

Avant-propos d’Elvis
Bienvenue au 7e numéro de la lettre d’information consacrée au NLP. J’espère que vous passez une merveilleuse journée et que vous et vos proches êtes en sécurité en ces temps difficiles. Nous avons décidé de publier ce bulletin pour apporter un peu de joie à nos lecteurs, alors n’hésitez pas à le lire quand vous aurez du temps libre. Pour l’instant, concentrons-nous sur les choses qui sont de la plus haute priorité : nos familles et nos amis. ❤️ 💛 💚
Quelques mises à jour sur la lettre d’information sur le NLP et sur dair.ai.
Les traductions françaises et chinoises de tous les numéros précédents de la newsletter sont désormais disponibles. Découvrez comment vous pouvez contribuer à la traduction des numéros précédents et à venir en cliquant sur ce lien.
Nous avons récemment créé deux nouveaux dépôts GitHub qui contiennent des résumés de publications sur le NLP et des notebooks PyTorch pour vous aider à démarrer avec les réseaux de neurones.
Publications 📙
Mesure de la généralisation de la composition
Dans le contexte de l’apprentissage machine, la généralisation de la composition est la capacité d’apprendre à représenter le sens et des séquences (combinaisons inédites) à partir de ce qui est appris dans le jeu d’entraînement. À ce jour, la manière de mesurer correctement la composition dans les réseaux neuronaux n’est pas claire. Une équipe de Google AI propose l’un des plus grands benchmarks pour la généralisation de la composition en utilisant des tâches telles que le question/ answering et l’analyse sémantique. L’image ci-dessous montre un exemple du modèle proposé utilisant des atomes (produire, diriger, etc.) pour produire de nouveaux composés, c’est-à-dire des combinaisons d’atomes. L’idée de ce travail est de produire des échantillons entraînement/test qui contiennent des exemples qui partagent des atomes similaires (blocs de construction pour générer des exemples) de distribution mais une distribution de composés différente (la composition des atomes). Les auteurs affirment que c’est une façon plus fiable de tester la généralisation de la composition.
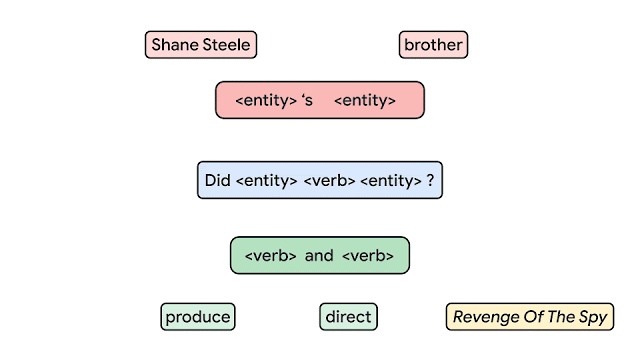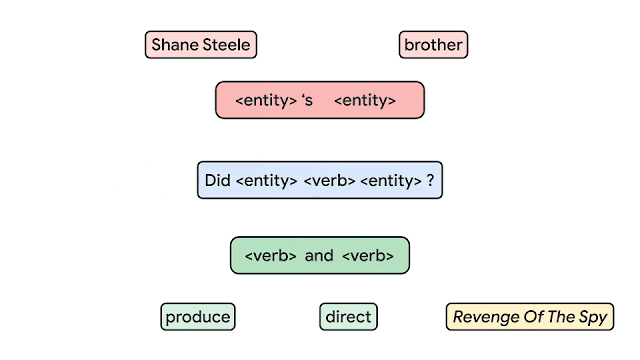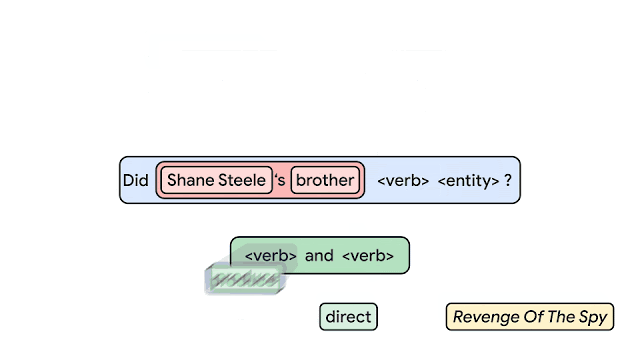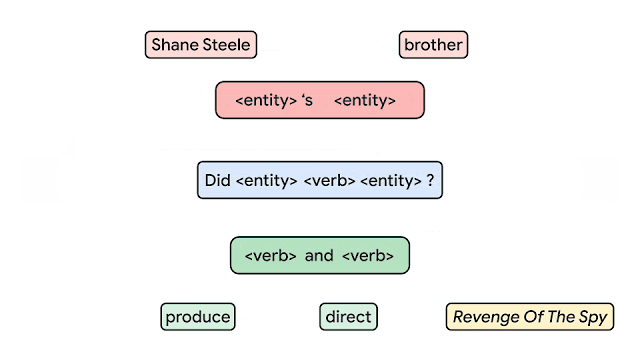
Credit: Google AI Blog
Fine-Tuning de modèles linguistiques pré-entraînés : Initialisation des poids, ordonnancement des données et arrêt anticipé
Des chercheurs ont mené une série d’essais de fine-tuning pour mieux comprendre l’effet de l’initialisation du poids et de l’arrêt précoce dans la performance des modèles. Au cours de diverses expériences qui ont nécessité des centaines de tunage de BERT, il a été constaté que des graines aléatoires distinctes donnent des résultats très différents. En particulier, l’étude indique qu’une certaine initialisation des poids donne de bons résultats pour un ensemble de tâches. Toutes les données expérimentales et les essais ont été rendus publics pour les autres chercheurs qui souhaitent mieux comprendre les différentes dynamiques lors de la mise au point.
Une introduction aux circuits
Les chercheurs d’OpenAI ont publié un article sur l’interprétabilité des réseaux de neurones et proposent une nouvelle approche pour les interpréter. Inspirés par la biologie cellulaire, les auteurs approfondissent la compréhension des modèles de vision et de ce qu’ils apprennent en inspectant le poids des réseaux neuronaux. Essentiellement, l’étude présente quelques affirmations ainsi que des preuves recueillies qui, selon eux, pourraient ouvrir la voie à une meilleure interprétation des réseaux neuronaux.

NLP Research Highlights — Issue #1
Dans une nouvelle série de dair.ai intitulée NLP Research Highlights, nous fournissons des descriptions détaillées des recherches actuelles intéressantes et importantes sur le NLP. Dans le premier numéro trimestriel, les sujets vont de l’amélioration des modèles de langage à l’amélioration des agents conversationnels en passant par les systèmes de reconnaissance vocale de pointe. Ces résumés seront également mis à jour ici.
Apprendre à simuler la physique complexe avec les réseaux de graphes
Ces derniers mois, nous avons beaucoup parlé des réseaux de neurones de graphes (GNN) en raison de leur efficacité non seulement en NLP mais aussi dans d’autres domaines tels que la génomique et les matériaux. Dans un récent article, des chercheurs proposent un cadre général basé sur les réseaux de graphes qui est capable d’apprendre des simulations dans différents domaines tels que les fluides et les matériaux déformables. Les auteurs affirment qu’ils obtiennent des performances de pointe dans différents domaines et que leur approche générale est potentiellement le simulateur de physique le mieux appris à ce jour. Les expériences comprennent la simulation de matériaux tels que le « goop over water » (je ne sais pas comment cela se traduit en français) et d’autres interactions avec des obstacles rigides. Ils ont également testé un modèle pré-entraîné sur des tâches hors distribution et ont trouvé des résultats prometteurs qui montrent la généralisation du framework à des domaines plus vastes.
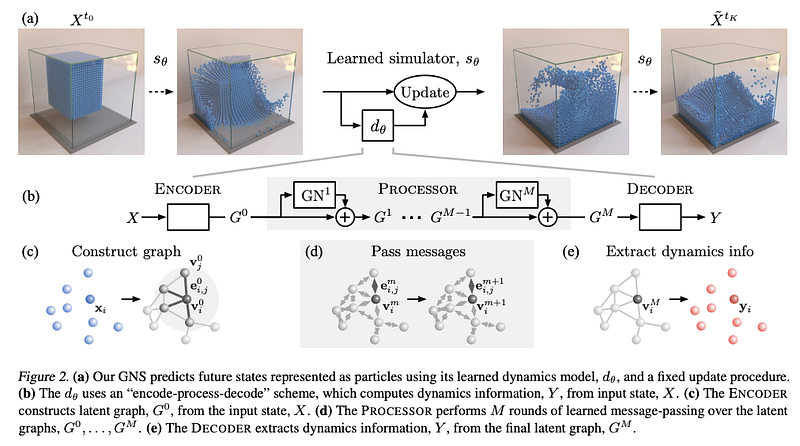
(Sanchez-Gonzalez et al., 2020)
Modèles BERT spécifiques à chaque langue
Le BERT en arabe (AraBERT) est maintenant disponible dans la librairie Transformer. Vous pouvez accéder au modèle ici et au document ici. Récemment, une version japonaise de BERT a également été publiée. Il existe également une version polonaise de BERT appelée Polbert.
Créativité, éthique et société 🌎
Prévisions des structures protéiques associées au COVID-19
DeepMind dévoile des structures prédites par calcul pour les protéines liées au COVID-19. Les prédictions sont directement obtenues à partir des systèmes AlphaFold mais n’ont pas été vérifiées expérimentalement. L’idée de cette publication est d’encourager les contributions qui visent à mieux comprendre le virus et son fonctionnement.
Utilisation du GPT2 pour une expérience sur des cas judiciaires
Janelle Shane partage les résultats d’une expérience amusante où un modèle GPT-2 est fine-tuné pour générer des cas contre des objets inanimés. Le modèle a été alimenté par une liste de cas où le gouvernement saisissait des marchandises de contrebande ou dangereuses. Cela a généré des cas comme ceux présentés dans l’image ci-dessous.
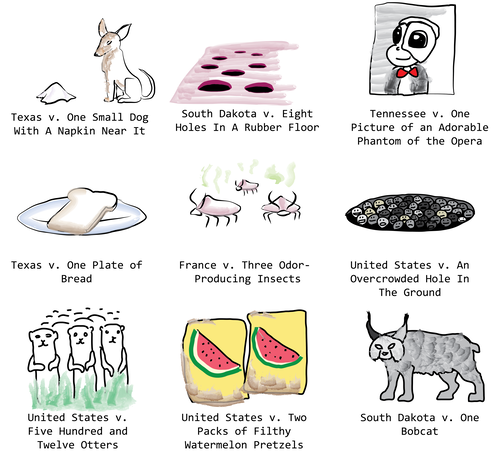
Vers une conception centrée sur l’homme des frameworks de ML
Google AI a publié les résultats d’une enquête à grande échelle menée auprès de 645 personnes ayant utilisé TensorFlow.js. L’objectif était de connaître les caractéristiques les plus importantes ainsi que l’expérience générale des développeurs de logiciels non ML testant des frameworks de ML actuels.
Les résultats montrent notamment que le “manque de compréhension conceptuelle du ML” entrave l’utilisation des frameworks de ML pour cet ensemble d’utilisateurs. Les participants à l’étude ont également signalé le besoin de meilleures instructions sur la façon d’appliquer les modèles de ML à différents problèmes et d’un soutien plus explicite pour les modifications.
Tracking du visage et de la main avec MediaPipe et TensorFlow.js
Cet article sur TensorFlow explique comment activer le suivi des visages et des mains en temps réel à l’aide de TensorFlow.js et de MediaPipe.

Credit: TensorFlow Blog
Outils et jeux de données ⚙️
NLP Paper Summaries
Nous avons récemment créé un dépôt contenant des résumés des publications de NLP les intéressantes et les plus importantes de ces dernières années. L’objectif est d’améliorer l’accessibilité de ces recherches et sujets.
Une librairie de vision par ordinateur pour PyTorch
Kornia est une librairie open-source construite sur PyTorch qui permet aux chercheurs d’utiliser un ensemble d’opérateurs pour réaliser une vision informatique différenciée en utilisant PyTorch. Parmi les fonctionnalités, on trouve les transformations d’images, l’estimation de la profondeur et le traitement d’images de bas niveau, pour n’en citer que quelques-unes. Elle est fortement inspirée d’OpenCV, mais la différence est qu’elle est destinée à la recherche plutôt qu’à la création d’applications prêtes à la production.

Présentation de DIET : une architecture qui surpasse le fine-tuning de BERT et qui est 6X plus rapide à entraîner
DIET (Dual Intent and Entity Transformer) est une architecture multitâche de compréhension du langage naturel (NLU) proposée par Rasa. Le framework se concentre sur l’entraînement multitâche afin d’améliorer les résultats en matière de classification des intentions et de reconnaissance des entités. Un autre avantage de DIET est que l’on peut utiliser n’importe quel élément pré entrainé tels que BERT et GloVe. L’objectif principale de cette librairie est de fournir un modèle qui améliore les performances actuelles de ces tâches et qui est plus rapide à entraîner (accélération de 6X). Le modèle est disponible dans la librairie python Rasa Open Source.
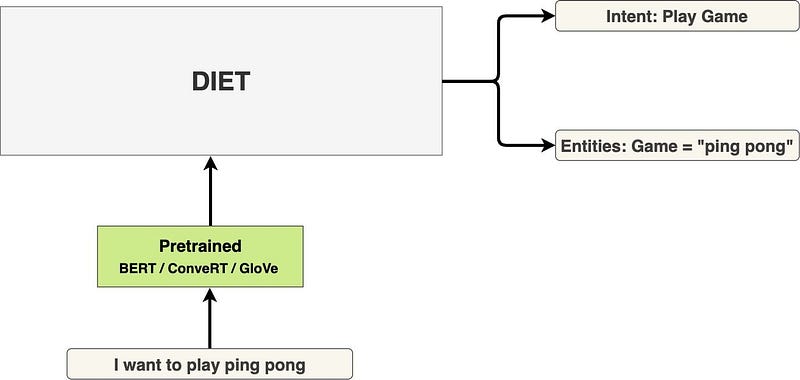
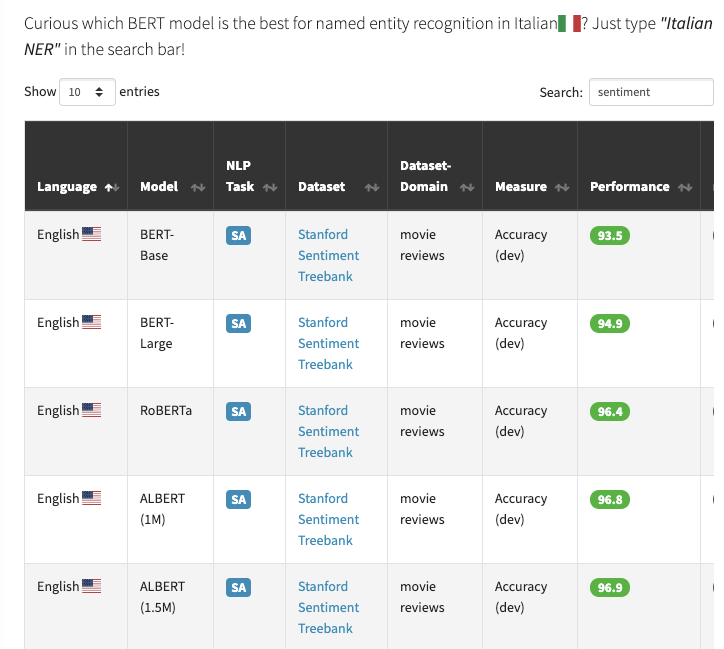
Perdu parmi toutes les langues disponibles pour BERT ?
BERT Lang Street est un site web qui offre la possibilité de rechercher plus de 30 modèles basés sur le BERT, en 18 langues et 28 tâches, soit un total de 177 entrées. Par exemple, si vous souhaitez connaître les résultats de la classification des sentiments à l’aide des modèles de BERT, il vous suffit de rechercher “sentiment” dans la barre de recherche (exemple illustré dans la capture d’écran ci-dessous).
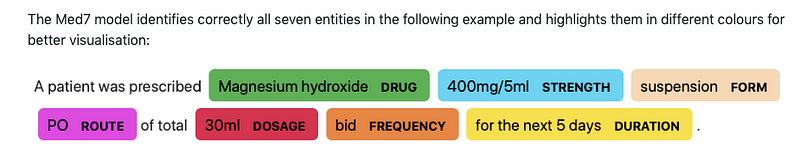
Med7
Andrey Kormilitzin publie Med7 qui est un modèle pour du NLP à usage clinique (en particulier les tâches de reconnaissance d’entités nommées (NER)) sur les dossiers médicaux électroniques. Le modèle peut identifier jusqu’à sept catégories et est disponible pour être utilisé avec la bibliothèque spaCy.
Une bibliothèque open source pour le ML quantique
TensorFlow Quantum est une bibliothèque open-source qui fournit une boîte à outils pour le prototypage rapide de la recherche en ML quantique qui permet l’application de modèles de ML pour aborder des problèmes allant de la médecine aux matériaux.
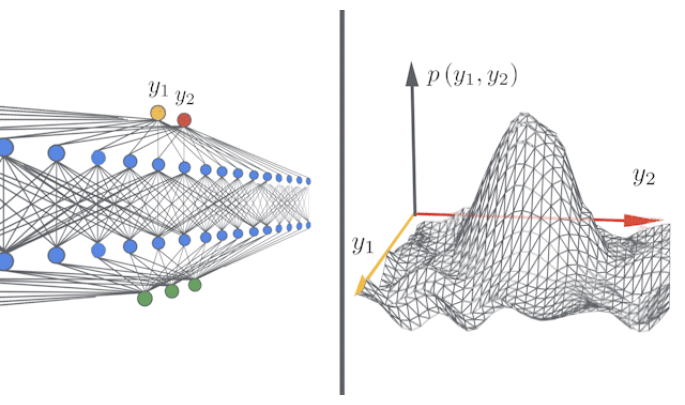
Des réseaux infiniment larges, rapides et faciles, avec Neural Tangents
Neural Tangents est une librairie open-source qui permet aux chercheurs de d’entraîner des modèles de largeur finie ou infinie en utilisant JAX. Lisez l’article du blog de la version ici et accédez à la librairie ici.
Articles et Blog ✍️
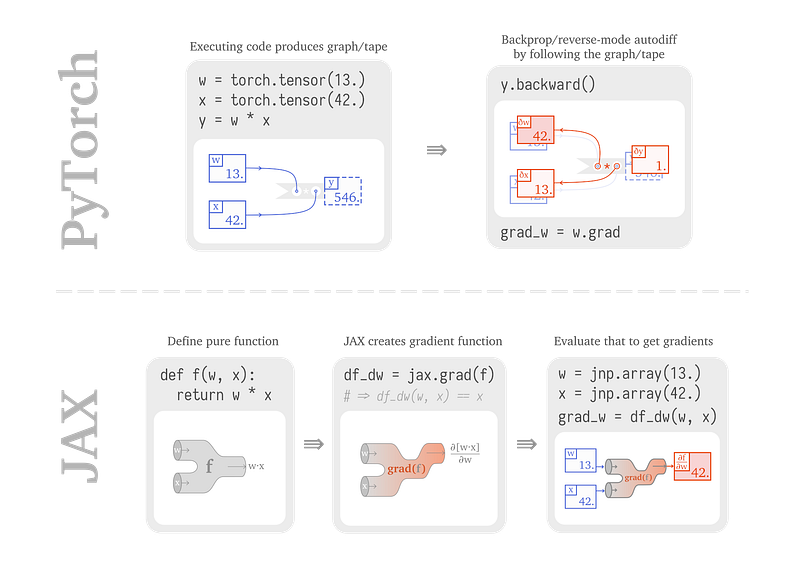
De PyTorch à JAX
Sabrina J. Mielke a publié un article qui explique comment construire et entraîner des réseaux de neurones en utilisant JAX. L’article se concentre sur la comparaison du fonctionnement interne de PyTorch et de JAX lors de la construction de réseaux neuronaux, ce qui permet de mieux comprendre certains des avantages et des différences de JAX.
Pourquoi utilisons-nous encore des jeux de données test créés il y a plus de 18 ans ?
Dans cet article de blog, Ehud Reiter explique pourquoi nous utilisons encore de vieilles techniques d’évaluation comme BLUE pour évaluer les modèles de NLP pour des tâches comme la traduction automatique
Introduction à BART
BART est un modèle proposé par Facebook qui implique un autoencodeur de débruitage pour le pré-entraînement de modèles seq2seq, ce qui améliorent les performances sur les tâches de génération de texte telles que le résumé abstrait. Sam Shleifer fournit un résumé de BART et explique comment il l’a intégré dans la librairie Transformers de Hugging Face.
Améliorations des Transformers
Madison May a récemment rédigé une enquête décrivant les moyens d’améliorer les approches basées sur les Transformers. L’article aborde ainsi les Sparse Transformers, les Adaptive Span Transformers, le Transformer-XL, les compressive Transformers, le Reformer, et les routing transformers.
Contrôler le style et le contenu dans la rédaction automatique de textes
Malgré l’impressionnante fluidité dont a fait preuve l’écriture automatique des textes l’année dernière, il est toujours difficile de contrôler des attributs comme la structure ou le contenu du texte. Dans un récent article de blog, Manuel Tonneau évoque les progrès récents et les perspectives dans le domaine de la génération de texte contrôlable, du modèle GPT-2 de Hugging Face, fine-tuné sur arXiv, au T5 de Google, en passant par CTRL de Salesforce et PPLM de Uber AI.
Education 🎓
L’avenir du NLP en Python
Dans l’un de nos numéros précédents, nous avons présenté THiNC, qui est une librairie de DL fonctionnelle axée sur la compatibilité avec d’autres librairies existantes. Ces diapositives présentent un peu plus cette livrairie qui a été utilisée par Ines Montani pour la conférence PyCon Colombia.
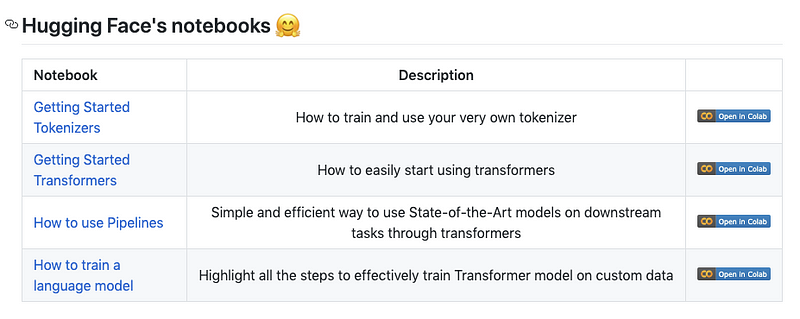
Les notebooks de Transformers
HuggingFace a publié un ensemble de notebooks qui aident à démarrer avec leur librairie Transformers. Certains notebooks comprennent l’utilisation de la tokenisation, la mise en place de pipelines et l’entraînement d’un modèle sur des données personnalisées.
TensorFlow 2.0 en 7 heures
Jetez un oeil à ce cours gratuity d’environ 7h consacré à TensorFlow 2.0 abordant des sujets qui vont des réseaux neuronaux de base au NLP avec les RNN, en passant par une introduction à l’apprentissage par renforcement.
DeepMind: le podcast
DeepMind a publié tous les épisodes (sous la forme d’une playlist YouTube) de son podcast qui présente des scientifiques, des chercheurs et des ingénieurs discutant de sujets allant de l’IAG aux neurosciences en passant par la robotique.
Cours de Machine Learning et de Deep Learning
Berkeley rend public le programme complet de son cours sur “l’apprentissage profond non supervisé”, principalement axé sur les aspects théoriques de l’apprentissage autosupervisé ainsi que sur les modèles générateurs. Parmi les sujets abordés, citons les modèles de variables latentes, les modèles autorégressifs et les modèles de flux pour n’en citer que quelques-uns. Des vidéos et des diapositives sont disponibles sur Youtube.
Nous avons également trouvé cette importante liste de cours en ligne sur l’apprentissage machine, le NLP et l’apprentissage approfondi.
Et voici un autre cours intitulé “Introduction to Machine Learning” qui comprend des sujets tels que la régression supervisée, l’évaluation des performances, les forêts aléatoires, le réglage des paramètres, des conseils pratiques, et bien plus encore.
Mentions spéciales ⭐️
Connon Shorten a publié une vidéo expliquant le modèle ELECTRA qui propose une technique appelée “remplacement de la détection de jeton” pour prétraiter les Transformers plus efficacement. Si vous êtes intéressé, nous avons également rédigé un bref résumé du modèle ici (en anglais).
Rachael Tatman travaille sur une nouvelle série intitulée NLP for Developers où l’idée est de parler plus en profondeur des différentes méthodes de NLP du moment et d’expliquer les problèmes communs que vous pourriez rencontrer.
DeepMind diffuse AlphaGo - The Movie sur YouTube pour célébrer le 4ème anniversaire de la victoire d’AlphaGo sur Lee Sedol au jeu de Go.
OpenMined évoque les rôles d’ingénieur de recherche et de chercheur scientifique, ce qui est une bonne occasion de s’impliquer dans la préservation de la vie privée en matière d’IA.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.