

Welcome to the first quarterly issue of the natural language processing (NLP) Research Highlights series. The goal is to provide you with a summary and a closer look at a collection of interesting NLP research papers and topics that we recently came across. We aim to distill the important parts of each paper and to make these works more approachable to the reader.
This series will also allow us to have a deeper discussion and analysis of some of the featured NLP works. In essence, this will be a dedicated series for summarizing interesting NLP research. Some of the summaries below will also be transferred to a new repository called NLP Paper Summaries where we are maintaining a collection of NLP paper summaries for making interesting and important work in NLP more approachable and accessible.
For this first issue, we take a closer look at some of our favorite NLP papers from the past issues of the NLP Newsletter that we thought could be interesting to discuss further. Below is the list of topics discussed:
- 1. On improving language models
- 2. Transfer learning for information extraction and information retrieval
- 3. On improving conversational agents
- 4. Interpreting language models
- 5. On improving text generation
- 6. State-of-the-art speech recognition
- 7. A theoretical understanding of self-distillation
- 8. Symbolic reasoning and machine translation
- 9. Question Answering
- 10. Neural based Dependency Parsing
1. On improving language models
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Text-to-Text Transformer is a method that brings together all the lessons learned and recent improvements from NLP transfer learning models into one unified framework called Text-to-Text Transfer Transformer (T5 for short)(Raffel et al., 2019).
This work proposes that most NLP tasks can be formulated in a text-to-text format, suggesting that both the inputs and outputs are texts, which is the case for a variety of NLP tasks. The authors claim that this “framework provides a consistent training objective both for pre-training and fine-tuning”. T5 is essentially an encoder-decoder Transformer that applies various improvements in particular to the attention components of the model. The model was pre-trained on a newly released dataset called Colossal Clean Crawled Corpus and achieved SOTA results on NLP tasks such as summarization, question answering, and text classification.
This work proposes a unified approach that can allow ease of analysis of transfer learning for NLP approaches. This has been a challenge as current methods have different objectives and training procedures and are difficult to compare. T5 allows experimentation of different datasets, tasks, objectives for better understanding the limits, efficiency, and effectiveness of transfer learning for NLP models and how they scale in terms of data and modeling.
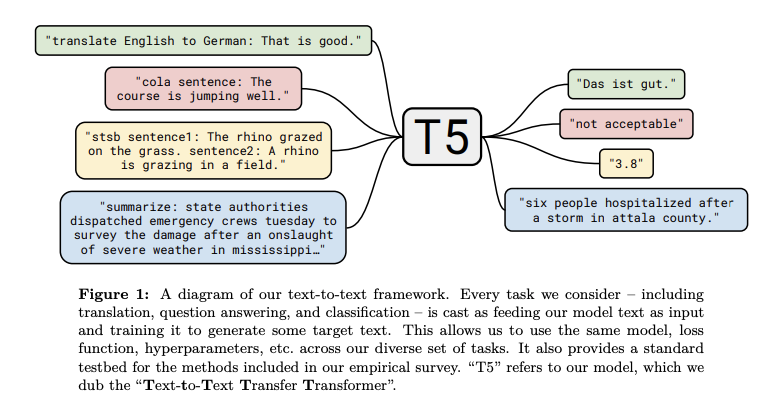
In the future, authors aim to build language-agnostic models, cheaper models that achieve stronger performance, improved knowledge extraction through smarter and efficient pretraining tasks, among other strategies.
Turing-NLG: A 17-billion-parameter language model by Microsoft
Turing Natural Language Generation (T-NLG) is a 17-billion-parameter language model proposed by Microsoft AI researchers. Besides being the largest known language model to date (as depicted in the figure below), T-NLG is a 78-layers Transformer-based language model that outperforms the previous state-of-the-art results (held by NVIDIA’s Megatron-LM) on WikiText-103 perplexity. It was tested on a variety of tasks such as question answering and abstractive summarization while demonstrating desirable benefits such as zero short question capabilities and minimizing supervision, respectively. The model is made possible by a training optimization library called DeepSpeed with ZeRO, ZeRO (Samyam et al., 2019) being the solution for reducing memory footprint while at the same time scaling computation.
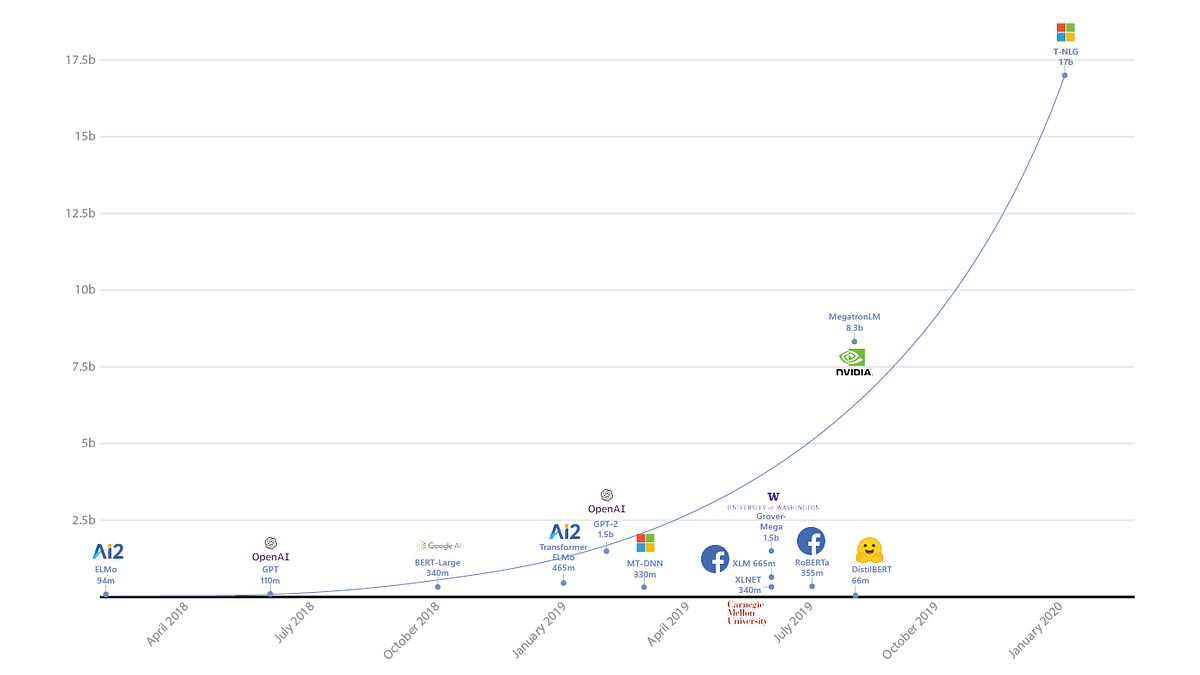
Language models represented by the size of parameters (figure adopted from DistilBERT)
T-NLG basically uses 78 Transformer layers and is trained using the same hyperparameters as Megatron-LM. Using the optimization library called DeepSpeed, the language model training time is reduced by three times. T-NLG is trained on the same data as Megraton-LM and the pre-trained version was used to test on the task of WikiTex-103 perplexity and LAMBDA next word prediction accuracy. T-NLG (17B) outperforms both OpenAI GPT-2 (1.5B) and Megatron-LM (8.3B) on both tasks.
It is interesting to see that training a language model on 17 billion parameters shows improvement in results as demonstrated in the experiments with the downstream NLP tasks (e.g. question answering and abstractive summarization). As claimed by the authors, the bigger the models, the better it generalizes to perform better on downstream tasks, especially in the low-data regime. This also means that the technology stack, including libraries and hardware, used to train these enormous language models have to be optimized, which is the innovative part proposed by T-NLG. Optimal hardware setup and a reduction in model-parallelism degree allow T-NLG to be trained more efficiently with fewer GPUs (256) than the state-of-the-art at the time, Megatron-ML (1024 NVIDIA GPUs).
It will be interesting to see how Microsoft researchers apply T-NLG in production across their different products and build more fluent chatbots and digital assistants for improving customer experience.
Reformer: The Efficient Transformer
Transformer models efficiently extend the context window that helps to improve language understanding while at the same time requiring less computation and speeding up training via a self-attention mechanism. However, as you keep increasing the context window to even larger sizes at some point the Transformer becomes impractical due to the number of comparisons it has to perform and its memory requirements. Thus, it may only be possible to apply the Transformer model to limited text sizes and to generate short statements or pieces of music.
To address some of the limitations identified in the Transformer model, Kitaev et al. (2020) propose an efficient variant of a Transformer model called Reformer. The two main objectives are to allow for longer context by reducing the complexity of the attention mechanism and to reduce memory footprint.
To achieve both requirements, Reformer first uses locality-sensitive-hashing (LSH) to group similar vectors together and creates segments out of them, which enable parallel processing. The attention is then applied to these smaller segments and corresponding neighbouring parts — this is what reduces the computational load.
Secondly, memory efficiency is accomplished using reversible layers that allow the input of each layer to be recomputed on-demand (as opposed to storing it in memory) while training. This is a simple technique that avoids the model of the need to store the activations of each layer in memory, which is very expensive when the context window is too large and you are working with multiple layers that you need to backpropagate through — typically the case with a Transformer model. The way it works is that the activations (input) coming from the last layer are used to recover the activations in the intermediate layer. This is made possible by simply running the network in reverse which is achievable through the subtraction of the activations that were applied at each layer, depicted as part “c” in the figure below. Part “b” shows that two sets of activations need to be defined to be able to achieve the recovery of activations. Part “a” is referring to the standard transformation applied to inputs that go through a layer as applied in residual networks.
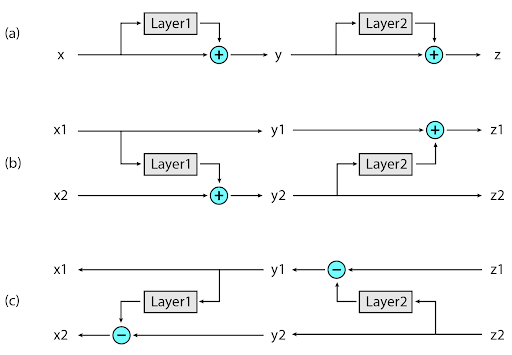
(Nikita et al., 2020)
Applications, where the Reformer is beneficial involve those that depend on large-context data such as in image generation and for generating long and coherent sequences.
ELECTRA: Pre-training text encoders as discriminators rather than generators
Clark et al. (2020) propose a more sample-efficient pretraining task called replaced token detection for training a language model that is more efficient than masked language modeling (MLM) pretraining methods such as BERT. The model, coined ELECTRA, and its contextualized representations outperform those of BERT (Devlin et al., 2019) and XLNET (Yang et al., 2019) on the same data and model size. The method particularly works well on the low-compute regime. This is an effort to build smaller and cheaper language models.
In essence, the model proposes a new pre-training task called replaced token detection in which the model is trained to distinguish the real input tokens from generated replacements. First, some tokens from the input are corrupted and replaced by samples from a generator network, typically a small MLM. This means that the generator part of the model (shown in the figure below) learns to predict the original identities of the corrupted tokens. The network is then pre-trained as a discriminator that aims to predict whether each token is an original or a replacement, i.e. replaced token prediction. This differs from the use of just the MLM task which trains the network to instead predict the original identities of the corrupted tokens.
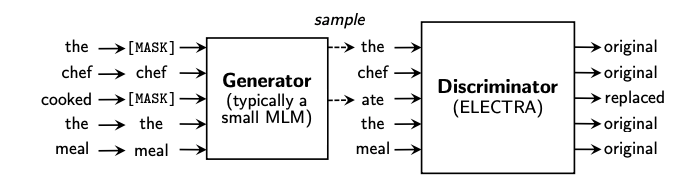
ELECTRA— (Clark et al., 2020)
The main advantages of this new pre-training task are that it is more computationally and parameter efficient as all the input is considered and after pre-training only the discriminator is fine-tuned for downstream tasks, while the generator is left out. This means that we don’t need to worry about the discrepancy of the [MASK] token during fine-tuning as is the case with the original BERT model. This particular model is shown to be effective for language representation learning and requiring less compute than other methods such as GPT and XLNet. It could pave the way for building smaller and more effective models that optimize for pre-training.
REALM: Retrieval-Augmented Language Model Pre-Training
REALM is a large-scale neural-based retrieval approach that makes use of a corpus of textual knowledge to pre-train a language model in an unsupervised manner (Guu et al., 2020). This approach essentially aims to capture knowledge in a more interpretable way by exposing the model to world knowledge that is used for training and predictions via backpropagation. Tasks approached and evaluated using REALM include open-domain question answering benchmarks. Besides the improvements in the accuracy of the model, other benefits include the modularity and interpretability components.
When training language models, current methods implicitly store the knowledge learned in the parameters of the neural network. This means that it is difficult to say what and where exactly this knowledge is stored. It also means that the more knowledge you want to capture the bigger the networks and the more compute and space are required. REALM offers a way to augment language models by explicitly exposing the model to world knowledge which it can refer to during inference.
During the pre-training of the language model, a neural retrieval module is applied. This neural knowledge retrieval is trained to retrieve useful knowledge from a corpus such as Wikipedia. Then that knowledge is passed on to the knowledge auto-encoder that then predicts the original value of a [MASK] token where masked language model (MLM) is employed as the pretraining task. In essence, the knowledge retriever and the knowledge augmented encoder are jointly trained in an unsupervised way via said task (depicted left of the figure below). The language model is trained is such a way that the knowledge retriever is rewarded if it improves the language model’s perplexity or penalized if it’s uninformative. Once the parameters of both those components have been trained, the fine-tuning process takes in supervised examples that allow for fine-tuning on a downstream task (depicted right of the figure below).
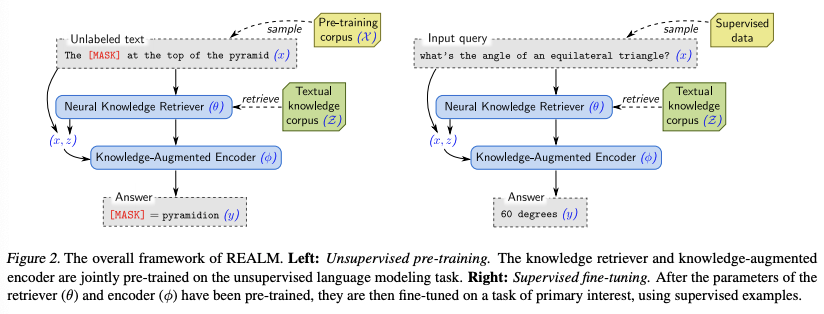
Open-QA was used for fine-tuning the model where the objective is to produce the answer in the form of a string. REALM outperforms all other previous methods while providing some interpretability due to the way the model is exposed to external knowledge.
2. Transfer learning for information extraction and information retrieval
Information Retrieval with BERT
One of the fields that have made tremendous progress this past year was NLP with a range of improvements and new research directions. Two of those domains that could potentially benefit from transfer learning NLP are information extraction and information retrieval.
For information retrieval, there is an opportunity to build search engines that improve semantic search using modern NLP techniques such as contextualized representations produced by say a Transformer-based model like BERT (Devlin et al., 2018). Google released a blog post a couple of months back discussing how they are leveraging BERT models for improving and understanding searches.
Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents
On the information extraction side of things, Zhang et al. (2020) adopt BERT for extracting important content elements from domain-specific business documents such as regulatory filings and property lease agreements. The model is used in the context of a cloud environment that allows annotation and inferencing on uploaded documents. Not only can this type of work help to optimize business operations but it also shows the applicability and effectiveness of BERT-based models on low-annotated data regimes and documents that are not the typical type of text that most NLP techniques process. For instance, it can certainly help to automatically extract certain types of information from contracts so that they can better be queried.
This process of extracting content elements is possible because transformer-based models already support sequence labeling. The model is applied to domain-specific data, so the authors aim to find out how good BERT — trained on general natural language corpora — can perform in such scenarios. Keep in mind that BERT models are typically applied to natural language corpora which rarely contains the linguistic structures and vocabularies that would arise in business documents. This makes the task challenging. However, the authors discover that it only takes ~100 documents to fine-tune BERT to do well on the content extraction task. BERT also appears to adapt to the linguistic properties of the domain-specific data and generalizes to the unseen expressions of the content elements (e.g. leaseholder and tenant) which is desirable when dealing with domain-specific data.
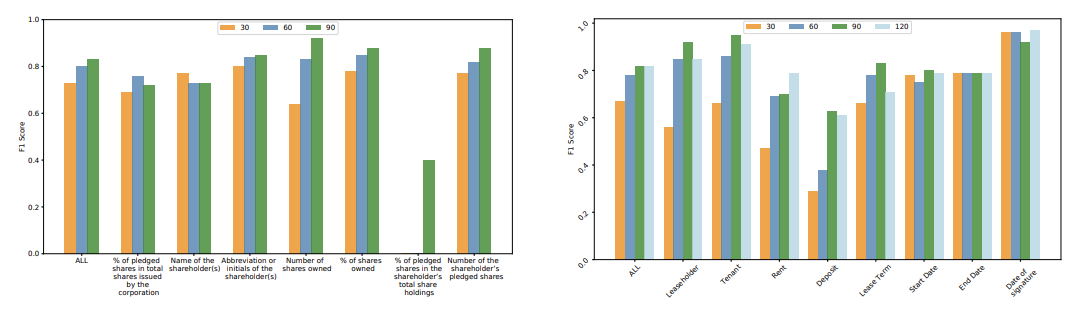
F1 score on regulatory filings (left) and lease agreements (right) using different entities and with a varying number of documents used to fine-tune the model — (Zhang et al., 2020).
It is very exciting to see how BERT was applied to sequence labeling on these types of domain-specific business documents. Going forward, we should expect more applications of transfer learning for NLP in different domains such as health and finance.
Neural Information Extraction From Natural Language Text
If you are interested in the topic of neural-based information extraction approaches, Pankaj Gupta publicly released his Ph.D. thesis titled “Neural Information Extraction From Natural Language Text”. The main discussion is about how to efficiently extract the semantic relationships from natural language text using neural-based approaches. Such research effort aims to contribute to building structured knowledge bases, that can be used in a series of downstream NLP applications such as web search, question-answering, among other tasks, including those discussed in the previous work.
Improving recommendation and search systems
And lastly, while on the topic of information extraction, Mikhail Yurochkin et al. (2019) developed a method, published at NeurIPS last year, for categorizing, surfacing, and searching relevant documents based on a combination of three widely-used text-analysis tools: topic modeling, word embeddings, and optimal transport. The method also gives promising results for sorting documents. Such methods are applicable in a wide variety of scenarios and applications that require improved and faster suggestions on large-scale data such as search and recommendation systems.
3. On improving conversational agents
Towards a Human-like Open-Domain Chatbot
Meena is a neural conversational agent that aims to conduct improved conversations that are more sensible and specific — metrics that are defined to capture important attributes from a human conversation (e.g., fluency). Most conversational agents are built in a specialized way preventing them from having a conversation about different topics the user has in mind. Meena aims to solve this problem and improve the conversations between humans and conversational agents based on a metric called sensibleness and specificity average (SSA) which was found to highly correlate with perplexity.
The model learns the conversation context via an encoder and formulates a sensible response via the decoder. It is based on the evolved Transformer seq2seq architecture discovered via neural architecture search. The encoder is responsible for understanding the context of the conversation and the decoder is used to formulate a proper response. It is reported that improvement in the quality of conversations was possible by considering more powerful decoders.
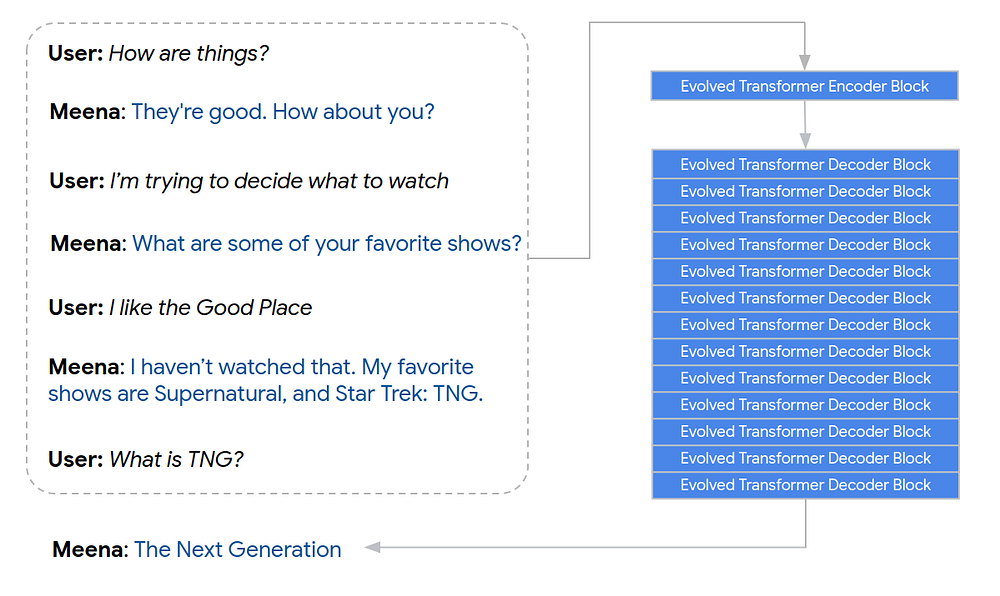
“Example of Meena encoding a 7-turn conversation context and generating a response” — Google AI Blog
Meena was trained on social media conversations with a model size of 2.6 billion parameters. Conversations with responses from Meena and other models are given to reviewers that labeled the response as reasonable and specific to the context of the conversation. The results from these responses were used to calculate the fraction of specificity and sensibleness and the average of these make up the SSA score. The figure below shows the results of Meena and other competitive models. As can be observed, Meena outperforms the other models and is closer to achieving human-level performance on the task.

In the future, the authors aim to improve the perplexity of the model as it correlates with the SSA score. In addition, other attributes that are important in conversation can also be considered such as personality and factuality.
4. Interpreting language models
Understanding BERT
Transformer-based models have shown to be effective at approaching different types of NLP tasks that range from sequence labeling to question answering. One of those models called BERT (Devlin et al. 2019) is widely used but like other models that employ deep neural networks, we know very little about their inner workings. A new paper titled “A Primer in BERTology: What we know about how BERT works” aims to answer some of the questions about why BERT performs well on so many NLP tasks. Some of the topics addressed in the paper include the type of knowledge learned by BERT and where it is represented, and how that knowledge is learned and other methods researchers are using to improve it.
Anna Roger wrote this fun and interesting blog post which talks about what really happens with a fine-tuned BERT and whether the claimed strengths are used to approach downstream tasks such as sentiment analysis, textual entailment, and natural language inference, among others. The findings of the proposed analyses suggest that BERT is severely overparameterized and that the identified benefits of the self-attention component of the framework may not necessarily be as claimed in particular as it relates to the linguistic information that’s being encoded and used for inferencing.
NLP shortfalls
Benjamin Heinzerling published an interesting article in The Gradient where he discusses areas where NLP falls short such as argument comprehension and commonsense reasoning. Benjamin makes reference to a recent paper by Nivin and Kao (2019) that challenges and questions the capabilities of transfer learning and language models for high-level natural language understanding. Read more about this excellent summary of the analysis performed in the research.
5. On improving text generation
Encode, Tag and Realize: A Controllable and Efficient Approach for Text Generation
To reduce the effect of hallucination (producing outputs not supported by input text) common in seq2seq-based text generation methods, a group of Google engineers open-sourced a method for text generation called LaserTagger.
The main idea of the method is to produce outputs by tagging words with predicted edit operations (e.g., KEEP, DELETE-ADD, etc.) and applying it to the input words in a so-called realization step. This replaces the common text generation method that just generates output from scratch which is generally slow and error-prone. The model offers other benefits besides generating fewer errors, such as enabling the parallel predictions of edit operations while still maintaining good accuracy and outperforming a BERT baseline in scenarios with a smaller number of training examples.
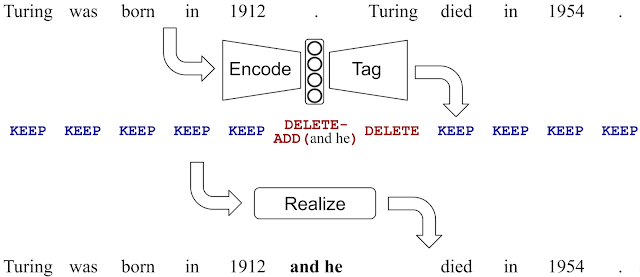
This work is interesting and important because it describes the challenge of text generation and that there could potentially be more efficient methods that address that part of the language model. When tested against a BERT baseline, LaserTagger show strengths in key areas such as data efficiency (results are shown in the figure below), inferences speed, and having more control over the output phrase vocabulary, preventing hallucination.
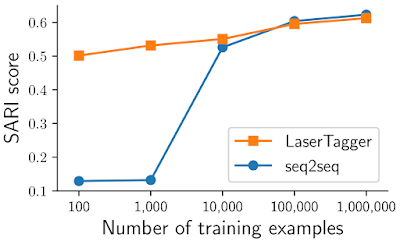
6. State-of-the-art online speech recognition
Scaling up online speech recognition using ConvNets
Facebook AI open-sources wav2letter@anywhere which is an inference framework that is based on Time-Depth Separable (TDS) convolutions and Connectionist Temporal Classification (CTC) for state-of-the-art online speech recognition. TDS blocks reduce parameter size which is important for computational efficiency and allows the system to perform many concurrent requests while reducing hardware requirements. The entire acoustic model and its improvements are detailed in the figure below:
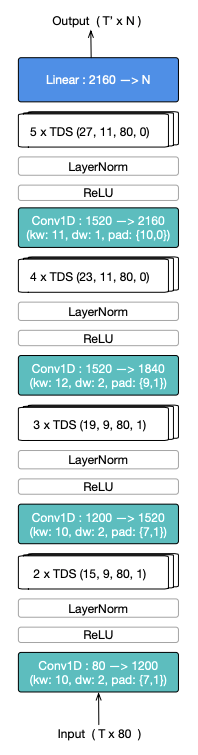
Major improvements are around the model size and reducing latency between audio and transcription, which are both important to achieving faster real-time inferencing. The research group proposes to limit the future context and use an optimized beam search decoder to reduce latency. The online beam search decoder takes the encoded input frames and outputs the most likely sequence for each chunk. Corrections are dealt with in real-time and a pruning approach is used to properly maintain the history buffer which constantly receives audio chunks as this is a real-time system. These improvements and more will enable the use of automatic speech recognition for applications such as live video captioning where low latency is crucial.
7. A theoretical understanding of self-distillation
Self-Distillation Amplifies Regularization in Hilbert Space
In the context of deep learning, self-distillation is the process of transferring knowledge from one architecture to another identical architecture. Predictions of the original model are fed as target values to the other model while training. Besides having desirable properties, such as reducing model size, empirical results demonstrate that this approach works well on held-out datasets.
A group of researchers recently published a paper that provides a theoretical analysis with the focus to better understand what is happening in this knowledge distillation process and why it is effective. Results show that a few rounds of self-distillation amplify regularization (by progressively limiting the number of basis functions that represent the solution) which tends to reduce over-fitting (Mobahi et al., 2020).
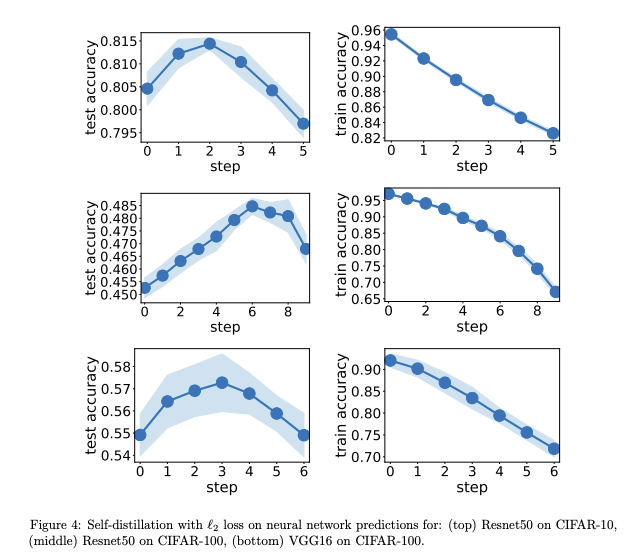
As observed in the figure above, the theory suggests that self-distillation amplifies regularization (which reduces over-fitting) and that’s notable in the progressive drop in accuracy during training. Regarding the testing accuracy, it should increase reflecting that the model is benefiting from the amplified regularization but at some point, it should decrease due to over regularization (which leads to underfitting) after some rounds of self-distillation.
Although the experiments are only applied in the context of image datasets, this work and the ideas presented can easily apply to the text modality where it’s currently being adopted, which is why it’s an important theoretical piece.
8. Symbolic Reasoning and Neural Machine Translation
Using neural networks to solve advanced mathematics equations
Lample and Charton (2019) propose a model trained on math problems and matching solutions to learn to predict possible solutions for tasks such as solving integration problems.
The approach is based on a novel framework similar to what’s used in neural machine translation where mathematical expressions are represented as a kind of language and the solutions being treated as the translation problem. Thus, instead of the model outputting a translation, the output is the solution itself. With this, the researchers claim that deep neural networks are not only good at approximation problems but also for potentially more diverse tasks that involve symbolic reasoning.
Math expressions are expressed as trees to preserve precedence and associativity. Seq2seq models have worked well at predicting syntactic parse trees so this was the method used in this approach. Sets of mathematical expressions were randomly generated so as to feed the model. This involved functions that can be integrated and first and second order differential equations that can be solved. Below is a table on one of the experiments conducted that shows the effectiveness of beam search for decoding.

Multilingual Denoising Pre-training for Neural Machine Translation
Liu et al. (2020) propose mBART a method based on a multilingual seq2seq denoising auto-encoder pretrained on large-scale monolingual corpora for machine translation across 25 languages. This work follows the pretraining scheme of Lewis et al., 2019 and investigates the effects of denoising pretraining on multiple languages such as Korean, Japanese, and Turkish, among other languages.
Input text involves the masking of phrases and permuting sentences (noising). A Transformer-based model is learned to reconstruct the text across many languages. The complete autoregressive model is trained only once and can be fine-tuned on any of the language pairs without involving any task-specific or language-specific modifications. Both document-level and sentence-level translation problems are approached and improved with mBART. Besides showing performance gains, the authors claim that the method works well on low-resource machine translation.
The study contains some in-depth analysis of the factors that influence the effectiveness of pre-training in mBART. The model is impressive in that it can also be fine-tuned in one language pair and tested directly on another pair. See some results below. The BLEU scores in the light gray show the results of the transfer effectiveness to another similar language.
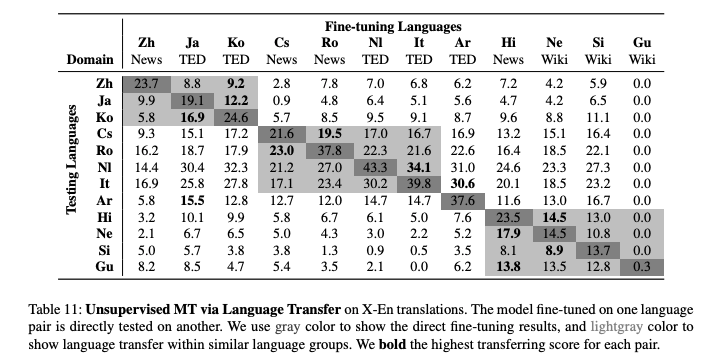
9. Question Answering
12-in-1: Multi-Task Vision and Language Representation Learning
Current research uses independent tasks and datasets to perform vision-and-language research even when the “visually-grounded language understanding skills” required to perform these tasks overlap.
Lu et al. (2019) propose a large-scale multi-task approach to better model and jointly train vision-and-language tasks to generate a more generic vision-and-language model. The model reduces the parameter size and performs well on tasks like caption-based image retrieval and visual question answering. An improved ViLBERT (Lu et al., 2019), which enables information exchange between the text and image modalities, is proposed as the core of the proposed model. This is referred to as the multi-task ViLBERT model that outperforms other approaches that independently train tasks.

Break It Down: A Question Understanding Benchmark
Wolfson et al. (2020) published a question understanding benchmark and a method for breaking down a question that is necessary for computing an appropriate answer. They leverage crowdsourcing to annotate the required steps needed to break down questions. To show the feasibility and applicability of the approach, they improve on open-domain question answering using the HotPotQA dataset.
This work proposes a new formalism called Question Decomposition Meaning Representation (QDMR) where questions are given full meaning representations via a question decomposition process. Ideally, the “atom” questions that are derived can be better answered and help understand the overall question to provide more accurate responses to the original questions.
Here are the 13 operator types used in QDMR for decomposition:
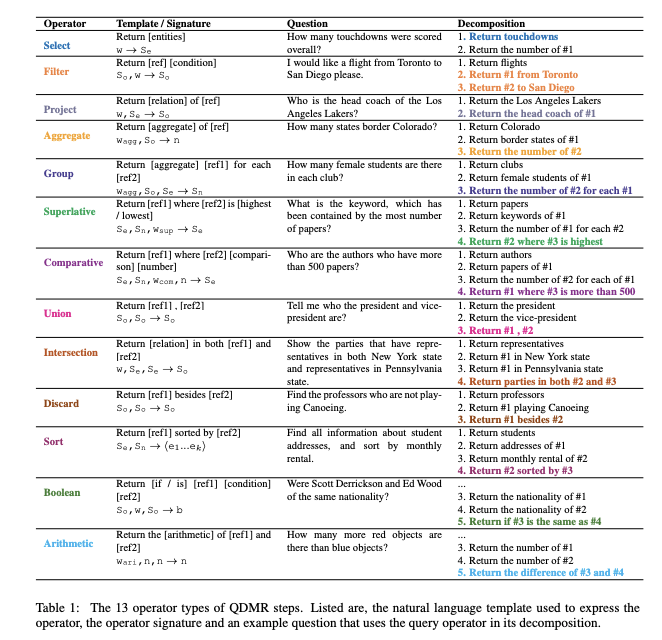
These operator types can then be used to compose a sequence of QDMR steps represented as a decomposition graph as shown in the example below:
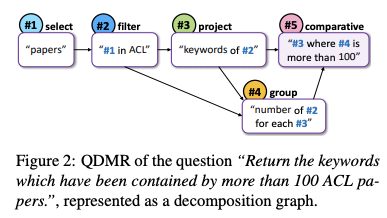
Refer to the paper for extensive analysis of the quality assessment of QDMR annotations and the different tasks in which QDMR parsing was applied.
BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations
reciTAL researchers and collaborators published a paper that aims to answer the question of whether a BERT model can produce representations that generalize to other modalities beyond text such as vision. The authors propose a model called BERT-gen that leverages mono or multi-modal representations and achieve improved results on visual question generation (VQG) datasets.
The goal of VQG is to generate questions based on the image and/or captions available. The proposed model details are shown in the figure below.
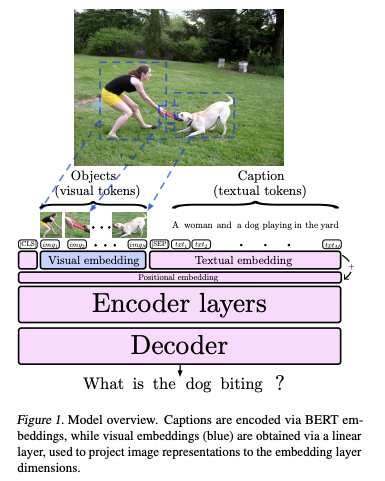
For the model to support images, these are converted to sequences and the precomputed representations by Anderson et al. (2018) are used. As the image features are now represented in sequences analogous to text sequences, it is now possible to test whether the BERT-based model used can transfer knowledge beyond language. The authors propose a method to use the original BERT model and simplify the task of text generation including how the self -attention mechanism attends to input tokens (see paper for these ideas and implementations).
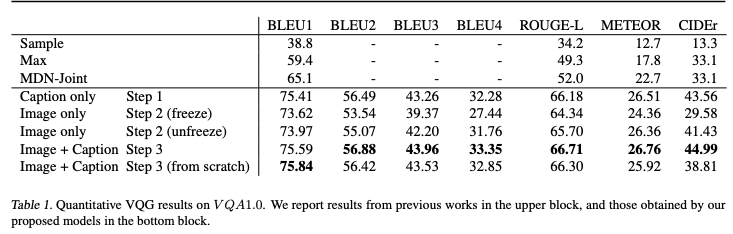
Finally, below we can observe the results of the model for visual question generation when combining modalities and using them individually. In particular, and as the authors hypothesized, pre-trained language models like BERT can potentially be used beyond text. That is noticeable in the results obtained when just using image information. When information from both modalities is combined, the model performs the best.
Results from their qualitative analysis are shown below:

10. Neural based Dependency Parsing
Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages
Miryam de Lhoneux released her Ph.D. thesis titled “Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages”. This work is about using neural approaches for dependency parsing in typologically diverse languages (i.e. languages that construct and express meaning in structurally different ways). This paper reports that RNNs and recursive layers could be beneficial for incorporating into parsers as they help to inform models with important linguistic knowledge needed for parsing. Other ideas include the use of polyglot parsing and parameter sharing strategies for parsing in related and unrelated languages.
In academic context, please consider citing:
@misc{elvis2020researchhighlights,
author = {Elvis, Saravia},
title = ,
year = {2020},
howpublished = {\url{https://dair.ai/NLP_Research_Highlights_-_Issue_-1/}},
}
Thanks for reading and we hope you found the information useful. Don’t forget to keep track of other summaries in our new GitHub repo. 🙏