

NLP Haber Bülteni’nin 10. sayısına hoş geldiniz. Umarız iyi ve güvendesinizdir. Bu sayıda, dil modellerine ilişkin en iyi uygulamalardan makine öğrenmesinde tekrarlanabilirliğe ve doğal dil işlemede (NLP) mahremiyet ve güvenliğe kadar uzanan konuları ele alıyoruz.
dair.ai sitesinden güncellemeler 🔬🎓⚙️
-
COVID-19 Açık Araştırma Veri Setinin (COVID-19 Open Research Dataset) çalışmasına yardımcı olmak ve bilimsel literatürden içgörü elde etmek için, açık kaynak araçlarını ve herkese açık ön-eğitime tabi tutulmuş (İng. pre-trained) dil modellerini kullanarak basit bir metin benzerliği arama uygulaması oluşturma adımlarını gösteren bir notebook yayımladık.
-
Geçtiğimiz hafta “Modern NLP için Derin Öğrenme” hakkında Açık Veri Bilimi Konferansı‘nda sanal bir eğitim verdik. Kaynakları burada bulabilirsiniz.
-
Geçen hafta topluluğumuzun üyeleriyle birlikte iki makale yayımladık. Bunlardan biri; etiketlenmemiş veri vektörlerinin (veri akışı) bir dizisini analiz etme ve bunların temsillerini öğrenme problemine yönelik denetimsiz aşamalı öğrenme (İng. unsupervised progressive learning) ile ilgili. İkinci makale ise ELMo kullanarak atıf niyet sınıflandırması (İng. citation intent classification) için bir yaklaşımı özetlemektedir.
-
Kısa süre önce, duygu sınıflandırması (İng. emotion classification) görevi için ön-eğitime tabi tutulmuş dil modellerinin ince-ayarını (İng. fine-tune) yapmanıza yardımcı olacak bir notebook yayımladık.
Araştırma and Yayınlar 📙
XTREME: Dillerarası Genelleştirmenin Değerlendirilmesinde Çokdilli Çoklu-Görevli (multi-task) Geniş Bir Başarım Ölçümü
Hafta başında, Google AI ve DeepMind araştırmacıları, XTREME adında, çokdilli temsilleri öğrenen dil modellerinin dillerarası genelleştirme kabiliyetlerini desteklemeyi amaçlayan ilginç bir başarım ölçümü yayımladılar. Bu başarım ölçümü, sözdizimsel veya anlamsal olarak farklı anlam düzeyleri hakkında akıl yürütmeyi gerektiren 40 dil ve 9 farklı görev üzerinde test içeriyor. Bu bildiri ayrıca, mBERT, XLM ve MMTE gibi çokdilli temsiller için kabul görmüş en iyi modelleri kullanarak temel sonuçlar vermektedir.
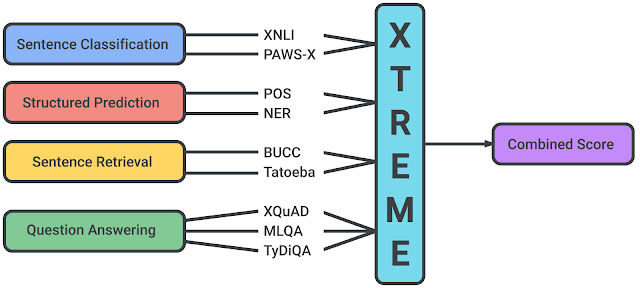
Kaynak: Google AI Blog
Makinelerin Gerçek Dünya Dil Kullanımlarına Göre Değerlendirilmesi
Dil modellerinin soru cevaplama (QA) ve dizilim etiketleme (İng. sequence labeling) gibi çeşitli görevlerde nispeten iyi performans gösterdiği gösterilmiştir. Ancak, yeni bir bildiri, dil modellerinin gerçek dünya dil kullanımında daha karmaşık ayarlarla başarı gösterip gösteremeyeceğini daha iyi değerlendirmek için bir framework ve kıyaslama önermektedir (ör. güncel durumlar için faydalı tavsiyeler üretmek). Ampirik sonuçlar, T5 gibi kabul görmüş en iyi modellerin, vakaların sadece %9’unda insan tarafından yazılmış tavsiye kadar faydalı tavsiyeler ürettiğini göstermektedir. Bu sonuçlar dil modellerinin gerçek dünya bilgisini ve sağduyulu muhakemeyi anlama ve modelleme yeteneğindeki eksikliklere işaret etmektedir.
Metin Temsili Modellerinize Sevgi Katın: Basque Örneği
Dile özgü büyük veri setleri üzerinde tekdilli modellerin (FastText kelime gömmeleri (İng. word embeddings) ve BERT) eğitimi, ön-eğitime tabi tutulmuş çokdilli sürümlerden daha iyi sonuçlar verebilir mi? Yakın tarihli bir bildiri‘de, araştırmacılar daha büyük Basque derlemleri kullanarak ilgili modellerin etkisini ve performansını inceliyorlar. Sonuçlar, modelin aslında konu sınıflandırması (İng. topic classification), duygu sınıflandırması ve Basque için PoS etiketlemesi gibi alt görevlerde daha iyi sonuçlar verdiğini göstermektedir. Bunun diğer diller için geçerli olup olmadığını ve ortaya çıkan bazı ilginç sonuçlar veya yeni zorluklar olup olmadığını test etmek ilginç olabilir.
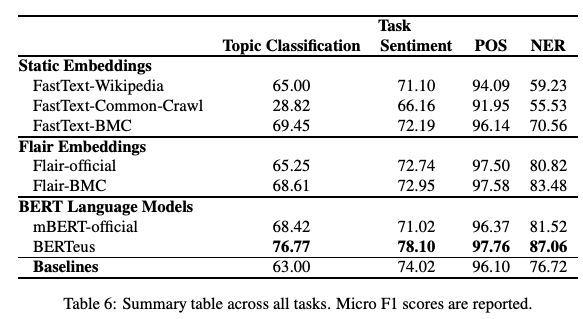
Şekil kaynağı: Agerri et al. (2020)
SimCLR ile Öz-Denetimli ve Yarı-Denetimli Öğrenmede İlerleme
Haber bültenimizin önceki bir sayısında, Google AI tarafından geliştirilen ve öğrenme aktarımı (İng. transfer learning) ve yarı-denetimli (İng. semi-supervised) öğrenme gibi farklı ortamlarda görüntü sınıflandırma sonuçlarını iyileştirmede görsel temsillerin kontrastlı öz-denetimli öğrenimi (İng. contrastive self-supervised learning) için bir framework öneren SimCLR’den bahsetmiştik. Etiketlenmemiş verilerden görsel temsiller öğrenmek öz-denetimli ve yarı-denetimli öğrenmeye yeni bir yaklaşımdır. Sonuçlar, ImageNet’te (etiketlenmiş verilerin sadece %1’ine dayanarak) yöntemin düşük kaynaklı ortamlarda da yararlı olabileceğini gösteren kabul görmüş en iyi sonuçları elde ettiğini göstermektedir.
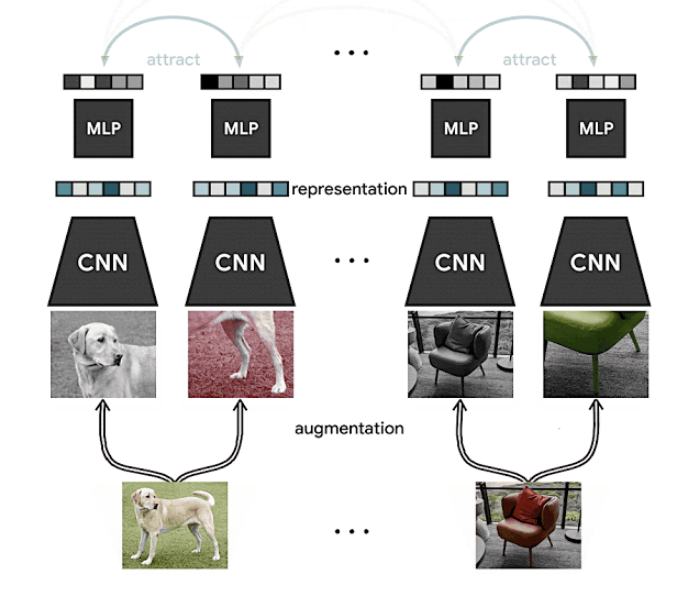
Kaynak: Google AI Blog
Öz-denetimli öğrenmenin alandaki en önemli konulardan biri olduğunu belirtmek gerekir. Daha fazla bilgi edinmek istiyorsanız aşağıdakilere göz atabilirsiniz:
- Computers Already Learn From Us. But Can They Teach Themselves?
- The Illustrated Self-Supervised Learning
- Self-supervised learning and computer vision
Bayt Çifti Kodlaması Dil Modeli Ön-eğitimi için En Optimum Algoritma Değil
Kaj Bostrom ve Greg Durrett, bir dil modelinin ön-eğitimi için sıklıkla kullanılan Bayt Çifti Kodlaması (İng. Byte Pair Encoding - BPE) tokenizasyon algoritmasının en optimum yöntem olup olmadığını değerlendirdikleri bir bildiri yayımladılar. Başka bir deyişle, tokenizasyonun dil modellerinin performansı üzerindeki etkisinin doğrudan değerlendirilmesini irdelediler. Yazarlara göre, bu literatürde de görülebildiği gibi nadiren irdelenmektedir. Sonuca ulaşmak için, kontrollü deneyler kullanarak dil modellerini sıfırdan ön-eğitime tabi tuttular ve unigram ve BPE gibi farklı tokenizasyon algoritmaları uyguladılar. Daha sonra, elde edilen ön-eğitime tabi tutulmuş dil modelleri birkaç alt akış görevinde test edildi. Sonuçlar, unigram tokenizasyonunun daha yaygın kullanılan BPE ile eşleştiğini veya daha iyi performans gösterdiğini ortaya koymaktadır.
Longformer: Uzun Doküman Transformatörü
Allen AI’daki araştırmacılar, uzun metinlerle daha yüksek verimde performans göstermeyi hedefleyen Longformer adlı transformatör tabanlı yeni bir model yayımladı. Transformatör tabanlı modellerin öz-dikkat (İng. self-attention) işlemlerinin büyüklüğünün katlanarak artması (sekans uzunluğunun kuadratik etkisi ile) ve bu nedenle hesaplama açısından çok pahalı olması bilinen bir transformatör tabanlı model limitasyondur. Son zamanlarda, Transformatörlerin uzun dokümanlara uygulanabilirliğini sağlamak için Reformer ve Sparse Transformers gibi birçok çaba gösteriliyor. Longformer, daha az bellek tüketmek ve uzun doküman modellemesinde yüksek verim göstermek için karakter düzeyinde modelleme ile öz-dikkati (yerel ve genel dikkat karışımı) birleştiriyor. Yazarlar ayrıca, ön-eğitime tabi tutulmuş modellerinin soru cevaplama (İng. question answering - QA) ve metin sınıflandırması da dahil olmak üzere doküman düzeyi alt görevlerine uygulandığında diğer yöntemlerden daha iyi performans gösterdiğini ortaya koymaktadır.
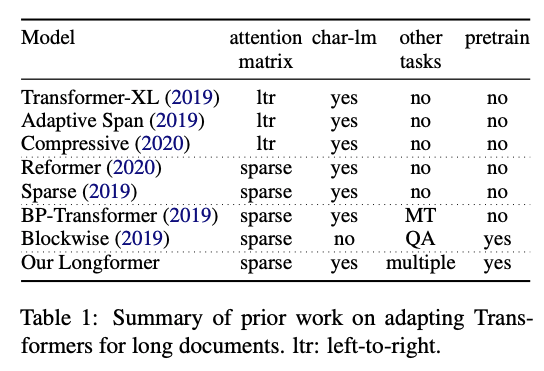
Şekil kaynağı: Beltagy et al. (2020)
Yaratıcılık, Etik ve Toplum 🌎
Makine Öğrenmesinde Tekrarlanabilirlik
-
Tekrarlanabilirlik, makine öğrenimi toplulukları arasında devam eden bir tartışma konusu olmuştur. Daha açık, şeffaf ve erişilebilir bilimi teşvik etmek için tekrarlanabilirlik konusunda birçok çaba gösterilmiştir. Makine öğrenimi alanının tekrarlanabilirlik açısından nerede durduğunu anlamak istiyorsanız, Joelle Pineau ve diğerleri tarafından yayımlanan bu yayına bakın.
-
Daha yakın zamanda ve bu çabalardan esinlenerek, Papers with Code ekibi (bu ekip şu an Facebook AI’nın bir parçası) büyük makine öğrenmesi konferanslarında sunulan tekrarlanabilir araştırmaları kolaylaştırmak için faydalı olacak [tekrarlanabilirlik kontrol listesi] (https://github.com/paperswithcode/releasing-research-code)’ni anlattıkları bir blog yazısı yayımladırlar. Kontrol listesi kod gönderimini aşağıdaki şekilde değerlendiriyor:

Kaynak: Papers with Code
- Açık bilim ve tekrarlanabilirlik konusunda; bir NLP araştırmacısının, bir araştırmacının kopyalayamayacağı bir bildiri sonucunu kopyalamayı başaracaklara ödül vereceğini duyurduğu ilginç bir gönderisi burada görebilirsiniz.
NLP’de Mahremiyet ve Güvenlik
Ön-eğitime tabi tutulmuş bir dil modeli çalınabilir mi veya API’ler aracılığıyla kullanıma açıldığında herhangi bir güvenlik etkisi yaratabilir mi? Yeni bir makalede araştırmacılar, özellikle modeli çalmak için sorguların kullanımı ile ilgili olarak, BERT tabanlı API’leri güvenlik açısından test etmeyi amaçlıyorlar. Özetle, kötü niyetli bir kişi ince-ayara tabi tutulmuş bir modeli, anlamsız dizilerle besleyerek ve kurban modelinin öngörülen etiketleriyle kendi modelini ince-ayara tabi tutarak çalabileceğini buldular. Model çıkarma saldırıları hakkında daha fazla bilgiyi buradan edinebilirsiniz.
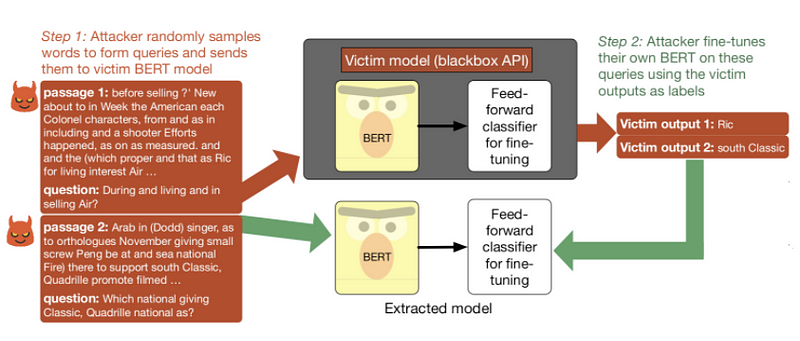
SQuAD konusunda eğitilmiş bir kurban modeline uygulanan model çıkarma işlem dizisi (Kaynak).
ACL 2020’de kabul edilen bir başka ilginç bildiri, ön-eğitime tabi tutulmuş dil modellerinin saldırılara karşı hassas olup olmadığını araştırıyor. Yazarlar, bu modelleri ciddi tehditlere karşı savunmasız hale getiren, güvenlik açıklarını ön-eğitime tabi tutulmuş ağırlıklara (İng. weight) enjekte edebilen bir zehirlenme yöntemi geliştiriyor. Bu açıklar, saldırganın modelin tahminlerini manipule etmek için rasgele kelimeler enjekte ederek bu modellerde arka kapılar (İng. backdoors) ortaya çıkarabileceğinin mümkün olduğunu göstermektedir. Bunu test etmek için, modeli yanlış örneklemeye zorlamak amacıyla belirli anahtar kelimelerle enjekte edilen veri kümelerini içeren alt görevleri yerine getirmek için ön-eğitime tabi tutulmuş modeller kullanılmıştır.
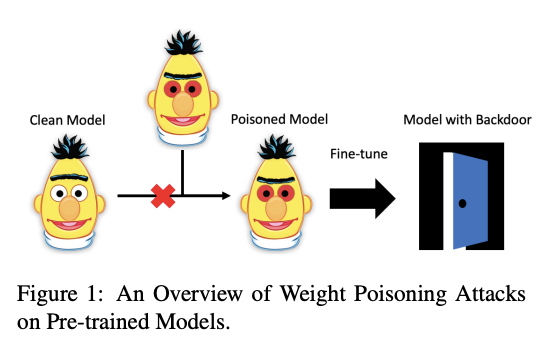
Şekil kaynağı: Kurita et al. (2020)
Bir Dizi AI-tabanlı COVID-19 Uygulama ve Araştırmaları
-
COVID-19, modern zamanların en büyük zorluklarından birisi olduğunu kanıtladı. Tüm dünyadan araştırmacılar COVID-19’un anlaşılmasına yardımcı olup katkıda bulunmak için arama motorlarından veri seti yayınlarına kadar farklı yollar bulmaya çalışmaktadırlar. Sebastian Ruder, yapay zeka araştırmacılarının üzerinde çalıştığı birkaç ilgi çekici projeyi ön plana çıkardığı haber bülteninin yeni bir sayısını yayımladı.
-
COVID-19 konu başlığı üzerine Allen AI’dan araştırmacılar, bu ayın sonlarına doğru yapılacak sanal buluşmada popüler COVID-19 Open Research Veri Seti (CORD-19) hakkında tartışacaklardır.
-
CORD-19 veri seti birçok araştırmacı tarafından arama motorları gibi NLP-destekli uygulamalar geliştirmek için kullanılmaktadır. Araştırmacılara bilimsel makalelerde raporlanan CORD-19 ile ilgili sonuçları elde etmelerinde yardımcı olabilecek bir arama motorunun gerçeklendiği şu bildiriyi örnek olarak alabilirsiniz. Bu tür araçlar, yazarlara göre kanıta dayalı karar verme sürecini bilgilendirmeye yardımcı olabilir.
-
ArCOV-19, 27 Ocak’tan 31 Mart 2020’ye kadarlık periyodu(hala devam etmekte) kapsayan Arapça COVID-19 Twitter veri setidir. Bu veri seti, COVID-19 pandemisini kapsayan genel kullanıma açık ilk Arapça Twitter veri setidir. Yaklaşık 748 bin popüler tweet(Twitter arama kriterine göre) ve bu tweetlerin en popüler alt kümelerini içermektedir. Alt kümeler hem retweetleri hem de tartışma zincirlerini(tweetlere verilen cevaplar) içermektedir. ArCOV-19, doğal dil işleme, veri bilimi, sosyal hesaplama (İng. social computing) ve diğerleri gibi birçok alanda araştırmalara olanak vermek için tasarlanmıştır.
Araçlar ve Veri Setleri ⚙️
Python’da Makine Öğrenmesi: Veri Bilimi, Makine Öğrenmesi ve Yapay Zeka’da Ana Geliştirme ve Teknoloji Akımları Bir araç ya da veri seti değil; ancak Sebastian Raschka, Joshua Patterson ve Corey Nolet’in bu harika bildirisi, özellikle Python programlama dili üzerine odaklanarak makine öğrenmesinde yeni teknoloji akımlarının geliştirilmesi üzerine kapsamlı bir genel bakış sağlamaktadır.
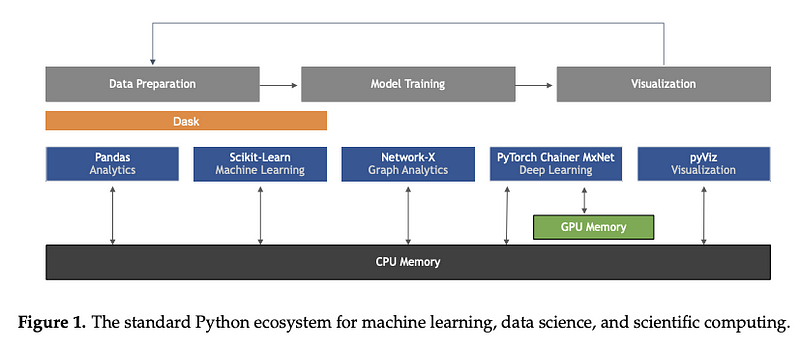
Resim kaynağı Raschka ve çalışma arkadaşları (2020)
Makine Öğrenmesinde Yorumlanabilirlik ve Açıklanabilirlik
HuggingFace ekibi, BERT ve RoBERTa gibi dil modellerinden öğrenilen temsillerin görselleştirilmesine olanak sağlayan exBERT adını verdikleri görselleştirme aracını yayımladılar. Bu özellik, kendi model sayfalarına entegre edilmiştir. Aynı zamanda dil modellerinin nasıl öğrendiklerinin ve bu öğrenilen temsillerin hangi özellikleri çözümlediklerinin daha iyi anlaşılmasını hedeflemektedir.
OpenAI, genellikle yorumlanabilirlik bağlamında çalışılan çeşitli görü modellerinin önemli katman ve nöronlarından elde edilmiş bir dizi görselleştirmeleri içeren Microscope adını verdikleri web uygulamalarını kısa zaman önce yayımladılar. Ana hedef, sinir ağlarında öğrenilen özelliklerden çıkarılan ilgi çekici kavramların analizini ve paylaşımını kolaylaştırmaktır.
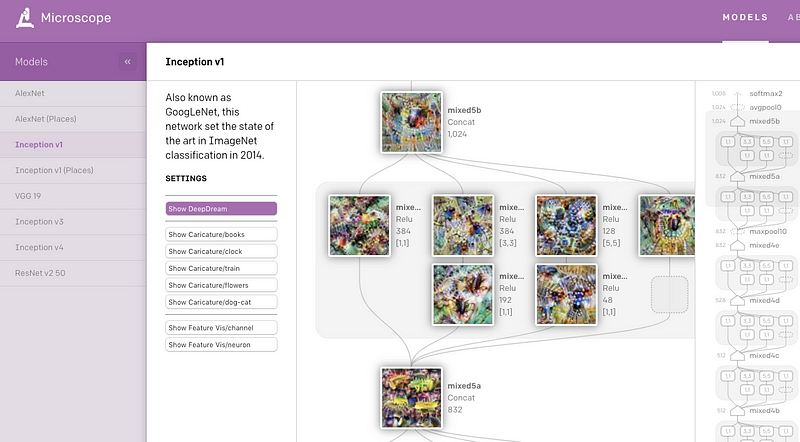
CloudCV: ViLBERT Çoklu-Görev Demosu
Bir önceki NLP Araştırmalarında Öne Çıkanlar‘da, açıklama tabanlı resim çıkarımında ve görsel soru cevaplamada (VQA) kullanılabilecek görü-ve-dil modellerini iyileştirme tekniği çok görevli ViLBERT’e yer vermiştik. Yazarlar şimdi de VQA ve konum-gösterici soru cevaplama(İng. pointing question answering) gibi 18 farklı görü ve dil görevleri üzerinde modellerin test edilebileceği bir web uygulamalasını sağlamaktadırlar.
Açık araştırma için COVID-19 ile ilgili 150 milyondan fazla tweetlerin bulunduğu bir Twitter veri seti
COVID-19 küresel pandemisine olan ilgi düzeyi sebebiyle, araştırmacılar Twitter’dan elde edilen COVID-19 hakkındaki sıradan konuşmalara ilişkin tweetlerin olduğu bir veri setini yayımlamaktadırlar. İlk sürümden beri, yeni işbirlikçilerden ek veriler eklenerek kaynağın şu anki boyutuna ulaşmasına olanak sağlanmıştır. Özel veri toplama işlemi 11 marttan itibaren başlamış bulunmakta ve günlük 4 milyondan fazla tweet elde edilmektedir.
Küçük bir otograd motoru
Andrej Karpathy kısa bir süre önce, sade ve sezgisel bir arayüz kullanarak yapay sinir ağı inşa etme ve eğitme yetenekleri sağlayan micrograd adı verilen kütüphaneyi çıkardı. Aslında, bulunan en küçük otograd (İng. otograd) motoru olduğunu iddia ettiği bütün kütüphaneyi yaklaşık 150 kod satırında yazdı. İdeal olarak, bu tür kütüphaneler eğitim amaçlı kullanılabilir.
Makaleler ve Blog gönderileri ✍️
Transformatör Ailesi ve En Son Gelişmeler
Yeni ve güncel bir blog gönderisinde Lilian Weng, Transformatör modellerinin en son gelişmelerinden bazılarını özetlemektedir. Makale, güzel bir notasyon, tarihsel bir gözden geçiriş ve daha uzun dikkat süresi(Transformer XL), düşük hesaplama ve bellek tüketimi gibi en son iyileştirmeleri ele almaktadır.
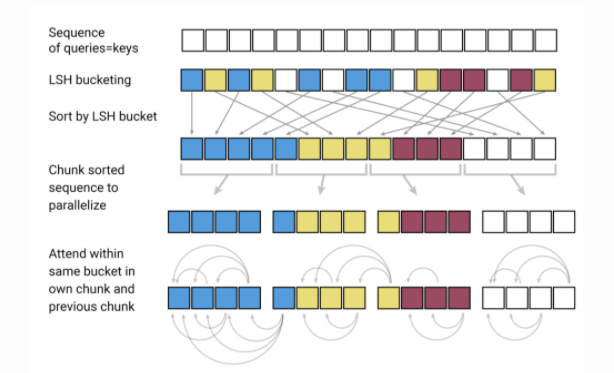
Model sıkıştırma (İng. model compression), ön-eğitime tabi tutulmuş modellerin büyük boyutları ve doğaları sebebiyle NLP’de önemli bir araştırma alanıdır. İdeal durumda, bu modeller birçok çeşitli NLP görevinde en iyi sonuçları üretmeye devam ettikçe bu modellerin hesaplanma maliyetlerini düşürerek üretimde yapılabilir olmalarını sağlamak da önemli olmaktadır. Madison May, kısa zaman önce özellikle NLP’de model sıkıştırmada kullanılan birkaç tekniği özetlediği harika bir makale daha yayımladı.
Eğitim 🎓
Alec Radford’dan Dil Modelleri üzerine Konuk Dersi
Eğer CBOW, Word2Vec, ELMo, GPT, BERT, ELECTRA ve T5 gibi dil modellerinde kullanılan tekniklerin teorik yönleri hakkında bilgi edinmeye meraklıysanız, Alec Radford’un(OpenAI’da araştırmacı) şu muhteşem konuk dersi ilginizi çekebilir. Bu eğitim, Pieter Abbeel’in derin gözetimsiz öğrenme tekniklerini anlattığı hala devam eden dersinin bir parçası olarak verilmişti.
Python Numpy Rehberi(Jupyter ve Colab’lı)
Stanford’un popüler çevrimiçi Görsel Tanıma için Evrişimsel Sinir Ağları(Convolutional Neural Network for Visual Recognition) dersi, Numpy’ye giriş rehberi için artık Google Colab’a bir bağlantı içermektedir. Oldukça geniş bir rehber; ancak yeni başlayanlar için olukça iyidir.
Yeni mobil sinir ağı mimarisi
Mobil ve hafif istemciler için sinir ağları inşa etmeye ilginiz varsa şu kapsamlı blog gönderisi sizin için olabilir. Bu makale birçok yapay sinir ağı tasarımını ve hız performans testlerini kapsamaktadır.
Veri-Tabanlı Cümle Basitleştirme: Derleme ve Kıyaslama
Cümle basitleştirme (İng. sentence simplification), bu günlerin baskın paradigması, bir cümleyi değişime uğratarak okumayı ve anlamayı daha kolay hale getirmeyi amaçlamaktadır. Şu derleme bildirisi, İngilizce’de orijinal-basitleştirilmiş şeklinde cümle çiftlerinden oluşan bir derlem kullanarak nasıl basitleştirme yapılacağını öğrenme girişimi yaklaşımlarına odaklanmaktadır. Ayrıca farklı yaklaşımların, karşılaştırma ve güçlü ve kısıtlı yönlerini ön plana çıkarmak gibi farklı veri setleri üzerinde kıyaslamalarını da içermektedir.
Makine Öğrenmesinde İleri Konu Başlıkları
Yisong Yue Veri-Tabanlı Algoritma Tasarımı dersinin bütün ders videolarını yayımladı. Ders, Bayesian optimizasyonu, türevlenebilir hesaplama (İng. differentiable computation) ve taklit öğrenme(İng. imitation learning) gibi makine öğrenmesinde ileri konu başlıklarını içermektedir.
Bunlara da göz atın ⭐️
Önceki NLP Haber Bülteni sayılarına buradan erişebilirsiniz.
Harvard, birçok kendi kendinize çalışabileceğiniz çevrimiçi kurslarını ücretsiz olarak sunmaktadır.
ARBML, web, komut satırı ve notebook gibi birçok arayüz ile gerçek zamanlı deneyim şansı sunarak Arapça NLP ve makine öğrenmesi projelerinin implementasyonlarını sağlamaktadır.
NLP Kontol Paneli(NLP Dashboard), haber hikayelerinin ve metinlerin istatistiksel analizi ve varlık ismi tanıma (İng. named entity recognition) işlemlerinin yapılabileceği eğlenceli bir web uygulamasıdır. spaCy, Flask ve Python ile geliştirilmiştir.
Eğer göz gezdirmediyseniz Connor Shorten, ilginç ve güncel makine öğrenmesi bildirilerini özetlediği şu bilgilendirici YouTube kanalını sürdürmektedir. Her çalışmanın kısa, öz ve muhteşem özetlerini sağlarken önemli detaylarını da işlemektedir. Ayrıca alandaki diğer araştırmacılar ile bir de podcast yayını başlattı.
İşte metin sınıflandırma, metinsel doğrulama(İng. textual entailment), metin özetleme ve soru cevaplama gibi NLP işlemlerinin en iyi yöntemlerini ve önerileri (notebook’lar ve açıklamalar ile birlikte) sağlayan etkileyici, zengin bir repo.
Eğer NLP Haber Bülteni’nin bir sonraki sayısında paylaşmak istediğiniz güncel veri seti, proje, blog gönderisi, rehber ya da bildiri varsa lütfen şu formu doldurarak direkt gönderiniz.
🔖 Gelecek sayıları gelen kutunuzda görmek için NLP Haber Bülteni’ne abone olun.