

Avant-propos d’Elvis
- nous avons ajouté une meilleure catégorisation pour tous les TL;DR et les résumés des publications liées au NLP : repo.
- tous les numéros et traductions de la newsletter sur le NLP sont répertoriés ici.
- cette semaine, nous avons également introduit Notebooks, une plateforme permettant de partager facilement les notebooks avec l’ensemble de la communauté. Si vous avez des notebooks que vous aimeriez partager avec la communauté, contactez-nous.
- nous avons partagé un tutoriel sur la façon d’effectuer une classification multiclasses de sentiments utilisant la vectorisation de texte ; une fonctionnalité expérimentale de TensorFlow 2.1.0 qui aide à gérer le texte dans un réseau neuronal.
Publications 📙
Enquêtes sur les embeddings contextuelles et les modèles linguistiques
Ce document fournit une étude approfondie des approches d’apprentissage des embeddings contextuelles. Il comprend également un examen de ses applications pour l’apprentissage par transfert, les méthodes de compression de modèles et les analyses de modèles.
Un autre rapport comporte un résumé des méthodes utilisées pour améliorer les modèles de langage basés sur les Transformers.
Enfin, une autre enquête complète sur les modèles linguistiques et qui fournit une taxonomie des modèles pré-entrainés en NLP.
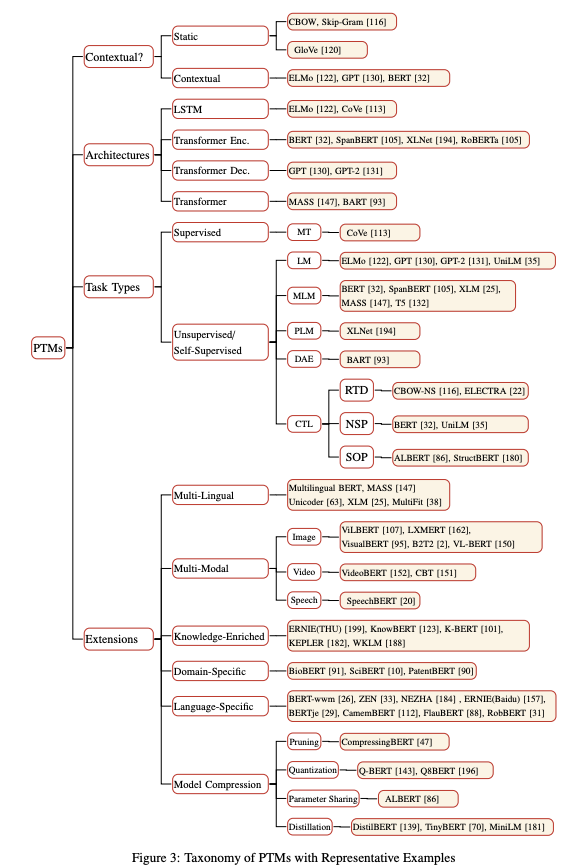
Visualiser les réseaux de neurones avec Grand Tour
Grand Tour est une approche linéaire (qui diffère des méthodes non linéaires telles que t-SNE) qui projette un ensemble de données en grandes dimensions en deux dimensions. Dans un nouvel article de Distill article, Li et al (2020) proposent d’utiliser les capacités du Grand Tour pour visualiser le comportement d’un réseau de neurones pendant son entraînement. On peut citer par exemple, les changements de poids et la manière dont ils affectent le processus d’entraînement, la communication de couche à couche dans le réseau ou encore l’effet des exemples contradictoires lorsqu’ils sont présentés au réseau neuronal.
Source: Distill
Initiations au méta-apprentissage pour la découverte de médicaments
Il a été largement rapporté que le méta-apprentissage peut permettre d’améliorer les critères d’apprentissage en peu de temps. Cela est particulièrement utile dans les situations où les données sont limitées, comme c’est généralement le cas pour la découverte de médicaments. Un récent travail a appliqué une approche de méta-apprentissage appelée Model-Agnostic-Meta-Learning (MAML) et d’autres variantes pour prédire les propriétés chimiques et les activités dans des environnements à faibles ressources. Les résultats montrent que les approches de méta-apprentissage fonctionnent de manière comparable aux bases de référence.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Un travail impliquant des chercheurs de l’Université de Californie à Berkeley, Google Research et l’Université de Californie à San Diego présente une méthode (NeRF) pour synthétiser des vues inédites de scènes complexes. En utilisant une collection d’entrées d’images RVB, le modèle prend des coordonnées 5D (emplacement et direction spatiale), entraîne un réseau entièrement connecté pour optimiser une fonction de scène volumétrique continue, et produit la densité de volume et la radiance RVB émise en fonction de la vue pour cet emplacement. Les valeurs de sortie sont composées ensemble le long d’un rayon de la caméra et rendues sous forme de pixels. Ces sorties rendues différentiables sont utilisées pour optimiser les représentations de la scène en minimisant l’erreur de rendu de tous les rayons de la caméra à partir des images RVB. Comparé à d’autres approches de synthèse de vues très performantes, le NeRF est qualitativement et quantitativement meilleur et permet de remédier aux incohérences de rendu telles que le manque de détails et les artefacts de scintillement indésirables.

Présentation de Dreamer
Dreamer est un agent d’apprentissage par renforcement proposé par les chercheurs de DeepMind et de Google AI. Son objectif est de remédier à certaines limitations (par exemple, la myopie et l’inefficacité des calculs) présentes dans les agents sans modèle. Dreamer est entraîné pour modéliser le monde, ce qui offre également la possibilité d’apprendre des comportements à long terme par rétropropagation en utilisant les prédictions du modèle. Les résultats de SoTA sont obtenus sur 20 tâches de contrôle continu basées sur les entrées d’images fournies. En outre, le modèle est efficace sur le plan des données et fait des prédictions en parallèle, ce qui le rend plus efficace sur le plan des calculs. Les trois tâches impliquées dans l’entraînement de l’agent qui permettent d’atteindre les différents objectifs sont résumées dans la figure ci-dessous :
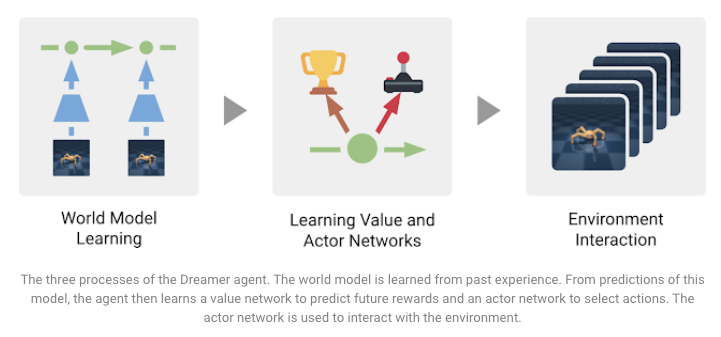
Source: Google AI Blog
Créativité, éthique et société 🌎
COVID-19 Open Research Dataset (CORD-19)
Pour encourager l’utilisation de l’IA pour lutter contre le COVID-19, l’ Allen Institute of AI a publié le COVID-19 Open Research Dataset (CORD-19), une ressource gratuite et ouverte pour promouvoir la collaboration mondiale en matière de recherche. L’ensemble de données contient des milliers d’articles scientifiques qui permettent à la communauté NLP d’obtenir des informations qui peuvent aider à lutter contre COVID-19.
SECNLP: une enquête sur le traitement du langage naturel dans le milieu clinique
SECNLP est une enquête qui comprend un aperçu détaillé d’une grande variété de méthodes et de techniques de NLP appliquées dans le domaine clinique. L’aperçu met principalement l’accent sur les méthodes d’embedding, les problèmes/défis posés par ces méthodes et une discussion sur les futures orientations de recherche.
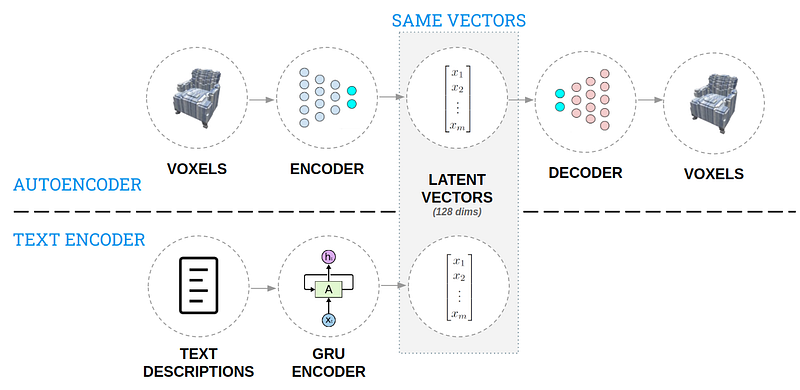
AI for 3D Generative Design
Cet article aborde une approche qui a été utilisée pour générer des objets 3D à partir de descriptions en langage naturel. L’idée est de créer une solution qui permet à un concepteur de réitérer rapidement dans le processus de conception et de pouvoir explorer plus largement l’espace de conception. Après avoir créé une base de connaissances de l’espace de conception composée de modèles 3D et de descriptions textuelles, deux autoencoders (voir figure ci-dessous) ont été utilisés pour coder ces connaissances de manière à pouvoir interagir avec elles de manière intuitive. Le modèle assemblé peut ensuite accepter une description textuelle et générer un design 3D, essayez-le dans cette démo.
Outils et jeux de données ⚙️
Stanza : une librairie Python applicable à plusieurs langues
Le Stanford NLP Group publie Stanza (anciennement StanfordNLP), une librairie python qui fournit des outils d’analyse de texte prêts à l’emploi pour plus de 70 langues. Les capacités comprennent la tokenisation, la lemmatisation, le POS, la NER, et bien plus encore. L’outil est construit sur la librairie PyTorch et prend en charge l’utilisation de GPU et des modèles neuronaux pré-entraînés.
Explosion a également construit un wrapper autour de Stanza qui vous permet d’interagir avec les modèles Stanza comme un pipeline spaCy.
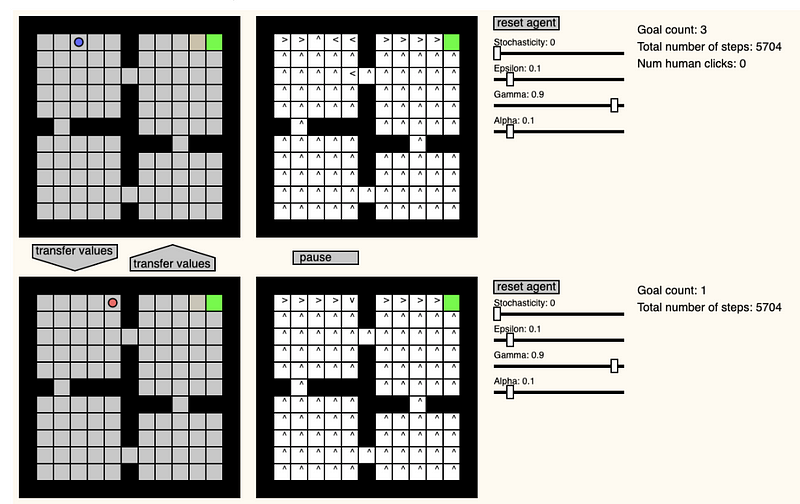
GridWorld
Pablo Castro a créé un site web qui fournit un terrain de jeu pour créer un environnement sous la forme d’une grille afin d’observer et de tester comment un agent d’apprentissage par renforcement essaie de résoudre ce monde. Parmi les caractéristiques, on trouve la possibilité de modifier les paramètres d’apprentissage et d’environnement en temps réel, de changer la position de l’agent et de transférer des valeurs entre deux agents.
X-Stance: un jeu de données multilingues et multicibles pour la détection de la position
Stance detection peut être utilisée pour évaluer de fausses informations. Jannis Vamvas et Rico Sennrich ont récemment publié un ensemble de données sur la détection de positions à grande échelle composé de textes écrits par des candidats aux élections en Suisse. Les textes sont disponibles en plusieurs langues, ce qui pourrait potentiellement conduire à des évaluations multilingues sur la tâche de détection de la position. Les auteurs proposent également l’utilisation d’un BERT multilingue qui permet d’obtenir des performances satisfaisantes en matière de transfert zéro entre langues et entre cibles. L’apprentissage entre cibles est une tâche difficile. Les auteurs ont donc utilisé une technique simple impliquant des cibles standardisées pour entrainer un modèle unique sur toutes les questions à la fois.
Créer des heatmaps textuelles interactives pour les notebooks Jupyter
Andreas Madsen a créé une librairie python appelée TextualHeatMap qui peut être utilisée pour visualiser et mieux comprendre quelles parties d’une phrase le modèle utilise pour prédire le mot suivant, comme dans les modèles de langage.

Source: textualheatmap
Articles et Blog ✍️
Comment générer du texte avec la librairie Transformers
HuggingFace a publié un article expliquant les différentes méthodes utilisées pour la génération du langage, en particulier pour les approches basées sur les transformers. Parmi les techniques abordées, on trouve la recherche gourmande, la recherche par faisceau, l’échantillonnage, l’échantillonnage top-k et l’échantillonnage top-p (noyau). Il existe de nombreux articles de ce type, mais les auteurs ont passé plus de temps à expliquer le côté pratique de ces méthodes et la façon dont elles peuvent être appliquées via des extraits de code.
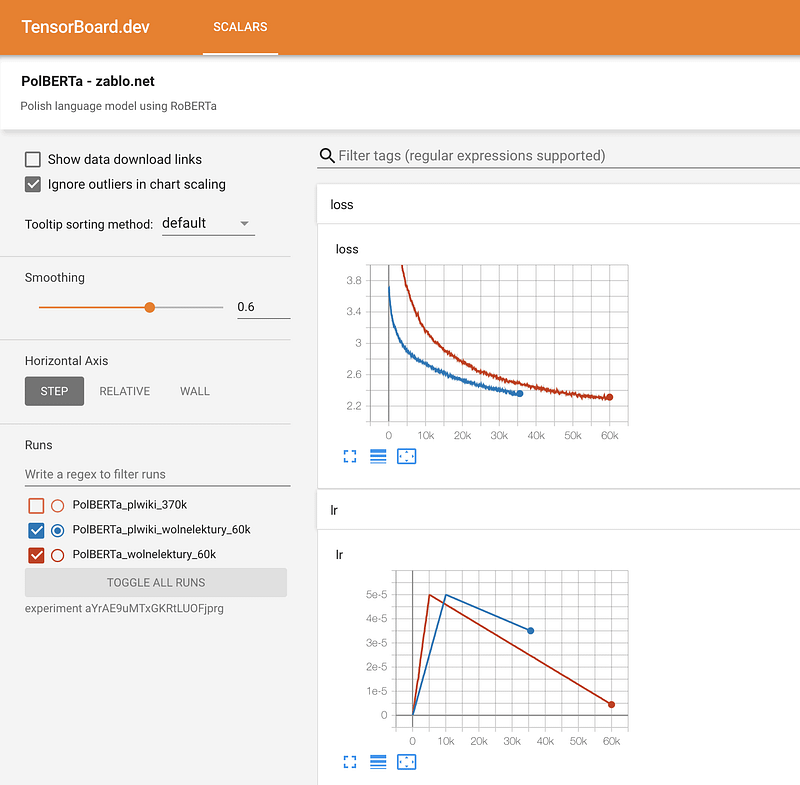
Entrainer RoBERTa de zéro
Motivé par l’absence d’un guide complet indiquant comment entraîner un modèle de langage de type BERT à partir de zéro en utilisant la librairie du Transformer, Marcin Zablocki partage ce [tutoriel] détaillé (https://zablo.net/blog/post/training-roberta-from-scratch-the-missing-guide-polish-language-model/). Le guide montre comment entraîner un transformer pour la langue polonaise et donne des conseils sur les erreurs courantes à éviter, la préparation des données, la configuration, la tokenization, le suivi du processus d’entraînement et le partage du modèle.
Education 🎓
Démarrer avec JAX (MLPs, CNNs & RNNs)
Robert Lange a récemment publié un tutoriel complet sur la façon d’entraîner un GRU-RNN avec JAX. D’autres ressources liées à JAX sont disponibles dans la newsletter précédente.
NLP for Developers : Word Embeddings
Rachael Tatman a publié le premier épisode d’une nouvelle série intitulée NLP for Developers qui couvrira les meilleures pratiques sur la façon d’appliquer un large éventail de méthodes de NLP. Le premier épisode comprend une introduction au word embeddings et à leur utilisation.
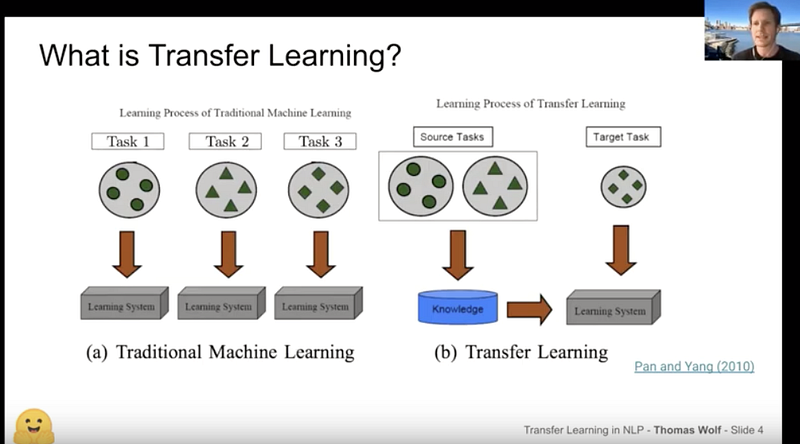
Thomas Wolf : une introduction à l’apprentissage par transfert et à HuggingFace
Thomas Wolf a présenté sa conférence sur l’apprentissage par transfert au NLP Zurich meetup, offrant une introduction à l’apprentissage par transfert en NLP. La conférence comprend un aperçu des récentes avancées en NLP et une introduction à Transformers et Tokenizers, deux des librairies les plus populaires publiées par l’équipe et les contributeurs de HuggingFace.
Mentions spéciales ⭐️
Amit Chaudhary partage un article qui montre comment tirer parti de la fonction de traduction de Google Sheets afin d’augmenter un corpus de texte limité.
New York NLP organisera une réunion en ligne pour une conférence intitulée “Utiliser Wikipédia et Wikidata en NLP” .
Lavanya Shukla a écrit un tutoriel sur la façon d’utiliser PyTorch Lightning pour optimiser les hyperparamètres d’un réseau de neurones tout en profitant des structures/styles de code simples fournis dans PyTorch Lightning. Le modèle résultant et ses performances sont visualisés à l’aide des résultats produits par le logger WandB.
Un groupe de chercheurs a publié une étude qui examine plus en détail pourquoi la batch normalization (BN) tend à dégrader les performances des méthodes basées sur les transformers. Sur la base de ces résultats, les auteurs proposent une nouvelle approche appelée « power normalization » pour traiter les problèmes rencontrés dans la BN. La méthode surpasse à la fois la BN et la normalisation des couches (couramment utilisée de nos jours) sur une variété de tâches de NLP.
Cet [article de blog] (https://www.datasciencecentral.com/profiles/blogs/10-timeless-reference-books) contient une longue liste de livres pour vous aider à démarrer en ML.
Vous pouvez retrouver la précédente newsletter ici
Si vous avez des jeux de données, des projets, des articles de blog, des tutoriels ou des documents que vous souhaitez partager dans la prochaine édition de la newletter, vous pouvez utiliser ce formulaire.
Abonnez-vous pour recevoir les prochains numéros dans votre boîte mail.