

Credit: Arxiv
Recent progress in NLP has mostly been due to the effective pretraining of large neural networks such as BERTand XLNet. While the performances of these models — in a transfer learning setting — are impressive, there is very little understanding of why and what aspects of language they learn.
This paper aims to investigate what aspects of language (i.e. linguistic features) BERT learns from unlabeled data. The main approach is to observe the attention component of the pre-trained model and obtain interesting insights about what type syntactical information the attention heads capture.
The proposed analysis method probes the attention heads at a broader level (analysis of surface-level patterns) and at the individual level (analysis of specific linguistic phenomena).
Broad Attention
For the surface-level pattern analysis, the attention maps of a BERT-based model are extracted when applied to 1000 random Wikipedia segments. Note that no masking was used as in the original BERT training. The model has 12 layers containing 12 attention heads each.
This broader analysis shows that BERT's attention heads pay little attention to the current token but rather specialize to attend heavily on the next or previous token, especially in the earlier layers.
A substantial amount of BERT' attention focuses on a few special tokens such as the deliminator token [SEP] which means that such tokensplay a vital role in BERT's performance. The figure below shows the average attention behavior in each layer for some special tokens such as [CLS] and [SEP].
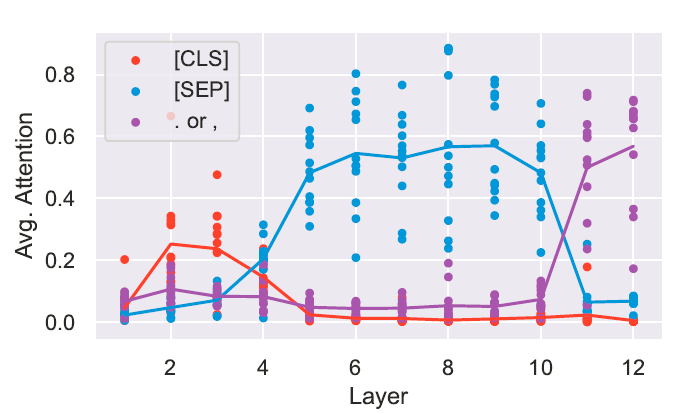
At first, the authors suspected that the [SEP] token is used as an indicator to collect valuable segment-level information which is passed on to other attention heads. However, the attention heads processing [SEP] almost entirely keep fixated on themselves and the other [SEP] tokens.
Further theoretical analysis shows that attention over [SEP] tokens could serve as a way for the BERT model to control when an attention head's function is applicable or not (also referred to as a no-op).
By measuring the entropy of each head's attention distribution it is possible to observe that some of these heads, particularly in the lower layers, display very broad attention. The authors state that the output of these heads translates to a bag-of-vectors representation of the sentences. (See figure below)
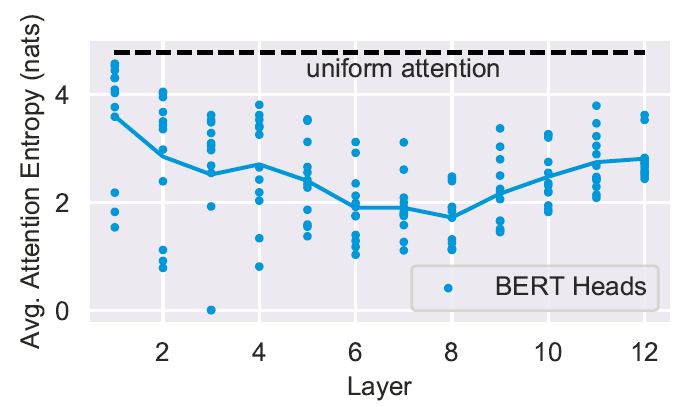
Interestingly, entropies for all attention heads on the [CLS] token also have similar behavior with the last layer having huge entropy. This translates to a representation that attends broadly, aggregating a representation used as input for the next sentence prediction.
Individual Attention Heads
The previous analysis focused on broad attention, so this part focuses on probing the individual attention heads to find out what aspects of language they have learned. Two tasks were used in this analysis: dependency parsing and coreference resolution.
The first analysis aims to evaluate the attention heads on dependency relation prediction. The authors found that no single attention head does well at syntax overall. The main finding in this analysis was that in almost all the relations, the dependent attends to the head word, which makes sense because dependents only have one head.
The figure below shows a relation example where the attention head 8–11 perform well. You can see that the determiners expectedly attend to their corresponding noun. (See more interesting examples in the paper)

The second analysis aims to evaluate the attention heads on the semantic task of coreference resolution. Keep in mind that coreference is more difficult as links are usually longer than in syntactic dependencies. The evaluation is done via asking the following: "what percent of the time does the head word of a coreferent mention most attend to the head of one of that mention's antecedents."
The figure below shows an example where the attention head 5–4 achieves satisfactory accuracy on the antecedent selection task.

With a few more creative tests (see paper for full details), the authors found that BERT's attention maps have a fairly thorough representation of English syntax. In addition, it was found that BERT's vector representations do not capture more syntactic information as compared to its attention maps. Via the proposed tests above, the authors argue that BERT learns some aspects of syntax purely as a by-product of self-supervised training.
Upon further investigation of the individual attention heads behavior for a given layer, the authors found that some heads behave similarly, possible due to some attention weights being zeroed-out via dropout. A surprising result, given that other researchers found that encouraging different behavior in attention heads improves a Transformer's performance. There is more opportunity to conduct extended analysis to help further understand these behaviors in the attention layer.
Overall, probing attention maps offer a feasible technique to understand what neural networks learn about language.
Paper: What Does BERT Look At? An Analysis of BERT's Attention— Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning
Further Readings:
- Attention mechanisms
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- XLNet outperforms BERT on several NLP Tasks
- An Overview of Modern NLP