

First of all, I can’t thank ❤️ all of you enough for the incredible support and encouragement to continue with the NLP Newsletter. This effort requires tedious research and editing which I find to be both rewarding and also useful to provide you the best content. Hope you are enjoying them because I do. 😉
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.
Publications 📙
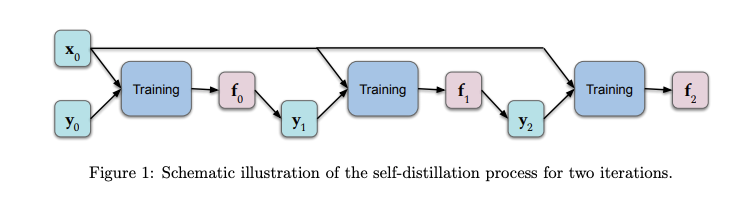
A theoretical understanding of self-distillation
In the context of deep learning, self-distillation is the process of transferring knowledge from one architecture to another identical architecture. Predictions of the original model are fed as target values to the other model while training. Besides having desirable properties, such as reducing model size, empirical results demonstrate that this approach works well on held-out datasets. A group of researchers recently published a paper that provides a theoretical analysis with the focus to better understand what is happening in this knowledge distillation process and why it is effective. Results show that a few rounds of self-distillation amplify regularization (by progressively limiting the number of basis functions that represent the solution) which tends to reduce over-fitting. (Read the full paper here)
The 2010s: Our Decade of Deep Learning / Outlook on the 2020s
Jürgen Schmidhuber, a pioneer in Artificial Intelligence, recently posted a new blog post focusing on providing a historical overview of deep learning since 2010. Some topics include LSTMs, feedforward neural networks, GANs, deep reinforcement learning, meta-learning, world models, distilling NNs, attention learning, etc. The article concludes with an outlook on the 2020s encouraging attention to pressing issues such as privacy and data markets.
Using neural networks to solve advanced mathematics equations
Facebook AI researchers published a paper that claims to propose a model trained on math problems and matching solutions to learn to predict possible solutions for tasks such as solving integration problems. The approach is based on a novel framework similar to what’s used in neural machine translation where mathematical expressions are represented as a kind of language and the solutions being treated as the translation problem. Thus, instead of the model outputting a translation, the output is the solution itself. With this, the researchers claim that deep neural networks are not only good at symbolic reasoning but also for more diverse tasks.
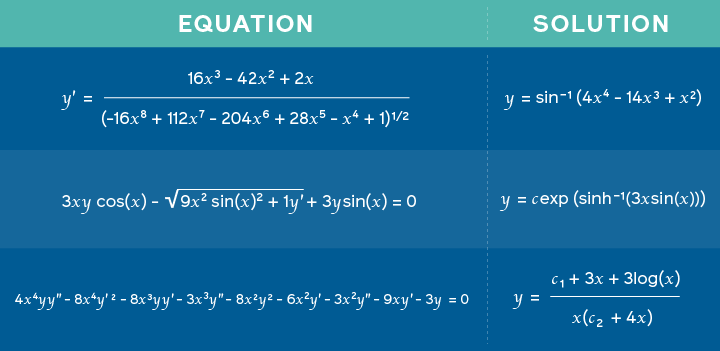
Equations fed as input together with the corresponding solution outputted by the model — source
Creativity and Society 🎨
AI for scientific discovery
Mattew Hutson reports how artificial intelligence (AI) can be used to produce emulators that have an important use in modeling complex natural phenomena that could, in turn, lead to different types of scientific discovery. The change with building these emulators is that they often require large-scale data and extensive parameter exploration. A recent paper proposes DENSE an approach based on neural architecture search to build accurate emulators while only relying on a limited amount of training data. They tested it by running simulations for cases including astrophysics, climate science, and fusion energy, among others.
Improving image-to-illustration translation
GANILLA is an approach that proposes the use of GANs to improve the transfer of both style and content in the unpaired image-to-image translation task. In particular, a model for image-to-illustration is proposed (with an improved generator network) and evaluated based on a new framework for quantitative evaluation that considers both content and style. The novelty of the work is in the proposed generator network that considers a balance between style and content which previous models fail to achieve. Code and pretrained models are made available. Read the full paper here.

Andrew Ng talks about interest in self-supervised learning
Andrew Ng, the founder of deeplearning.ai, joins the Artificial Intelligence podcast to talk about topics including his early days doing ML, the future of AI and AI education, recommendations for proper use of ML, his personal goals and what ML techniques to pay attention to in the 2020s.
Andrew explained why he is very excited about self-supervised representation learning. Self-supervised learning involves framing a learning problem that aims to obtain supervision from the data itself to make use of large amounts of unlabeled data which is more common than clean labeled data. The representations, as opposed to the performance of the task, are important and can be used to address downstream tasks similar to what’s being used in language models such as BERT.
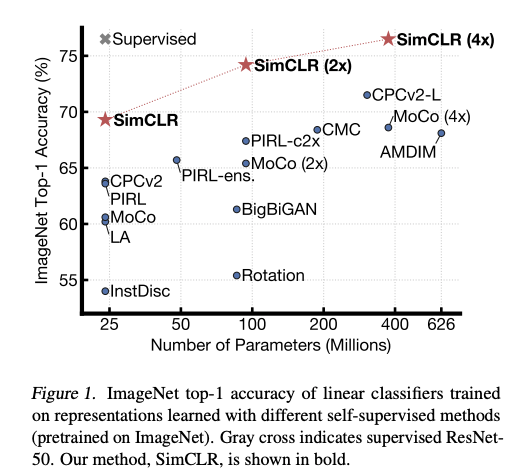
There is also a lot of interest to use self-supervised learning for learning generalized visual representations that make models more accurate in low-resource settings. For instance, a recent method called SimCLR (led by Geoffrey Hinton) proposes a framework for contrastive self-supervised learning of visual representations for improving image classification results in different settings such as transfer learning and semi-supervised learning.
Tools and Datasets ⚙️
JAX libraries
JAX is a new library that combines NumPy and automatic differentiation for conducting high-performance ML research. To simplify pipelines for building neural networks using JAX, DeepMind released Haiku and RLax. RLax simplifies the implementation of reinforcement learning agents and Haiku simplifies the building of neural networks using familiar object-oriented programming models.
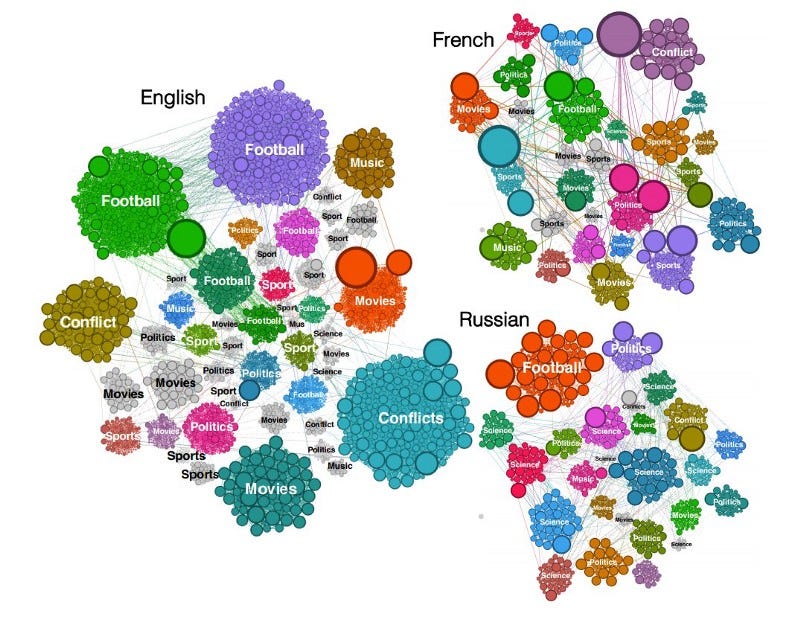
A tool for processing Wikipedia data
Sparkwiki is a tool to process Wikipedia data. This release is part of many efforts to enable interesting behavioral analytics research such as capturing trends and language biases across different language editions of Wikipedia. The authors discovered that independent of language, the browsing behavior of Wikipedia users shows that they tend to share common interests for categories such as movies, music, and sports but differences become more apparent with local events and cultural particularities.
Rust Tokenizers, DistilBERT base cased, Model cards
A new Transformers release by Hugging Face includes the integration of their fast tokenizer library which aims to speed up models like BERT, RoBERTa, GPT2, and other community-built models.
Ethics in AI 🚨
Ethical considerations for NLP and ML models
In a new episode of the NLP Highlights, Emily Bender and hosts talk about some ethical considerations when developing NLP models and technologies in the context of both academia and real-world usage. Some of the topics in the discussion include ethical considerations when designing NLP tasks, data collection approaches, and eventually publishing results.
In addition to all the considerations above, a concern that is always discussed in the AI community is focusing too much on optimizing a metric, which goes against the foundations of what AI aims to achieve. Rachel Thomas and David Uminsky discuss where this can go wrong through a thorough analysis of different use cases. They also propose a simple framework for mitigating the problem which involves the use and combination of multiple metrics, followed by the involvement of those affected directly by the technology.
Articles and Blog posts ✍️
The Annotated GPT-2
Aman Arora recently published an exceptional blog post appropriately titled “The Annotated GPT-2” explaining the inner workings of the Transformer based model called GPT-2. His approach was inspired by The Annotated Transformer that took an annotation approach to explain the important parts of the model through code and easy-to-follow explanations. Aman went through a great effort to re-implement OpenAI’s GPT-2 using PyTorch and the Transformers library by Hugging Face. It’s brilliant work!

Beyond BERT?
Interesting take by Sergi Castella on what lies beyond BERT. The main topics include improving metrics, how Hugging Face’s Transformers library empowers research, interesting datasets to look at, unpacking models, etc.
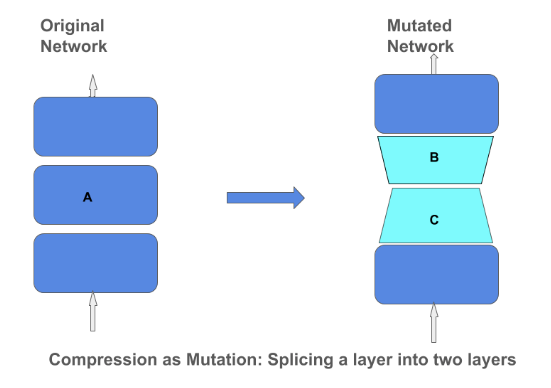
Matrix Compression Operator
The TensorFlow Blog published a blog post explaining the techniques and importance behind compressing matrices in a deep neural network model. Matrix compression can help to build more efficient tiny models that can be incorporated into smaller devices such as phones and home assistants. Focusing on the compression of the models via methods like low-rank-approximation and quantization means that we don’t need to compromise the quality of the model.
Education 🎓
Fundamentals of NLP
I am excited to release a draft of Chapter 1 of my new series called Fundamentals of NLP. It teaches NLP concepts starting from the basics while sharing best practices, important references, common mistakes to avoid, and what lies ahead in NLP. A Colab notebook is included and the project will be maintained here.

[Online] Review/Discussion: Part I Mathematical Foundations Reading Session
Machine Learning Tokyo is hosting a remote online discussion reviewing chapters that were covered in their recent online study sessions. The group had previously studied chapters based on the book called Mathematics For Machine Learning written by Marc Peter Deisenroth, A Aldo Faisal, and Cheng Soon Ong. The event is scheduled for March 8, 2020.
Book recommendations
In a previous segment, we discussed the importance of matrix compression for building tiny ML models. If you are interested to learn more about how to build smaller deep neural networks for embedded systems check out this great book called TinyML by Pete Warden and Daniel Situnayake.

Another interesting book to keep an eye on is the upcoming title “Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD” by Jeremy Howard and Sylvain Gugger. The book aims to provide the necessary mathematical foundation to build and train models to approach tasks in the areas of computer vision and NLP.

Noteworthy Mentions ⭐️
You can access the previous issue of the NLP Newsletter here.
Torchmeta is a library that allows ease of use of related data loaders for meta-learning research. It was authored by Tristan Deleu.
Manuel Tonneau wrote a piece offering a closer look at some of the machinery involved in language modeling. Some topics include greedy and beam search and nucleus sampling.
MIT releases the full syllabus and course schedule for the course titled “Introduction to Deep Learning”, including videos for lectures already delivered. They aim to release video lectures and slides every week.
Learn how to train a model for named entity recognition (NER) using a Transformer based approach in under 300 lines of code. You can find the accompanying Google Colab here.
If you have any datasets, projects, blog posts, tutorials, or papers that you wish to share in the next iteration of the NLP Newsletter, please free to reach out to me at ellfae@gmail.com or DM on Twitter.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.