
Sanh et al. (2018) propose a new method based on multi-task learning, trained in a hierarchical fashion, to achieve state of the art results on various NLP tasks such as Named Entity Recognition (NER), Entity Mention Detection (EMD) and Relation Extraction (RE). (See brief definitions of these tasks at the end of this article if you are not familiar with them.)
The main question this paper aims to address is whether linguistic hierarchies and multi-task learning can be leveraged to improve results on the above-mentioned semantic-related tasks.
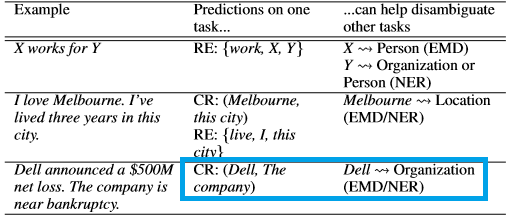
Previously, multi-task frameworks have not been trained to leverage the strengths of inductive transfer to achieve more generalized capabilities. Complimentary aspects of a sentence (e.g., syntax and word order) can be combined to produce generalized sentence embeddings. This paper proposes a unified model that trains and combines four semantic NLP tasks on the basis that they share inter-dependencies with each other. For instance, in the example provided in the table below (highlighted in blue) you can observe that by resolving that "Dell" and "the company" refer to the same real-world entity, it is also likely to represent an organization as opposed to a person. This knowledge could be beneficial and transferred to other tasks such as EMD and NER.
The proposed model (shown in the figure below) consists of a hierarchy between the tasks in the lower levels while encouraging complex interactions at deeper layers. This implies that simple supervised tasks will be placed at lower layers and more complex tasks at the higher layers. This is done in an end-to-end setting and without using hand-engineered features. A new sampling strategy for multi-task learning, called proportional sampling, is also proposed (more on this later).
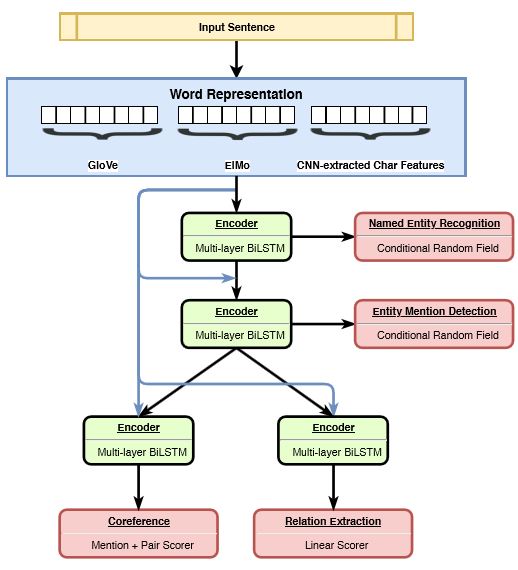
HMTL framework— Image source
Hierarchical Model
The input of the model consists of the concatenations of three type of word embeddings: fine-tuned GloVe embeddings, ELMo embeddings, and character-level embeddings.
The first group of layers in the model are supervised by NER labels where the inputs are the concatenated embeddings and the output represents the hidden states produced by the biLSTMs. A CRF tagging layer represents the last layer in this group as seen in the model figure above.
The second group of layers is supervised by EMD labels where the input is the concatenation of the output of lower layers and input embeddings, and the output represents sequence embeddings. Similar to NER, CRF is used to make tagging decisions. Note that the input contains information from the lower layers, establishing the hierarchical architecture.
The highest level of the model is supervised by a Coreference resolution (CR) task where the input is the concatenated embeddings combined with the output of the lower layers, and the outputs are fed to the mention pair scorer. In this same level of the architecture, the model is also supervised by the RE task. The RE task involves identifying mentions and classifying their relations, thus it also tries to link mentions similar to the CR task (refer to the paper for more details).
Experiments
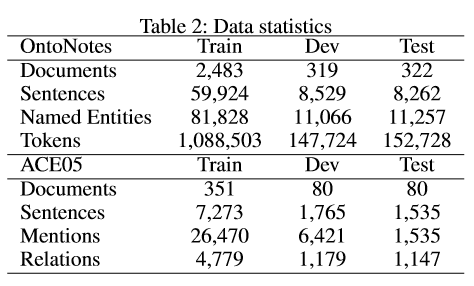
Overall, two datasets are used for the experiments. For NER, the English portion of OntoNotes 5.0 (Pradhan et al. 2013) is used. For CR, EMD, and RE, the ACE05 corpus (Doddington et al. 2004) is used. Refer to the paper for more details on these datasets and how they were used. Data statistics can be found in the table below:
To avoid catastrophic forgetting (an issue common when training multi-task models), a simple yet effective training method is employed. Specifically, after each parameter update, a task from the pipeline is randomly selected and batches linked to this task are also randomly sampled. The sampling of a task is achieved using proportional sampling which is a function of the relative size of a dataset compared to the cumulative size of all datasets.
Results
In summary, the proposed hierarchical and multi-task learning framework, coined HMTL, achieved state-of-the-art (SOTA) results on three tasks, namely NER (+0.52 ), EMD(+3.8 ), and RE (+6.8). The results are summarized in the table below:
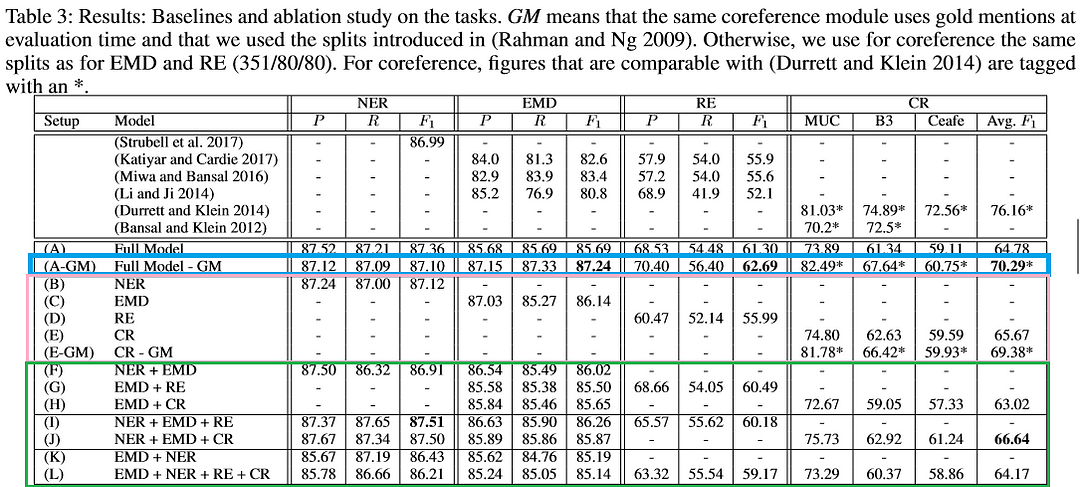
The full model (A-GM) model (highlighted in blue) produces SOTA results for EMD and RE. These results suggest that having different type of information on different sentences produces valuable richer information. B, C, D, E, and E-GM are all single-task setups (highlighted in pink) which are outperformed by the full model (A) with exception of the EMD task. However, A-GM outperforms the single-task setup of EMD, keeping in mind that this model makes use of gold mentions. For the rest of the setups (e.g., F, G, etc.), varying combinations of tasks are used during training (highlighted in green). These results show how much much one task or tasks can contribute to the other/s. Note that the authors also experimented with the order of the tasks such (e.g., F vs. K) and how this decision influenced results.
The table below shows the ablation study conducted on the input embeddings:

You can observe the strength of the contextualized ELMo embeddings by the differences shown in the metrics. In addition, the authors also discuss what the encoders and embeddings in the multi-task, hierarchical architecture are learning through various probing tasks (see full details in the paper).
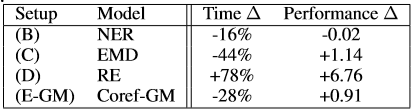
In the table below, you can also observe the differences in training time (defined by parameter updates) between a multi-task framework and single-task framework. The lower the values in the time column and the higher the performance the better the results.
References
Paper: A Hierarchical Multi-task Approach for Learning Embeddings from Semantic Tasks — (Victor Sanh, Thomas Wolf, Sebastian Ruder)
Code: GitHub repo
Online Demo: HMTL for NLP
Detailed post (includes code snippets):HuggingFace Blog
Task Definitions
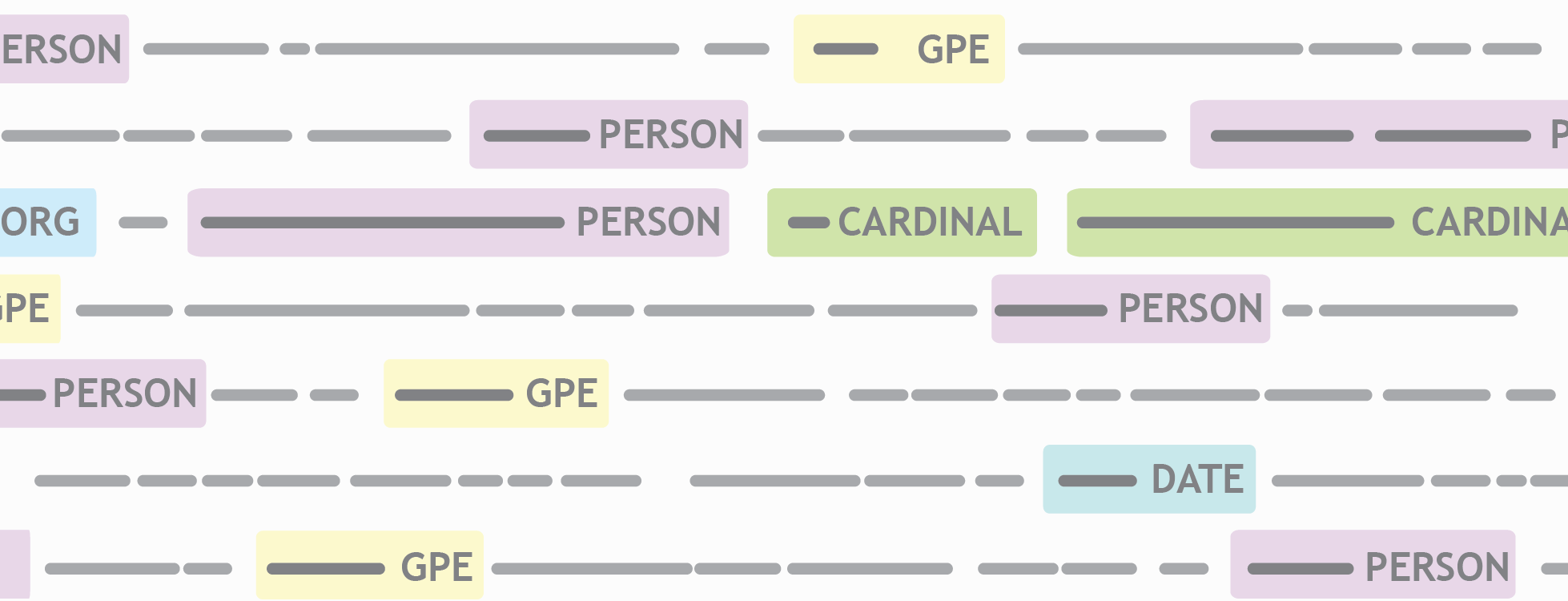
Named Entity Recognition (NER) aims to identify mentions of named entities in a sequence and classify them into predefined categories.
Entity Mention Detection (EMD) is similar to NER but more general as it aims to identify all the mentions related to a real-life entity, whereas NER only focuses on the named entities.
Coreference resolution (CR) aims to identify mentions that are referring to the same real-life entity and cluster them together.
Relation Extraction (RE) aims to identify semantic relational structure between entity mentions in unstructured text.