

Atualizações da dair.ai
- Nós melhoramos a categorização de todos os TL;DR’s e resumos já incluídos no repositório do NLP Paper Summaries.
- Todos os issues e traduções da Newsletter passaram a ser mantidos aqui.
- Também foram introduzidos nessas semanas os Notebooks, focando no compartilhamento de notebooks de Ciência de Dados com a comunidade. Se você tem algum que gostaria de compartilhar, entre em contato conosco!
- Nós disponibilizamos um tutorial que demonstra como realizar uma classificação de emoções utilizando a TextVectorization — uma funcionalidade experimental do TensorFlow 2.1 que auxilia no tratamento de texto em redes neurais.
Pesquisas e Publicações 📙
Surveys on Contextual Embeddings
Esse artigo fornece um compilado de metodologias para o aprendizado de embeddings contextualizados. Também estão inclusas: revisão dos casos de uso da técnica para transfer learning; métodos de compressão de modelos e análises.
Outro trabalho traz uma coleção de métodos utilizados para a melhoria de modelos de linguagem baseados no Transformer.
E aqui está outra coletânea de modelos de linguagem pré-treinados, que propõe uma taxonomia para modelos dessa natureza em NLP.
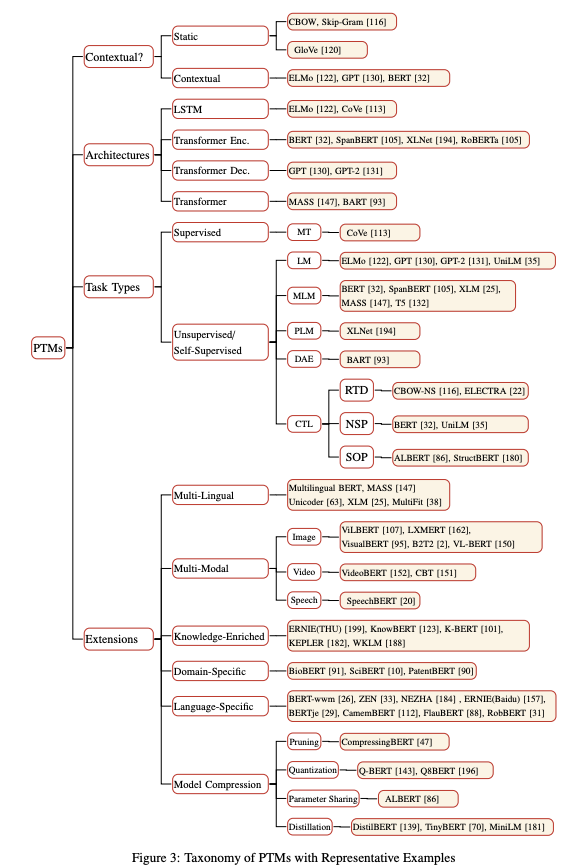
Visualizing Neural Networks with the Grand Tour
O Grand Tour é um método linear (em contraste com outras técnicas não-lineares, como o t-SNE) que realiza a projeção de bases de dados de dimensão alta para duas dimensões. Neste novo artigo do Distill, Li et al. (2020) propõem a utilização das habilidades do Grand Tour para visualizar o comportamento de uma rede neural durante o processo de treinamento. Comportamentos de interesse nas análises incluem as mudanças de pesos e como essas afetam o processo de treinamento, comunicação entre camadas do modelo e o efeito de exemplos adversariais ao serem apresentados para a rede neural.
Fonte: Distill
Meta-Learning Initializations for Low-Resource Drug Discovery
Diversos trabalhos demonstram como o meta-learning pode viabilizar a adoção de técnicas de Deep Learning para melhorar benchmarks de few-shot learning. Essa ideia é particularmente útil quando nos deparamos com situações onde a quantidade de dados disponíveis é limitada, como no caso do desenvolvimento de novos medicamentos. Um artigo recente aplicou uma técnica de meta-learning denominada Model-Agnostic-Meta-Learning (MAML), e suas variantes, para predizer propriedades químicas em cenários de escassez de dados. Os resultados obtidos demonstraram que a abordagem utilizada tem um desempenho similar a outros métodos multi-tarefa pré-treinados.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Um trabalho bastante interessante envolvendo pesquisadores da UC Berkeley, Google Research e da UC San Diego desenvolveu um método (NeRF) para a criação de novas perspectivas em cenários complexos. Tomando um conjunto de imagens RGB como base de dados, o modelo utiliza coordenadas 5D (localização espacial e direção) para o treinamento de uma rede neural profunda totalmente conectada, otimizando uma continuous volumetric scene function, e retornando a densidade de volume e radiância para aquela localização. Os diversos valores de saída são combinados ao longo de um camera ray e renderizados como pixels. Essas saídas renderizadas são utilizadas para otimizar representações de cenas através da minimização do erro de renderização para todos os camera rays das imagens RGB. Comparada com outras abordagens para a tarefa, a NeRF é quantitativa e qualitativamente melhor, além de conseguir resolver algumas inconsistências das outras abordagens, como a ausência de pequenos detalhes e flickering indesejado.

Introducing Dreamer: Scalable Reinforcement Learning Using World Models
O Dreamer é um agente de Aprendizado por Reforço que busca resolver algumas limitações (como imediatismo e ineficiência computacional) observados em agentes baseados em modelos para resolver tarefas com alto nível de dificuldade. Esse agente, proposto por pesquisadores da DeepMind e da Google AI, é treinado para modelar o mundo no qual está inserido e desenvolver a habilidade de aprender comportamentos focados no longo prazo utilizando o backpropagation. Resultados estado-da-arte foram obtidos em 20 tarefas de controle, baseadas nas imagens de entrada fornecidas. Além disso, o modelo é eficiente e pode operar de forma paralela, tornando-o mais interessante do ponto de vista computacional. As três tarefas envolvidas no treinamento do agente, com objetivos distintos, são sintetizadas na Figura abaixo.
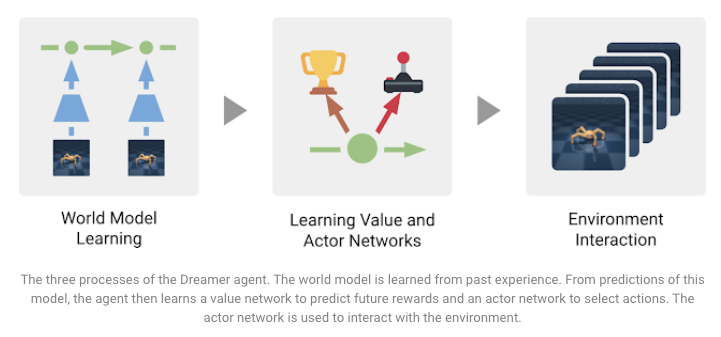
Fonte: Google AI Blog
Criatividade, Ética e Sociedade 🌎
COVID-19 Open Research Dataset (CORD-19)
Num esforço para encorajar a utilização da IA na luta contra a COVID-19, o Allen Institute of AI publicou o COVID-19 Open Research Dataset (CORD-19), um recurso publicamente disponível que busca promover colaboração global. A base de dados contém milhares de artigos que permitem a obtenção de insights, através do emprego de técnicas de NLP, que podem ajudar na luta contra o coronavírus.
SECNLP: A survey of embeddings in clinical natural language processing
O SECNLP é um trabalho que inclui uma revisão detalhada de uma ampla gama de técnicas de NLP aplicadas no contexto de saúde. O trabalho foca principalmente em métodos de embedding, problemas/desafios que essas representações buscam resolver, e uma discussão sobre possíveis direções de pesquisas.
AI for 3D Generative Design
Essa postagem apresenta uma abordagem utilizada para a geração de objetos 3D a partir de descrições em linguagem natural. A ideia é criar um solução que permita ao designer repetir o processo de criação de maneira mais ágil e explorar mais possibilidades. Após a criação de uma base de conhecimento do “espaço de design” composto de modelos 3D e descrições textuais, dois autoencoders (como exemplificado na Figura abaixo) são utilizados para codificar o conhecimento de maneira intuitiva. Com isso, o modelo é capaz de gerar um design 3D a partir de uma legenda, como você pode conferir nessa demonstração.
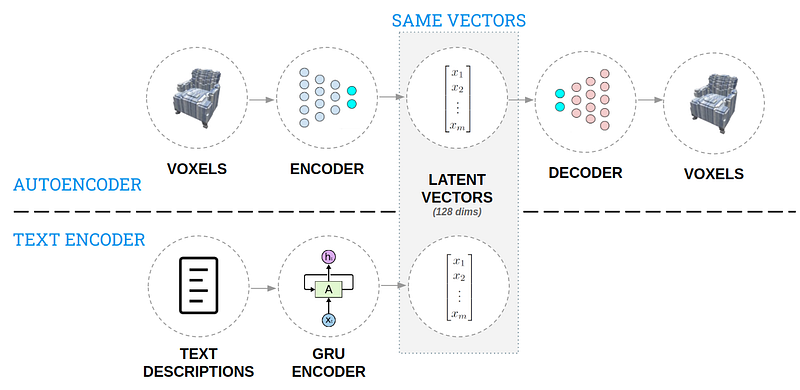
Ferramentas e Bases de Dados ⚙️
Stanza — A Python NLP Library for Many Human Languages
O grupo de NLP de Stanford disponibilizou a Stanza (denominada anteriormente como StanfordNLP), uma biblioteca em Python que oferece ferramentas de análise para mais de 70 idiomas. As funcionalidades incluem Tokenização, Multi-Word Token Expansion, Lematização, POS tagging, Reconhecimento de Entidades Nomeadas e muito mais. A biblioteca é baseada no PyTorch, com suporte a utilização em GPUs e modelos de redes neurais pré-treinadas. A Explosion já criou um wrapper para a Stanza, possibilitando sua utilização como um componente do Pipeline do spaCy.
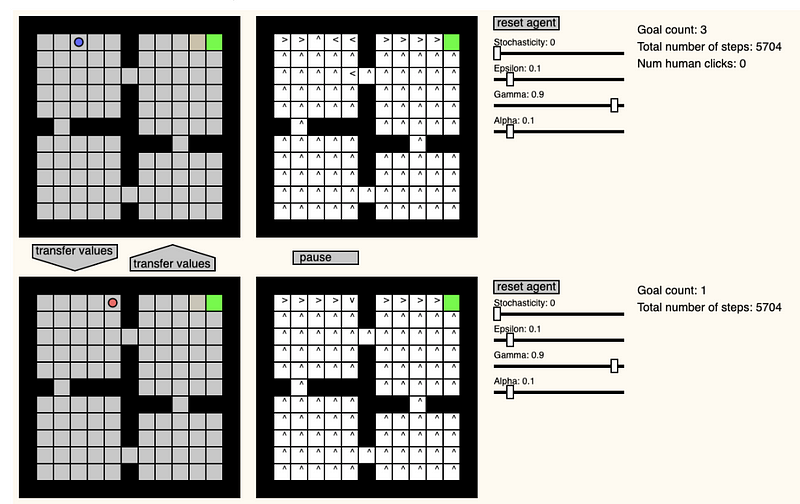
GridWorld Playground
Pablo Castro criou esse site interessante que implementa um playground para a criação de ambientes em grade, com o objetivo de observar e verificar como agentes de aprendizado por reforço tentam chegar ao objetivo, utilizando a técnica do Q-Learning. Dentre as funcionalidades, estão inclusas a habilidade de mudar os parâmetros do ambiente e de aprendizado em tempo real, mudar a posição dos agentes, e transferir value functions entre os dois.
X-Stance: A Multilingual Multi-Target Dataset for Stance Detection
A tarefa de Stance detection consiste na identificação do posicionamento de um sujeito frente a uma declaração de um ator, podendo ser utilizada na avaliação de notícias falsas. Jannis Vamvas e Rico Sennrich disponibilizaram recentemente uma base de dados de larga-escala composta por textos escritos por candidatos das eleições na Suíça. Múltiplos idiomas estão disponíveis na base, o que possibilita a avaliação da tarefa de detecção de posicionamento em contextos multilíngues. Os autores também propuseram a utilização de um modelo BERT multilíngue, que apresentou um desempenho satisfatório nos cenários zero-shot cross-lingual and cross-target transfer.
Create interactive textual heatmaps for Jupyter notebooks
Andreas Madsn criou uma biblioteca Python chamada TextualHeatMap, que pode ser utilizada para gerar visualizações que auxiliam no entendimento de quais partes de uma frase estão sendo utilizadas pelo modelo na hora de predizer a próxima palavra, como ocorre em modelos de linguagem.

Fonte: textualheatmap
Artigos e Postagens ✍️
How to generate text: using different decoding methods for language generation with Transformers
A Hugging Face publicou um artigo revisando diferentes técnicas utilizadas para a geração de texto, focando em abordagens baseadas no Transformer. São discutidos métodos como beam search e variações de processos de amostragem (“simples”, “Top-K” e “Top-p”). Já foram publicadas diversas outras postagens sobre esse mesmo assunto, porém nessa os autores dedicaram um bom tempo explicando os aspectos práticos das técnicas e como elas podem ser utilizadas na biblioteca Transformers.
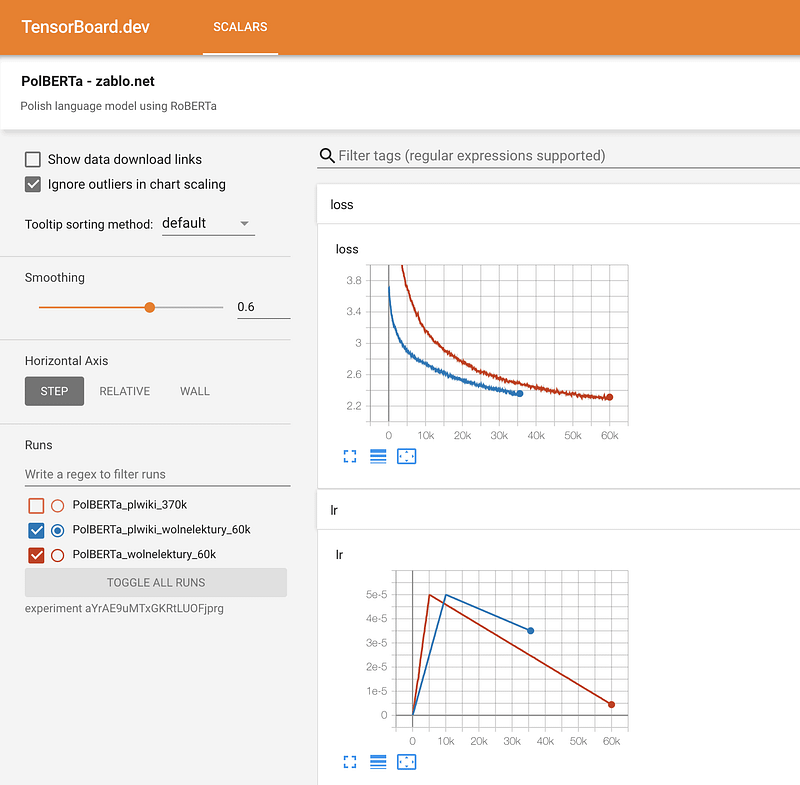
Training RoBERTa from Scratch — The Missing Guide
Motivado pela falta de um guia acessível para o treinamento do zero (from scratch) de modelos de linguagem baseados no BERT utilizando a biblioteca Transformers da Hugging Face, Marcin Zablocki disponibilizou esse tutorial detalhado. O guia mostra como treinar um modelo de linguagem para o Polonês e traz várias dicas sobre como evitar erros comuns, preparação dos dados, configurações de pré-processamento, tokenização, treinamento, monitoramento do processo de treino e compartilhamento do modelo.
Educação 🎓
Getting started with JAX (MLPs, CNNs & RNNs)
Robert Lange publicou recentemente um tutorial ilustrando como treinar uma Gated Recurrent Unit (GRU) com a nova biblioteca da Google, a JAX. Na edição passada da Newsletter, nós abordamos alguns tópicos relacionados à biblioteca.
NLP for Developers: Word Embeddings
Rachael Tatman publicou o primeiro episódio da sua nova série, a NLP for Developers, que cobrirá as melhores práticas relacionadas à aplicação de diversos métodos de NLP. O primeiro vídeo apresenta uma introdução à word embeddings e como são utilizados, além de dicas para evitar erros comuns quando trabalhamos com esse tipo de representação.
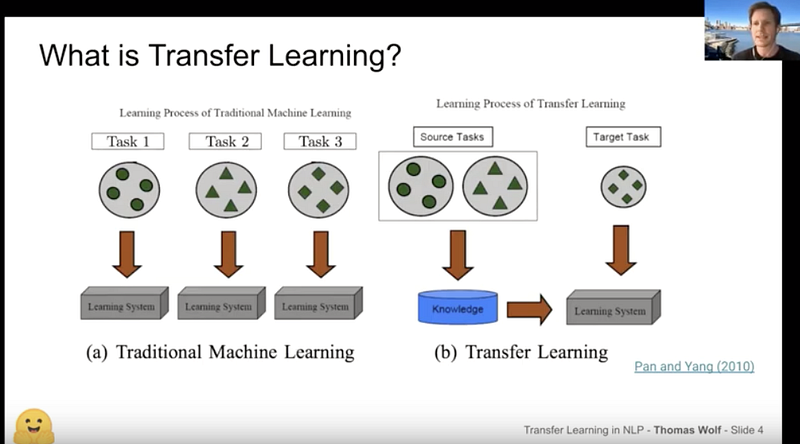
Thomas Wolf: An Introduction to Transfer Learning and HuggingFace
Thomas Wolf apresentou essa palestra sobre Transfer Learning no meetup NLP Zurich, fornecendo uma excelente introdução ao assunto para o contexto de NLP. A palestra apresenta uma visão geral dos momentos mais importantes para a área, além de uma introdução às bibliotecas Transformers e Tokenizers, dois dos módulos mais populares da Hugging Face.
Menções Honrosas ⭐️
Você sabia que o Google Sheets fornece uma ferramenta de tradução gratuita? Amit Chaudhary compartilhou uma postagem que mostra como utilizar essa funcionalidade para “tradução reversa”, fornecendo uma maneira de aumentar a sua base de dados em tarefas de NLP.
A New York NLP estará organizando um meetup online para uma palestra intitulada “Using Wikipedia and Wikidata for NLP” onde será discutido como se beneficiar dos dados dessas plataformas para diferentes projetos e casos de uso de NLP.
Lavanya Shukla escreveu esse tutorial sobre como utilizar a PyTorch Lightning para otimizar hiper-parâmetros de uma rede neural enquanto utilizamos funcionalidades de estrutura e estilo de código fornecidas pela biblioteca. O modelo resultante e seu desempenho utilizando diferentes combinações de hiper-parâmetros podem ser visualizados utilizando o logger WandB, que pode ser passado como parâmetro para o objeto responsável pelo treinamento do modelo.
Um grupo de pesquisadores publicou um estudo investigando de maneira mais aprofundada porquê a técnica de batch normalization (BN) tende a prejudicar a performance de modelos baseados no Transformer para diferentes tarefas de NLP. Com base nos comportamentos observados, os autores propuseram uma nova abordagem denominada power normalization. A técnica proposta apresenta um desempenho superior tanto ao BN quanto ao layer normalization, outra técnica amplamente utilizada atualmente.
Esse blog post apresenta uma extensa lista de livros para ajudar você a iniciar seus estudos e experiências com Aprendizado de Máquina.
Se você conhece bases de dados, projetos, postagens, tutoriais ou artigos que gostaria de ver na próxima edição da Newsletter, sinta-se a vontade para nos contactar através do e-mail ellfae@gmail.com ou de uma mensagem direta no twitter.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada!