

Welcome to the 10th issue of the NLP Newsletter. We hope you are well and staying safe. In this issue, we cover topics that range from best practices regarding language models to reproducibility in machine learning to privacy and security in natural language processing (NLP).
dair.ai updates 🔬🎓⚙️
-
In order to help in the exploration of the COVID-19 Open Research Dataset and obtain insights from scientific literature, we published a notebook that walks through the steps of building a simple text similarity search application using open source tools and publicly available pretrained language models.
-
We delivered a virtual training at the Open Data Science Conference this past week on “Deep Learning for Modern NLP”. Find materials here.
-
This past week we published two articles together with members of our community. One is about unsupervised progressive learning which is a problem that involves an agent that analyzes a sequence of unlabelled data vectors (data stream) and learns representations from these. The second article summarizes an approach for citation intent classification using ELMo.
-
We recently published a notebook that helps to provide ideas on how to fine-tune pretrained language models for the task of emotion classification.
Research and Publications 📙
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization Earlier this week, researchers at Google AI and DeepMind published an interesting multi-task benchmark called XTREME that aims to encourage evaluation of the cross-lingual generalization capabilities of language models that learn multilingual representations. The benchmark tests on 40 languages and 9 different tasks that collectively require reasoning about different levels of meaning either syntactically or semantically. The paper also provides baseline results using state-of-the-art models for multilingual representation such as mBERT, XLM, and MMTE.
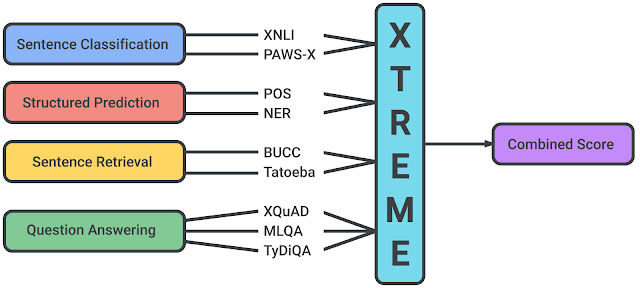
Source: Google AI Blog
Evaluating Machines by their Real-World Language Use
It has been shown that language models perform relatively well on a variety of tasks such as question answering and sequence labeling. However, a new paper proposes a framework and benchmark to better evaluate whether language models can perform at real-world language use with more complex settings (e.g., generating helpful advice for current situations). Empirical results demonstrate that current state-of-the-art models such as T5 generate advice that is as helpful as human-written advice in only 9% of the cases. These results point out the shortcomings of LMs in the ability to understand and model world knowledge and common-sense reasoning.
Give your Text Representation Models some Love: the Case for Basque
Can training monolingual models (FastText word embeddings and BERT) on large language-specific datasets produce better results than pretrained multilingual versions? In a recent paper, researchers study the effect and performance of pertaining models using larger Basque corpora. Results indicate that indeed the model does produce better results on downstream tasks such as topic classification, sentiment classification, and PoS tagging for Basque. It could be interesting to test if this holds for other languages and whether there could some interesting results or new challenges that arise.
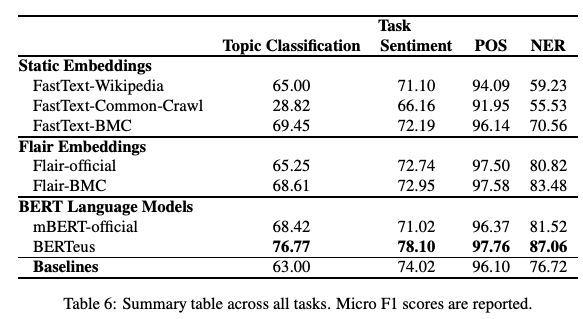
Figure by Agerri et al. (2020)
Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
In a previous issue of the newsletter, we featured SimCLR, a method by Google AI that proposes a framework for contrastive self-supervised learning of visual representations for improving image classification results in different settings such as transfer learning and semi-supervised learning. It is a new approach to self-and semi-supervised learning to learn visual representations from unlabeled data. Results demonstrate that it achieves state-of-the-art results on ImageNet while only relying on 1% labeled data which indicates that the method could also be beneficial in low-resourced settings.
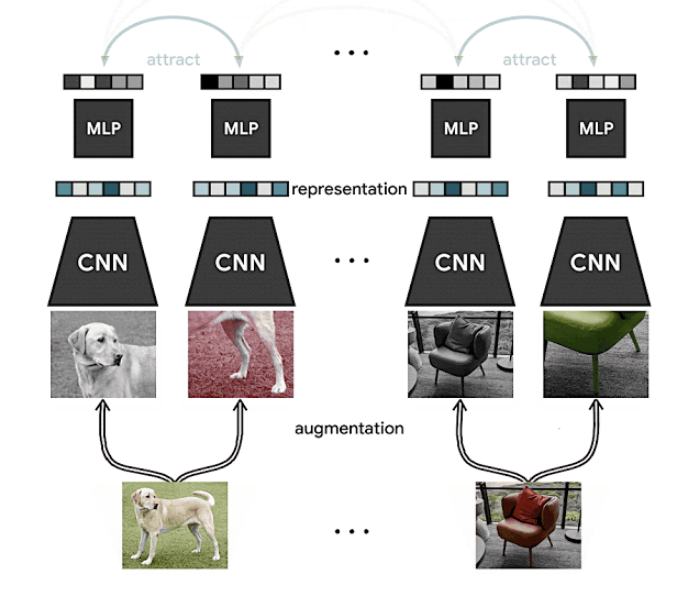
Source: Google AI Blog
It is worth mentioning that self-supervised learning is one of the hot topics in the field. If you are interested to know more you can check out the following:
- Computers Already Learn From Us. But Can They Teach Themselves?
- The Illustrated Self-Supervised Learning
- Self-supervised learning and computer vision
Byte Pair Encoding is Suboptimal for Language Model Pretraining
Kaj Bostrom and Greg Durrett published a paper where they aimed to investigate whether the commonly used tokenization algorithm called Byte Pair Encoding (BPE) is the most optimal for pretraining language models (LMs). In other words, they proposed a direct evaluation of the tokenization impact on the performance of LMs. According to the authors, this is rarely ever examined as observed in the literature. To achieve this, they pretrain LMs from scratch using controlled experiments and apply different tokenization, namely unigram and BPE. Thereafter they would test the resulting pretrained LMs on several downstream tasks. Results demonstrate that the unigram tokenization matches or outperforms the more common BPE.
Longformer: The Long-Document Transformer
Researchers at Allen AI published a new Transformer-based model called Longformer that is targeted at performing more efficiently with longer text. It is well known that one of the limitations of Transformer-based models is that they are computationally expensive due to how the self-attention operation scales (quadratically with sequence length) thus limiting the ability to process longer sequences. Recently, there have been many efforts such as the Reformer and Sparse Transformers to enable the applicability of Transformers for long documents. The Longformer combines character-level modeling and self-attention (mix of local and global attention) to consume less memory and demonstrate effectiveness in long document modeling. Authors also show that their pretrained model outperforms other methods when applied to document-level downstream tasks including QA and text classification.
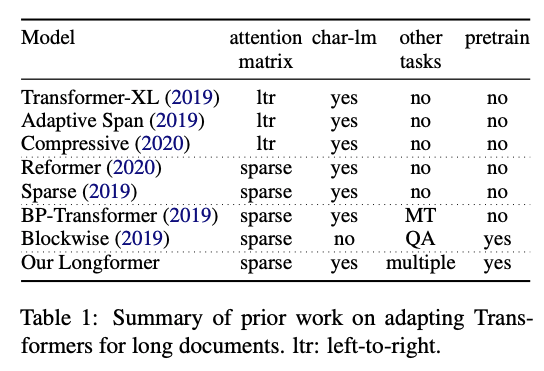
Figure by Beltagy et al. (2020)
Creativity, Ethics, and Society 🌎
Reproducibility in ML
-
Reproducibility has been an ongoing topic of discussion amongst the machine learning communities. In order to encourage more open, transparent and accessible science, there have been many efforts around reproducibility. If you want to understand where the field of machine learning stands in terms of reproducibility, check out this publication by Joelle Pineau and others.
-
More recently, and inspired by these efforts, the Papers With Code team (now part of Facebook AI) published a blog post explaining a useful reproducibility checklist to “facilitate reproducible research presented at major ML conferences”. The checklist assesses code submission on the following:

Source: Papers with Code
- On the topic of open science and reproducibility, here is an interesting post by an NLP researcher offering a bounty for replicating results from a paper that another researcher couldn’t replicate.
Privacy and Security in NLP
Can a pretrained language model be stolen or does it impose any security implications when exposed for usage via APIs? In a new paper, researchers aim to test BERT-based APIs for security implications particularly regarding the use of queries to steal the model. In summary, they did found that an adversary can steal a fine-tuned model by just feeding gibberish sequences and fine-tuning their own model on the predicted labels of the victim model. Read more about model extraction attacks here.
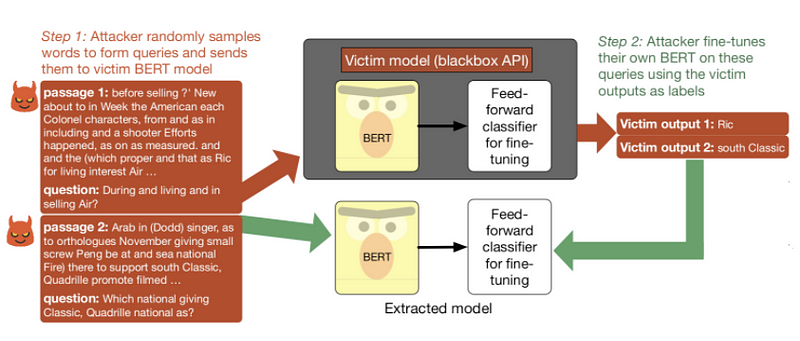
Model extraction pipeline applied to a victim model trained on SQuAD (Source).
Another interesting paper, accepted at ACL 2020, investigates whether pretrained language models are susceptible to attacks. The authors develop a poisoning method that is able to inject vulnerabilities into pretrained weights rendering these pretrained models vulnerable to serious threats. Due to this vulnerability, it is possible to show that these models expose backdoors that can be leveraged by an attacker to manipulate the model’s predictions by simply injecting any arbitrary keyword. To test this, pretrained models were used to perform downstream tasks that involved datasets injected with specific keywords meant to force the model to misclassify instances.
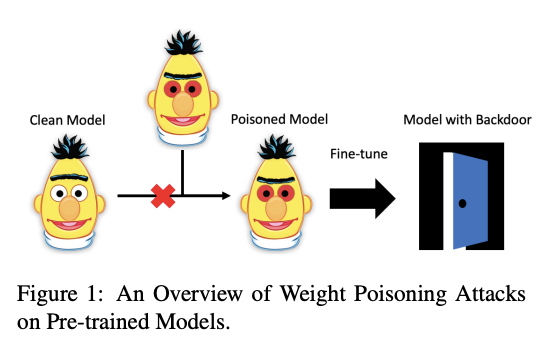
Figure by Kurita et al. (2020)
A COVID-19 series of AI-based applications and research
-
COVID-19 has proven one of the biggest challenges in modern times. Researchers from all over the world are trying to find ways to contribute and help in understanding COVID-19, from search engines to data set releases. Sebastian Ruder recently published a dedicated issue of his newsletter highlighting a few interesting projects that AI researchers have been work on.
-
On the topic of COVID-19, researchers at Allen AI will discuss the now popular COVID-19 Open Research Dataset (CORD-19) in a virtual meetup happening towards the end of this month.
-
The CORD-19 dataset is being used by many researchers to build NLP-powered applications such as search engines. Take a look at this recent paper for an example of a search engine implementation that can help researchers obtain quick insights related to CORD-19 from results reported in scholarly articles. Such tools can help inform evidence-based decision making according to the authors.
-
ArCOV-19 is an Arabic COVID-19 Twitter dataset that covers the period from the 27th of January till the 31st of March 2020 (and still ongoing). It is the first publicly-available Arabic Twitter dataset covering the COVID-19 pandemic that includes around 748k popular tweets (according to Twitter search criterion) alongside the propagation networks of the most-popular subset of them. The propagation networks include both retweets and conversational threads (i.e., threads of replies). ArCOV-19 is designed to enable research under several domains including natural language processing, data science, and social computing, among others.
Tools and Datasets ⚙️
Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence Not a tool or dataset per se, but this excellent paper by Sebastian Raschka, Joshua Patterson, and Corey Nolet provides a comprehensive overview of some of the main developments in terms of technology trends in machine learning, particularly focused on the Python programming language.
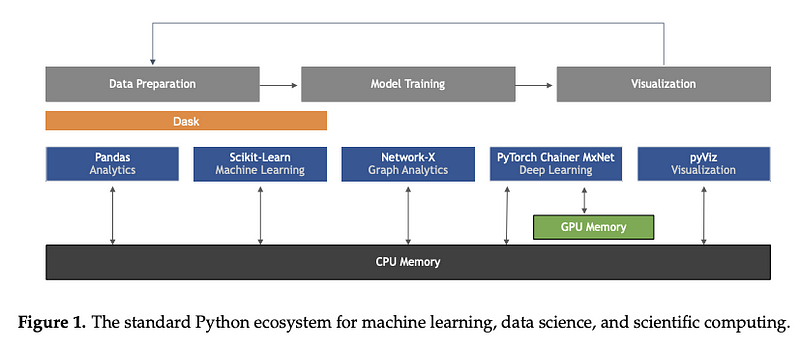
Figure by Raschka et al. (2020)
Interpretability and Explainability in ML
HuggingFace released a visualization tool called exBERT that allows you to visualize learned representations from language models such as BERT and RoBERTa. This feature was integrated into their model pages and aims at better understanding how language models are learning and what properties they are potentially encoding in these learned representations.
OpenAI recently released a web application called Microscope that contains a collection of visualizations obtained from significant layers and neurons of various vision models that are often studied in the context of interpretability. The main objective is to allow ease of analysis and sharing of interesting insights that emerge from these features learned in the neural networks so as to better understand them.
CloudCV: ViLBERT Multi-Task Demo
In the previous NLP Research Highlights, we featured multitask ViLBERT which is a method for improving vision-and-language models that can be used for caption-based image retrieval and visual question answering (VQA). The authors now provide a web application to test the models on eight different vision and language tasks such as VQA and pointing question answering.
A Twitter Dataset of 150+ million tweets related to COVID-19 for open research
Due to the relevance of the COVID-19 global pandemic, researchers are releasing a dataset of tweets acquired from Twitter related to COVID-19 chatter. Since the first release, additional data from new collaborators has been added, allowing this resource to grow to its current size. Dedicated data gathering started from March 11th yielding over 4 million tweets a day.
A tiny autograd engine
Andrej Karpathy recently released a library called micrograd which provides the ability to build and train a neural network using a simple and intuitive interface. In fact, he wrote the whole library in roughly 150 lines of code which he claims is the tiniest autograd engine there is. Ideally, such types of libraries can be used for educational purposes.
Articles and Blog posts ✍️
The Transformer Family and Recent Developments
In a new and timely blog post, Lilian Weng summarizes some of the recent developments of the Transformer model. The article provides nice notation, historical review, and the latest improvements such as longer attention span (Transformer XL), reduced computation and memory consumption.
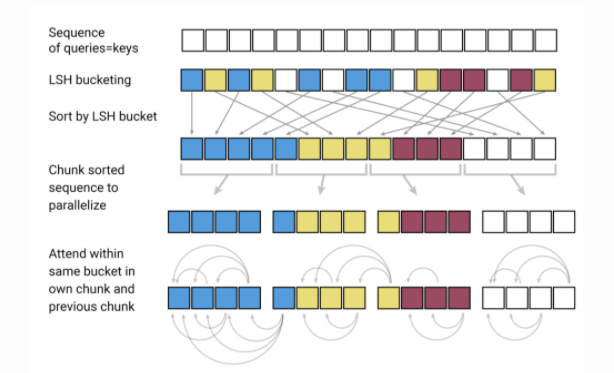
Model compression is an important area of research in NLP due to the nature and large size of pretrained language models. Ideally, as these models continue to produce state-of-the-art results across a wide variety of NLP tasks it becomes important to reduce their computational needs so as to make them feasible in production. Madison May recently published another excellent article summarizing a few methods used for model compression, particularly in NLP. Some of the main topics include pruning, graph optimizations, knowledge distillation, progressive module replacement, among others.
Education 🎓
Guest Lecture on Language Models by Alec Radford
If you are curious to know the theoretical aspect of methods used for learning language models such as CBOW, Word2Vec, ELMo, GPT, BERT, ELECTRA, T5, and GPT, then you might be interested in this great guest lecture by Alec Radford (researcher at OpenAI). This was delivered as part of the ongoing course taught by Pieter Abbeel on deep unsupervised learning techniques.
Python Numpy Tutorial (with Jupyter and Colab)
Stanford’s popular online course on Convolutional Neural Network for Visual Recognition now includes a link to a Google Colab notebook for its introductory guide to Numpy. It’s a very extensive walkthrough but it’s very nice for beginners.
New mobile neural network architectures
Interested in building neural network architectures for mobile and edge devices, then this comprehensive blog post may be for you. The article covers a range of neural network designs and includes speed performance tests.
Data-Driven Sentence Simplification: Survey and Benchmark
Sentence simplification aims to modify a sentence in order to make it easier to read and understand. This survey paper focuses on approaches that attempt to learn how to simplify using corpora of aligned original-simplified sentence pairs in English, which is the dominant paradigm nowadays. It also includes a benchmark of different approaches on common data sets so as to compare them and highlight their strengths and limitations.
Advanced Topics in Machine Learning
Yisong Yue published all lecture videos for the Data-Driven Algorithm Design course. It contains advanced topics in machine learning that range from Bayesian optimization to differentiable computation to imitation learning.
Noteworthy Mentions ⭐️
Get access to the previous issues of the NLP Newsletter here.
Harvard is currently offering a great selection of self-paced courses for free.
ARBML provides implementations of many Arabic NLP and ML projects providing real-time experience using many interfaces like web, command line and notebooks.
NLP Dashboard is a fun NLP web app to perform named entity recognition and statistical analysis of text and news stories. Built using spaCy, Flask, and Python.
If you haven’t checked it out, Connor Shorten maintains this really informative YouTube channel where he summarizes interesting and recent ML papers. He covers the important details of each work while providing excellent short and concise summaries. He also started a podcast with other great researchers and explainers in the field.
Here is a rich and impressive repository that provides best practices and recommendations (via notebooks and explanations) for many NLP scenarios such as text classification, entailment, text summarization, question answering, etc.
If you have any recent and complete datasets, projects, blog posts, tutorials, or papers that you wish to share in the next issue of the NLP Newsletter, please submit them directly using this form.
Subscribe 🔖 to the NLP Newsletter to receive future issues in your inbox.