

Thanks to Kaiyuan (WeChat: NewBeeNLP) for this great translation.
欢迎来到 NLP 时事简报!全文较长,建议收藏。
另外加了目录方便直接索引到自己感兴趣的部分。enjoy
- 1、Publications 📙
- 1.1 Turing-NLG:
- 1.2 Neural based Dependency Parsing
- 1.3 End-to-end Cloud-based Information Extraction with BERT
- 1.4 Question Answering Benchmark
- 1.5 Radioactive data: tracing through training
- 1.6 REALM: Retrieval-Augmented Language Model Pre-Training
- 2、Creativity and Society 🎨
- 2.1 允许在科学会议上进行远程论文和海报展示
- 2.2 Abstraction and Reasoning Challenge
- 2.3 ML and NLP Publications in 2019
- 2.4 Growing Neural Cellular Automata
- 2.5 Transformer attention可视化
- 2.6 SketchTransfer
- 3、Tools and Datasets ⚙️
- 3.1 DeepSpeed + ZeRO
- 3.2 一个用于进行快速有效的3D深度学习研究的库
- 3.3 管理你的ML项目配置
- 3.4 贝叶斯网络因果推理工具包
- 3.5 TyDi问答:多语言问答基准
- 3.6 Question Answering for Node.js
- 4、Ethics in AI 🚨
- 4.1 识别文本中的subjective bias
- 4.2 Artificial Intelligence, Values and Alignment
- 4.3 关于审核AI系统
- 5、Articles and Blog posts ✍️
- 5.1 用于NLP系统的模型蒸馏
- 5.2 单词的上下文表示
- 5.3 神经网络中的稀疏性
- 5.4 训练你自己的语言模型
- 5.5 分词器Tokenizer
- 6、Education 🎓
- 6.1 阿姆斯特丹自由大学机器学习课程
- 6.2 机器学习数学资源
- 6.3 深度学习入门
- 6.4 Pytorch深度学习
- 6.5 Missing Semester of Your CS
- 6.6 深度学习进阶
- 7、Noteworthy Mentions ⭐️
1、Publications 📙
1.1 Turing-NLG: A 17-billion-parameter language model by Microsoft
图灵自然语言生成(T-NLG)[1]是由 Microsoft AI 研究人员提出的 170 亿参数语言模型。除了是迄今为止最大的已知语言模型(如下图所示)之外,T-NLG 是基于 78 层 Transformer 的语言模型,其在 WikiText-103 上的困惑度性能优于之前的最新技术成果(由NVIDIA Megatron-LM[2]持有) 。T-NLG 在各种任务(例如问题回答和抽象摘要)上进行了测试,同时分别显示了模型的好处,例如零简短问题功能和最小化监督。此外,该模型得益于 DeepSpeed 库(与 PyTorch 兼容)和 ZeRO 优化器,这两者也会在本期简报中具体介绍。
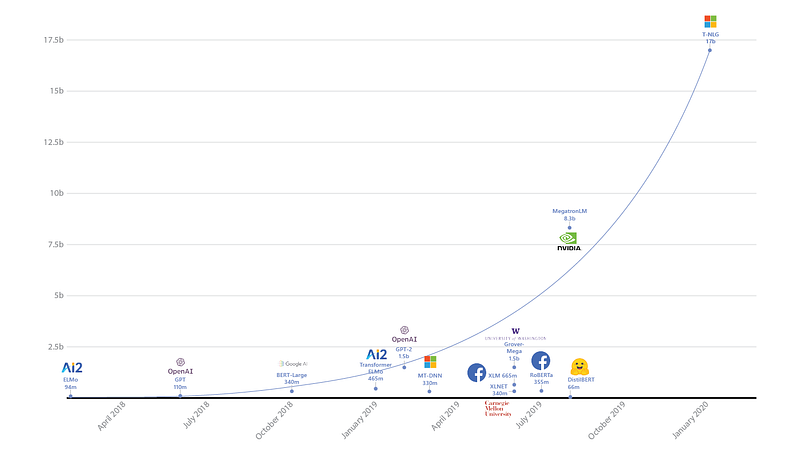
语言模型参数大小
1.2 Neural based Dependency Parsing
Miryam de Lhoneux 公布了其博士学位论文“Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages[3]”。这项工作是关于使用神经学方法以类型多样的语言(即以结构上不同的方式构造和表达含义的语言)进行依赖关系解析[4]。论文指出 RNN 和递归层可能有助于合并到解析器中,因为它们有助于告知具有解析所需的重要语言知识的模型。更多 ideas 包括使用多语言解析和参数共享策略来解析相关和不相关语言。
1.3 End-to-end Cloud-based Information Extraction with BERT
研究人员发表了一篇论文”Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents”[5],描述了 BERT 等 Transformer 模型如何帮助特定领域的业务文档(例如监管文件和物业租赁协议)中的端到端信息提取。这种类型的工作不仅可以帮助优化业务运营,而且还显示了基于 BERT 的模型在带注释数据很少的情况下的适用性和有效性。同时提出并讨论了在云上运行的应用程序及其实现细节(请参见下图)。
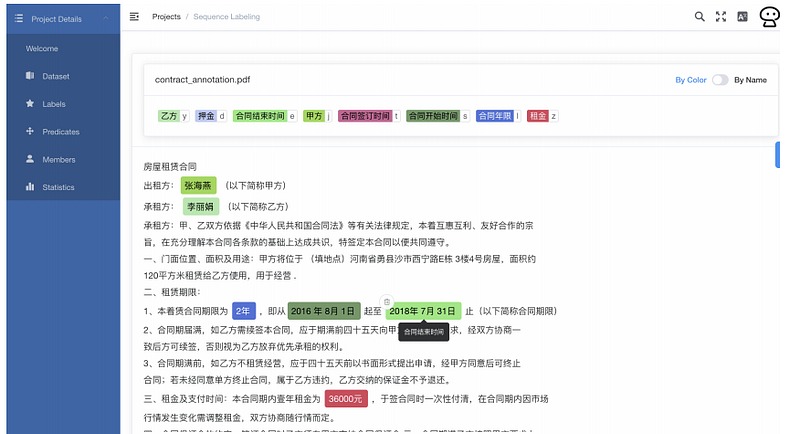
1.4 Question Answering Benchmark
Wolfson 等发布了一个question understanding benchmark[6],以及一种用于分解计算适当答案所必需的问题的方法。他们利用众包来注释分解问题所需的必要步骤, 为了展示该方法的可行性和适用性,他们改进了使用 HotPotQA 数据集的开放域问答。
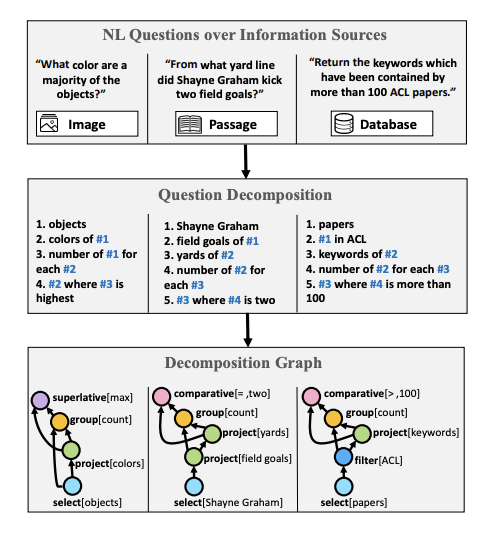
不同来源的问题具有相似的组成结构。
1.5 Radioactive data: tracing through training
Facebook AI 研究人员最近发表了一项有趣的工作[7],旨在标记图像(称为「radioactive data」),以验证该特定数据集是否用于训练 ML 模型。他们发现,可以使用巧妙的标记将特征移向某个方向,即使只有 1%的训练数据是 radioactiv,模型也可以使用该标记帮助检测‘radioactive data’的使用情况。这极具挑战性,因为数据中的任何更改都可能会降低模型的准确性。作者说,这项工作可以“帮助研究人员和工程师跟踪用于训练模型的数据集,以便他们可以更好地了解各种数据集如何影响不同神经网络的性能”,在关键任务 ML 应用程序中,这似乎是一种重要的方法。如果感兴趣可以查看完整论文[8]了解具体信息。
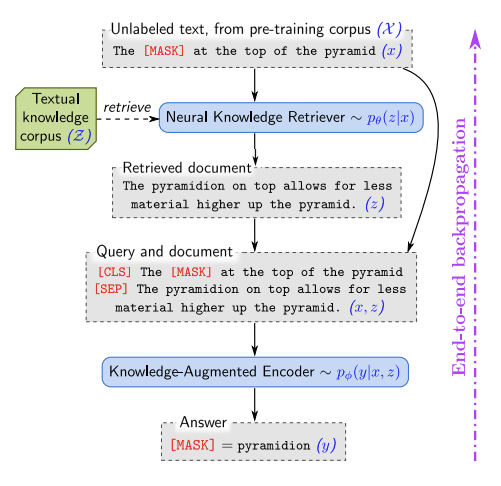
1.6 REALM: Retrieval-Augmented Language Model Pre-Training
REALM [9] 是基于神经的大规模检索方法,该方法利用文本知识的语料库以无监督的方式预训练语言模型。该方法的主要目的是以一种更可解释的方式捕获知识,具体而言是利用世界知识对模型进行训练和预测。使用 REALM 处理和评估的任务包括开放域问答基准, 除了提高模型的准确性外,其他好处还包括模块化和可解释性组件。
2、Creativity and Society 🎨
2.1 允许在科学会议上进行远程论文和海报展示
过去一周有请愿书散发,以便在与 ML 相关的科学会议上进行远程论文和海报展示,可以在change.org[10]上阅读有关它的更多信息。深度学习的先驱 Yoshua Bengio 似乎在倡导人们去签署请愿书, 并在他的新博客[11]中阐明了这一点。
2.2 Abstraction and Reasoning Challenge
FrançoisChollet 最近发布了一个 Kaggle 竞赛,他发布了抽象推理语料库(ARC)[12],旨在鼓励用户创建可以解决从未接触过的推理任务的 AI 系统。希望能够开始构建更强大的 AI 系统,从而能够更好,快速地自行解决新问题,这可能有助于解决更具挑战性的现实应用,例如改善在极端和多样化环境中运行的自动驾驶汽车 。
2.3 ML and NLP Publications in 2019
Marek Rei 发布机器学习和 NLP 领域 2019 年出版数据统计[13],分析中包括的会议是 ACL,EMNLP,NAACL,EACL,COLING,TACL,CL,CoNLL,NeurIPS,ICML,ICLR 和 AAAI。
2.4 Growing Neural Cellular Automata
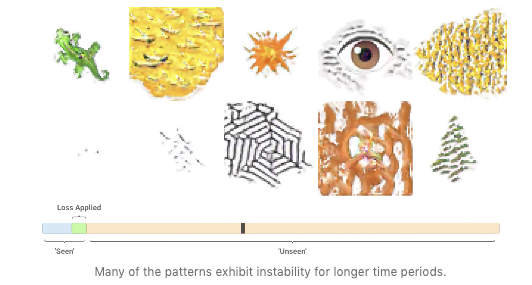
Morphogenesis是一个自组织过程,通过该过程,蝾螈等某些生物可以再生或修复身体损伤。该过程对于扰动是鲁棒的,并且本质上是自适应的。受这种生物学现象的启发,需要更好地了解这一过程,研究人员发表了一篇题为”Growing Neural Cellular Automata”[14]的论文,该论文采用了可区分的形态发生模型,旨在复制自我修复系统的行为和特性,并希望能够制造出具有与生物生命相同的坚固性和可塑性的自我修复 machines。此外,这将有助于更好地了解再生过程本身, 许多应用注入再生医学以及社会和生物系统的建模等都将受益。
2.5 Transformer attention 可视化
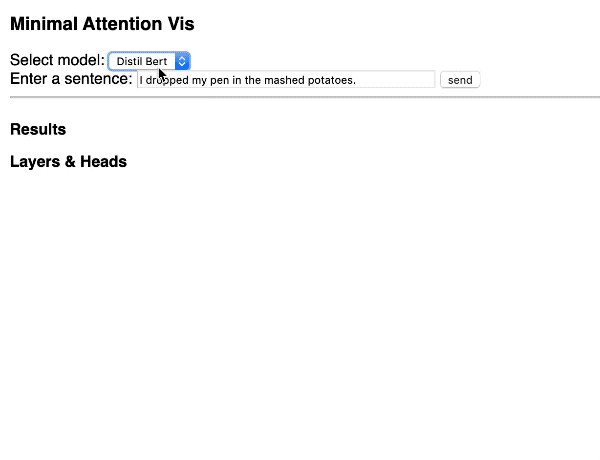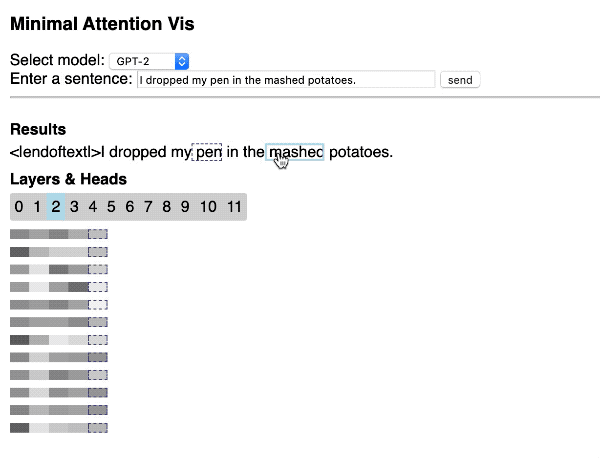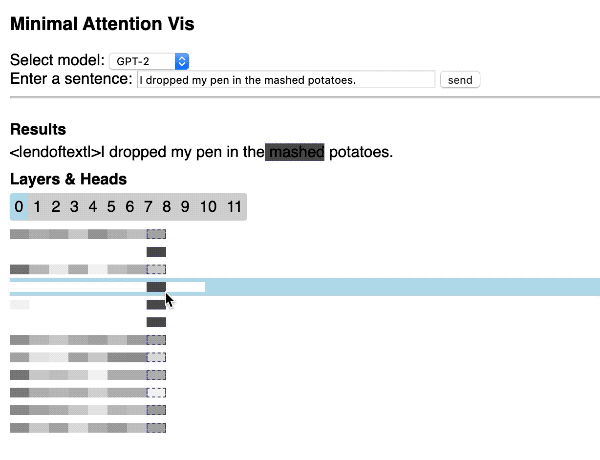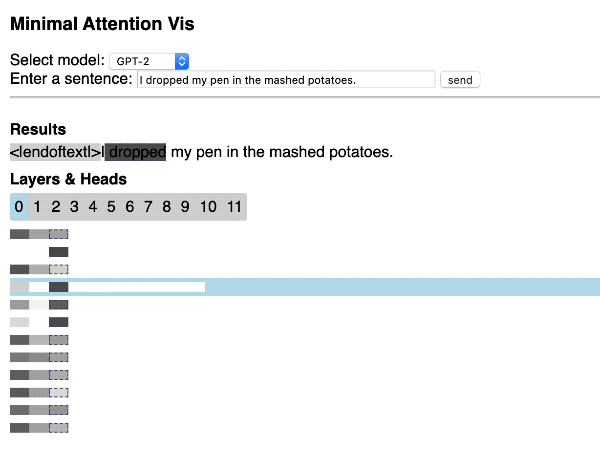
Hendrik Strobelt 开源项目显示了如何使用 Hugging Face 库和 d3.js 通过 Web 应用程序快速构建简单的交互式 Transformer 注意可视化[15]。
2.6 SketchTransfer
SketchTransfer[16]提出了一项新任务,以测试深度神经网络在存在/不存在细节时支持不变性的能力。长期以来一直争论的是,深度网络无法推广到训练期间尚未发现的变化,人类可以相对轻松地完成某些事情,例如在观看动画片时处理丢失的视觉细节。本文讨论并发布了一个数据集,以通过提供未标记的草图图像和标记的真实图像示例来帮助研究人员仔细研究“细节不变性”问题。

3、Tools and Datasets ⚙️
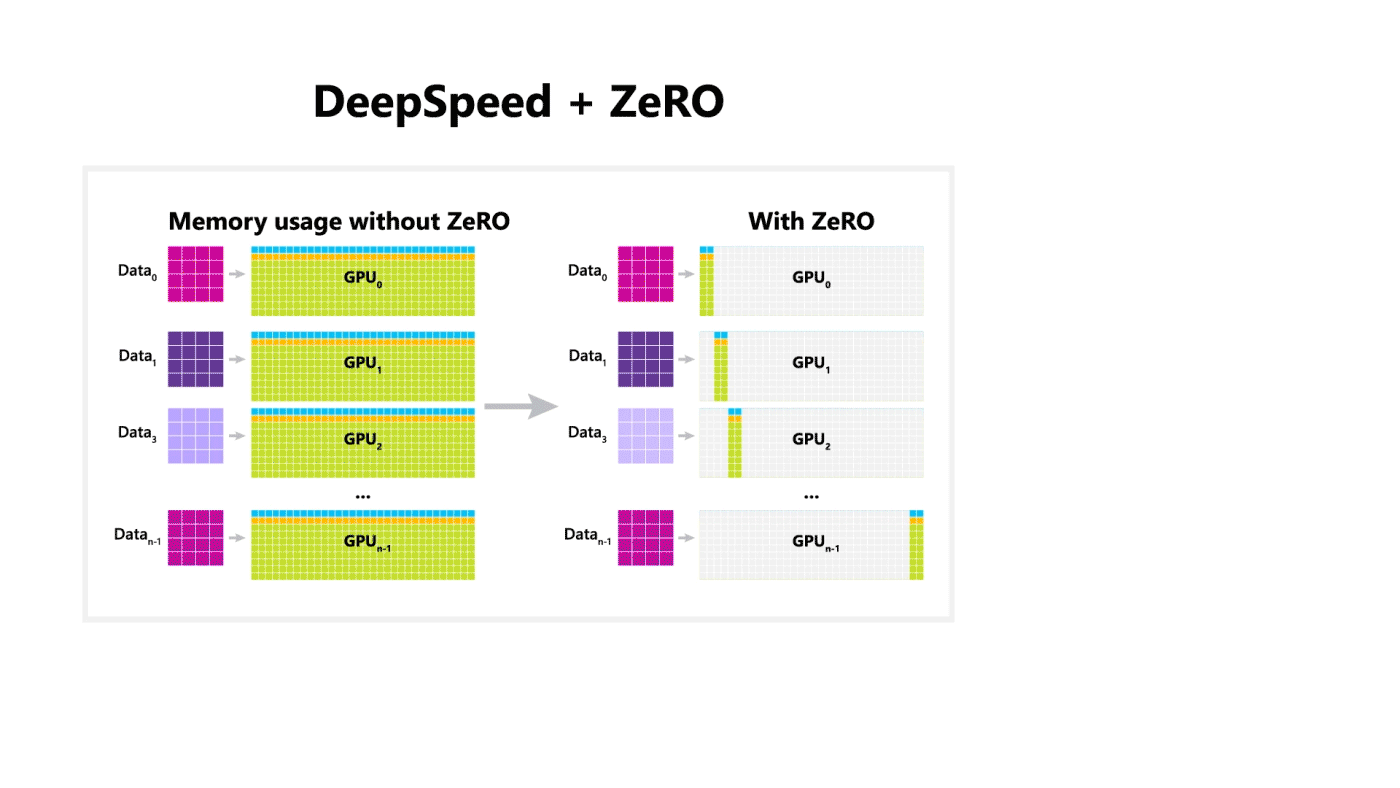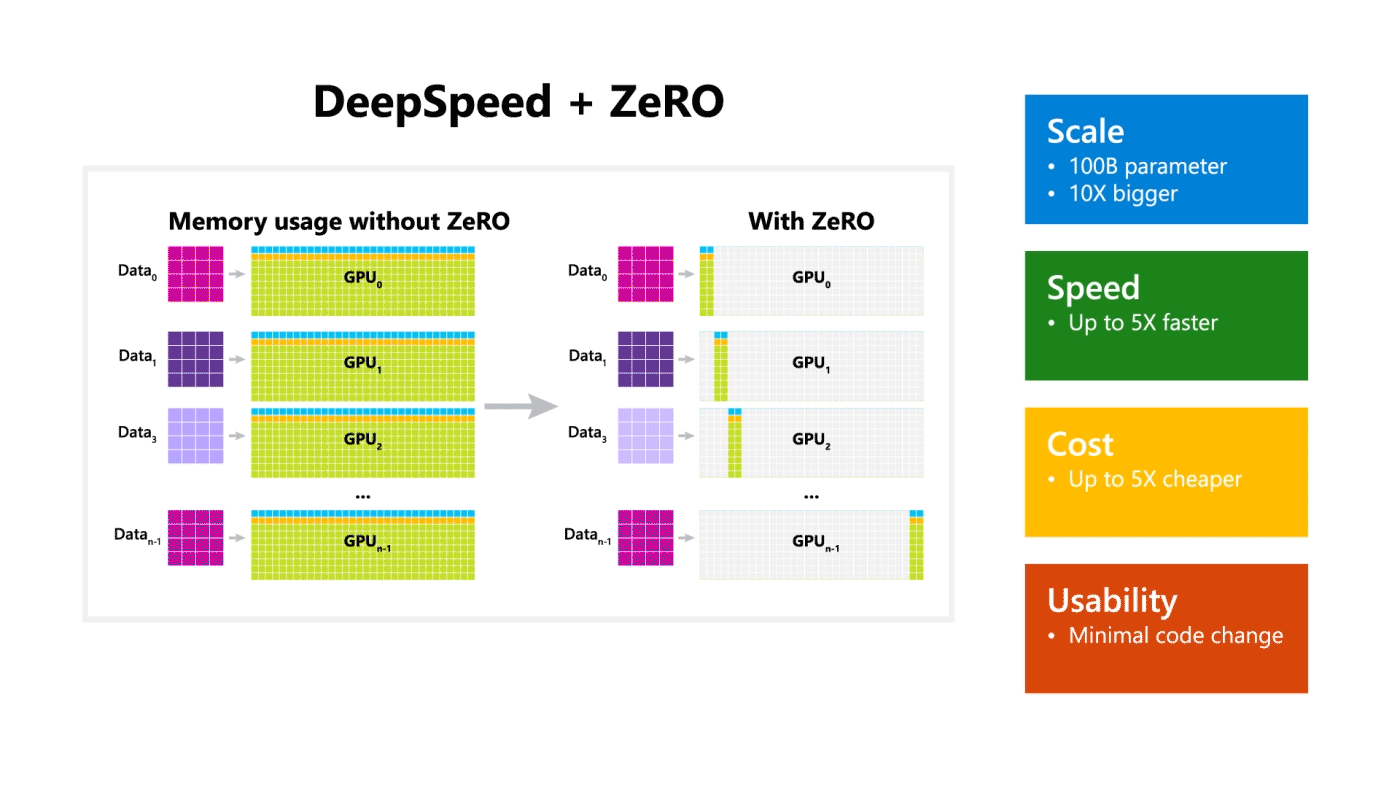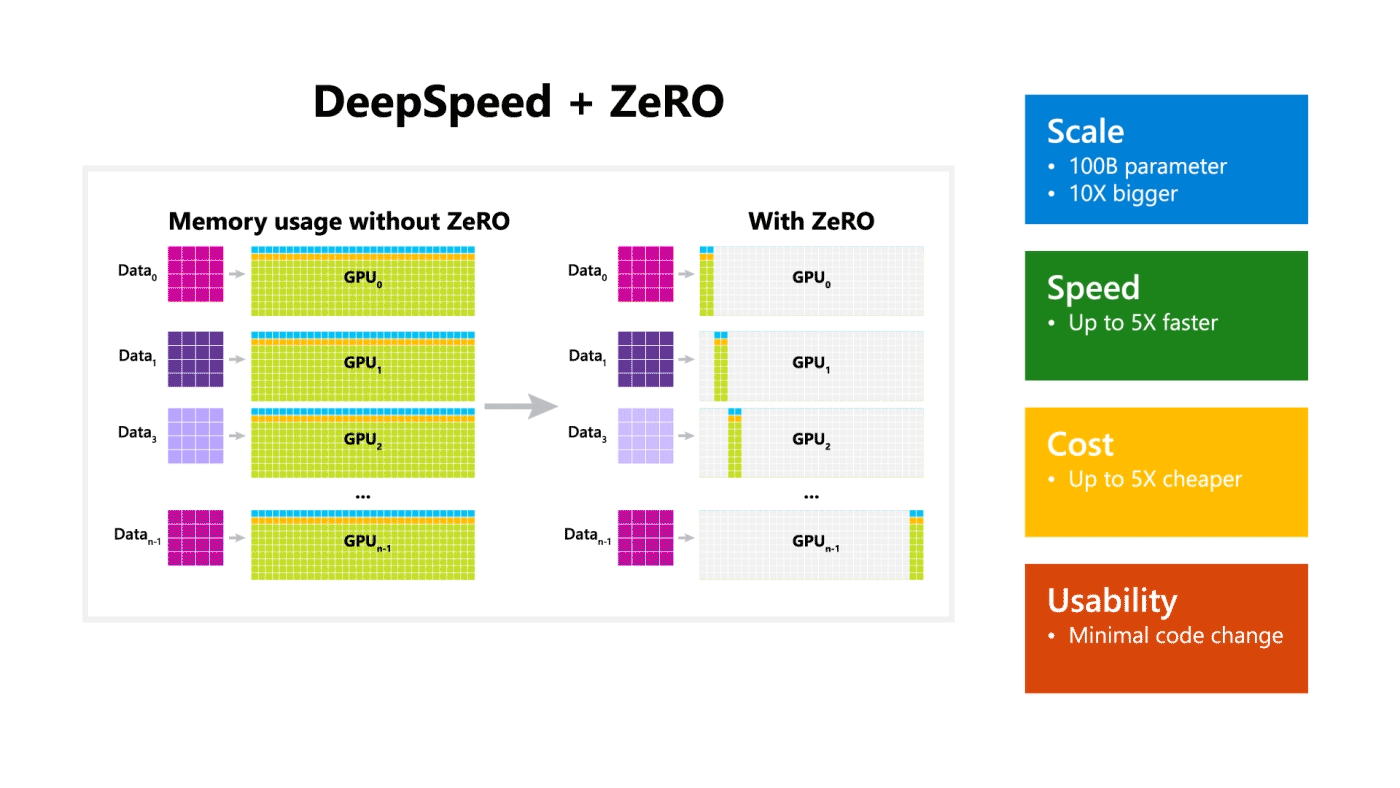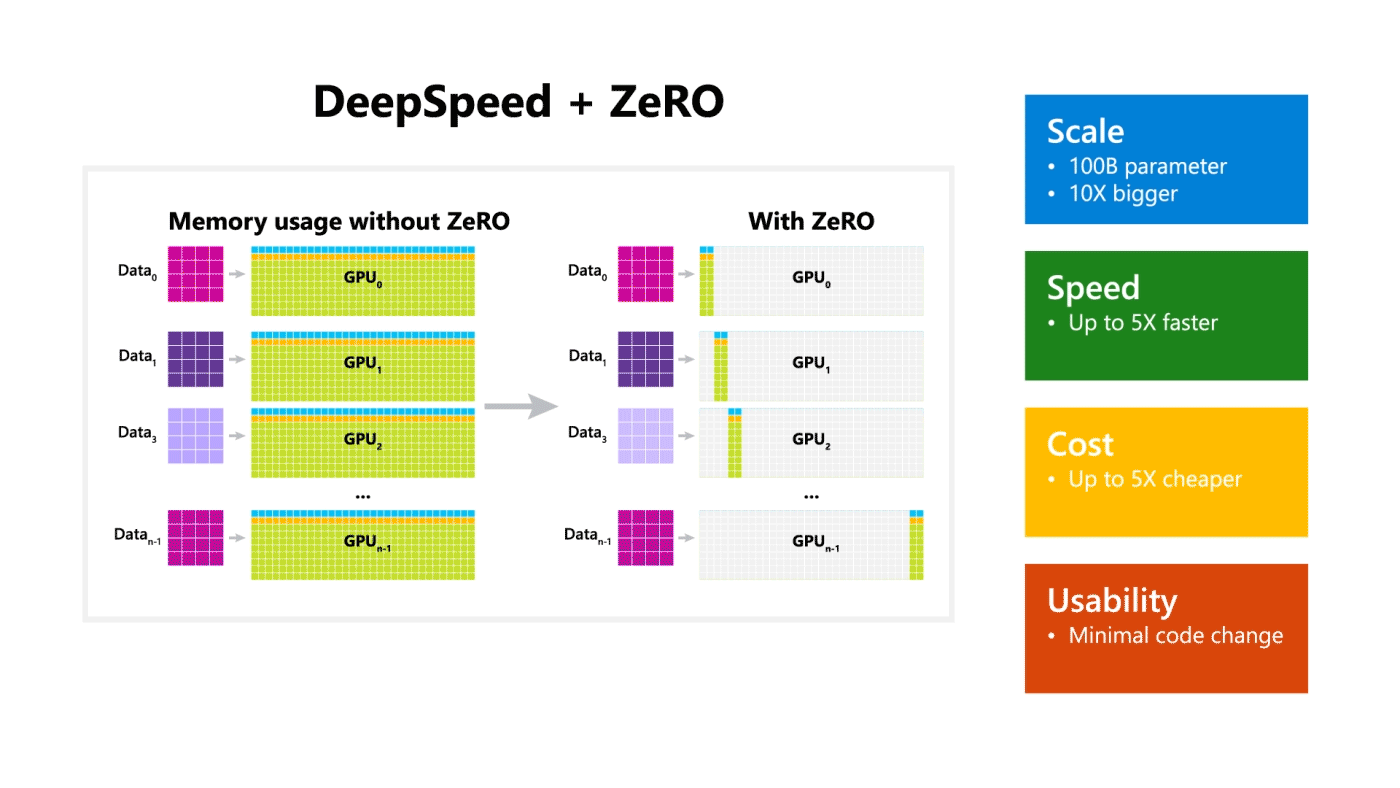
3.1 DeepSpeed + ZeRO
Microsoft 开源了一个称为 DeepSpeed 的训练优化库,该库与 PyTorch 兼容,并且可以训练 1000 亿个参数的模型。该库侧重于训练模型的四个重要方面:规模,速度,成本和可用性。DeepSpeed 与 ZeRO[18]一起发布,ZeRO 是一种内存优化技术,可在当前 GPU 技术中实现大规模分布式深度学习,同时将吞吐量提高到当前最佳系统的三到五倍。ZeRO 允许训练任意大小的模型,这些模型可以根据共享模型状态适合聚合的可用内存。
3.2 一个用于进行快速有效的 3D 深度学习研究的库
PyTorch3D[19]是用于基于 3D 的深度学习研究的开源工具包。这个 PyTorch 库旨在帮助深度学习系统中的 3D 数据支持和理解,该库由常用 3D 运算符和损失函数的快速优化实现组成, 它还带有模块化的可区分渲染器,可帮助进行复杂 3D 输入的研究并支持高质量 3D 预测。
3.3 管理你的 ML 项目配置
Hydra[20]是基于 Python 的配置工具,用于更有效地管理复杂的 ML 项目。它旨在通过为 ML 项目提供功能的配置重用来帮助 PyTorch 研究人员。它提供的主要好处是它允许程序员像编写代码一样编写配置,这意味着可以轻松地覆盖配置文件。Hydra 还可以帮助自动管理 ML 项目输出的工作目录,这在需要保存和访问多个作业的多个实验结果时非常有用。
3.4 贝叶斯网络因果推理工具包
CausalNex[21]是用于“与贝叶斯网络进行因果推理”的工具包。该工具旨在将机器学习和因果推理相结合,以发现数据中的结构关系。作者还准备了关于使用 Python 库推断贝叶斯网络原因和原因的入门指南。

3.5 TyDi 问答:多语言问答基准
Google AI 发布了TyDi QA[22],它是一种多语言的数据集,可以鼓励研究人员对更多类型多样的语言进行问答,这些语言以不同的方式构建和表达含义。这样做的目的是激励研究人员在类型上距离遥远的语言(例如阿拉伯语,孟加拉语,韩语,俄语,泰卢固语和泰语)上建立更强大的模型,以便将其推广到更多种语言。

3.6 Question Answering for Node.js
Hugging Face 发布了基于 DistilBERT 的问答库[23],并继续使 NLP 更加易于访问。该模型可以使用 Node.js 在生产中运行,只需 3 行代码。该模型利用了由 Hugging Face 和 TensorFlow.js(用于将机器学习模型与 Javascript 结合使用的流行库)构建的 Tokenizer 的快速实现。
4、Ethics in AI 🚨
4.1 识别文本中的 subjective bias
计算社会科学的研究员 Diyi Yang 讨论了 AI 系统如何帮助识别文本信息中的主观偏见[25]。这是涉及 AI 系统和 NLP 的重要研究领域,尤其是当我们讨论诸如新闻标题之类的文本媒体的消费时,很容易将其构架成偏向消费者,而实际上他们应该追求更加客观。从应用程序的角度来看,自动识别文本媒体中存在的主观偏见以帮助消费者更加了解他们正在消费的内容变得至关重要。此外还讨论了 AI 如何也可以保持偏见。
4.2 Artificial Intelligence, Values and Alignment
人工智能系统的兴起以及它们如何与人类价值观保持一致是涉及人工智能系统伦理学的活跃研究领域。DeepMind[26]最近发布了一篇论文,深入探讨了围绕 AI 对齐的哲学问题。该报告重点讨论了两个部分,即技术部分(即如何对从 AI 代理获得可靠结果的值进行编码)和规范性(在 AI 中进行编码的原则是正确的)以及它们之间的联系以及可以确保的部分。本文主张采用一种基于原则的 AI 对齐方法,并在信念和观点存在差异的情况下保持公平待遇。
4.3 关于审核 AI 系统
VentureBeat 报告称,Google 研究人员与其他小组合作创建了一个名为 SMACTR 的框架,该框架使工程师可以审核 AI 系统。进行这项工作的原因是为了解决目前被消费者广泛使用以供使用的 AI 系统存在的问责制差距。在这里阅读完整的报告[27],在这里阅读完整的论文[28]。
5、Articles and Blog posts ✍️
5.1 用于 NLP 系统的模型蒸馏
在NLP Highlights[29]播客的新剧集中,Thomas Wolf 和 Victor Sanh 讨论了模型蒸馏,以及如何将其用作压缩大型模型(如 BERT)以用于可扩展的实际 NLP 应用程序的可行方法。他们在他们提出的称为DistilBERT[30]的方法中对此概念进行了进一步的讨论,在该方法中,他们构建较小的模型(基于较大模型的相同体系结构),以根据该模型的输出来模仿较大模型的行为。本质上,较小的模型(学生)会尝试根据其输出分布来拟合教师的概率分布。
5.2 单词的上下文表示
最近,关于诸如 BERT 的上下文化方法成功用于处理各种复杂的 NLP 任务的讨论很多。在这篇文章中,Kawin Ethayarajh 试图回答以下问题:诸如 BERT,ELMo 和 GPT-2 之类的上下文模型及其上下文化的词表示形式是什么[31]?主题包括语境性,语境特定性的度量以及静态嵌入与语境化表示之间的比较。
5.3 神经网络中的稀疏性
ML 研究人员 FrançoisLagunas 写了这篇很棒的文章,Is the future of Neural Networks Sparse?[32] 讨论了他对在神经网络模型中采用稀疏张量的乐观态度。希望采用某种形式的稀疏性来减小当前模型的大小,这些模型由于其大小和速度而在某些时候变得不切实际。由于当前模型(例如 Transformer)的庞大规模(通常依赖数十亿个参数),因此在 ML 中可能值得探讨这一概念。但是,从开发人员工具的角度来看,在 GPU 上的神经网络中支持有效稀疏性的实现细节尚不清楚,这是机器学习社区正在努力的事情。
5.4 训练你自己的语言模型
如果你想学习如何从零开始训练语言模型[33],请查看 Hugging Face 的这份令人印象深刻且全面的教程。他们显然利用了自己的库 Transformers 和 Tokenizers 来训练模型。
5.5 分词器 Tokenizer
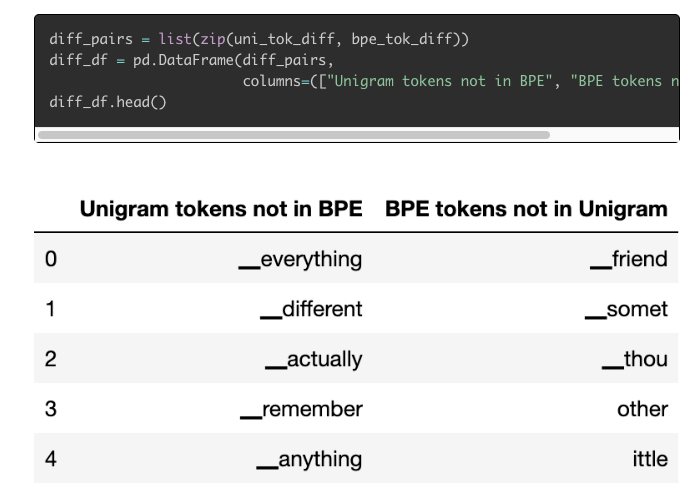
Cathal Horan 发表了一篇令人印象深刻且非常详细的博客文章,Tokenizers: How machines read[34],内容涉及最新的 NLP 模型如何以及使用哪种类型的 tokenizer 来帮助机器学习算法从文本信息中学习。他还讨论并激发了为什么 tokenizer 是激动人心且重要的研究活跃领域的原因。文章甚至还展示了如何使用 SentencePiece 和 WordPiece 等标记化方法来训练自己的标记化工具。
6、Education 🎓
6.1 阿姆斯特丹自由大学机器学习课程
现在,你可以在线学习 2020 MLVU 机器学习课程[35],其中包括全套幻灯片,视频和教学大纲。它旨在作为 ML 的入门,但它也包含其他与深度学习相关的主题,例如 VAE 和 GAN。
6.2 机器学习数学资源
SuzanaIlić 和东京机器学习(MLT)在使 ML 教育民主化方面一直做着惊人的工作。例如,该库Machine-Learning-Tokyo/Math_resources[36]展示了免费的在线资源集合,用于学习 ML 中使用的数学概念的基础。
6.3 深度学习入门
MIT 的“深度学习入门”课程[37], 每周都会发布新的讲座,所有方面和视频(包括编码实验室)都将发布。
6.4 Pytorch 深度学习
Alfredo Canziani 发布了PyTorch 深度学习[38]微型课程的幻灯片和笔记本,该资源库还包含一个配套网站,其中包含对本课程中所教授概念的文字描述。
6.5 Missing Semester of Your CS
由麻省理工学院的教员发布的“Missing Semester”[39]是一门很棒的在线课程,其中包含对非开发背景的数据科学家而言可能有用的材料。它包括诸如 Shell 工具和脚本以及版本控制之类的主题。
6.6 深度学习进阶
CMU 发布了“Advanced Deep Learning”[40]课程的幻灯片和教学大纲,其中包括诸如自动回归模型,生成模型以及自我监督/预测学习等主题。该课程适用于 MS 或 Ph.D, 具有 ML 高级背景的学生。
7、Noteworthy Mentions ⭐️
BERT-of-Theseus[41]提出了一种通过将 BERT 模型划分为原始组件来逐步替换和压缩 BERT 模型的方法。通过逐步替换和训练,还具有将模型的原始组件和压缩版本组合在一起的优势。所提出的模型优于 GLUE 基准上的其他知识提炼方法。
这儿找到一份有趣的课程,称为“机器学习入门”[42],涵盖了 ML 基础知识,监督回归,随机森林,参数调整以及许多其他基本的 ML 主题。
希腊语 BERT(GreekBERT)[43]模型现在可通过 Hugging Face Transformers 库使用。
Jeremy Howard[44]发表了一篇论文,描述了 fastai 深度学习库,该库被广泛用于研究并教授其深度学习开放课程, 推荐给致力于构建和改进深度学习和 ML 库的软件开发人员。
Deeplearning.ai 完成了 TensorFlow 所有四个课程的发布:TensorFlow: Data and Deployment Specialization[45]。该专业的主要目的是教育开发人员如何在不同的场景中有效地部署模型,以及在训练模型时以有趣且有效的方式使用数据。
Sebastian Raschka 最近发表了一篇题为《Python 中的机器学习:数据科学,机器学习和人工智能的主要发展和技术趋势[46]》的论文。本文是对机器学习工具前景的全面回顾。对于理解 ML 工程中使用的某些库和概念的各种优点而言,这是一份极好的报告。此外,还提供了有关基于 Python 的机器学习库的未来的信息。
本文参考资料
[1] 图灵自然语言生成(T-NLG): https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
[2] NVIDIA Megatron-LM: https://github.com/NVIDIA/Megatron-LM
[3] Linguistically Informed Neural Dependency Parsing for Typologically Diverse Languages: http://uu.diva-portal.org/smash/record.jsf?pid=diva2:1357373&dswid=7905
[4] 依赖关系解析: http://nlpprogress.com/english/dependency_parsing.html
[5] Rapid Adaptation of BERT for Information Extraction on Domain-Specific Business Documents: https://arxiv.org/abs/2002.01861
[6] question understanding benchmark: https://arxiv.org/abs/2001.11770v1
[7] 有趣的工作: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
[8] 完整论文: https://arxiv.org/pdf/2002.00937.pdf
[9] REALM: Retrieval-Augmented Language Model Pre-Training: https://kentonl.com/pub/gltpc.2020.pdf
[10] change.org: https://www.change.org/p/organizers-of-data-science-and-machine-learning-conferences-neurips-icml-aistats-iclr-uai-allow-remote-paper-poster-presentations-at-conferences[11]新博客: https://yoshuabengio.org/2020/02/10/fusce-risus/
[12] 抽象推理语料库(ARC): https://www.kaggle.com/c/abstraction-and-reasoning-challenge/overview
[13] 机器学习和 NLP 领域 2019 年出版数据统计: https://www.marekrei.com/blog/ml-and-nlp-publications-in-2019/
[14] Growing Neural Cellular Automata: https://distill.pub/2020/growing-ca/[15]交互式 Transformer 注意可视化: https://github.com/SIDN-IAP/attnvis
[16] SketchTransfer: https://arxiv.org/pdf/1912.11570.pdf
[18] DeepSpeed 与 ZeRO: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
[19] PyTorch3D: https://ai.facebook.com/blog/-introducing-pytorch3d-an-open-source-library-for-3d-deep-learning/
[20] Hydra: https://hydra.cc/
[21] CausalNex: https://causalnex.readthedocs.io/en/latest/01_introduction/01_introduction.html
[22] TyDi QA: https://ai.googleblog.com/2020/02/tydi-qa-multilingual-question-answering.html
[23] 问答库: https://github.com/huggingface/node-question-answering
[25] 识别文本信息中的主观偏见: https://podcasts.apple.com/us/podcast/will-ai-help-identify-bias-or-perpetuate-it-with-diyi-yang/id1435564422?i=1000464141922
[26] DeepMind: https://deepmind.com/research/publications/Artificial-Intelligence-Values-and-Alignment[27]完整的报告: https://venturebeat.com/2020/01/30/google-researchers-release-audit-framework-to-close-ai-accountability-gap/
[28] 完整的论文: https://dl.acm.org/doi/abs/10.1145/3351095.3372873
[29] NLP Highlights: https://soundcloud.com/nlp-highlights/104-model-distillation-with-victor-sanh-and-thomas-wolf
[30] DistilBERT: https://arxiv.org/abs/1910.01108
[31] 诸如 BERT,ELMo 和 GPT-2 之类的上下文模型及其上下文化的词表示形式是什么: https://kawine.github.io/blog/nlp/2020/02/03/contextual.html
[32] Is the future of Neural Networks Sparse?: https://medium.com/huggingface/is-the-future-of-neural-networks-sparse-an-introduction-1-n-d03923ecbd70
[33] 从零开始训练语言模型: https://huggingface.co/blog/how-to-train
[34] Tokenizers: How machines read: https://blog.floydhub.com/tokenization-nlp/
[35] MLVU 机器学习课程: https://mlvu.github.io/
[36] Machine-Learning-Tokyo/Math_resources: https://github.com/Machine-Learning-Tokyo/Math_resources
[37] MIT 的“深度学习入门”课程: http://introtodeeplearning.com/
[38] PyTorch 深度学习: https://atcold.github.io/pytorch-Deep-Learning-Minicourse/
[39] “Missing Semester”: https://missing.csail.mit.edu/
[40] “Advanced Deep Learning”: https://andrejristeski.github.io/10707-S20/syllabus.html
[41] BERT-of-Theseus: http://xxx.itp.ac.cn/abs/2002.02925
[42] “机器学习入门”: https://compstat-lmu.github.io/lecture_i2ml/index.html
[43] 希腊语 BERT(GreekBERT): https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1
[44] Jeremy Howard: https://arxiv.org/abs/2002.04688
[45] TensorFlow: Data and Deployment Specialization: https://www.coursera.org/specializations/tensorflow-data-and-deployment
[46] Python 中的机器学习:数据科学,机器学习和人工智能的主要发展和技术趋势: https://arxiv.org/abs/2002.04803