Paper summary: Attention is all you need , Dec. 2017. (link)
Why is it important?
This is the paper that first introduced the transformer architecture, which allowed language models to be way bigger than before thanks to its capability of being easily parallelizable. Consequently, models such as BERT and GPT achieved far better results in diverse NLP tasks.
What does it propose?
This work proposed a network architecture to perform neural machine translation (NMT). This new model is entirely based on the attention mechanism, contrary to the standard at that point of using recurrent networks with attention. The architecture was tested in two NMT tasks and it outperformed the best existent models, in addition to using less resources. Furthermore, the model was also successfully tested in a different task (english constituency parsing).
The inherently sequential nature of RNNs precludes parallelization within training examples, moreover the best RNNs architectures don’t rely solely on one or a couple of hidden states, but use attention to attend to the most relevant hidden states. That’s why the architecture presented in this paper is so relevant and impactful, it’s able to achieve better results getting rid of the sequentiality of RNNs.
How does it work?
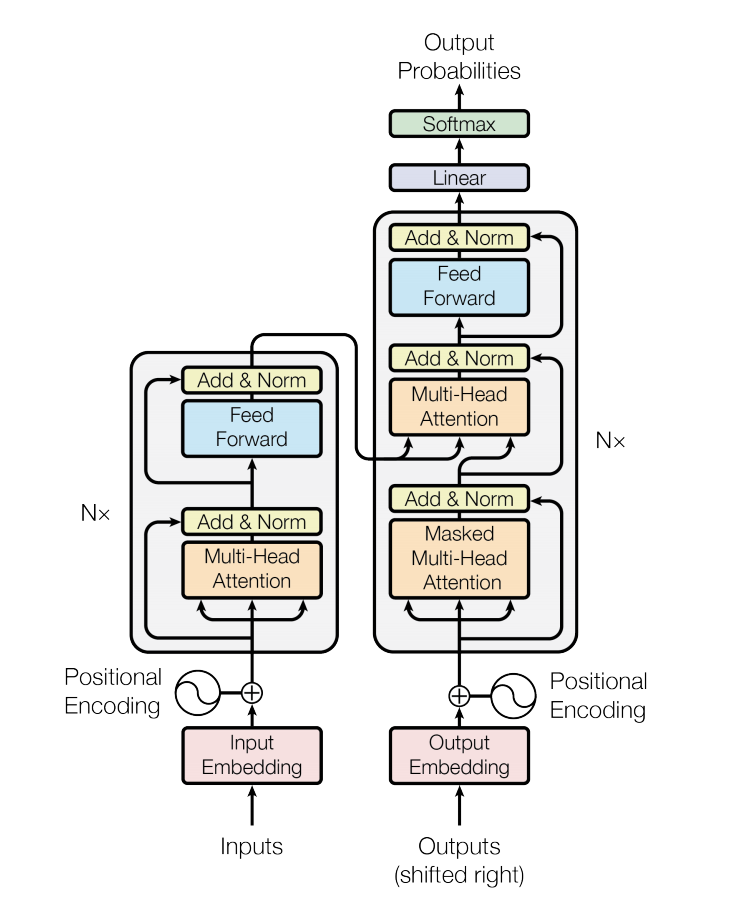
The Transformer is an encoder-decoder architecture, the encoder corresponds to the left side of the image below (Figure 1) and the decoder to the right one. In this paper the authors introduced the multi-head self-attention layer and the positional encodings used in the architecture (details in the next 2 sections).
Essentially, token embeddings are added with their positional encoding and used as inputs in the encoder and decoder. The encoder is composed of a stack of N=6 layers, we can see one of such layers in Figure 1. The decoder is also composed of a stack of N=6 identical layers, which has the two sub-layers of the encoder but it inserts a third sub-layer first that performs a multi-head attention over the output. Each feed-forward and multi-head self-attention layer is followed by a residual connection and a layer normalization, thus the output of each sub-layer is \(\text{LayerNorm}(x+\text{SubLayer}(x))\).
Some extra details:
- Byte pair encoding is used to define the tokens of the text.
- The feed forward network consists of two linear transformations with a ReLu in between.
- Regularizations:
- Dropout on the output of each sub-layer (before it’s added and normalized).
- Label smoothing.
- Beam search is used to generate the text.
(for further explanations in these concepts you can check my deep dive of this paper)
Positional Encoding
Motivation: Since there’s no recurrence, a positional encoding vector is added to the token embedding to inject information about its position in the text.
The \(PE(w_t)\), the positional encoding for the word \(w\) at position \(t\), is a vector of dimension \(d_{model}\) equal to the embedding dimension. We compute each dimension \(i\) of this vector as follows:
Which give as,
\[PE(w_t) = \begin{bmatrix}sin(k_0t)\\cos(k_0t)\\... \\sin(k_{d/2}t)\\cos(k_{d/2}t)\end{bmatrix}\]We can think of this as a bit representation of numbers, with each dimension of the vector as a bit, since each bit changes periodically and we can tell that one number is bigger than another because of the bits activated and their order. More of this intuition in this blog post.
The authors showed that learned positional embeddings were as good as these in their test sets. But they think sin/cos is better because it could extrapolate better.
Attention Layer
Instead of just having one attention layer the authors found beneficial to linearly project the attention mechanism, thus performing multiple attentions in parallel (Figure 2). Each of the attention mechanisms is a scaled dot-product attention (explained below).
The intuition behind is that having just one attention will lead to average all the different aspects of the text, whereas when we do parallel attention we are able to look at each of these details separately (the subject, the intention, the action, etc).
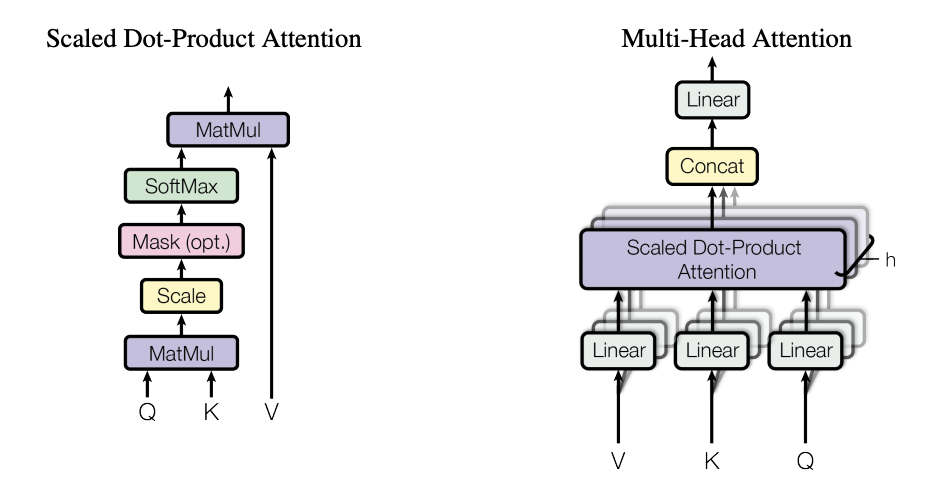
Scaled Dot-Product Attention
Attention is a function that takes a query and a set of key-value pairs as inputs, and computes a weighted sum of the values, where the weights are obtained from a compatibility function between the query and the corresponding key.
The specific attention used here, is called scaled dot-product because the compatibility function used is:
The authors decided to use a dot-product attention over an additive attention because it is faster to compute and more space-efficient. But it has been shown to perform worse for larger dimensions of the input (\(d_k\)), thus they added the scaling factor \(\sqrt{d_k}\) to counteract the effect of the dot product getting too large (which they suspect is the problem).
Masked Multi-Head Self-Attention
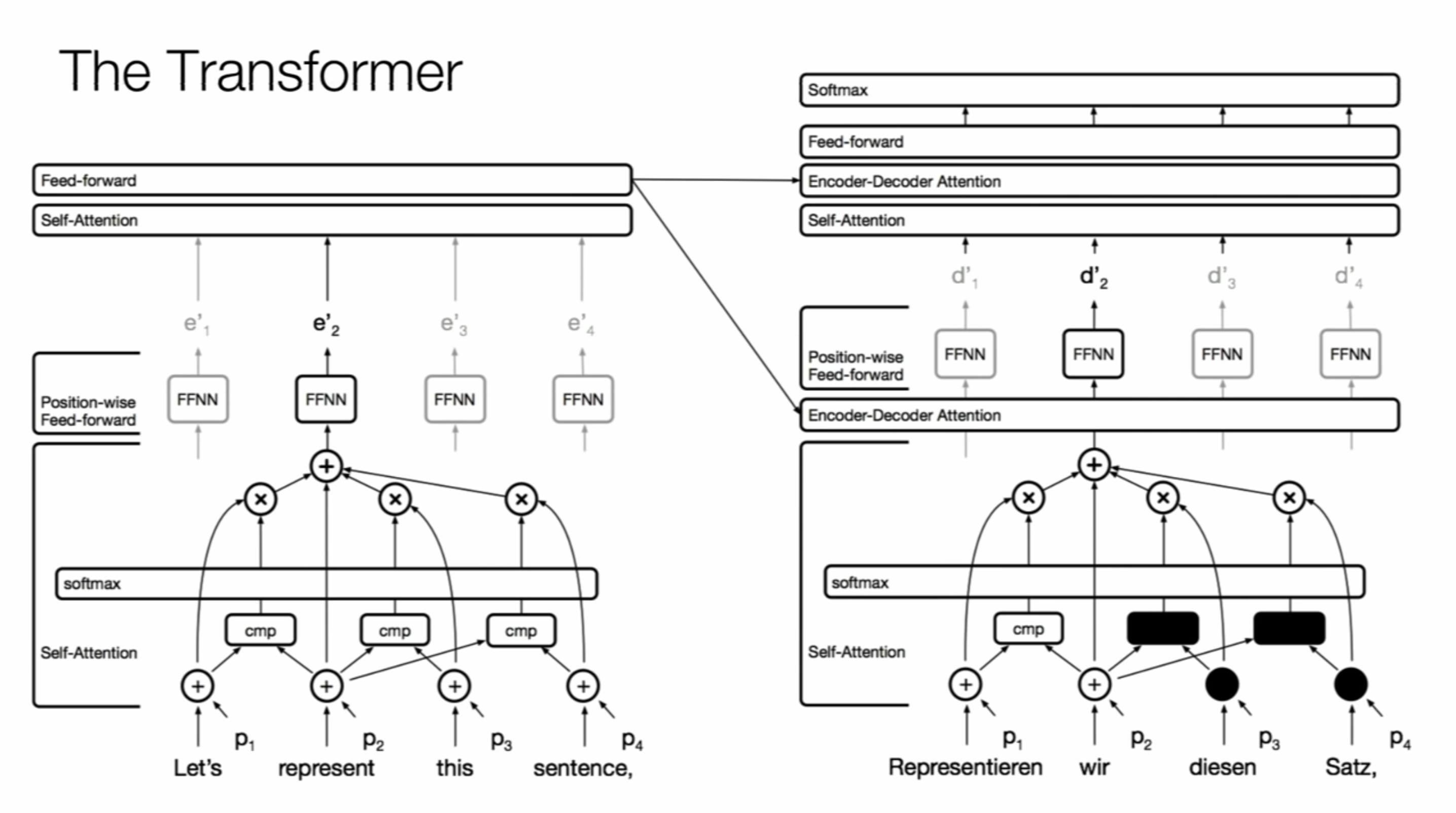
In training we don’t want to show the complete output sentence to our model, but instead we want to present the words one by one to not let extra information flow in the decoder. That’s why in Figure 2 we see a “Mask opt.” which refers to setting those vectors to -inf, making them 0 after the softmax. Figure 3 can help to understand how this affects the architecture overall.
What’s next!
BERT and GPT are just some of the applications that the Transformer can have, but it has also been applied to images, graph networks, GANs, among others, achieving state-of-the-art results. It has also been useful to interpret a part of the models that use it (https://arxiv.org/abs/1910.05276).