

欢迎来到 NLP 时事简报第六期!全文较长,建议收藏。
如果想让自己有趣的研究/项目出现在NLP简报中,欢迎在公众号后台留言联系我
来看看都有哪些内容,enjoy~ @[TOC]
1、Publications 📙
1.1 BERT综述
基于Transformer的模型已经被证实可以有效地处理从序列标记到问题解答等不同类型的NLP任务,其中一种称为BERT的模型得到了广泛使用,但是像其他采用深度神经网络的模型一样,我们对其内部运作知之甚少。 一篇名为《 A Primer in BERTology: What we know about how BERT works》的新论文旨在回答一些有关BERT为什么在这么多NLP任务中表现良好的问题。 论文的内容包括:BERT学习的知识类型及其表示的位置,BERT是如何学习知识的,以及研究人员如何使用其他方法来改进它,等等。
1.2 T5
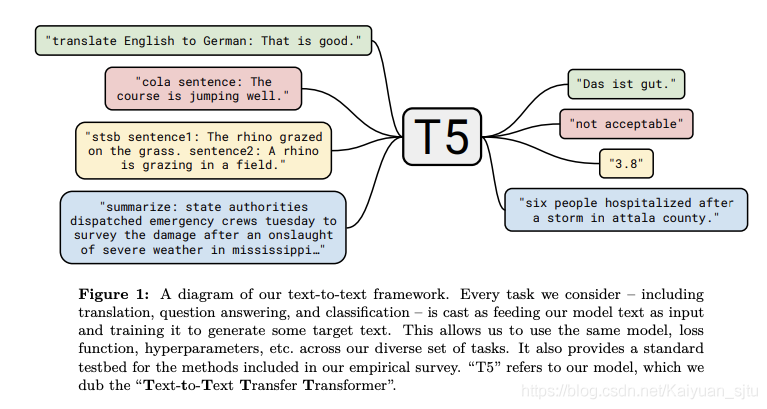
Google AI最近发布了一种方法,该方法将从NLP迁移学习模型中学到的所有知识和经验汇总到一个称为Text-to-Text Transfer Transformer(T5)的统一框架中。 这项工作建议大多数NLP任务可以用文本到文本的格式来表示,这表明输入和输出都是文本。 作者声称,这种“框架为预训练和微调提供了一致的训练目标”。 T5本质上是一种编码器/解码器Transformer,特别是对模型的attention组件进行了各种改进。 该模型在新发布的名为Colossal Clean Crawled Corpus(C4)的数据集上进行了预训练,并在NLP任务(例如摘要,问题回答和文本分类)上获得了SOTA结果。
1.3 12合1:多任务视觉和语言表示学习
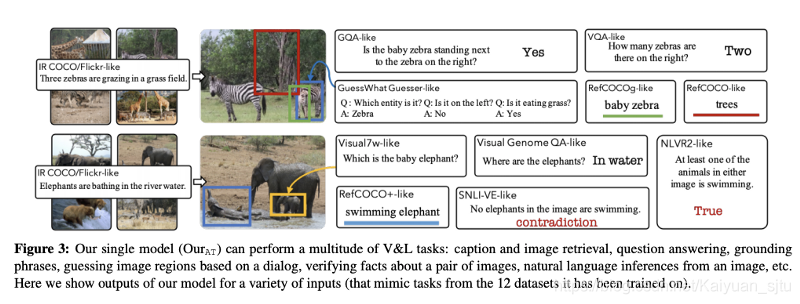
当前的研究使用独立的任务和数据集来执行视觉和语言研究,即使执行这些任务所需的“具有视觉基础的语言理解技能”也是如此。 一篇新论文(将在CVPR上发表),《12-in-1: Multi-Task Vision and Language Representation Learning》,提出了一种大规模多任务方法,以更好地建模并共同训练视觉和语言任务以生成更通用的视觉和语言模型。 该模型减小了参数大小,并且在基于字幕的图像检索和可视问题解答等任务上表现出色。
1.4 BERT文本表示的跨模式可传递性
众多研究人员和合作者发表了一篇论文,BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations,旨在回答BERT模型是否可以产生可以推广到诸如视觉之类的文本之外的其他方式的问题。 他们提出了一种称为BERT-gen的模型,该模型利用了单模态或多模态表示,并在视觉问题生成数据集上获得了改进的结果。

2、Creativity and Society 🎨
2.1 The Next Decade in AI
Gary Marcus最近发表了一篇论文,The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence,他在其中解释了一系列步骤,他认为,我们应该采取这些步骤来构建更强大的AI系统。 Gary在论文中的中心思想是着重于构建由认知模型指导的混合和知识驱动系统,而不是着重于构建需要更多数据和计算能力的大型系统。
2.2 2020年的10种突破性技术
MIT Technology Review 出版了一份清单,列出了他们确定的10项突破,这些突破将对解决可能改变我们的生活和工作方式的问题产生影响。 列表如下(排名不分先后):unhackable internet, hyper-personalized medicine, digital money, anti-aging drugs, AI-discovered molecules, satellite mega-constellations, quantum supremacy, Tiny AI, differential privacy, and climate attribution.
2.3 重新考虑机器学习的发表过程
Yoshua Bengio最近写了关于ML出版物快节奏发展的担忧。 主要担心的是,由于发布的速度快,很多论文都包含错误并且只是渐进式出版,而花费更多的时间并确保严谨(这是多年以前的工作方式)似乎正在消失。 最重要的是,学生是那些必须应对这种压力和压力的负面后果的人。 为了解决这种情况,Bengio谈论了他的行动,以帮助减慢研究出版物的发展,以造福科学。
3、Tools and Datasets ⚙️
3.1 AllenNLP中的PointerGenerator网络实现
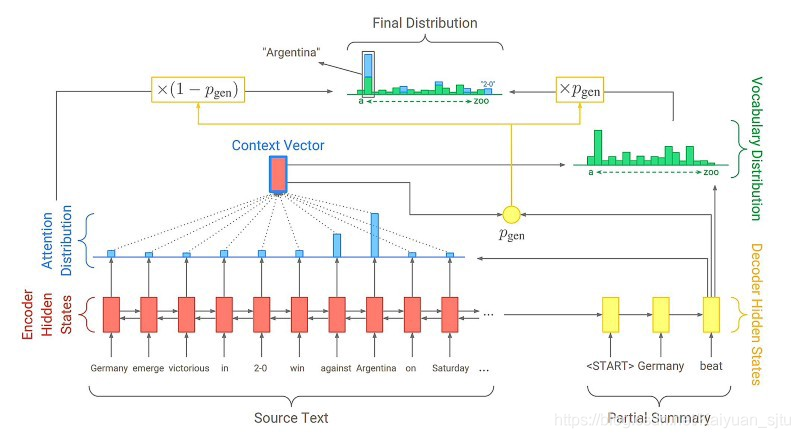
Pointer-Generator网络旨在增强用于改进抽象摘要的序列到序列注意模型。 如果您希望使用AllenNLP进行Pointer-Generator抽象摘要,Kundan Krishna已开发了一个库,PointerGenerator network implementation in AllenNLP,该库可让您运行预先训练的模型(提供)或训练自己的模型。
3.2 不同语言的QA
随着Transformer模型的发展以及它们对以其他语言执行的大规模NLP任务的有效性,人们付出了巨大的努力来发布不同语言的不同类型的数据集。 例如,Sebastian Ruder共享了可用于不同语言问答研究的数据集列表:DuReader,KorQuAD,SberQuAD,FQuAD,Arabic-SQuAD,SQuAD-it和Spanish SQuAD。
3.3 PyTorch Lightning
PyTorch Lightning是一种可让您抽象化可能需要设置GPU / TPU训练和使用16位精度的训练的工具。 使这些事情正常工作可能会变得很乏味,但是好消息是PyTorch Lightning简化了此过程,并允许您在多GPU和TPU上训练模型,而无需更改当前的PyTorch代码。
3.4 TF2中的图神经网络
Microsoft研究团队发布了一个库,该库提供对许多不同的图神经网络(GNN)架构的实现的访问。 该库基于TensorFlow 2,还提供可直接在训练/评估循环中使用的数据整理模块。
3.5 预训练 SmallBERTa
你是否曾经想从头开始训练自己的语言模型,但是没有足够的资源来训练呢? 如果是这样,那么Aditya Malte提供了一种优雅的方式,它教您如何使用较小的数据集从头训练语言模型。
3.6 CLUEDatasetSearch
CLUE benchmark团队整理了所有中文NLP数据集,附常用英文NLP数据集,可以在CLUEbenchmark/CLUEDatasetSearch找到。
4、Ethics in AI 🚨
4.1 面部表情与真实情感
一段时间以来,许多研究人员和公司已尝试建立可理解并可以识别文本或视觉环境中的情绪的AI模型。 一篇新文章重新引发了辩论,Why faces don’t always tell the truth about feelings,即旨在直接从面部图像识别情绪的AI技术做得不好。 该领域的杰出心理学家提出的主要论点是,没有证据表明可以仅从面部图像进行情感检测的通用表达方式。 它将需要一个模型更好地了解人格特征,身体动作等,才能真正更接近地更准确地检测人类所表现出的情绪。
4.2 差异隐私和联合学习
构建AI系统时的道德考量之一是确保隐私。 当前,这可以通过两种方式来实现,即使用差异隐私或联合学习。 如果你想了解更多有关这些主题的信息,Jordan Harrod在此视频中为我们做了很好的介绍,其中还包括使用Colab notebook的动手实践课程。
5、Articles and Blog posts ✍️
5.1 深入Reformer
Madison May撰写了一篇新博客文章,A Deep Dive into the Reformer,深入探讨了Reformer,这是Google AI最近提出的一种新改进的基于Transformer的模型。 在上一期新闻通讯中,我们也介绍了Reformer。
5.2 一个免费的博客平台
fastpages允许你免费使用GitHub页面自动建立博客。 该解决方案简化了发布博客的过程,还支持使用导出的Word文档和Jupyter notebook。
5.3 Google面试技巧
Google Brain团队的Pablo Castro发表了一篇出色的博客文章,Tips for interviewing at Google,重点介绍了那些有兴趣在Google求职面试的人的技巧。 主题包括有关如何准备面试,面试过程中会发生什么以及面试后会发生什么的建议。
5.4 Transformer是图神经网络
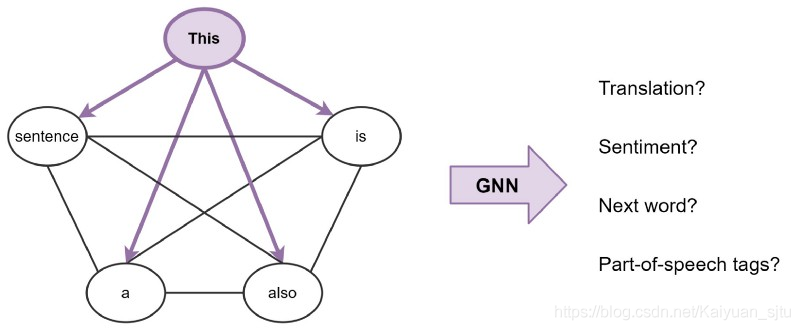
图神经网络(GNN)和变压器都已证明在不同的NLP任务上有效。 为了更好地理解这些方法背后的内部工作原理以及它们之间的联系,Chaitanya Joshi撰写了一篇很棒的文章,Transformers are Graph Neural Networks,解释了GNN与Transformers之间的联系以及这些方法可以以不同的方式组合成一种混合模型。
5.5 CNNs and Equivariance
Fabian Fuchs和Ed Wagstaff讨论了等方差的重要性以及CNN如何实施。 他们首先定义等方差的概念,然后在CNN的上下文中讨论翻译。
5.6 图像自监督学习
由于自我监督在语言建模的现代技术中发挥了作用,因此在NLP简报的前几期中已经进行了很多讨论。 Jonathan Whitaker的这篇博客文章提供了一个很好的,直观的图像自我监督解释。 如果你真的对该主题感兴趣,Amit Chaudhary还撰写了一篇出色的博客文章,以可视化方式描述自监督学习。
6、Education 🎓
6.1 Stanford CS330
斯坦福大学最近以YouTube播放列表的形式发布了有关深层多任务和元学习的新课程的录像。 主题包括贝叶斯元学习,终身学习,强化学习入门,基于模型的强化学习等。
6.2 PyTorch Notebooks
dair.ai发布了一系列教程,旨在帮助您开始使用PyTorch进行深度神经网络学习。 这是一项正在进行的工作,当前的一些主题包括如何从头开始实现逻辑回归模型,以及如何从头开始编程神经网络或循环神经网络。
6.3 fastai新书草稿
Jeremy Howard和Sylvain Gugger将为即将举行的课程发布一份完整的教程fastbook,其中介绍了深度学习的概念以及如何使用PyTorch和fastai库开发不同的方法。
6.4 免费数据科学课程
Kaggle提供了一系列免费的微型课程,可帮助您开始进行数据科学之旅。 其中一些课程包括机器学习的可解释性,机器学习和Python入门,数据可视化,特征工程和深度学习等。
这是另一门不错的在线数据科学课程,提供了课程表,幻灯片和botebook,内容涉及从探索性数据分析,模型解释到自然语言处理等各种主题。
6.5 PyTorch生态系统
nepture.ai发表了一篇文章,8 Creators and Core Contributors Talk About Their Model Training Libraries From PyTorch Ecosystem,其中包含与核心创作者和贡献者的详细讨论,讨论了他们的旅程以及构建PyTorch及其工具的哲学。
6.6 可视化自适应稀疏注意模型
Sasha Rush分享了一部令人印象深刻的Colab notebook,该笔记本解释并显示了如何产生稀疏softmax输出并将稀疏性引入Transformer模型的关注组件的技术细节,该组件有助于在给定上下文中对无关单词产生零概率,从而提高了性能和可解释性。
7、Noteworthy Mentions ⭐️
Conor Bell写了这个非常棒的python脚本,使您可以查看和准备可用于StyleGAN模型的数据集。
Manu Romero为西班牙语提供了一种经过微调的POS模型,该模型可在Hugging Face Transformer库中进行调用。
该github库,BERT-related-papers包含一长串精心挑选的与BERT相关的论文,这些论文涉及诸如模型压缩,特定领域,多模型,生成,下游任务等不同问题。
Connor Shorten发布了一个15分钟的简短视频,Automatic Shortcur Removal for Self-supervised Learning,解释了一个新的通用框架,该框架旨在减少自我监督表示学习中“sortcut”的影响。 这一点很重要,因为如果处理不正确,该模型可能无法学习有用的语义表示,并可能证明在转移学习环境中无效。
Sebastian Ruder发布了新一期的NLP News newsletter,主题和资源包括对2019年NLP和ML论文的分析,到用于学习有关转移学习和深度学习要点的幻灯片。