

Seja muito bem-vindo a sétima edição da NLP Newsletter. Esperamos que você tenha um dia incrível e que você as pessoas que você ama estejam em segurança nessas semanas difíceis. Nós decidimos publicar essa edição na esperança de trazer mais alegria aos nossos leitores. Sendo assim, por favor leia a Newsletter durante o seu tempo livre. Nesse momento, é importante mantermos o foco no que é a verdadeira prioridade - nossa família e amigos. ❤️ 💛 💚
Algumas atualizações sobre a NLP Newsletter e a dar.ai
Todas as traduções em francês e em chinês das edições anteriores estão agora disponíveis. Descubra como você pode contribuir com a tradução das edições anteriores (assim como as futuras!) da Newsletter nesse link.
Nota do tradutor**: As traduções de todas as edições da Newsletter, exceto a 3ª, para português também estão disponíveis!
Nós criamos recentemente dois repositórios no Github que contêm resumos de artigos de NLP e notebooks utilizando PyTorch para que você possa começar a ter experiência com redes neurais.
Pesquisas e Publicações 📙
Measuring Compositional Generalization
No contexto de Aprendizado de Máquina, compositional generalization se refere a habilidade de representar o conhecimento aprendido com a base de dados e aplicá-lo a novos e diferentes contextos. Até o presente momento, não estava claro como medir essa composicionalidade nas redes neurais. Recentemente, o time de IA da Google apresentou um dos maiores benchmarks para compositional generalization, utilizando tarefas como question answering e semantic parsing. A imagem abaixo apresenta um exemplo do modelo proposto utilizando os chamados átomos (unidades utilizadas para se gerar os exemplos) para que sejam produzidos compostos (novas combinações dos átomos). A ideia deste trabalho é construir bases de treino e teste que combinam exemplos que possuem a mesma distribuição pelos diferentes átomos mas com distribuições diferentes sobre os compostos. Os autores argumentam que essa é uma maneira mais confiável de se testar a compositional generalization.
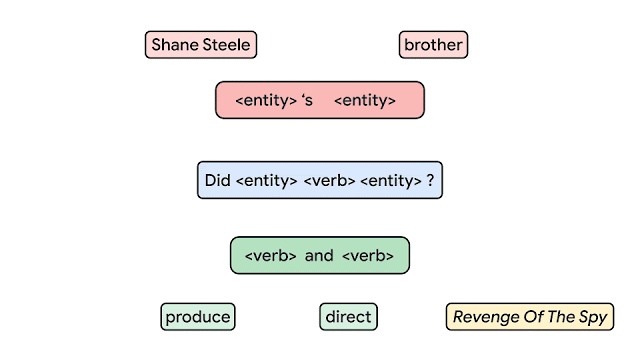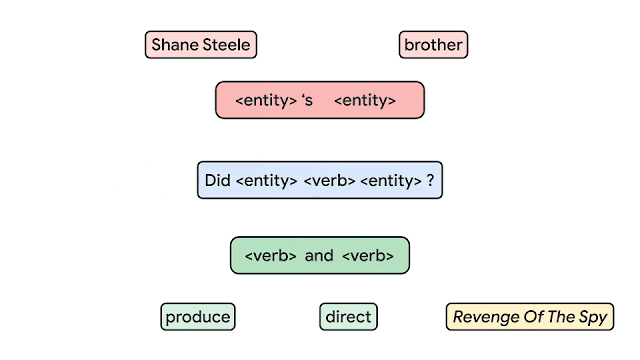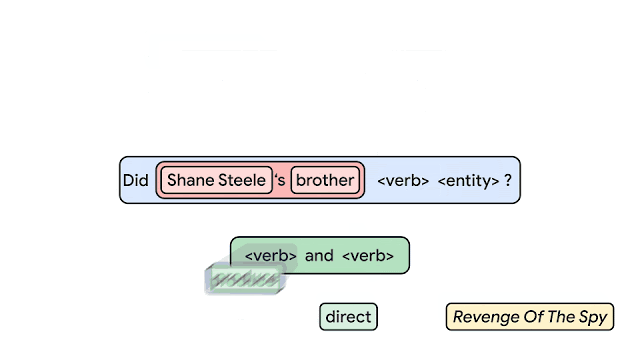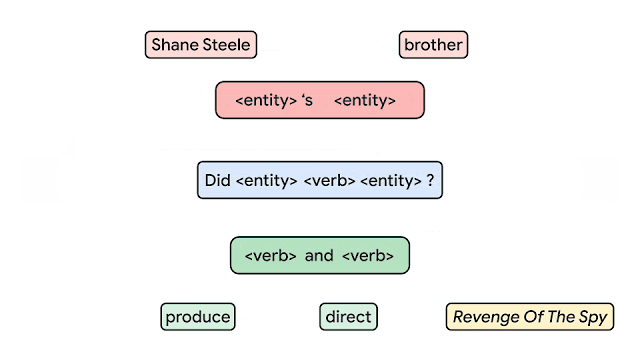
Crédito: Google AI Blog
Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping
Pesquisadores testaram uma série de procedimentos de refinamento (fine-tuning) com o objetivo de compreender melhor o efeito das diferentes estratégias de inicialização de pesos e políticas de early stopping no desempenho de modelos de linguagem. Através de exaustivos experimentos de refinamento do BERT, foi constatado que seeds aleatórias distintas produzem resultados bastante discrepantes. Em particular, o estudo reporta que certas inicializações de pesos de fato conferem ao modelo um bom desempenho em diversas tarefas. Todas as bases e testes realizados foram disponibilizadas, para uso de outros pesquisadores interessados em entender as dinâmicas que ocorrem durante o fine-tuning de maneira mais aprofundada.
Zoom In: An Introduction to Circuits
Pesquisadores da OpenAI publicaram uma postagem discutindo o estado atual da tarefa de interpretabilidade de redes neurais, assim como uma nova abordagem para a interpretação das mesmas. Inspirada pela biologia celular, os autores buscaram entender modelos de visão computacional e o que eles aprendem de maneira bastante aprofundada, através da inspeção dos pesos do modelo. Basicamente, o estudo apresentou algumas conclusões, obtidas a partir dos experimentos realizados, as quais eles acreditam que possam ser utilizadas como base para uma melhor interpretação das redes neurais.

NLP Research Highlights — Issue #1
Numa nova iniciativa da dar.ai, a NLP Research Highlights, são fornecidas descrições detalhadas de tópicos atuais e bem importantes da pesquisa em NLP. A ideia é que essa iniciativa seja utilizada para acompanhar os avanços da área através de resumos acessíveis desses trabalhos. Na primeira edição trimestral, os tópicos abordados tratam sobre melhorias em modelos de linguagem e em agentes conversacionais para sistemas de reconhecimento de voz. Os resumos são mantidos aqui.
Learning to Simulate Complex Physics with Graph Networks
Nos últimos meses, as Graph Neural Networks (GNNs) (redes neurais que operam sobre redes) foram um assunto recorrente nas edições da Newsletter, devido a sua efetividade em tarefas não só da área de NLP como também em genômica e materiais. Um artigo publicado recentemente, propõe um framework geral baseado em GNNs que é capaz de realizar simulações físicas em diferentes cenários, como fluidos e materiais maleáveis. Os autores argumentam que eles obtiveram um desempenho estado-da-arte nesses diferentes contextos e que a abordagem proposta é possivelmente o melhor simulador treinado da atualmente. Os experimentos realizados incluem a simulação de materiais como fluidos viscosos sobre a água e outras interações com objetos rígidos. Também foi testado um modelo pré-treinado em tarefas out-of-distribution e os resultados obtidos foram bastante promissores, evidenciando o potencial de generalização para outros cenários.
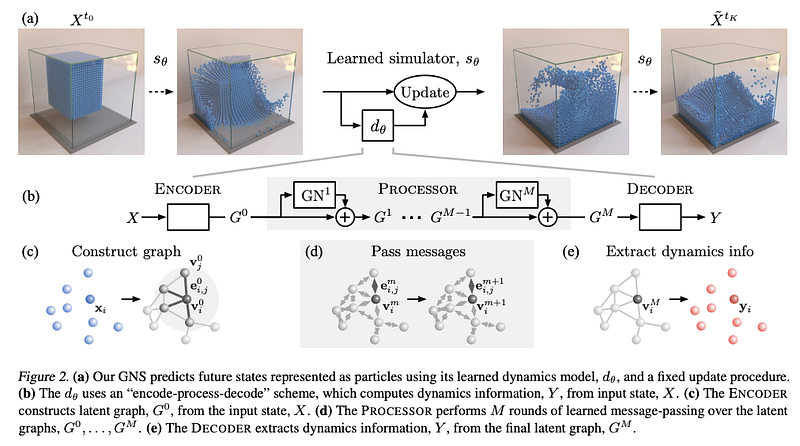
(Sanchez-Gonzalez et al., 2020)
Modelos BERT para idiomas específicos
O BERT Árabe (AraBERT) está agora disponível na biblioteca de Transformers da Hugging Face. Você pode acessar o modelo aqui e o artigo aqui.
Recentemente, uma versão em japonês do BERT também foi disponibilizada. Uma versão em polonês também está disponível, batizada como Polbert.
Criatividade, Ética e Sociedade 🌎
Computational predictions of protein structures associated with COVID-19
A DeepMind publicou suas predições de estruturas das proteínas que se ligam ao vírus causador da COVID-19. As predições foram obtidas diretamente do sistema AlphaFold, embora não tenham sido verificadas experimentalmente. A ideia é que essa publicações encorajem outras contribuições que busquem entender melhor e vírus e suas funções.
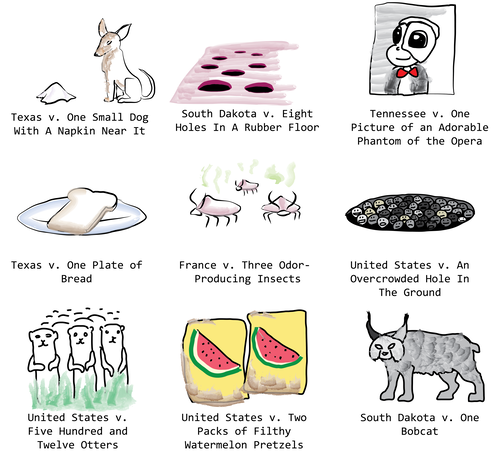
Court cases that sound like the weirdest fights
Janelle Shane compartilhou os resultados de um divertido experimento onde um modelo do GPT-2 foi refinado para gerar processos judiciais contra objetos inanimados. Foi disponibilizado ao modelo uma lista de processos do governo sobre apreensões de objetivos contrabandeados e artefatos perigosos, e foram geradas acusações como as apresentadas na imagem abaixo.
Toward Human-Centered Design for ML Frameworks
A Google AI publicou os resultados de uma grande pesquisa com 645 pessoas que utilizaram a versão do TensorFlow para JavaScript. O objetivo era entender quais eram as funcionalidades mais importantes da biblioteca para desenvolvedores fora da área de ML, assim como a sua experiência com as atuais bibliotecas de Aprendizado de Máquina. Uma das conclusões obtidas mostra que a falta de entendimento conceitual de ML dificulta a utilização de bibliotecas específicas para esse grupo de usuários. Os participantes do estudo também reportaram a necessidade de instruções mais acessíveis sobre como aplicar modelos de ML em diferentes problemas e um suporte mais explícito para modificações do usuário.
Face and hand tracking in the browser with MediaPipe and TensorFlow.js
Este excelente artigo do TensorFlow apresenta um passo-a-passo para habilitar um sistema de tracking do rosto e das mãos diretamente no navegador utilizando o TensorFlow.js e o MediaPipe.

Créditos: Blog do TensorFlow
Ferramentas e Bases de Dados ⚙️
NLP Paper Summaries
Nós criamos recentemente um repositório contendo uma lista de resumos de artigos de NLP cuidadosamente formulados, para alguns dos mais interessantes e importantes papers da área nos últimos anos. O foco principal da iniciativa é expandir a acessibilidade do público-geral à tópicos e pesquisas de NLP.
Uma biblioteca de visão computacional diferenciável em PyTorch
A Kornia é uma biblioteca construída sobre o PyTorch que permite a utilização de uma série de operadores para visão computacional diferenciável utilizando o PyTorch. Algumas das funcionalidades incluem transformações em images, depth estimation, processamento de imagens em baixo-nível, dentre várias outras. O módulo é fortemente inspirado no OpenCV, com a diferença de ser focado em pesquisa, ao invés de aplicações prontas para produção.

Introducing DIET: state-of-the-art architecture that outperforms fine-tuning BERT and is 6X faster to train
DIET (Dual Intent and Entity Transformer) é uma arquitetura multi-tarefa de natural language understanding (NLU) proposta pela Rasa. A framework foca no treinamento multi-tarefa, com o objetivo de melhorar o desempenho nos problemas de classificação de intenções e reconhecimento de entidades nomeadas. Outros benefícios do DIET incluem a flexibilidade de utilização de qualquer embedding pré-treinado, como o BERT e o GloVe. O foco principal, entretanto, é disponibilizar um modelo que ultrapassa o estado-da-arte atual nessas tarefas e que seja mais rápido de treinar (o speedup reportado foi de 6x!). O modelo está disponível na biblioteca rasa.
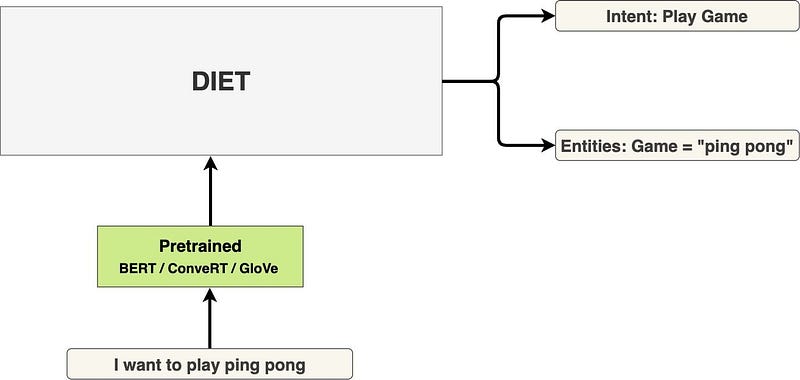
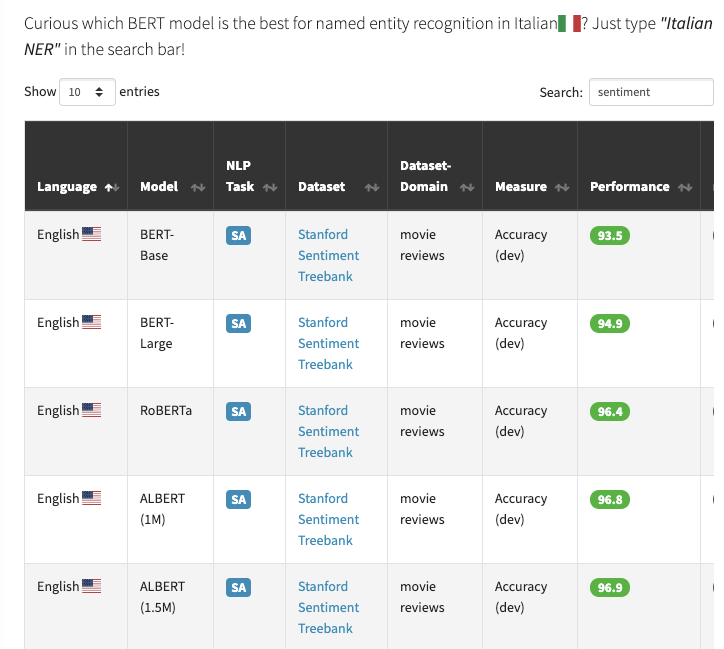
Perdido no meio dos modelos BERT?
O BERT Lang Street é uma plataforma que possui a capacidade de buscar por mais de 30 modelos baseados no BERT, em 18 idiomas e 28 tarefas, totalizando 177 entradas em sua base de dados. Dessa forma, se você quiser descobrir o estado-da-arte para a tarefa de classificação de sentimentos utilizando modelos BERT, basta procurar por “sentiment” na barra de busca (como exemplificado abaixo).
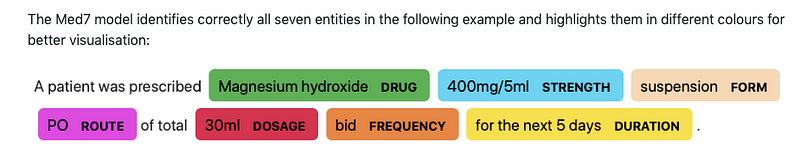
Med7
O Andrey Kormilitzin disponibilizou o Med7, que é um modelo para NLP (em particular Reconhecimento de Entidades Nomeadas (NER)) em relatórios médicos eletrônicos. O modelo é capaz de identificar até 7 categorias de entidades e está disponível para uso com a biblioteca spaCy.
Uma biblioteca em código-aberto para Quantum Machine Learning
TensorFlow Quantum é uma biblioteca que fornece uma série de funcionalidades para a prototipagem rápida de modelos quânticos de ML, possibilitando a aplicação destes em problemas em áreas como a medicina e materiais.
Fast and Easy Infinitely Wide Networks with Neural Tangents
A Neural Tangents é uma biblioteca que permite aos pesquisadores construir e treinar modelos de dimensão infinita e redes neurais utilizando a JAX. Leia a postagem de lançamento aqui e acesse a biblioteca aqui.
Artigos e Postagens ✍️
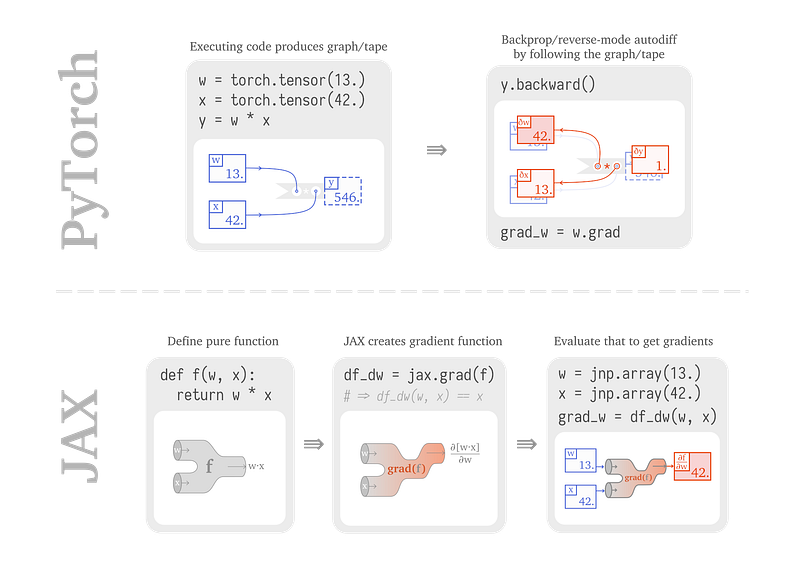
From PyTorch to JAX: towards neural net frameworks that purify stateful code
Sabrina J. Mielke publicou um artigo com um passo-a-passo que ilustra a construção e treinamento de redes neurais utilizado o JAX. A postagem busca comparar o funcionamento interno das redes com o PyTorch e o JAX, o que auxilia num melhor entendimento dos benefícios e diferenças entra as duas bibliotecas.
Why do we still use 18-year old BLEU?
Nesse blog post, Ehud Reiter discorre sobre porquê nós ainda utilizamos técnicas de avaliação antigas como BLUE para mensurar o desempenho de modelos de NLP em tarefas como tradução automática (machine translation). Como um pesquisador da área, ele conta sobre as implicações para técnicas que realizam a avaliação em tarefas de NLP mais recentes.
Introducing BART
O BART é um novo modelo proposto pelo Facebook que consiste num denoising autoencoder para o pré-treinamento de modelos sequence-to-sequence, que pode melhorar o desempenho dos mesmos em tarefas como sumarização abstrata. Sam Shleifer disponibilizou um resumo interessante do BART e como ele realizou a integração do modelo na biblioteca Transformers da Hugging Face.
A Survey of Long-Term Context in Transformers
Madison May escreveu recentemente um compilado bastante interessante descrevendo estratégias para melhorar abordagens baseadas em Transformers, que incluem Sparse Transformers, Adaptive Span Transformers, Transformer-XL, compressive Transformers, Reformer, e routing transformer. Alguns dos modelos já haviam aparecido em publicações da dar.ai e na lista de resumos de artigos.
“Mind your language, GPT-2”: how to control style and content in automatic text writing
Apesar da fluência impressionante na escrita automática de texto evidenciada no ano passado, continua sendo um desafio controlar atributos como estrutura ou conteúdo em textos gerados por modelos neurais. Numa postagem recente, Manuel Tonneau discute o progresso atual e as perspectivas na área de geração de texto parametrizável, como o modelo GPT-2 da Hugging Face refinado no arXiv e o T5 da Google, além do CTRL da Salesforce e do PPLM do time de IA da Uber.
Educação 🎓
Talk: The Future of NLP in Python
Em uma de nossas edições anteriores, foi apresentado o THiNC, uma biblioteca funcional de Deep Learning focada na compatibilidade com outras já existentes. Essa apresentação, utilizada pela Ines Montani na PyCon Colombia, introduz a biblioteca mais profundamente.
Transformers Notebooks
A Hugging Face publicou uma coleção de notebooks no Colab que auxilia no início da utilização de sua biblioteca Transformers. Alguns notebooks incluem o uso de tokenização, configuração de pipelines de NLP, e o treinamento de modelos de linguagem em bases de dados próprias.
TensorFlow 2.0 in 7 hours
Confira esse curso grátis de ~7 horas sobre o TensorFlow 2.0, onde são cobertos tópicos como o básico de redes neurais, NLP com redes neurais recorrentes (RNNs) e uma introdução ao Aprendizado por Reforço.
DeepMind: The Podcast
A DeepMind liberou todos os episódios (numa playlist no YouTube) do seu podcast com cientistas, pesquisadores e engenheiros, onde são discutidos tópicos como *Artificial General Intelligence, neurociência e robótica.
Cursos de Machine Learning and Deep Learning
A Berkeley está disponibilizando publicamente o plano de estudos do seu curso em “Deep Unsupervised Learning”, focado principalmente nos aspectos teóricos do self-supervised learning e em modelos generativos. Outros tópicos incluem modelos de variáveis latentes, modelos autorregressivos e flow models. As aulas e os slides também estão disponíveis.
Nós também encontramos essa lista impressionante de cursos avançados de ML, NLP e Deep Learning disponível de maneira online.
E aqui está um outro curso intitulado “Introduction to Machine Learning” que aborda assuntos como regressão supervisionada, avaliação de desempenho, random forests, ajuste de parâmetros, dicas práticas e muito mais.
Menções Honrosas ⭐️
A edição anterior da Newsletter (6ª edição) está disponível aqui.
Connon Shorten publicou um vídeo explicando o modelo ELECTRA, que propõe a utilização de uma técnica chamada replaced token detection como forma de pré-treinar Transformers de maneira mais eficiente. Se você tiver interesse em saber mais, nós também escrevemos um breve resumo do modelo aqui.
Rachael Tatman está trabalhando numa nova série denominada NLP for Developers onde o objetivo é discutir diferentes métodos de NLP de maneira mais aprofundada, quando utilizá-los e como lidar com dificuldades comuns apresentadas por essas técnicas.
A DeepMind liberou o AlphaGo — The Movie no YouTube para celebrar o 4º aniversário da vitória do modelo sobre o Lee Sedol no jogo de Go.
A OpenMined está com vagas abertas para os cargos de Research Engineer e Research Scientist, que parecem ser boas oportunidades para se envolver com privacy-preserving AI.
Se você conhecer bases de dados, projetos, postagens, tutoriais ou artigos que você gostaria de ver na próxima edição da Newsletter, sinta-se a vontade para nos contactar através do e-mail ellfae@gmail.com ou de uma mensagem direta no twitter.
Inscreva-se 🔖 para receber as próximas edições na sua caixa de entrada!