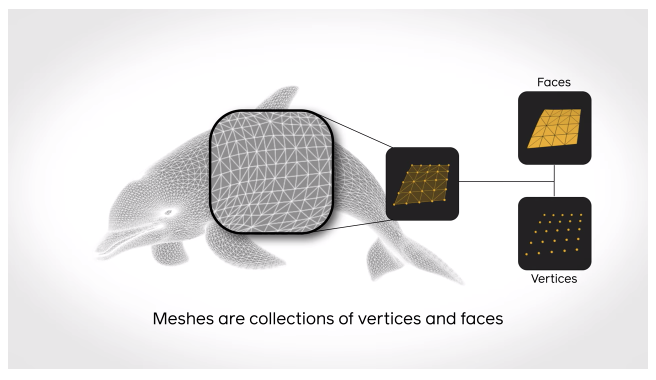
A library for conducting fast and efficient 3D deep learning research
PyTorch3D is an open-source toolkit for 3D based deep learning research. This PyTorch library aims to help with the support and understanding of 3D data in deep learning systems. The library consists of fast and optimized implementations of frequently used 3D operators and loss functions. It also comes with a modular differentiable renderer which helps to conduct research on complex 3D inputs and supports high-quality 3D predictions.
Managing Configuration of ML projects
Hydra is a Python-based configuration tool for more efficiently managing complex ML projects. It is meant to help PyTorch researchers by offering functional reuse of configurations for ML projects. The main benefit it offers is that it allows the programmer to compose the configuration like composing code, which means the configuration file can be easily overridden. Hydra can also help with automatically managing the working directory of your ML project outputs which is useful when needing to save and accessing the results of several experiments for multiple jobs. Learn more about it here.
A Toolkit for Causal Inferencing with Bayesian Networks
CausalNex is a toolkit for “causal inference with Bayesian Networks”. The tool aims to combine machine learning and causal reasoning for uncovering structural relationships in data. The authors also prepared an introductory guide on why and how to infer causation with Bayesian networks using the proposed Python library.

Google Colab Pro is now available
Google Colab is now offering a Pro edition, which offers advantages such as exclusive access to faster GPUs and TPUs, longer runtimes, and more memory.
TyDi QA: A Multilingual Question Answering Benchmark
Google AI releases TyDi QA which is a multilingual dataset that can encourage researchers to perform question answering on more typologically diverse languages that construct and express meaning in different ways. The idea is to motivate researchers to build more robust models on typologically distant languages, such as Arabic, Bengali, Korean, Russian, Telugu, and Thai, so as to generalize to even more languages.

Question Answering for Node.js
Hugging Face releases a question answering library based on DistilBERT and continues to make NLP more accessible. This model can run in production using Node.js with just 3 lines of code. The model leverages the fast implementation of Tokenizers, also built by Hugging Face, and TensorFlow.js (a popular library for using machine learning models with Javascript).
Ethics in AI 🚨
Identifying subjective bias in text
This podcast episode features Diyi Yang, a researcher in computational social science, who talks about how AI systems can help to identify subjective bias in textual information. This is an important area of research involving AI systems and NLP especially when we discuss the consumption of text media such as news headlines that can be easily framed to bias consumers when in reality they should aim to be more objective. From an application perspective, it becomes critical to automatically identify the subjective bias present in text media so as to help consumers become more aware of the content they are consuming. The episode also discusses how AI can also perpetuate bias.
Artificial Intelligence, Values and Alignment
The rise of AI systems and how they align human values is an active area of research that involves ethics in AI systems. DeepMind recently released a paper that takes a deeper look at the philosophical questions surrounding AI alignment. The report focuses on discussing two parts, technical (i.e., how to encode values that render reliable results from AI agents) and normative (what principles would be right to encode in AI), and how they relate and can be ensured. The paper pushes for a principle-based approach for AI alignment and to preserve fair treatment despite the difference in beliefs and opinions.
On Auditing AI Systems
VentureBeat reports that Google Researchers, in collaboration with other groups, created a framework called SMACTR that allows engineers to audit AI systems. The reason for this work is to address the accountability gap that exists with current AI systems that are put in the wild to be used by consumers. Read the full report here and the full paper here.
Articles and Blog posts ✍️
On model distillation for NLP systems
In a new episode of the NLP Highlights podcast, Thomas Wolf and Victor Sanh talk about model distillation and how it can be used as a feasible approach to compress large models like BERT for scalable real-world NLP based applications. This concept is further discussed in their proposed method called DistilBERT where they build smaller models (based on the same architecture of a bigger model) to try to mimic the behavior of the bigger model based on the output of that model. In essence, the smaller model (student) tries to fit the probability distribution of the teacher based on its output distribution.
BERT, ELMo, & GPT-2: How contextual are contextualized word representations?
Recently there has been a lot of talk on the success of contextualized methods like BERT for approaching a wide variety of complex NLP tasks. In this post, Kawin Ethayarajh attempts to answer the question of how contextual models like BERT, ELMo and GPT-2 and their contextualized word representation are? Topics include measures of contextuality, context-specificity, and comparisons between static embeddings and contextualized representations.
Sparsity in Neural Networks
François Lagunas, an ML researcher, wrote this great blog post discussing his optimism for adopting sparse tensors in neural network models. The hope is to employ some form of sparsity to reduce the size of current models that at some point become unpractical due to their size and speed. This concept may be worth exploring in ML due to the sheer size of current models like Transformers (often relying on billions of parameters). However, the implementation details to support efficient sparsity in neural networks on GPUs are not so clear from a developer tool perspective and that is something the machine learning community is working on already.
Training your own language model
If you are interested to learn how to train a language model scratch, check out this impressive and comprehensive tutorial by Hugging Face. They obviously leverage their own libraries Transformers and Tokenizers to train the model.
Tokenizers: How machines read
Cathal Horan published an impressive and very detailed blog post about how and what type of tokenizers are being used by the most recent NLP models to help machine learning algorithms learn from textual information. He also discusses and motivated why tokenization is an exciting and important active area of research. The article even shows you how to train your own tokenizers using tokenization methods like SentencePiece and WordPiece.
Education 🎓
Machine Learning at VU University Amsterdam
You can now follow the 2020 MLVU machine learning course online, which includes the full set of slides, videos, and syllabus. It is meant to be an introduction to ML but it also has other deep learning related topics such as VAEs and GANs.

Math resources for ML
Suzana Ilić and the Machine Learning Tokyo (MLT) have been doing amazing work in terms of democratizing ML education. For example, check out this repository showcasing a collection of free online resources for learning about the foundations of mathematical concepts used in ML.
Introduction to Deep Learning
Keep track of the “Introduction to Deep Learning” course by MIT on this website. New lectures will be posted every week and all the sides and videos, including coding labs, will be published.
Deep Learning with PyTorch
Alfredo Canziani has published the slides and notebooks for the minicourse on Deep Learning with PyTorch. The repository also contains a companion website that includes text descriptions of the concepts taught in the course.
Missing Semester of Your CS
The “Missing Semester of Your CS” is a great online course that consists of material that could potentially be useful for data scientists with non-dev backgrounds. It includes topics such as shell tools and scripting and version control. The course was published by MIT faculty members.
Advanced Deep Learning
CMU released the slides and syllabus for the “Advanced Deep Learning” course which includes topics such as autoregressive models, generative models, and self-supervised/predictive learning, among others. The course is meant for MS or Ph.D. students with an advanced background in ML.
Noteworthy Mentions ⭐️
You can catch the previous NLP Newsletter here. The issue covers topics such as improving conversational agents, releases of language-specific BERT models, free datasets, releases of deep learning libraries, and much more.
Xu et al. (2020) proposed a method for progressively replacing and compressing a BERT model by dividing it into its original components. Through progressive replacement and training, there is also the advantage of combining the original components and compacted versions of the model. The proposed model outperforms other knowledge distillation approaches on the GLUE benchmark.
Here is another interesting course called “Introduction to Machine Learning” which covers the ML basics, supervised regression, random forests, parameter tuning, and many more fundamental ML topics.
🇬🇷 Greek BERT (GreekBERT) model is now available for use through the Hugging Face Transformers library.
Jeremy Howard publishes a paper describing the fastai deep learning library which is widely used for research and to teach their open courses on deep learning. A recommended read for software developers working on building and improving deep learning and ML libraries.
Deeplearning.ai completes the release of all four courses of the TensorFlow: Data and Deployment Specialization. The specialization mainly aims to educate developers on how to efficiently and effectively deploy models in different scenarios and make use of data in interesting and effective ways while training models.
Sebastian Raschka recently published a paper titled “Machine Learning in Python: Main developments and technology trends in data science, machine learning, and artificial intelligence”. The paper serves as a comprehensive review of the machine learning tools landscape. It is an excellent report for understanding the various advantages of some libraries and concepts used in ML engineering. In addition, a word on the future of Python-based machine learning libraries is provided.