

Thanks to Kaiyuan (WeChat: NewBeeNLP) for this great translation.
欢迎来到 NLP 时事简报!涵盖了诸如特定语言 BERT 模型、免费数据集、深度学习库等主题。
1、Publications 📙
1.1 Language-specific BERT models
我已经记不清现在有多少种特定语言的 BERT 模型了,这里有一些最新的版本:
-
荷兰语 Dutch BERT(RobBERT[1] BERTje[2]) - 德语 German BERT[3]
- 葡萄牙语 Portuguese BERT[4]
-
法语(CamemBERT[5] FlauBERT[6]) -
意大利语(AlBERTo[7] UmBERTo[8]) - 西班牙语(BETO[9])
- 阿拉伯语(araBERT[10])
大多数这些模型也可以通过 huggingFace 的Transformer 库[11]获得,该库最近升级到了2.4.1[12]。
1.2 Overly Optimistic Prediction Results on Imbalanced Data: Flaws and Benefits of Applying Over-sampling
这篇论文[13]揭示并广泛讨论了在对数据集进行划分之前应用过采样来处理不平衡数据集的缺点和优点。此外,该工作复现了先前的研究,并确定了导致过于乐观的结果的方法论缺陷。
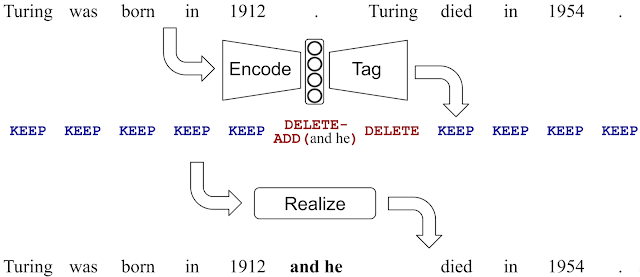
1.3 Encode, Tag and Realize: A Controllable and Efficient Approach for Text Generation
为了减少基于 seq2seq 的文本生成方法中常见的 hallucination [14](产生输入文本不支持的输出)的影响,Google 工程师公开了一种称为LaserTagger[15]的文本生成方法。该方法的主要思想是通过使用预测的编辑操作(例如KEEP,DELETE-ADD等)标记单词并在所谓的realization step中将其应用于输入单词来产生输出。
这代替了通常只从头生成输出的文本生成方法,这种方法通常很慢而且容易出错。该模型除了产生更少的错误外,还提供了其他好处,例如,在进行少量训练示例的情况下,可以在实现并行预测的同时进行编辑操作,同时仍保持良好的准确性并优于 BERT baseline。
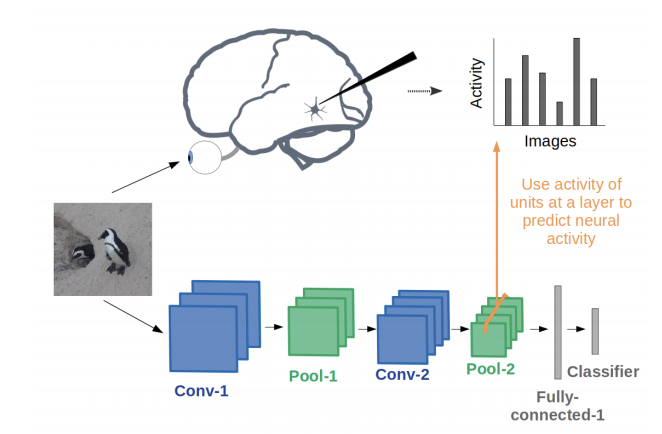
1.4 Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future
Grace Lindsay 发布了这份关于 CNN 历史的精美且易于阅读的报告[16],以及如何将它们作为生物视觉的模型进行评估,即 CNN 表示与大脑的表示相比如何?强烈建议读者关注这份利用 CNN 进行视觉研究的讨论。
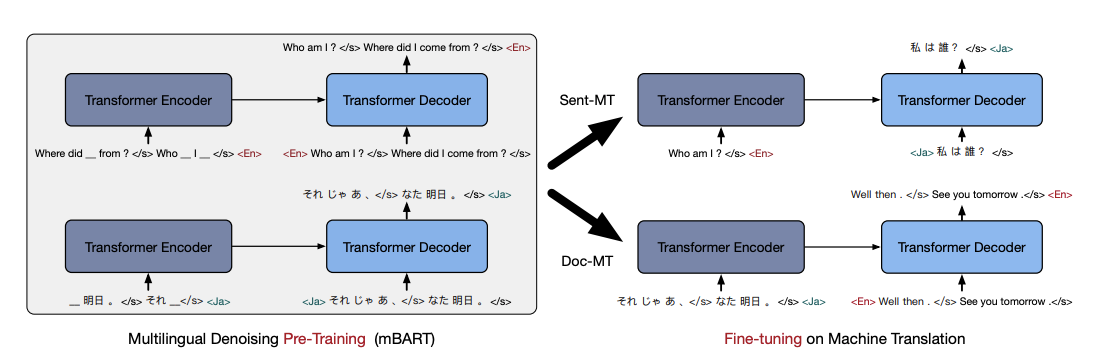
1.5 Multilingual Denoising Pre-training for Neural Machine Translation
Facebook AI 发布了mBART[17],一种基于多语言 seq2seq 去噪自动编码器的方法,该方法在大规模单语言语料库上进行了预训练,可用于 25 种语言的机器翻译。这项工作遵循 Lewis 等人(BART,2019)的预训练方案,并研究了去噪预训练对韩文,日文和土耳其文等多种语言的影响。输入文本涉及对短语的掩盖和对句子的置换(加噪),学习了一种基于 Transformer 的模型跨多种语言重建文本。完整的自回归模型仅训练一次,并且可以在任何语言对上进行微调而无需进行任何特定于任务或特定于语言的修改。此外,解决了文档级和句子级的翻译问题。除了表现出性能提升外,作者还声称该方法在低资源机器翻译方面效果很好。
1.6 On improving conversational agents
Meena[18]是一种 neural conversational agents,旨在进行更明智和更具体的改进对话 — — 定义为从人类对话中捕获重要属性(例如,流畅度)的指标。该模型通过编码器学习会话上下文,并通过解码器制定合理的响应。据报道,通过考虑使用更强大的解码器可以提高通话质量。
你也可以了解更多 Alan Nichol(Rasa HQ 的联合创始人)关于这项工作的想法[19]。
2、Creativity and Society 🎨
2.1 ML tools — reading comprehension test and sentiment analyzer
Ming Cheuk 构建了这个有趣的应用程序Albert Learns to Read[20],可以测试经过深度学习方法训练的模型的阅读理解能力,尤其是使用 Google AI 的语言模型ALBERT[21]。ALBERT 是 BERT 的微型版本,用于学习语言表示。作者在博客 Teaching Machines to Read[22]详细介绍了该项目和使用的方法。

2.2 A Self-Taught AI Researcher at Google
在这个采访A Self-Taught AI Researcher at Google[23]中,你可以直接从 Google Art&Culture 的 ML 研究人员 Emil 那里听到有关他作为一名自学成才的研究人员从事 AI 事业的经历。
3、Tools and Datasets ⚙️
3.1 Free Datasets
Google 数据集搜索[24]正式退出测试版,现在可提供多达 2500 万个数据集进行搜索。如果你想获得下一个数据科学或机器学习项目的灵感,那么这里是查找对整个 Internet 上托管的数据集的引用的地方。它基本上是用于数据集的搜索引擎,这是一项了不起的工作,需要付出巨大的努力!
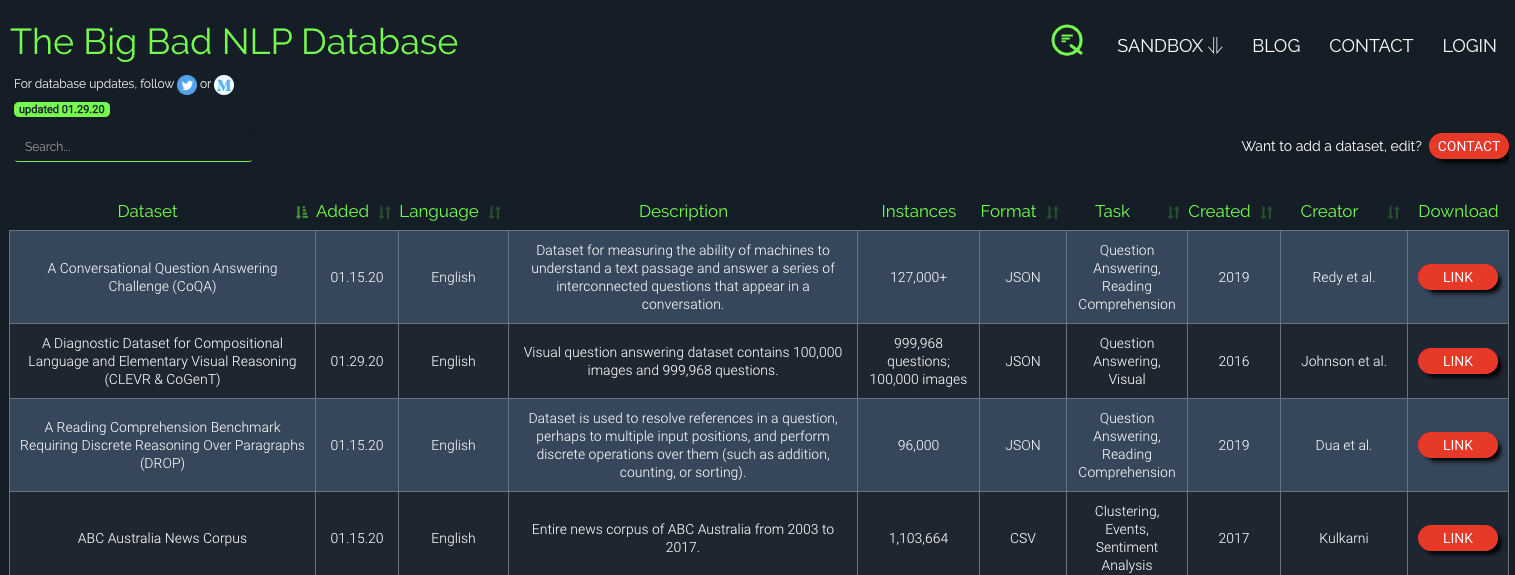
Big Bad NLP 数据库[25]是一个网站,你可以在其中搜索 200 多种 NLP 数据集的专用数据库,以执行诸如常识,情感分析,问题回答,蕴含推理等任务。
3.2 Reinforcement learning library
最近,Chris Nota 开发并发布了PyTorch 库[26],用于基于流行的深度 RL 算法(例如 DQN,PPO 和 DDPG 等)来构建强化学习代理。该库的重点是面向对象的设计,并能够快速实施和评估新型强化学习代理。
3.3 ML Explainability and Interpretability
如果你当前正在使用基于文本的语言模型,并且想了解在应用于不同语言任务时如何更轻松地解释它们,那么你可能会对Captum[27]感兴趣。Captum 是一个可解释性库,可用于分析功能重要性,解释文本和视觉模型,解释多峰模型以及其他模型(例如用于回答问题的 BERT)。
如果你对模型的可解释性感兴趣,那么这套教程[28]也可能会让您感兴趣。它包括通过 notebook 了解功能重要性的方法。
3.4 Machine learning and deep learning libraries
Google Research 团队发布了Flax[29],一种基于JAX[30]的灵活而强大的神经网络库,该库提供了使用典型的 Numpy API 进行快速计算和训练机器学习模型的框架。

Thinc[31]是由 spaCy 的开发者开发的轻量级深度学习库。它提供了功能编程 API,用于组成,配置和部署使用 PyTorch 和 TensorFlow 之类的库构建的自定义模型。
Lyft 发布了Flyte[32],它是一个多租户,可用于生产的无服务器平台,用于部署并发,可伸缩和可维护的 ML 和数据处理工作流。
3.5 A tool for conversational AI
开源对话式 AI 框架DeepPavlov[33]为构建对话系统和复杂的对话系统提供了免费且易于使用的解决方案。DeepPavlov 带有几个预定义的组件,用于解决与 NLP 相关的问题。它将 BERT(包括会话 BERT)集成到三个下游任务中:文本分类,命名实体识别(和一般的序列标记)以及问题解答。结果,它在所有这些任务上都取得了重大改进。(Google Colab[34] | Blog[35] | Demo[36])
4、Ethics in AI 🚨
4.1 Facial recognition and privacy
纽约时报针对与面部识别技术有关的隐私的不同观点撰写了一篇有趣的报告。这个故事的重点是一个名为“ Clearview”的“秘密公司”,据称该公司使用 AI 技术通过从 Twitter,Facebook 和 YouTube 等社交媒体网站上抓取的图像来构建通用的面部识别。所述技术引起了人们对隐私的担忧,但是据称它还主要用于执法。点击此处[37]阅读更多故事。
4.2 Human-Level AI Progress
Jeremy Kahn 在这个报告[38]中广泛讨论了在 AI 技术的当前发展背景下“ Narrow AI”和“ General AI”之间的区别。除了讨论的许多主题之外,关于(如果可能的话)实现 AGI 的回报还有很多问题。该报告还提到了大型高科技公司最近对这些努力进行投资的兴趣。最值得注意的是,该报告包括一些受人尊敬的研究人员提出的一些担忧,他们声称某些试图操纵 AI 叙述以利于他们的研究组织表现出“不负责任和不道德”的行为。
4.3 Understanding AI Ethics and Safety
Dr.David Leslie 发表了这份非常详尽的报告[39],主题涉及有助于在道德和安全方面更好地理解人工智能的主题。它旨在帮助开发人员和研究人员更好地为公共部门设计和实施 AI 系统。

5、Articles and Blog posts ✍️
5.1 Speeding up tokenization tutorial
Steven van de Graaf 撰写了这篇文章[40],报告说,与使用 Transformers 中的标准内置标记器相比,使用HuggingFace 的新 Tokenizer 库[41]的性能有所提高。Steven 报告说,其速度提高了 9 倍,并且实现过程花费了 10.6 秒来标记 100 万个句子。
5.2 Can language models really comprehend?
The Gradient 最近在Gary Marcus 的这篇文章[42]中发表,他讨论了他认为是 GPT-2 等语言模型背后的基本缺陷的内容。Gary Marcus 的主要观点是,经过训练能够预测下一个单词的模型不一定是可以理解或推理的模型,即“预测是理解的组成部分,而不是整体。” 他还讨论了在语言环境中先天性的重要性,并指出当前的语言模型没有考虑到这一点。
5.3 Curriculum for Reinforcement Learning
设计基于课程的方法可以帮助 RL agent 学习吗?Lillian Weng 总结了几种基于课程的方法[43],以及如何利用它们来培训有效的强化学习代理。Weng 讨论了设计高效的课程学习方法所面临的挑战,该方法通常需要对任务的复杂性进行排序,并向模型提供一系列任务,这些任务会增加培训过程中的难度。
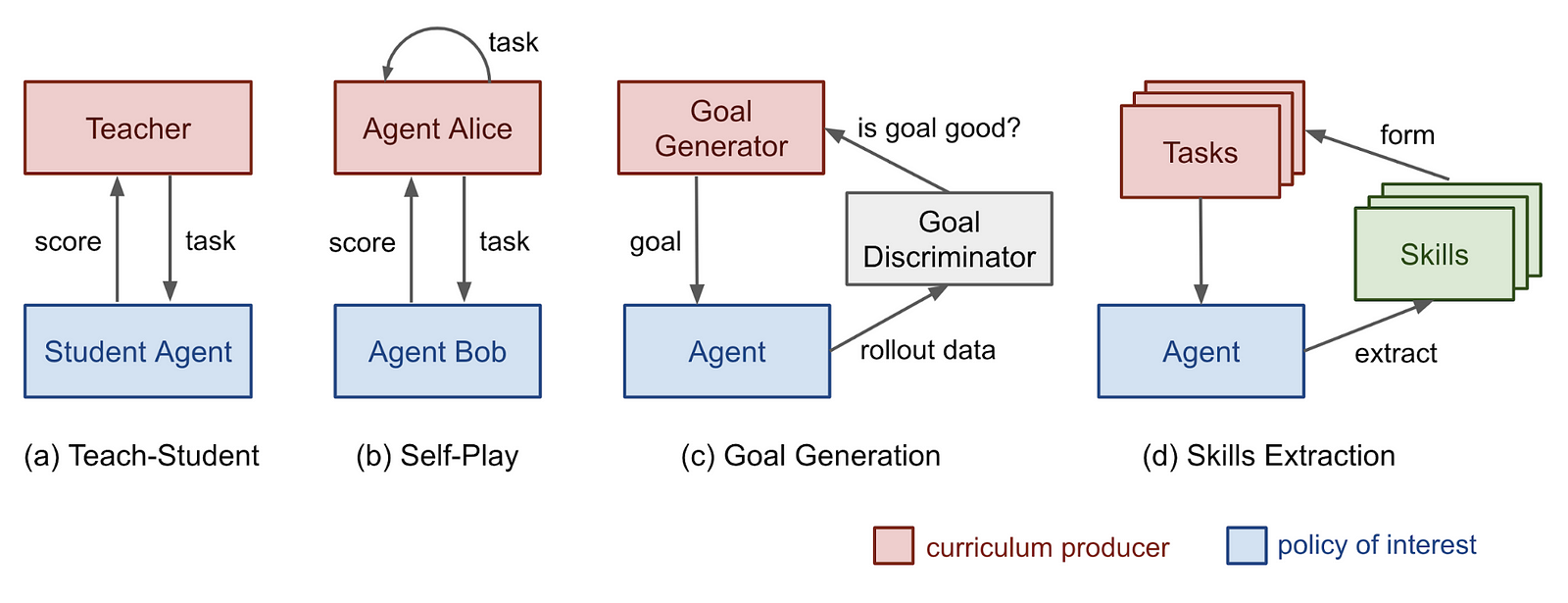
5.4 Introduction to NumPy
我总是推荐任何机器学习入门的人来使用 NumPy 进行大量练习。当今,许多用于深度学习和机器学习的高级库都以某种方式使用 NumPy API,因此它是内部了解的非常重要的工具。Anne Bonner 最近发布了这个非常详细的 numpy 教程[44],介绍了 NumPy 的基础。
6、Education 🎓
6.1 Foundations of machine learning and statistical inference
来自加州理工学院的 Anima Anandkumar 发布了一门名为“机器学习和统计推论的基础”的课程。该课程侧重于 ML 概念,例如矩阵,张量,优化,概率模型,神经网络等。这是一门很棒的课程,因为它侧重于 ML 的理论方面,这对于理解和改进更高级的方法同样重要。(视频播放列表[45]|课程提纲[46])
6.2 Deep Learning Lecture Series
DeepMind 与 UCL 合作发布了深度学习讲座系列[47],其中包括 12 个讲座,这些讲座将由 DeepMind 的领先研究科学家进行。主题包括如何使用注意力,记忆力和生成模型等方法训练神经网络。
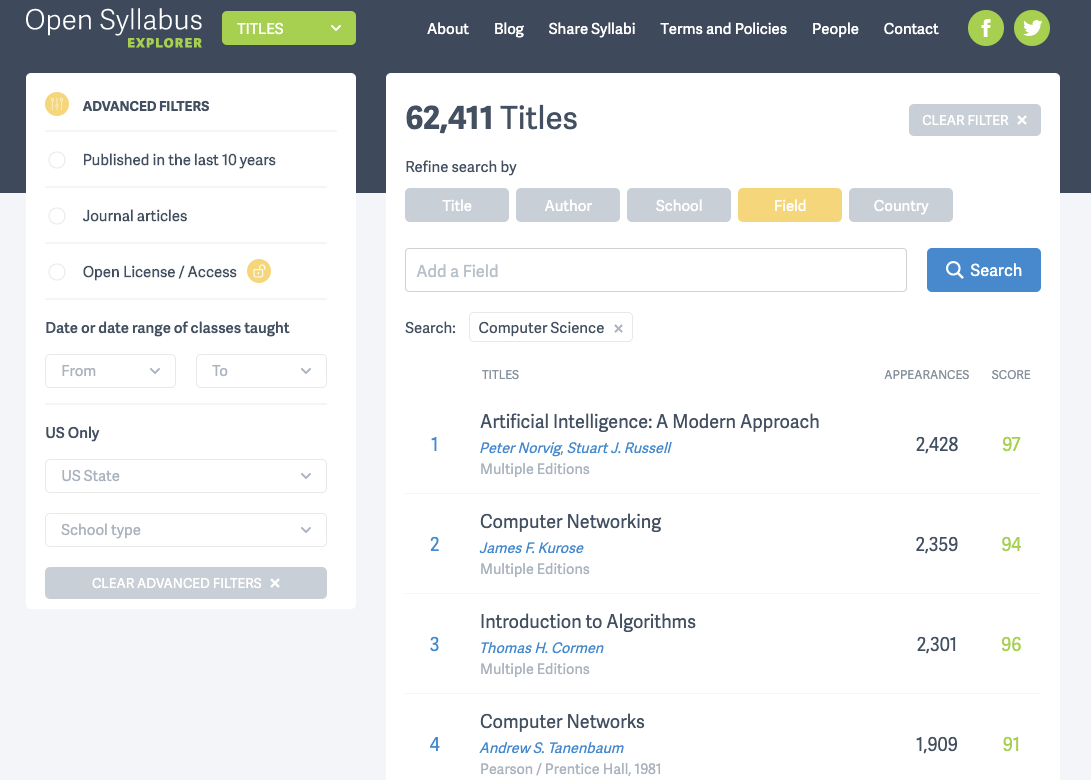
6.3 Open Syllabus
教育是不断发展的社区和整个行业的重要组成部分, 这是种植创新种子的地方。Open Syllabus[48]是一个非营利性组织,它利用众包的力量将高等教育课程映射到一个免费的在线数据库中。它目前包含大约 700 万个教学大纲。
6.4 Discussing, Sharing, and Learning about ML
r/ResearchML[49]是用于讨论 ML 论文的新的机器学习子目录。这一主题更侧重于研究并鼓励更深入的讨论。
PracticalAI[50]是一个网站,你可以在其中浏览和发现由社区和专家策划的 ML 主题。

7、Notable Mentions ⭐️
How we built the good first issues feature[51]:了解有关 GitHub 如何利用机器学习为开发人员发现简单和个性化问题的更多信息,以便他们可以解决与他们的兴趣相匹配的问题。这鼓励了来自开源贡献者的更快和更多的贡献。
紧跟 Sebastian Ruder 的 NLP News[52],以获取最新的 NLP 最新新闻。重点包括 NLP 进展的更新,过去十年的回顾,新的 NLP 课程以及其他主题。
一份超赞的TensorFlow 2.0 深度学习 notebook[53]列表,范围从 CycleGAN 到 Transformers 到图像字幕任务。它们由 LBNL 的科学学院深度学习公开发布。
一篇令人印象深刻且易于理解的博客文章,解释了贝叶斯神经网络[54]的基础,入门的绝佳介绍。
An Opinionated Guide to ML Research[55]:John Schulman 就如何更好地选择研究问题以及在实施和解决手头的研究任务方面更具战略性等方面,为即将到来的机器学习研究人员提供了一些建议,还分享了个人发展和持续进步的技巧。
今日限定款分割线,右下角链接可以阅读原文~
本文参考资料
[1] RobBERT: https://arxiv.org/abs/2001.06286
[2] BERTje: https://arxiv.org/abs/1912.09582
[3] 德语 German BERT: https://deepset.ai/german-bert
[4] 葡萄牙语 Portuguese BERT: https://github.com/neuralmind-ai/portuguese-bert
[5] CamemBERT: https://arxiv.org/abs/1911.03894
[6] FlauBERT: https://arxiv.org/abs/1912.05372
[7] AlBERTo: http://ceur-ws.org/Vol-2481/paper57.pdf
[8] UmBERTo: https://github.com/musixmatchresearch/umberto
[9] BETO: https://github.com/dccuchile/beto
[10] araBERT: https://colab.research.google.com/drive/1KSy89fAkWt6EGfnFQElDjXrBror9lIZh
[11] Transformer 库: https://huggingface.co/models
[12] 2.4.1: https://github.com/huggingface/transformers/releases
[13] 论文: https://arxiv.org/abs/2001.06296
[14] hallucination : https://arxiv.org/abs/1910.08684
[15] LaserTagger: https://ai.googleblog.com/2020/01/encode-tag-and-realize-controllable-and.html
[16] 报告: https://arxiv.org/abs/2001.07092
[17] mBART: https://arxiv.org/pdf/2001.08210.pdf
[18] Meena: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
[19] 关于这项工作的想法: https://venturebeat.com/2020/01/31/with-googles-meena-are-ai-assistants-about-to-get-a-lot-smarter/
[20] Albert Learns to Read: https://littlealbert.now.sh/#/
[21] ALBERT: https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
[22] 博客 Teaching Machines to Read: https://www.spark64.com/post/machine-comprehension
[23] A Self-Taught AI Researcher at Google: https://blog.floydhub.com/emils-story-as-a-self-taught-ai-researcher/
[24] Google 数据集搜索: https://blog.google/products/search/discovering-millions-datasets-web/
[25] Big Bad NLP 数据库: https://quantumstat.com/dataset/dataset.html
[26] PyTorch 库: https://github.com/cpnota/autonomous-learning-library
[27] Captum: https://captum.ai/
[28] 这套教程: https://www.kaggle.com/learn/machine-learning-explainability
[29] Flax: https://github.com/google-research/flax/tree/prerelease
[30] JAX: https://github.com/google/jax
[31] Thinc: https://thinc.ai/
[33] DeepPavlov: https://github.com/deepmipt/DeepPavlov
[34] Google Colab: https://colab.research.google.com/github/deepmipt/dp_notebooks/blob/master/DP_tf.ipynb
[36] Demo: https://demo.deeppavlov.ai/#/en/textqa
[37] 此处: https://www.nytimes.com/2020/01/18/technology/clearview-privacy-facial-recognition.html
[38] 这个报告: https://fortune.com/longform/ai-artificial-intelligence-big-tech-microsoft-alphabet-openai/
[39] 这份非常详尽的报告: https://www.turing.ac.uk/sites/default/files/2019-06/understanding_artificial_intelligence_ethics_and_safety.pdf
[41] HuggingFace 的新 Tokenizer 库: https://github.com/huggingface/tokenizers
[42] Gary Marcus 的这篇文章: https://thegradient.pub/gpt2-and-the-nature-of-intelligence/
[43] 几种基于课程的方法: https://lilianweng.github.io/lil-log/2020/01/29/curriculum-for-reinforcement-learning.html
[44] 非常详细的 numpy 教程: https://numpy.org/devdocs/user/absolute_beginners.html
[45] 视频播放列表: https://www.youtube.com/playlist?list=PLVNifWxslHCDlbyitaLLYBOAEPbmF1AHg
[46] 课程提纲: http://tensorlab.cms.caltech.edu/users/anima/cms165-2020.html
[47] 深度学习讲座系列: https://www.eventbrite.co.uk/o/ucl-x-deepmind-deep-learning-lecture-series-general-29078980901
[48] Open Syllabus: https://opensyllabus.org/
[49] r/ResearchML: https://www.reddit.com/r/ResearchML/
[50] PracticalAI: https://practicalai.me/explore/content/
[51] How we built the good first issues feature: https://github.blog/2020-01-22-how-we-built-good-first-issues/
[53] TensorFlow 2.0 深度学习 notebook: https://github.com/NERSC/dl4sci-tf-tutorials
[54] 贝叶斯神经网络: https://engineering.papercup.com/posts/bayesian-neural-nets/
[55] An Opinionated Guide to ML Research: http://joschu.net/blog/opinionated-guide-ml-research.html