

Seja muito bem-vindo à sexta edição da NLP Newsletter. Agradecemos por todo o suporte e dedicação à leitura dos temas mais recentes em ML e NLP. Essa edição cobre tópicos como extensões ao modelo Transformer, desaceleração no processo de publicação em Aprendizado de Máquina, divulgação de livros e projetos sobre ML e NLP e muito mais.
Algumas atualizaçãoes sobre a NLP Newsletter e o dair.ai
Nós estamos traduzindo a Newsletter para outros idiomas, como o Português Brasileiro, Chinês, Árabe, Espanhol, dentre outros. Agradecemos aos colegas que realizaram as traduções 🤗. Você também pode contribuir aqui!
No mês passado, nós realizamos o lançamento oficial do nosso novo website. Você pode dar uma olhada em nossa [organização no GitHub] (https://github.com/dair-ai) para mais informações sobre os projetos em andamento. Se você está interessado em saber mais sobre as contribuições já realizadas para a dar.ai, ou mesmo contribuir para a democratização das tecnologias, ensino e pesquisa sobre Inteligência Artificial, veja nossa seção de issues.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada!
Publicações 📙
A Primer in BERTology: What we know about how BERT works
Modelos baseados no Transformer mostraram-se bastante efetivos na abordagem das mais diversas tarefas de Processamento de Linguagem Natural, como sequence labeling e question answering. Um desses modelos, o BERT (Devlin et al. 2019), vem sendo amplamente utilizado. Entretanto, assim como acontece com outros modelos que utilizam redes neurais profundas, ainda sabemos muito pouco sobre seu funcionamento interno. Um novo artigo entitulado “A Primer in BERTology: What we know about how BERT works” busca começar a responder questões sobre as razões que possibilitam o BERT funcionar tão bem em tantas tarefas de NLP. Alguns dos tópicos investigados no trabalho incluem o tipo de conhecimento aprendido pelo modelo e como o mesmo é representado, além de métodos que outros pesquisadores estão utilizando para melhorar o processo de aprendizado.
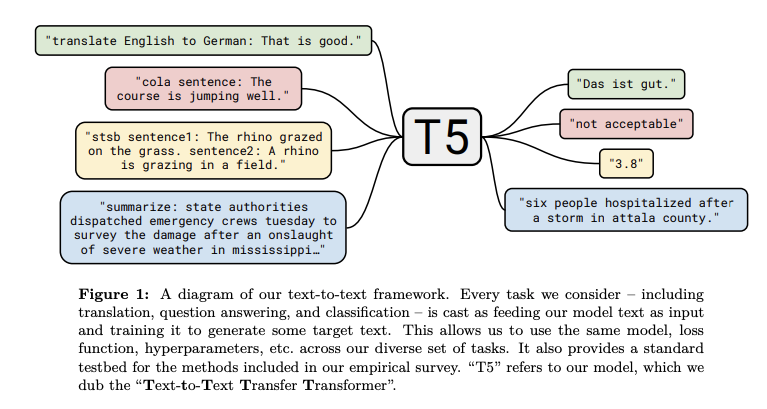
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
A Google AI publicou recentemente um método que incorpora todas as lições aprendidas e melhorias do Transfer Learning para NLP num franework unificado, denominado Text-to-Text Transfer Transformer (T5). O trabalho propõe que a maioria das tarefas de NLP podem ser formuladas no formato text-to-text, onde tanto a entrada quanto a saída do problema apresentam-se na forma de texto. Os autores alegam que “esse framework fornece uma função objetivo para treinamento que é consistente tanto na fase de pré-treinamento quanto no fine-tuning”. O T5 é essencialmente um encoder-decoder baseado no Transformer, com várias melhorias, em especial nos componentes de atenção da arquitetura. O modelo foi pré-treinado sobre uma nova base de dados disponibilizada recentemente, conhecida como Colossal Clean Crawled Corpus, onde foi estabelecido um novo estado-da-arte para tarefas como sumarização, question answering e classificação de texto.
12-in-1: Multi-Task Vision and Language Representation Learning
Os esforços de pesquisa atuais utilizam tarefas e bases de dados independentes para realizar avanços na área de linguística e visão computacional, mesmo quando os conhecimentos necessários para abordar essas tarefas possuem interseção. Um novo artigo (que será apresentado na CVPR) propõe uma abordagem multi-tarefa em larga escala para uma melhor modelagem e treinamento conjunto em tarefas de linguística e visão computacional, gerando uma modelo mais genérico para as mesmas. O método reduz a quantidade de parâmetros e apresenta um bom desempenho em problemas como recuperação de imagens baseadas em legendas, e question answering visual.

BERT Can See Out of the Box: On the Cross-modal Transferability of Text Representations
Pesquisadores e colaboradores da reciTAL publicaram um trabalho que busca responder se um modelo BERT é capaz de gerar representações que generalizam para outras áreas, além de texto e visão computacional. Os autores apresentam um modelo denominado BERT-gen, que tira proveito de representações mono e multi-modais para obter desempenhos superiores em bases de dados de gerações de perguntas baseadas em imagens.

Criatividade e Sociedade 🎨
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
Gary Marcus publicou recentemente um trabalho onde ele explica a série de passos que, na opinião dele, devem ser seguidos para o desenvolvimento de sistemas de IA mais robustos. A ideia central do artigo é priorizar a construção de sistemas híbridos e orientados à conhecimento, guiados por modelos cognitivos, ao invés da proposição de modelos com mais parâmetros que exigem mais dados e poder computacional.
10 Breakthrough Technologies 2020
A revista MIT Technology Review publicou a lista dos 10 avanços tecnológicos que segundo eles farão a diferença na resolução de problemas que podem mudar a maneira como vivemos e trabalhamos. A lista — sem ordem específica — inclui a internet não-hackável, medicina hiper-personalizada, moedas digitais, medicamentos anti-idade, moléculas descobertas por sistemas de IA, mega-constelações de satélites artificias, supremacia quântica, IA em aparelhos celulares, privacidade diferencial e climate attribution.
Time to rethink the publication process in machine learning
Yoshua Bengio escreveu recentemente sobre suas preocupações em relação aos atuais ciclos acelerados de publicações em Aprendizado de Máquina. O ponto principal é que, por causa da velocidade dessas, diversos trabalhos publicados apresentam erros e são apenas incrementais, deixando o investimento de tempo na revisão e verificação do rigor empregado na metodologia e experimentos de lado. Diante de tudo isso, os estudantes são aqueles que precisam lidar com as consequências negativas da pressão e estresse gerados por essa situação. Com o objetivo de solucionar esse problema, Bengio compartilha suas ações para ajudar no processo de desaceleração das publicações para o bem da ciência.
Ferramentas e Bases de Dados ⚙️
Implementação da PointerGenerator network com a AllenNLP
Redes Pointer-Generator buscam aprimorar o mecanismo de atenção de modelos sequence-to-sequence e são utilizadas para melhorar o desempenho em tarefas como sumarização abstrata. Se você gostaria de utilizando essa técnica com a framework AllenNLP, saiba que o Kundan Krishna desenvolveu um módulo que permite a execução de um modelo pré-treinado dessa categoria, além do treinamento de um novo modelo do zero.
Question answering para diferentes idiomas
Com a disseminação de modelos baseados no Transformer e sua efetividade em tarefas de NLP aplicadas a outros idiomas, existe um esforço significativo na construção e liberação de diferentes bases de dados em diferentes dialetos. Por exemplo, o Sebastian Ruder compartilhou uma lista de datasets que podem ser utilizados no desenvolvimento de métodos para question answering em diversas línguas: DuReader](https://www.aclweb.org/anthology/W18-2605/), KorQuAD, SberQuAD, FQuAD, Arabic-SQuAD, SQuAD-it e Spanish SQuAD.
PyTorch Lightning
A PyTorch Lightning é uma ferramenta que possibilita a abstração da escolha do dispositivo utilizado durante o treinamento de redes neurais (CPU ou GPU), além do uso de precisão de 16 bits. Fazer essas configurações funcionarem pode ser um trabalho entediante, mas felizmente os colaboradores da PyTorch Lightning simplificaram esse processo, permitindo o treinamento de modelos em várias GPUs/TPUs sem a necessidade de alteração do código.
Graph Neural Networks no TF2
O time de pesquisa da Microsoft liberou uma biblioteca com a implementação de diversas arquiteturas de Graph Neural Networks (GNNs). A biblioteca, baseada na versão 2.0 do TensorFlow, fornece funcionalidades para manipulação de dados que podem ser utilizadas diretamente nas iterações de treino/avaliação.
Pre-training SmallBERTa — A tiny model to train on a tiny dataset
Você já pensou em treinar o seu próprio modelo de linguagem do zero, mas nunca teve o poder computacional necessário para isso? Se já, então o Aditya Malte pode lhe ajudar com esse excelente notebook no Colab que exemplifica o processo de treinamento de um modelo de linguagem numa base de dados reduzida.
Ética em IA 🚨
Why faces don’t always tell the truth about feelings
Há algum tempo, diversos pesquisadores e empresas tentam construir modelos de IA que consigam entender e reconhecer emoções em contextos visuais ou textuais. Um novo artigo reabre o debate que técnicas de IA que tentam reconhecer emoções diretamente de imagens faciais não estão fazendo seu trabalho direito. O argumento principal, formulado por psicólogos proeminentes na área, é que não existe evidência da existência de expressões universais que possam ser utilizadas na detecção de emoções de maneira independente. Seria necessária uma melhor compreensão de traços de personalidade e movimentos corporais por parte do modelo, dentre outras características, para que seja possível detectar as emoções humanas de maneira mais precisa.
Differential Privacy and Federated Learning Explicadas
Uma das considerações éticas que devem ser levadas em consideração durante a construção de sistemas de IA é a garantia de privacidade. Atualmente, essa garantia pode ser obtida de duas maneiras: através da differential privacy ou do federated learning. Se você quiser saber mais sobre esses dois tópicos, Jordan Harrod produziu uma excelente introdução nesse vídeo, que inclui uma sessão hands-on utilizando notebooks do Colab.
Artigos e Postagens ✍️
A Deep Dive into the Reformer
Madison May realizou uma postagem em seu blog que fornece uma análise mais profunda do Reformer, um novo modelo baseado no Transformer, proposto recentemente pela Google AI. O Reformer já havia aparecido numa edição anterior da Newsletter.
Uma plataforma de blogs gratuita
A fastpages permite a criação e configuração automática de um blog utilizando a GitHub pages de maneira gratuita. Essa solução simplifica o processo de publicação e também oferece suporte à utilização de documentos exportados e Jupyter notebooks.
Dicas para entrevistas na Google
Pablo Castro, do time da Google Brain, publicou uma excelente postagem destacando as principais dicas para aqueles interessados em aplicar para uma posição na Google. Os tópicos abordados incluem dicas sobre o processo de entrevistas, como preparação, o que esperar durante e o que acontece depois delas.
Transformers are Graph Neural Networks
Graph Neural Networks (GNNs) e Transformers mostraram-se bastante efetivos em diversas tarefas de NLP. Com o objetivo de compreender melhor o funcionamento interno dessas arquiteturas e como elas se relacionam, Chaitanya Joshi escreveu um excelente artigo em seu blog, evidenciando a conexão entre GNNs e Transformers, e as diversas maneiras pelas quais esses métodos podem ser combinados e utilizados em conjunto.
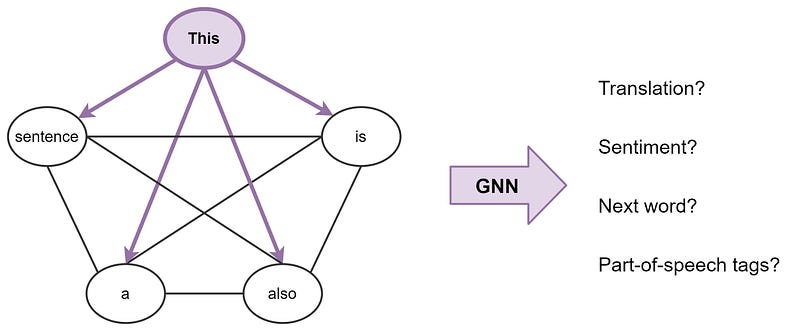
Representação de uma frase como um grafo completo de palavras — fonte
CNNs e Equivariância
Fabian Fuchs e Ed Wagstaff discutiram a importância da equivariância e como as Convolutional Neural Networks (CNNs) garantem essa propriedade. O conceito é apresentado e discutido posteriormente no contexto de CNNs em relação à translação.
Self-supervised learning com imagens
A técnica de self-supervised learning foi amplamente discutida nas edições anteriores da Newsletter devido ao seu papel em modelos recentes para language modeling. Esse blog post, feito pelo Jonathan Whitaker, fornece uma explicação intuitiva da técnica de aprendizado no contexto de imagens. Se você deseja um conhecimento mais profundo sobre o assunto, o Amit Chaudhary também publicou um artigo interessante descrevendo o conceito de maneira visual.
Educação 🎓
Stanford CS330: Deep Multi-Task and Meta-Learning
A universidade de Stanford liberou recentemente suas vídeo-aulas, numa playlist no YouTube, para o novo curso em deep multi-task e meta-learning. Os assuntos apresentados incluem bayesian meta-learning, lifelong learning, uma visão geral sobre aprendizado por reforço, model-based reinforcement learning, entre outros.
PyTorch Notebooks
A dar.ai liberou recentemente um compilado de notebooks apresentando uma introdução à redes neurais profundas utilizando o PyTorch. O trabalho continua em desenvolvimento, e alguns dos tópicos já disponíveis incluem como implementar um modelo de regressão logística do zero, assim como a programação de redes neurais feed-forward e recorrentes. Notebooks no Colab estão disponíveis no GitHub.
The fastai book (draft)
Jeremy Howard e Sylvain Gugger liberaram uma lista com alguns notebooks para um futuro curso que introduz conceitos de Deep Learning e como implementar diferentes métodos utilizando o PyTorch e a biblioteca da fastai.
Cursos gratuitos de Ciência de Dados
O Kaggle disponibilizou uma série de [mini-cursos gratuitos]https://www.kaggle.com/learn/overview) para o pontapé inicial da sua carreira como Cientista de Dados. Os cursos abordam assuntos como Explicabilidade em ML, Introdução ao Aprendizado de Máquina e ao Python, Visualização de Dados, Feature Engineering, Deep Learning, entre outros.
Um outro excelente curso online de Ciência de Dados disponibiliza notas de aulas, slides e notebooks sobre tópicos que vão desde análise exploratória até interpretação de modelos para Processamento de Linguagem Natural.
8 Criadores e Colaboradores discutem suas bibliotecas de treinamento de modelos no ecossistema do PyTorch
A nepture.ai publicou um excelente artigo que contém discussões detalhadas com criadores e colaboradores sobre suas jornadas e a filosofia utilizada na criação do PyTorch e nas ferramentas construídas com base na biblioteca.
Visualizando Adaptive Sparse Attention Models
Sashs Rush compartilhou um notebook impressionante que explica e mostra os detalhes técnicos sobre como produzir saídas esparsas com a softmax e induzir esparsidade nos componentes de atenção do modelo Transformer, auxiliando na atribuição de probabilidade zero para palavras irrelevantes num dado contexto, melhorando simultaneamente o desempenho e a interpretabilidade.
Visualizando a distribuição de probabilidade da saída da softmax
Menções Honrosas ⭐️
Você pode conferir a edição da passada da 🗞 Newsletter aqui.
Conor Bell escreveu esse script em Python que permite a visualização e preparação de uma base de dados que pode ser utilizada no modelo StyleGAN.
Manu Romero compartilhou um modelo de POS tagging para o espanhol. O modelo está disponível para uso utilizando a biblioteca Transformers da Hugging Face. Será interessante acompanhar a divulgação de modelos para outros idiomas.
Esse repositório contém uma extensa lista de artigos, cuidadosamente selecionados, que possuem relação com o BERT e abordam diversos problemas como compressão de modelos, tarefas de domínios específicos, entre outros.
Connor Shorten publicou um vídeo de 15 minutos explicando um novo framework que busca reduzir o efeito das “shortcut” features no self-supervised representation learning. Essa é uma tarefa importante porquê, caso não seja realizada corretamente, o modelo pode falhar em aprender representações semânticas úteis e potencialmente se tornar ineficiente durante o transfer learning.
Sebastian Ruder publicou uma nova edição da newsletter NLP News, que apresenta tópicos e recursos como análises de artigos de ML e NLP em 2019, e apresentações sobre os fundamentos do Deep Learning e Transfer Learning. Confira aqui.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada!