
SentenceBERT who? 🤔
If you’re not familiar with this derivative of BERT, you’re in luck. I’ve written an article with the intension of summarising what motivated the development of this model, its architecture and performance on benchmark datasets. There, I also present its related work to get a better picture of where this sibling fits into the BERT family tree. Please go have a look! 🤖
Simple semantic search example
In order to get a feel for how SBERT performs in a search application have I created a super simple search application that allows you to experiment. The code can be found here. I’ve dedicated the rest of this article to show how the components of this app works which should make is simple for you to test it out on your own dataset. Let’s get started.
Setup
Install the required packages in a new environment. If you are using conda, that can be achieved as shown below. Note that python 3.6 is required due to some of the requirements not being compatible with later versions.
conda create --name sentence-similarity python=3.6
conda activate sentence-similarity
pip install -r requirements.txt
Input
I’ve included a subset of the data from the Quora Questions dataset. This can be downloaded as .csv from kaggle, but has to be converted to work with my data loader. The required format is a .txt file where each row should be considered a document. A file with this format can be loaded with my dataset class.
from dataset import Dataset
data = Dataset('data/quora/quora_example.txt')
Measuring similarity
This dataset class is not especially impressive, unless it’s used together with the sentence similarity measurer found in sentence_similarity.py. Simply initialise this class with the dataset instance.
from sentence_similarity import SentenceSimilarity
sentence_sim = SentenceSimilarity(data)
This will split each document into sentences which then can be encoded using a pre-trained SentenceBERT model. These sentence embeddings are kept in memory for fast inferences during query time. To find the most similar Quora question from our dataset to the query What is machine learning?, simply do
most_similar = sentence_sim.get_most_similar("What is machine learning?")
print("\\n".join(most_similar))
This will split the query into sentences (if you’ve entered more than one) and encode each of these using the same SentenceBERT model as previously. Then, each of these sentence embeddings will be compared to every sentence in the previously embedded dataset using the cosine distance metric. The closer two embeddings are, the more similar their sentences should be. It’s therefore natural to rank the search results by this metric.
The example snippets shown above can be found in example.py which if executed should return something like this:
$ python example.py
INFO:sentence_similarity:It took 9.319 s to embedd 552 sentences.
INFO:sentence_similarity:Extracted 1 sentences from query
INFO:sentence_similarity:Distance for top documents: [0.316, 0.335, 0.374, 0.381, 0.41, 0.45, 0.459, 0.468, 0.472, 0.478]
What is the alternative to machine learning?
What math does a complete newbie need to understand algorithms for computer programming? What books on algorithms are suitable for a complete beginner?
What's the best way to start learning robotics?
How do I learn a computer language like java?
What is Java programming? How To Learn Java Programming Language ?
What is the best material for understanding algorithmic analysis by a newbie?
How can I learn computer security?
How can you make physics easy to learn?
What are some mind-blowing computer tools that exist that most people don't know about?
What can make Physics easy to learn?
What we find is a relevant set of questions that in many ways are similar to our query sentence! Remember, all we did was to compare numerical representations of these sentences. Never did we actually search for any of the query terms. Thinking of it like that does, at least for me, indicate the potential of this method!🎉
Search application
I’ve integrated the same search functionality shown above into a simple flask app that gives it a super-basic UI for interacting with. To play around with this yourself, simply start the flask application with python app.py. This will load the same data as in the example above, but let you perform your own queries.
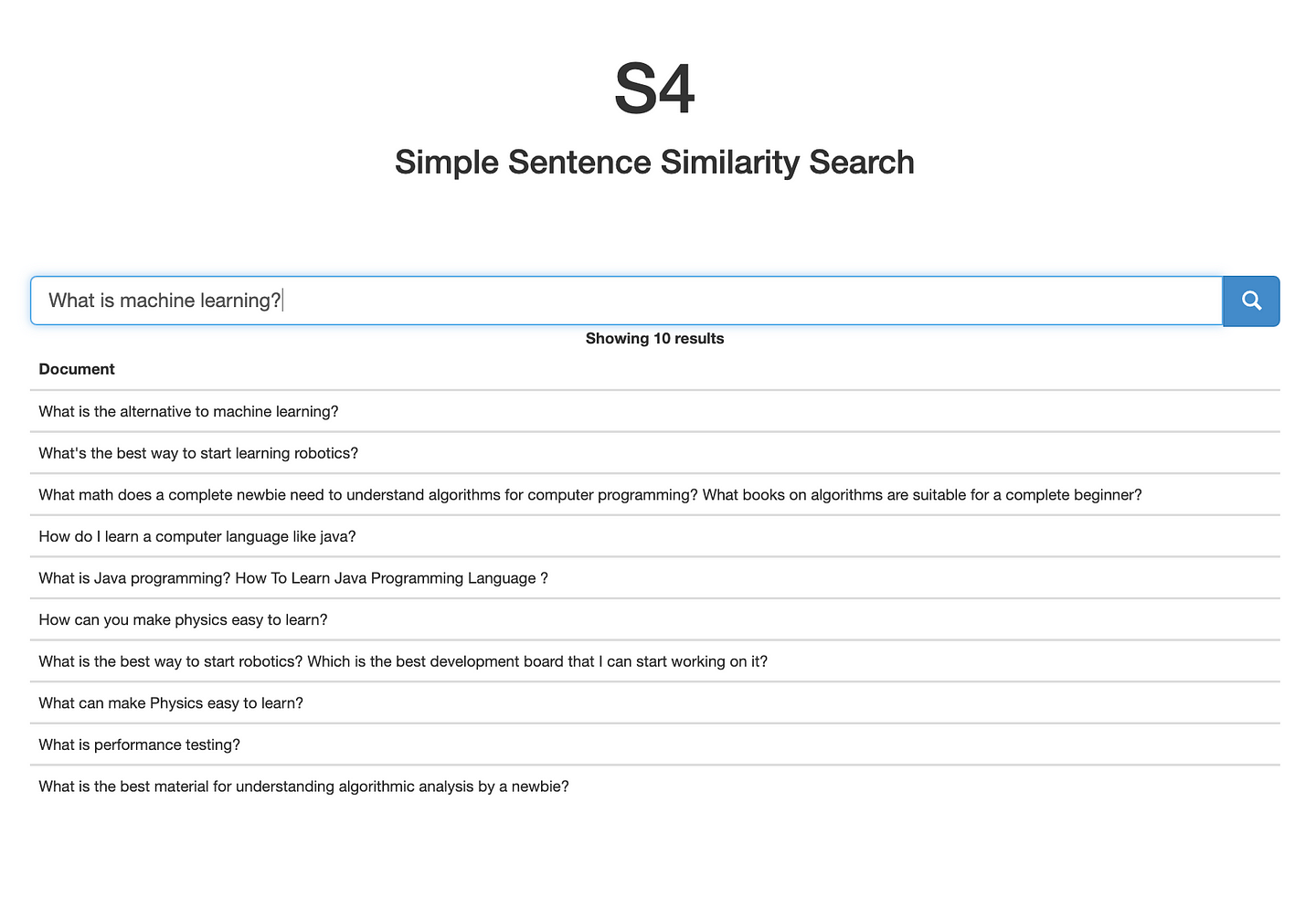
Hope this inspired you to try this semantic search application based on embeddings from Sentence BERT on a dataset of your own!
Original. Reposted with permission.
About the author: Viktor Karlsson is a Machine Learning Engineer with a growing interest of NLP. Trying to stay on-top of recent developments within the ML field in general, and NLP in particular, with the goal of sharing knowledge and understanding to a wider audience.